收藏 | Agent与LLM调用区别:小白程序员必学大模型进阶指南
0. Agent与LLM调用的区别
LLM调用是单纯的输入-输出,而Agent是具备规划、记忆、工具使用能力的自主系统。
一般,我们打开一个对话窗口,输入一个问题,模型立刻给出回答——这就是一次典型的LLM调用
| 一般 LLM 调用 | Agent(智能体) | |
|---|---|---|
| 核心定义 | 一个语言模型,根据输入生成文本输出 | 一个以LLM为“大脑”的系统,能自主规划、调用工具、管理记忆 |
| 交互方式 | 一次性问答:用户输入 → 模型输出 | 多轮循环:任务 → 思考 → 行动 → 观察 → 再思考 → 输出 |
| 是否具备自主性 | 被动响应,完全依赖用户指令 | 主动分解任务、制定步骤,过程中可自行决策 |
| 工具使用能力 | 无,仅靠内部知识 | 可调用外部API、数据库、计算器、搜索引擎等 |
| 记忆管理 | 通常只有单次对话的短期记忆 | 可维护长期记忆(向量数据库)和短期记忆(上下文) |
| 输出方式 | 一次生成最终答案 | 可能经过多步推理,最终给出结果,过程中可能有中间动作 |
| 典型例子 | 你用ChatGPT问“今天天气怎么样”,它说“我无法获取实时信息” | Agent收到同样问题,会主动调用天气API,获取数据后告诉你结果 |
LLM像是大脑(一个拥有短期记忆的大脑),但Agent不仅拥有大脑,并且拥有记忆和手脚(工具)。Agent不是另一个模型,而是以LLM为控制中枢,融合规划、记忆、工具执行能力的完整系统。它让AI从“能说会道”进化到“能动手解决实际问题”。接下来,我们就来拆解这个系统到底由哪些核心组件构成,它们又是如何协作的。
1. Agent的组成
Agent由以下部分组成:
-
- 大语言模型(LLM):LLM是Agent的大脑,它不仅是语言理解与生成的基础,更是整个系统的决策中枢。负责思考“用户想要什么?”、“现在该做什么?”以及“怎么做更好?”。往往LLM决定了一个Agent的上限。
-
- 记忆模块(Memory):记忆让Agent不再是“一次性对话”的工具,而是能持续学习和积累经验的个体。记忆通常分为两类:
- • 短期记忆:类似于人类的“工作记忆”,指在单次任务或会话中临时存储的信息。有多种实现方式,上下文窗口和摘要等。例如把对话历史、刚刚观察到的环境反馈直接拼接到提示词中。但短期记忆有容量限制(如上下文长度),当信息太多时会被遗忘或压缩。
- • 长期记忆:相当于人类的“长时记忆”,用于跨会话持久化存储重要信息。通常借助外部数据库(向量数据库+关系数据库)实现。Agent可以将关键知识(如用户偏好、任务经验、领域知识)向量化后存入数据库,后续需要时通过相似性检索召回,再放入短期记忆中供LLM使用。长期记忆让Agent在多次交互中保持一致性,并不断成长。
-
- 规划模块(Planning):规划能力是Agent从“被动响应”走向“主动行动”的关键;规划模块负责任务的分解,并决定执行顺序和策略;执行结果的反馈调整甚至是反思。
-
- 行动,工具的使用(Tool Use):工具是Agent连接外部世界、打破LLM自身能力限制的桥梁。通过调用各种工具,Agent能获取实时信息、执行具体操作、进行计算等。工具的使用抽象来讲就是Function Calling,具体一点可以是:浏览器搜索、调用api接口(查天气、查地图等)、发邮件等。将工具调用的方式标准化的实现就是MCP协议。
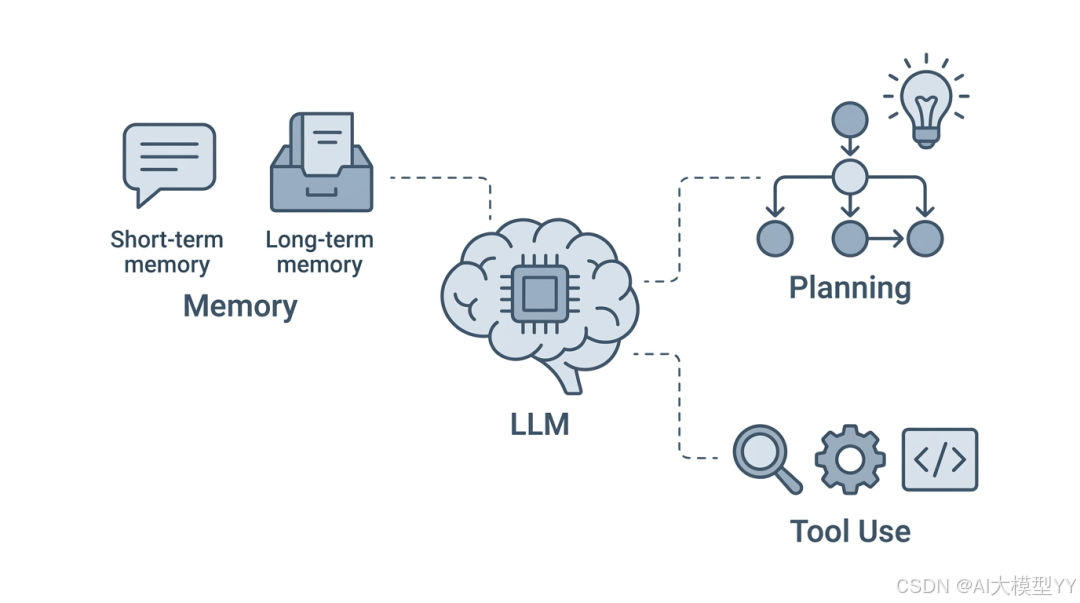
