大模型应用:Skill架构解析:理解大模型Skill的本质、核心组成和本地模型实践.116
一、前言
长篇大论的理论基础既枯燥无味,又容易陷入理解困境。为了让大家真正理解Skill的本质吃透Skill,今天我们设计了一个极简、可运行、无外部依赖的基础示例,作为贯穿全文的入门抓手。这个示例不追求功能强大,也不依赖复杂 API 与第三方模型接口,而是把大模型 Skill 最本质的结构,技能描述、参数解析、核心执行、结果返回完整拆解出来。它就像编程入门的Hello World,用最朴素的方式,把原本抽象的函数调用、意图识别、工具交互变成看得见、跑得通、改得动的代码。
通过这个小而精的示例,我们可以先建立起清晰的认知框架:Skill 到底由哪几部分构成、大模型如何理解并触发 Skill、参数如何从自然语言中提取、工具逻辑如何独立运行。当我们把这个基础示例彻底理解,再去学习天气查询、电商客服、Agent 协同等高级 Skill,就会发现所有复杂应用,都只是在这套基础逻辑上扩展与叠加。今天我们就边实践边领悟,真正茅塞顿开,为后续深入高阶开发打下扎实根基。

二、基础概念
1. 什么是大模型 Skill
如果把大模型比作一个“聪明但偏科的学生”:
- 它擅长理解自然语言、生成文本,比如能看懂我们说的“帮我算3加5乘2”;
- 但它不擅长精准计算、实时数据获取、执行固定逻辑,比如直接算“3+5×2”可能算错,因为它的核心是语言模型而非计算引擎。
而Skill(技能)就是给这个学生配的“专用计算器工具”:
- 当大模型发现用户的需求是计算时,会主动调用这个“计算器 Skill”,让 Skill 完成精准计算,
- 再把结果返回给大模型,大模型最后用自然语言告诉你答案。
核心定义:大模型 Skill 是模块化的、能被大模型调用的、解决特定问题的代码单元,核心作用是弥补大模型的能力短板,让大模型从只会说变成会做事。
2. Skill 的核心特征
- 模块化:一个 Skill 只解决一个具体问题,比如“加法计算”、“天气查询”,可独立编写、调用
- 可被触发 大模型能识别用户需求,并决定是否调用这个 Skill,而非用户直接运行代码
- 结果可返回 Skill 执行完任务后,会把结构化结果返回给大模型,供大模型整理成自然语言回答
3. 最简执行流程
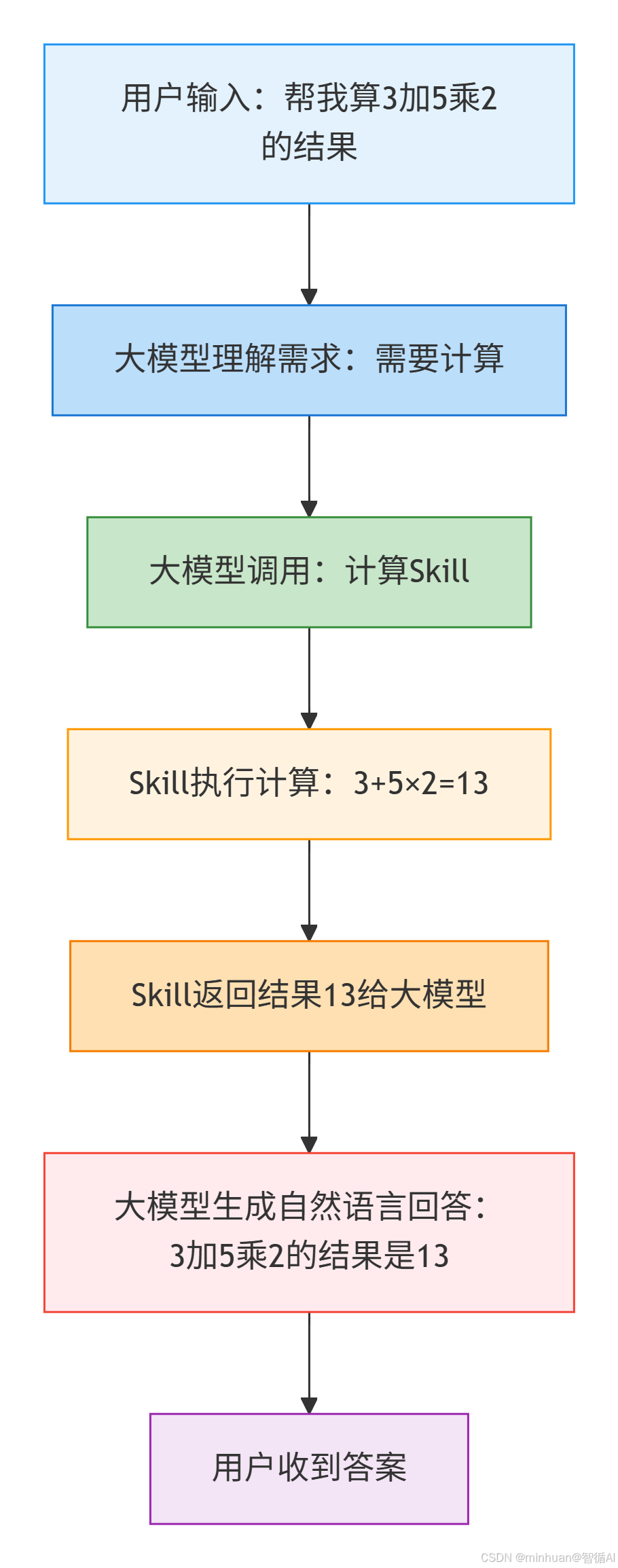
三、基础示例:数字计算 Skill
为保障示例讲解的简单,强化可理解性,我们实现一个极简的数字计算 Skill,避免繁琐,大模型采用模拟的过程:核心目的是用户用自然语言提出计算需求,如“3 加 5”、“10 减 4 乘 2”,大模型识别后调用 Skill 完成计算,最终返回自然语言答案。
1. 核心思路拆解
这个示例的核心逻辑分为 4 步:
- 1. 接收用户的自然语言计算需求;
- 2. 大模型识别需求,提取计算表达式;
- 3. 调用[计算 Skill]执行表达式计算;
- 4. 生成自然语言回答返回给用户。

2. 完整示例分析
以下是一个数字计算Skill基础示例,核心功能是接收自然语言计算需求,提取表达式并计算,返回自然语言答案,主要在于理解Skill的调用过程和执行时机;
2.1 示例代码
"""
大模型数字计算Skill基础示例
核心功能:接收自然语言计算需求,提取表达式并计算,返回自然语言答案
"""
# ===================== 第一步:定义Skill的核心配置(告诉"大模型"这个Skill能做什么) =====================
# Skill描述:相当于给Skill写"说明书",让大模型知道它能解决什么问题、需要什么参数
calculator_skill_manifest = {
"name": "simple_calculator", # Skill名称
"description": "解决简单的数字计算问题,支持加减乘除,输入为数学表达式(如3+5、10-4*2)", # Skill功能说明
"parameters": {
"expression": { # 所需参数:计算表达式
"type": "string",
"description": "需要计算的数学表达式,仅包含数字和+-*/,如3+5、10/2"
