基于LSTM - AdaBoost的多输入单输出回归预测
基于LSTM-AdaBoost长短期记忆网络结合AdaBoost多输入单输出回归预测 python代码 1.输入多个特征,输出单个变量,多变量回归预测; 2.data为数据集,excel数据,前6列输入,最后1列输出,运行主程序即可,所有文件放在一个文件夹; 3.命令窗口输出R2、MSE、MAE多指标评价; 4.可视化: 通过使用Matplotlib,代码提供了可视化工具,用于评估模型性能,包括真实值与预测值的对比图和残差图。 具体实现步骤如下: 数据预处理:将输入数据按照时间顺序划分为多个序列,每个序列包含多个输入变量和一个输出变量。 LSTM特征提取:对于每个序列,使用LSTM网络提取其特征表示。 将LSTM网络的输出作为AdaBoost的输入数据。 AdaBoost回归:将LSTM网络的输出作为AdaBoost的输入数据,并使用多个弱学习器对输出变量进行回归预测。 每个弱学习器的权重根据其预测误差进行更新,以提高整体的预测准确性。 预测输出:将多个弱学习器的预测结果进行加权组合,得到最终的预测输出结果。
在数据科学领域,多变量回归预测是一个常见且重要的任务。今天咱们来聊聊如何基于LSTM - AdaBoost实现多输入单输出回归预测,并用Python代码实现它。
1. 数据预处理
咱们的数据data是个Excel数据,前6列是输入特征,最后1列是输出变量。在预处理阶段,需要把输入数据按时间顺序划分成多个序列,每个序列包含多个输入变量和一个输出变量。
import pandas as pd
import numpy as np
# 读取Excel数据
data = pd.read_excel('your_data_file.xlsx')
X = data.iloc[:, :6].values
y = data.iloc[:, -1].values
# 划分序列,这里假设每个序列包含10个时间步
sequence_length = 10
X_sequences = []
y_sequences = []
for i in range(len(X) - sequence_length):
X_seq = X[i:i + sequence_length]
y_seq = y[i + sequence_length]
X_sequences.append(X_seq)
y_sequences.append(y_seq)
X_sequences = np.array(X_sequences)
y_sequences = np.array(y_sequences)在这段代码里,先用pandas的readexcel读取数据,然后把数据分割成X(特征)和y(目标变量)。接着通过循环,按照设定的sequencelength把数据划分成序列,Xsequences就是处理好的输入序列数据,ysequences是对应的输出。
2. LSTM特征提取
对于每个划分好的序列,使用LSTM网络提取其特征表示。
from keras.models import Sequential
from keras.layers import LSTM
# 构建LSTM模型
lstm_model = Sequential()
lstm_model.add(LSTM(50, return_sequences=False, input_shape=(sequence_length, 6)))
lstm_model.compile(optimizer='adam', loss='mse')
# 训练LSTM模型
lstm_model.fit(X_sequences, y_sequences, epochs=50, batch_size=32)
# 使用LSTM模型进行特征提取
lstm_features = lstm_model.predict(X_sequences)这里用Keras构建了一个简单的LSTM模型,它接收我们之前划分好的序列数据(sequencelength, 6)作为输入形状。LSTM(50, returnsequences=False)表示有50个LSTM单元,并且只返回最后一个时间步的输出。模型编译使用adam优化器和均方误差mse损失函数。训练模型后,用它来预测得到lstm_features,这就是LSTM提取出来的特征。
3. AdaBoost回归
把LSTM网络的输出作为AdaBoost的输入数据,并使用多个弱学习器对输出变量进行回归预测。每个弱学习器的权重根据其预测误差进行更新,以提高整体的预测准确性。
from sklearn.ensemble import AdaBoostRegressor