一个典型的Agent工作流程如下:
-
- 用户输入任务 → 进入短期记忆。
-
- LLM结合短期记忆和从长期记忆中检索到的相关知识,理解任务。
-
- 规划模块将任务拆解为步骤,决定下一步行动(可能是一个子任务,或直接调用工具)。
-
- 如果需要外部信息或操作,LLM生成工具调用指令,工具模块执行并返回结果。
-
- 结果被放回短期记忆,LLM继续分析,可能修正计划或进行下一步。
-
- 重复3-5步,直到任务完成,LLM生成最终答案返回给用户。
2. 大语言模型(LLM)
由大语言模型(LLM)来负责感知,如果把Agent比作一个能独立完成任务的数字员工,那么大语言模型(LLM)就是他的大脑。它不仅负责理解你说的话,更重要的是——它决定了整个Agent的思考深度和行动能力。在Agent架构中,LLM不再只是一个“文本生成器”,而是一个通用的推理引擎和决策中心。
在传统用法中,我们给LLM一个 prompt,它直接返回答案。但在Agent系统中,LLM被赋予了更多的“职责”:
- • 意图理解与任务分解:将用户模糊的指令(如“帮我研究一下RAG的最新进展”)转化为清晰、可执行的子任务清单。
- • 推理与规划:基于当前状态(包括对话历史、环境反馈)思考下一步该做什么。它可能采用 思维链(Chain-of-Thought) 的方式,一步步推理出解决方案。
- • 工具调用决策:判断何时需要借助外部工具(如搜索引擎、计算器),并生成符合格式的调用指令(如JSON格式的function calling参数)。
- • 自我反思与修正:当某一步执行失败或结果不符合预期时,LLM能分析原因,调整计划,甚至尝试新的路径。
- • 生成最终响应:综合所有信息,以自然语言的形式返回给用户。
简单来说,LLM让Agent具备了“思考”的能力,而其他模块(记忆、规划、工具)则是它的“感知”和“行动”的延伸。
让我们来举个🌰来进一步理解:
在下面这个例子中,LLM不仅理解了多步任务,还自主规划了调用工具的时机、解析了API返回结果,并最终生成了人性化的回答。整个过程完全由LLM的推理能力驱动。
用户输入:帮我查一下这周末杭州的天气,并推荐两个适合带小孩去的室内景点。LLM 第一轮思考(Thought):用户需要两个信息:1. 杭州周末天气;2. 室内儿童景点推荐。我目前没有实时天气数据,需要调用天气API;景点推荐可以结合天气情况和我的知识库给出,但最好也获取最新评价。计划:先调用天气API获取天气,然后根据天气情况推荐景点。LLM 行动(Action):调用天气API,参数:城市=杭州,日期=本周六、日。(系统返回天气数据:周六小雨,13-18℃;周日阴,15-20℃)LLM 观察(Observation):天气:周末有小雨,气温适宜。适合推荐室内景点。思考(Thought):现在需要推荐两个室内儿童景点。我可以从我的训练知识中回忆一些热门选项,但为了确保准确性,最好再调用一个景点评价API或搜索最新信息。计划:先调用景点查询API,如果没有再使用搜索引擎。LLM 行动(Action):调用景点推荐API,参数:城市=杭州,类型=室内儿童,返回数量=2。(系统返回:杭州Do都城少儿社会体验馆、杭州烂苹果乐园)LLM 最终思考(Final Thought):已获取景点信息,结合天气,可以给出完整回答。需要提醒用户带雨具。LLM 响应(Response):本周末杭州有小雨,气温13-20℃,建议带上雨具。推荐两个室内儿童景点:1. 杭州Do都城少儿社会体验馆(适合儿童职业体验)2. 杭州烂苹果乐园(大型室内儿童乐园)祝您周末愉快!