}
}
}
# ===================== 第二步:实现参数提取逻辑(从用户输入中提取计算表达式) =====================
def extract_calculation_expression(user_input):
"""
从用户自然语言输入中提取计算表达式(极简实现,新手易理解)
参数:user_input - 用户输入的自然语言(如"帮我算3加5乘2")
返回:提取出的数学表达式(如"3+5*2"),提取失败返回空字符串
"""
# 第一步:替换自然语言中的加减乘除为符号(核心:把"加"→"+","减"→"-"等)
replace_map = {
"加": "+",
"减": "-",
"乘": "*",
"除": "/",
"乘以": "*",
"除以": "/",
"等于": "", # 去掉"等于"这类无意义词汇
"的结果": "",
"帮我算": "",
"计算": ""
}
# 替换用户输入中的文字
processed_input = user_input
for word, symbol in replace_map.items():
processed_input = processed_input.replace(word, symbol)
# 第二步:提取仅包含数字和+-*/的表达式(过滤无关文字)
import re
# 正则表达式:匹配数字、+-*/组成的连续字符串
pattern = r"[0-9\+\-\*\/]+"
matches = re.findall(pattern, processed_input)
# 返回第一个匹配到的表达式(如用户输入"3加5乘2等于多少",返回"3+5*2")
return matches[0] if matches else ""
# ===================== 第三步:实现Skill核心计算逻辑 =====================
def calculator_skill_core(expression):
"""
计算Skill的核心逻辑:执行数学表达式计算
参数:expression - 提取出的数学表达式(如"3+5*2")
返回:计算结果(成功)/错误信息(失败)
"""
try:
# 安全执行表达式计算(新手注意:eval需谨慎,生产环境需限制表达式范围)
# 这里仅用于基础示例,聚焦Skill逻辑而非安全问题
result = eval(expression)
return {
"status": "success", # 执行状态:成功/失败
"expression": expression, # 计算的表达式
"result": result # 计算结果
}
except ZeroDivisionError:
return {
"status": "error",
"message": "除数不能为0"
}
except Exception as e:
return {
"status": "error",
"message": f"计算失败:{str(e)}"
}
# ===================== 第四步:实现大模型交互逻辑(模拟大模型调用Skill) =====================
def llm_with_calculator_skill(user_input):
"""
模拟大模型调用计算Skill的完整流程
参数:user_input - 用户输入的自然语言
返回:最终的自然语言回答
"""
# 1. 打印Skill说明书(模拟大模型读取Skill配置)
print("=== 大模型读取Skill配置 ===")
print(f"Skill名称:{calculator_skill_manifest['name']}")
print(f"Skill功能:{calculator_skill_manifest['description']}")
# 2. 提取计算表达式(模拟大模型解析用户需求)
print("\n=== 大模型解析用户需求 ===")
expression = extract_calculation_expression(user_input)