from sklearn.tree import DecisionTreeRegressor
# 使用LSTM特征作为AdaBoost输入
ada_boost = AdaBoostRegressor(DecisionTreeRegressor(max_depth = 4), n_estimators = 100)
ada_boost.fit(lstm_features, y_sequences)
# 预测输出
y_pred = ada_boost.predict(lstm_features)这里导入AdaBoostRegressor和DecisionTreeRegressor,DecisionTreeRegressor作为AdaBoost的弱学习器,设定最大深度maxdepth = 4,弱学习器数量nestimators = 100。然后用LSTM提取的特征lstmfeatures和目标变量ysequences训练AdaBoost模型,最后进行预测得到y_pred。
4. 模型评估与可视化
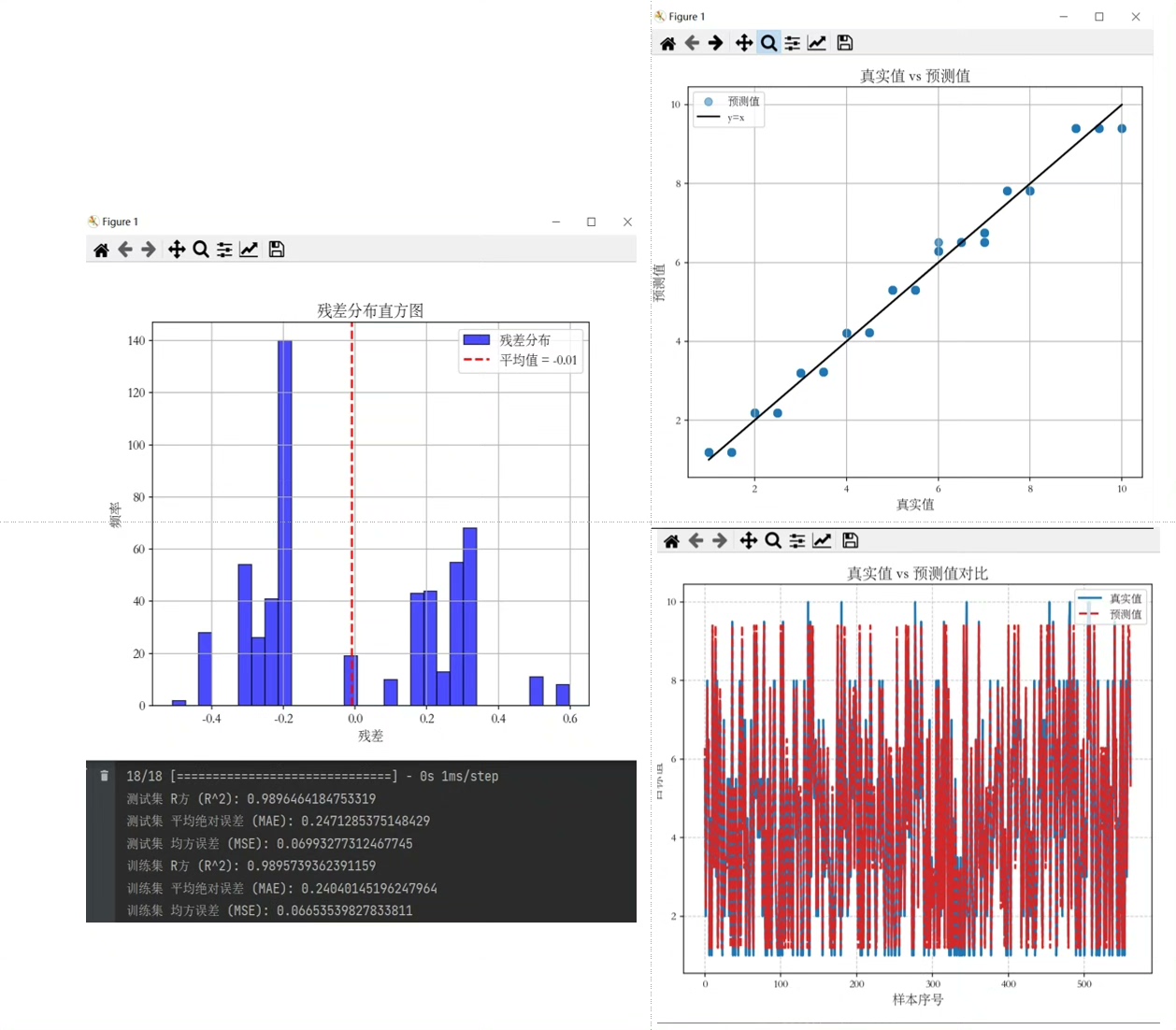
在命令窗口输出R2、MSE、MAE多指标评价,并通过Matplotlib进行可视化,包括真实值与预测值的对比图和残差图。
from sklearn.metrics import r2_score, mean_squared_error, mean_absolute_error
import matplotlib.pyplot as plt
# 计算评价指标
r2 = r2_score(y_sequences, y_pred)
mse = mean_squared_error(y_sequences, y_pred)
mae = mean_absolute_error(y_sequences, y_pred)
print(f"R2: {r2}, MSE: {mse}, MAE: {mae}")
# 真实值与预测值对比图
plt.figure(figsize=(10, 6))
plt.plot(y_sequences, label='True Values')
plt.plot(y_pred, label='Predicted Values')
plt.xlabel('Data Points')
plt.ylabel('Target Variable')
plt.legend()
plt.title('True vs Predicted Values')
plt.show()
# 残差图
residuals = y_sequences - y_pred
plt.figure(figsize=(10, 6))
plt.scatter(y_pred, residuals)
plt.xlabel('Predicted Values')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.show()通过sklearn.metrics里的函数计算R2、MSE、MAE指标并打印。接着用Matplotlib分别绘制真实值与预测值的对比图以及残差图,从这两个图能直观地看出模型的性能表现。
基于LSTM-AdaBoost长短期记忆网络结合AdaBoost多输入单输出回归预测 python代码 1.输入多个特征,输出单个变量,多变量回归预测; 2.data为数据集,excel数据,前6列输入,最后1列输出,运行主程序即可,所有文件放在一个文件夹; 3.命令窗口输出R2、MSE、MAE多指标评价; 4.可视化: 通过使用Matplotlib,代码提供了可视化工具,用于评估模型性能,包括真实值与预测值的对比图和残差图。 具体实现步骤如下: 数据预处理:将输入数据按照时间顺序划分为多个序列,每个序列包含多个输入变量和一个输出变量。 LSTM特征提取:对于每个序列,使用LSTM网络提取其特征表示。 将LSTM网络的输出作为AdaBoost的输入数据。 AdaBoost回归:将LSTM网络的输出作为AdaBoost的输入数据,并使用多个弱学习器对输出变量进行回归预测。 每个弱学习器的权重根据其预测误差进行更新,以提高整体的预测准确性。 预测输出:将多个弱学习器的预测结果进行加权组合,得到最终的预测输出结果。
这样,咱们就完成了基于LSTM - AdaBoost的多输入单输出回归预测,并且对模型进行了评估和可视化。希望这篇博文能帮你对这个方法有更清晰的了解和实践思路。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)