3. 记忆模块(Memory)
如果说LLM是Agent的大脑,那么记忆模块就是它的海马体——负责存储、检索和更新信息。没有记忆的Agent就像一位患有严重失忆症的助手:每次对话都从零开始,无法记住用户的偏好,也无法从过去的经验中学习。而有了记忆,Agent才能真正实现持续进化和个性化交互。
在Agent架构中,记忆被划分为两个层次:短期记忆和长期记忆,它们各司其职,共同构建起智能体的“经验库”。
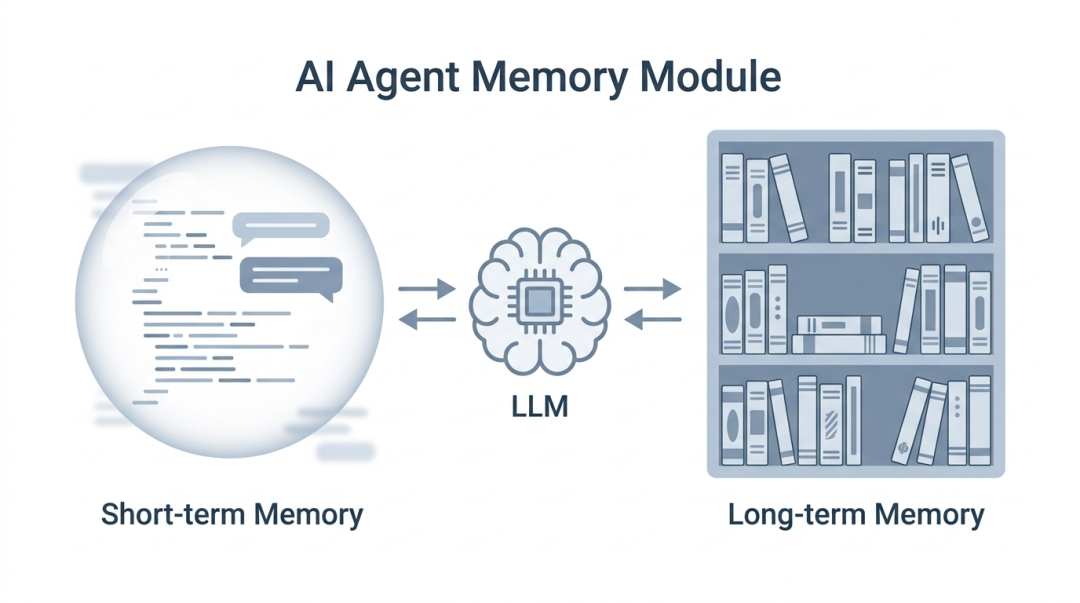
3.1 短期记忆
短期记忆是指在当前任务或会话过程中临时存储的信息。它相当于人类在工作时脑海中暂时记住的几个数字或一句话,用完即忘。
特点:
- • 容量有限:受限于LLM的上下文窗口(如cursor中的gpt-5.3-codex 272k tokens context window),超出部分会被截断或遗忘。
- • 会话级持久性:仅在单次对话或任务执行期间有效,任务结束后通常不会保留。
- • 实现方式:最直接的方式就是将对话历史、中间推理步骤、工具返回结果等直接拼接到LLM的提示词中(即In-Context Learning)。一些框架还会对记忆进行压缩或摘要,以节省上下文空间。
例如:
- • 用户连续提问:“南京天气怎么样?”→“那明天呢?” Agent需要记住刚刚提到的“南京”,才能理解第二次询问的是同一城市的天气。
- • Agent在执行多步任务时(如先查天气、再定酒店),需要将第一步的结果暂存,供后续步骤使用。
3.2 长期记忆
长期记忆用于跨会话持久化存储重要信息,使Agent能够在多次交互中记住用户、积累知识、学习新技能。
特点:
- • 容量近乎无限:借助外部存储系统(如数据库),可以存储海量信息。
- • 跨会话持久性:信息被保存下来,下次对话时可以重新调用。
- • 实现方式:通常采用向量数据库(如Pinecone、Chroma、Weaviate)+RAG(检索增强生成Retrieval Augment Generation)、关系型数据库、知识图谱(一种用图结构来组织和表示知识的数据模型)、模型微调(Fine-tuning,让LLM形成“肌肉记忆”)等。具体流程是:将文本(如用户偏好、领域知识)转化为特定的数据结构(如:向量),存入数据库;当需要回忆时,将当前问题也转为向量,在数据库中做相似性检索,召回最相关的内容,再放入短期记忆中供LLM使用。
例如:
- • 用户第一次使用时告诉Agent:“我喜欢读科幻小说。” 下次用户说“推荐一本书”,Agent会优先推荐科幻类书籍。
- • Agent在工作中学习了一套代码库的结构,下次处理类似项目时能直接调出相关模块的说明。

3.3 短期记忆和长期记忆的配合
短期和长期记忆不是孤立的,而是紧密配合:
-
- 用户输入进入短期记忆(当前对话上下文)。
-
- Agent根据用户问题和当前短期记忆,从长期记忆中检索相关信息(如用户偏好、历史对话摘要)。
-