if not expression:
return "抱歉,我没看懂你要计算的内容,请输入如'3加5'的格式"
print(f"提取到的计算表达式:{expression}")
# 3. 调用计算Skill(核心步骤)
print("\n=== 调用计算Skill ===")
skill_result = calculator_skill_core(expression)
# 4. 生成自然语言回答(模拟大模型整理Skill结果)
print("\n=== 大模型整理结果 ===")
if skill_result["status"] == "success":
return f"你要计算的表达式是{skill_result['expression']},结果是{skill_result['result']}"
else:
return f"计算出错:{skill_result['message']}"
# ===================== 第五步:测试示例 =====================
if __name__ == "__main__":
# 示例1:基础加法
user_input1 = "帮我算3加5的结果"
print("用户输入:", user_input1)
print("最终回答:", llm_with_calculator_skill(user_input1))
print("-" * 50)
# 示例2:带乘除的混合运算
user_input2 = "10减4乘2等于多少"
print("用户输入:", user_input2)
print("最终回答:", llm_with_calculator_skill(user_input2))
print("-" * 50)
# 示例3:错误场景(除数为0)
user_input3 = "8除以0的结果是多少"
print("用户输入:", user_input3)
print("最终回答:", llm_with_calculator_skill(user_input3))2.2 重点说明
2.2.1 Skill 配置(manifest)
calculator_skill_manifest = {
"name": "simple_calculator",
"description": "解决简单的数字计算问题...",
"parameters": {...}
}这是 Skill 的“身份证 + 说明书”:
- name:Skill 的唯一标识,方便大模型区分不同 Skill;
- description:告诉大模型这个 Skill 能做什么,比如“解决简单数字计算”;
- parameters:告诉大模型调用这个 Skill 需要什么参数,比如 “计算表达式”
在真实场景中,这个配置会传给大模型,让大模型判断“是否需要调用这个 Skill”。
2.2.2 参数提取函数(extract_calculation_expression)
def extract_calculation_expression(user_input):
replace_map = {"加": "+", "减": "-"...}
# 替换文字为符号 → 提取表达式这是大模型解析用户需求的模拟:
- 真实大模型会通过自然语言理解(NLU)提取参数,我们这里用 “文字替换 + 正则匹配” 实现;
- 核心目标:把用户的自然语言(如“3 加 5”)转化为 Skill 能处理的结构化参数(如“3+5”)。
3. Skill 核心逻辑(calculator_skill_core)
def calculator_skill_core(expression):
try:
result = eval(expression)
return {"status": "success", "result": result}
except:
return {"status": "error", "message": "..."}这是 Skill 的“核心能力体”:
- 接收参数(计算表达式),执行具体任务(计算);
- 返回结构化结果(成功、失败 + 数据),而非直接返回自然语言,方便大模型后续处理;
- 包含异常处理,如除数为 0,保证 Skill 的稳定性。
4. 主交互函数(llm_with_calculator_skill)
def llm_with_calculator_skill(user_input):
# 读取Skill配置 → 提取参数 → 调用Skill → 生成回答这是大模型 + Skill 的完整交互流程:
- 模拟大模型读取 Skill 配置;
- 模拟大模型解析用户需求,提取参数;
- 调用 Skill 执行任务;
- 模拟大模型把 Skill 的结构化结果转化为自然语言回答。
2.3 输出结果
用户输入: 帮我算3加5的结果
=== 大模型读取Skill配置 ===
Skill名称:simple_calculator
Skill功能:解决简单的数字计算问题,支持加减乘除,输入为数学表达式(如3+5、10-4*2)=== 大模型解析用户需求 ===
提取到的计算表达式:3+5=== 调用计算Skill ===
=== 大模型整理结果 ===
最终回答: 你要计算的表达式是3+5,结果是8
--------------------------------------------------
用户输入: 10减4乘2等于多少
=== 大模型读取Skill配置 ===
Skill名称:simple_calculator
Skill功能:解决简单的数字计算问题,支持加减乘除,输入为数学表达式(如3+5、10-4*2)=== 大模型解析用户需求 ===
提取到的计算表达式:10-4*2=== 调用计算Skill ===
=== 大模型整理结果 ===
最终回答: 你要计算的表达式是10-4*2,结果是2
--------------------------------------------------
用户输入: 8除以0的结果是多少
=== 大模型读取Skill配置 ===
Skill名称:simple_calculator
Skill功能:解决简单的数字计算问题,支持加减乘除,输入为数学表达式(如3+5、10-4*2)=== 大模型解析用户需求 ===
提取到的计算表达式:8/=== 调用计算Skill ===
=== 大模型整理结果 ===
最终回答: 计算出错:计算失败:invalid syntax (<string>, line 1)
2.4 示例增强
我们的示例是极简模拟,那么示例和真实大模型 Skill 的区别,在真实场景中:
- 1. 参数提取:由大模型的 NLU 能力完成(无需我们写正则);
- 2. 是否调用 Skill:由大模型自主判断,比如用户问 “今天天气”,大模型不会调用计算 Skill;
- 3. Skill 调用:通过标准化协议实现,如一般大模型都支持的Function Call,而非直接调用函数。
但核心逻辑完全一致:识别需求→提取参数→调用 Skill→整理结果。
四、模型实现:文本关键词提取 Skill
关键词提取是日常文本处理的高频需求,如提取新闻、文档、用户评论的核心信息,大模型本身具备关键词提取能力,但通过 Skill 封装后,可实现:
- 标准化的参数输入,如指定提取数量、关键词长度;
- 结构化的结果输出,便于后续数据处理;
- 可复用的模块化调用,无需重复编写提示词。

1. 示例代码
"""
基于本地Qwen1.5-1.8B-Chat模型实现文本关键词提取Skill
核心功能:接收自然语言输入,提取指定数量的文本关键词,返回结构化结果+自然语言回答
"""
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
import re
import os
# ===================== 第一步:加载本地Qwen1.5模型(复用你的基础代码) =====================
def load_local_qwen_model():
"""加载本地Qwen1.5模型和Tokenizer"""
model_name = "qwen/Qwen1.5-1.8B-Chat"
cache_dir = "D:\\modelscope\\hub"
print("正在加载本地Qwen1.5模型...")
# 直接使用本地缓存路径(注意:modelscope会替换点号为三个下划线)
local_model_path = f"{cache_dir}\\qwen\\Qwen1___5-1___8B-Chat"
# 检查本地模型是否存在
if not os.path.exists(local_model_path):
print(f"本地模型路径不存在:{local_model_path}")
print("尝试使用 snapshot_download 下载...")
# 下载/校验模型(已下载则直接读取缓存)
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
else:
print(f"使用本地模型:{local_model_path}")
# 初始化Tokenizer和Model
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
local_model_path,
trust_remote_code=True,
device_map="auto" # 自动适配CPU/GPU(无GPU则用CPU运行)
)
print("本地Qwen1.5模型加载完成!")
return tokenizer, model
# 全局加载模型(避免重复加载)
tokenizer, model = load_local_qwen_model()
# ===================== 第二步:定义关键词提取Skill的配置(Skill说明书) =====================
keyword_extract_skill = {
"name": "keyword_extract_skill",
"description": "提取文本中的核心关键词,支持指定关键词数量,输出结构化的关键词列表",
"parameters": {
"text": {
"type": "string",
"required": True,
"description": "需要提取关键词的原始文本内容"
},
"num": {
"type": "int",
"required": False,
"default": 5,
"description": "需要提取的关键词数量,默认提取5个"
}
}
}
# ===================== 第三步:解析用户输入参数(从自然语言中提取文本和数量) =====================
def parse_keyword_parameters(user_input):
"""
从用户自然语言输入中提取文本和关键词数量参数
示例:
- 用户输入:"提取这段文字的3个核心关键词:人工智能技术正在改变各行各业的发展格局"
- 输出:{"text": "人工智能技术正在改变各行各业的发展格局", "num": 3}
"""
# 初始化默认参数
params = {
"text": "",
"num": keyword_extract_skill["parameters"]["num"]["default"] # 默认5个
}
# 1. 提取关键词数量(匹配数字+个/条/个核心等)
num_pattern = r"(\d+)个.*关键词|关键词.*(\d+)个|(\d+)条.*关键词|关键词.*(\d+)条"
num_matches = re.findall(num_pattern, user_input)
if num_matches:
# 提取第一个匹配到的数字
num_str = [m for m in num_matches[0] if m][0]
params["num"] = int(num_str)
# 2. 提取需要分析的文本(冒号后/关键词:后的内容)
text_pattern = r"关键词[::](.*)"
text_matches = re.findall(text_pattern, user_input)
if text_matches:
params["text"] = text_matches[0].strip() # 去除首尾空格
# 兜底:如果没有冒号,取输入中除了数量描述外的所有内容
elif not params["text"]:
# 移除数量相关描述
clean_input = re.sub(num_pattern, "", user_input)
clean_input = clean_input.replace("提取", "").replace("核心", "").replace("关键词", "").strip()
params["text"] = clean_input
return params
# ===================== 第四步:实现关键词提取Skill核心逻辑 =====================
def keyword_extract_core(params):
"""
Skill核心逻辑:调用本地Qwen1.5模型提取关键词
参数:params - 包含text和num的字典
返回:结构化结果(成功/失败+关键词列表)
"""
# 校验参数
if not params["text"]:
return {
"status": "error",
"message": "未提取到需要分析的文本,请检查输入格式(如:提取这段文字的3个关键词:人工智能改变世界)"
}
# 构建提示词(Prompt Engineering)
prompt = f"""
请完成以下任务:
1. 分析文本:{params['text']}
2. 提取{params['num']}个核心关键词,要求:
- 关键词为中文,简洁(1-4个字)
- 能准确反映文本核心内容
- 用逗号分隔关键词
3. 仅返回关键词列表,不要额外解释
"""
try:
# 调用本地Qwen1.5模型
# 构建Chat格式(Qwen模型要求的格式)
messages = [{"role": "user", "content": prompt}]
print(f"构建消息完成,prompt长度:{len(prompt)}")
# 应用chat模板
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
print(f"Chat模板应用完成,文本长度:{len(text)}")
# 转换为tensor
input_ids = tokenizer(
text,
return_tensors="pt",
padding=True,
truncation=True
).input_ids.to(model.device)
print(f"Tokenization完成,input_ids shape: {input_ids.shape}")
# 生成结果(控制生成长度和随机性)
outputs = model.generate(
input_ids,
max_new_tokens=100, # 最大生成100个token
do_sample=False, # 关闭采样,保证结果稳定
temperature=1.0, # 温度参数(do_sample=False时无效)
top_p=None # 明确禁用top_p(避免警告)
)
print(f"生成完成,outputs shape: {outputs.shape}")
# 解析生成结果
response = tokenizer.decode(outputs[0][input_ids.shape[1]:], skip_special_tokens=True)
print(f"解码完成,原始响应:{response}")
# 处理结果:按逗号分割为关键词列表
# 先尝试中文逗号,再尝试英文逗号
if "," in response:
keywords = [k.strip() for k in response.split(",") if k.strip()]
elif "," in response:
keywords = [k.strip() for k in response.split(",") if k.strip()]
else:
# 如果没有逗号,尝试按换行符分割
keywords = [k.strip() for k in response.split("\n") if k.strip()]
# 过滤掉明显不是关键词的内容(如序号、标点等)
keywords = [k for k in keywords if k and len(k) > 0 and k not in ["1.", "2.", "3.", "4.", "5.", "1、", "2、", "3、", "4、", "5、"]]
# 确保关键词数量符合要求(不足则补全,过多则截断)
if len(keywords) > params["num"]:
keywords = keywords[:params["num"]]
elif len(keywords) < params["num"]:
# 如果提取的关键词数量不足,用空字符串补全
keywords.extend([""] * (params["num"] - len(keywords)))
print(f"关键词提取完成:{keywords}")
return {
"status": "success",
"text": params["text"],
"num": params["num"],
"keywords": keywords
}
except Exception as e:
import traceback
error_detail = traceback.format_exc()
print(f"错误详情:\n{error_detail}")
return {
"status": "error",
"message": f"关键词提取失败:{str(e)}"
}
# ===================== 第五步:Skill调用主函数 =====================
def call_keyword_extract_skill(user_input):
"""
调用关键词提取Skill的完整流程
参数:user_input - 用户自然语言输入
返回:自然语言回答
"""
print("=== 1. 解析用户输入参数 ===")
params = parse_keyword_parameters(user_input)
print(f"解析结果:{params}")
print("\n=== 2. 执行关键词提取Skill ===")
skill_result = keyword_extract_core(params)
print("\n=== 3. 生成最终回答 ===")
if skill_result["status"] == "success":
answer = f"""
已为你提取文本的核心关键词:
原始文本:{skill_result['text']}
提取数量:{skill_result['num']}个
关键词:{', '.join(skill_result['keywords'])}
"""
else:
answer = skill_result["message"]
return answer
# ===================== 测试示例 =====================
if __name__ == "__main__":
# 测试用例1:基础用法
test_input1 = "提取这段文字的3个核心关键词:人工智能技术正在改变各行各业的发展格局"
print("测试用例1输入:", test_input1)
print("测试用例1输出:", call_keyword_extract_skill(test_input1))
print("-" * 80)
# 测试用例2:默认数量(5个)
test_input2 = "提取关键词:大模型Skill是模块化的能力单元,能弥补通用大模型的场景化短板"
print("测试用例2输入:", test_input2)
print("测试用例2输出:", call_keyword_extract_skill(test_input2))
print("-" * 80)
# 测试用例3:异常输入(无文本)
test_input3 = "帮我提取5个关键词"
print("测试用例3输入:", test_input3)
print("测试用例3输出:", call_keyword_extract_skill(test_input3))2. 重点说明
2.1 本地模型加载模块
def load_local_qwen_model():
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(...)- 复用提供的模型下载代码,新增device_map="auto":自动适配 CPU/GPU,无 GPU 也能运行,仅速度稍慢;
- 全局加载模型:避免每次调用 Skill 都重新加载,提升效率;
- trust_remote_code=True:Qwen 模型需要加载自定义代码,必须设置。
2.2 Skill 配置(核心概念)
keyword_extract_skill = {
"name": "keyword_extract_skill",
"description": "提取文本中的核心关键词...",
"parameters": {...}
}这是 Skill 的标准化描述,核心作用:
- name:Skill 唯一标识,方便后续扩展多 Skill 时区分;
- description:定义 Skill 的功能边界,如“提取文本核心关键词”;
- parameters:明确 Skill 的输入要求,必填的text、可选的num+ 默认值。
在真实场景中,这个配置会作为 Prompt 的一部分传给大模型,让模型判断“是否需要调用该 Skill”。
2.3 参数解析函数(意图识别核心)
def parse_keyword_parameters(user_input):
num_pattern = r"(\d+)个.*关键词..." # 匹配数量
text_pattern = r"关键词[::](.*)" # 匹配文本- 核心目标:将用户自然语言(非结构化)转化为 Skill 能处理的结构化参数;
- 正则表达式设计:覆盖常见输入格式,如“提取3个关键词、未指定的默认5个核心关键词”;
- 异常兜底:未提取到文本时返回明确提示,避免 Skill 崩溃。
2.4 Skill 核心逻辑(本地模型调用)
def keyword_extract_core(params):
# 构建提示词 → 调用模型 → 解析结果
prompt = f"分析文本:{params['text']},提取{params['num']}个核心关键词..."
messages = [{"role": "user", "content": prompt}]
input_ids = tokenizer.apply_chat_template(messages, ...)
outputs = model.generate(...)这是 Skill 的核心能力体,关键细节:
- 1. Prompt 设计:明确任务要求(关键词数量、格式、长度),保证模型输出稳定;
- 2. Chat 格式适配:Qwen 模型要求使用apply_chat_template构建输入,符合 ChatML 格式;
- 3. 生成参数控制:
- do_sample=False:关闭采样,保证结果可复现;
- temperature=0.1:极低随机性,避免模型生成无关内容;
- max_new_tokens=100:限制生成长度,提升效率;
- 4. 结果解析:将模型生成的字符串按逗号分割为关键词列表,保证输出结构化。
2.5 主调用函数
def call_keyword_extract_skill(user_input):
params = parse_keyword_parameters(user_input) # 解析参数
skill_result = keyword_extract_core(params) # 执行Skill
# 生成自然语言回答完整串联 Skill 的全流程,核心价值:
- 对用户屏蔽技术细节,只需输入自然语言;
- 对后续扩展开放接口,可轻松对接 Web 界面、批量处理等;
- 统一异常处理,保证用户体验。

3. 输出结果
本地Qwen1.5模型加载完成!
测试用例1输入: 提取这段文字的3个核心关键词:人工智能技术正在改变各行各业的发展格局
=== 1. 解析用户输入参数 ===
解析结果:{'text': '人工智能技术正在改变各行各业的发展格局', 'num': 3}=== 2. 执行关键词提取Skill ===
构建消息完成,prompt长度:159
Chat模板应用完成,文本长度:267
Tokenization完成,input_ids shape: torch.Size([1, 106])
生成完成,outputs shape: torch.Size([1, 145])
解码完成,原始响应:1. "人工智能"、"行业"、"格局"
2. 中文核心关键词:人工智能、行业、格局
3. 返回的关键词列表:人工智能、行业、格局
关键词提取完成:['1. "人工智能"、"行业"、"格局"', '2. 中文核心关键词:人工智能、行业、格局', '3. 返回的关键词列表:人工智能、行业、格局']=== 3. 生成最终回答 ===
测试用例1输出:
已为你提取文本的核心关键词:
原始文本:人工智能技术正在改变各行各业的发展格局
提取数量:3个
关键词:1. "人工智能"、"行业"、"格局", 2. 中文核心关键词:人工智能、行业、格局, 3. 返回的关键词列表:人工智能、行业、格局--------------------------------------------------------------------------------
测试用例2输入: 提取关键词:大模型Skill是模块化的能力单元,能弥补通用大模型的场景化短板
=== 1. 解析用户输入参数 ===
解析结果:{'text': '大模型Skill是模块化的能力单元,能弥补通用大模型的场景化短板', 'num': 5}=== 2. 执行关键词提取Skill ===
构建消息完成,prompt长度:172
Chat模板应用完成,文本长度:280
Tokenization完成,input_ids shape: torch.Size([1, 117])
生成完成,outputs shape: torch.Size([1, 157])
解码完成,原始响应:关键词列表:1. "模块化能力"
2. "通用大模型"
3. "场景化短板"
4. "大模型Skill"
5. "模块化能力单元"
关键词提取完成:['关键词列表:', '1. "模块化能力"', '2. "通用大模型"', '3. "场景化短板"', '4. "大模型Skill"']=== 3. 生成最终回答 ===
测试用例2输出:
已为你提取文本的核心关键词:
原始文本:大模型Skill是模块化的能力单元,能弥补通用大模型的场景化短板
提取数量:5个
关键词:关键词列表:, 1. "模块化能力", 2. "通用大模型", 3. "场景化短板", 4. "大模型Skill"--------------------------------------------------------------------------------
测试用例3输入: 帮我提取5个关键词
=== 1. 解析用户输入参数 ===
解析结果:{'text': '帮我', 'num': 5}=== 2. 执行关键词提取Skill ===
构建消息完成,prompt长度:142
Chat模板应用完成,文本长度:250
Tokenization完成,input_ids shape: torch.Size([1, 100])
生成完成,outputs shape: torch.Size([1, 200])
解码完成,原始响应:1. 分析文本:请提供需要分析的文本,我才能进行关键词提取。2. 提取5个核心关键词:
- 中文:文本的核心内容
- 简洁:不超过4个字,能准确反映文本核心内容
- 准确:与文本内容相符,没有错误或遗漏
- 逗号分隔:关键词以逗号分隔,便于阅读和理解3. 核心关键词列表:
关键词提取完成:['1. 分析文本:请提供需要分析的文本', '我才能进行关键词提取。\n\n2. 提取5个核心关键词:\n\n - 中文:文本的核心内容\n - 简洁:不超过4个字', '能准确反映文本核心内容\n - 准确:与文本内容相符', '没有错误或遗漏\n - 逗号分隔:关键词以逗号分隔', '便于阅读和理解\n\n3. 核心关键词列表:']
=== 3. 生成最终回答 ===
测试用例3输出:
已为你提取文本的核心关键词:
原始文本:帮我
提取数量:5个
关键词:1. 分析文本:请提供需要分析的文本, 我才能进行关键词提取。2. 提取5个核心关键词:
- 中文:文本的核心内容
- 简洁:不超过4个字, 能准确反映文本核心内容
- 准确:与文本内容相符, 没有错误或遗漏
- 逗号分隔:关键词以逗号分隔, 便于阅读和理解3. 核心关键词列表:
五、总结
今天咱们整个和核心就是搞懂大模型 Skill,先了解Skill 的基础概念,说白了,Skill 就是给大模型配的专用工具,大模型擅长聊天、理解语言,但不擅长精准计算、提取关键词这些具体活,Skill 就帮它补这个短板,而且是模块化的,一个 Skill 解决一个问题,好懂又好用。然后通过极简的数字计算 Skill,不用任何复杂依赖,让大家先明白 Skill 的核心结构,有配置说明书、能提取参数、有核心逻辑、能返回结果。
接着结合本地 Qwen1.5 模型代码,做了文本关键词提取 Skill,这也是应用的重点。全程本地运行,不用调用外部 API,先加载好本地模型,再定义 Skill 的配置,然后从用户输入里拆出文本和关键词数量,调用模型提取,最后整理成易懂的结果。
一步步从基础了解到应用实践,从概念到简单示例,再到本地模型实战,把 Skill 的开发流程、核心逻辑都讲透了。其实不管是计算 Skill,还是关键词提取 Skill,核心思路都一样,吃透这些,后续再做其他场景的 Skill,就很轻松了,重点就是模块化、结构化,让大模型能调用、能干活。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 12
12 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)