- 检索到的信息被加入到短期记忆中,供LLM参考。
-
- LLM结合短期记忆(包括当前输入+检索到的长期记忆)进行推理和决策。
-
- 在对话过程中,Agent可能将重要的新信息写入长期记忆(如用户新透露的偏好、任务执行经验)。
记忆模块的核心作用
- • 个性化体验:让Agent记住每个用户的偏好,提供定制化服务。
- • 持续学习:Agent可以从每次交互中学习,不断丰富自己的知识库,避免重复犯错。
- • 上下文连贯:即使对话中断很久,也能无缝衔接,因为长期记忆保存了之前的要点。
- • 复杂任务支撑:对于需要多步推理的任务,短期记忆保证了中间结果的可用性。
4. 规划模块(Planning)
规划模块负责将模糊的目标转化为清晰的行动步骤,决定先做什么、后做什么,并在执行过程中根据新情况动态调整。正是规划能力,让Agent从“被动响应”进化到“主动解决问题”。
规划的第一步是任务分解,将大目标变成小任务。分解后,还需要决定这些任务的先后顺序(排序)、处理依赖关系(调度)。以及在执行过程中根据反馈调整计划(动态调整),甚至是从失败中学习(反思)。
Agent的规划模块并非一成不变,而是经历了一条从静态推理到动态交互,再到分层解耦和自我进化的演进路径。
| 阶段 | 核心范式 | 代表技术 | 核心思想 | 提出时间 |
|---|---|---|---|---|
| 阶段1 | 静态推理范式 | CoT(思维链) | 让模型在回答前生成中间推理步骤,但不与环境交互 | 2022 |
| 阶段2 | 动态交互范式 | ReAct | 推理与行动交替进行,边想边做 | 2022 |
| 阶段3 | 分层解耦范式 | Plan-and-Execute | 规划与执行分离,先想后做+动态调整 | 2023 |
| 阶段4 | 高级扩展范式 | ToT、Reflexion、MCTS | 多路径探索、自我反思、搜索式规划 | 2023-2024 |
注:范式是一个领域内被公认的、用于思考和解决问题的框架——它不是具体的代码或工具,而是指导我们如何设计、如何思考的一套方法论。
ReAct(Reasoning and Acting,thought->action->observation循环)与Plan-and-Execute的关系:
-
- 设计哲学:ReAct是“边想边做”,计划隐含在思考-行动循环中;Plan-and-Execute是“先想后做”,计划显式生成再执行。
-
- 灵活性 vs 稳定性:ReAct更灵活,能实时适应环境变化,但可能效率低或陷入循环;Plan-and-Execute更稳定,可解释性强,但可能无法应对计划外的变化。
-
- 是否互斥:不一定。有些系统结合两者,比如先用Plan-and-Execute生成高级计划,然后在执行每个步骤时用ReAct处理细节。
在实际项目中,不必拘泥于单一范式。可以构建混合架构——用Plan-and-Execute生成粗粒度计划,对计划中不确定性高的步骤(如“查资料”),内部用ReAct精细化执行。这样既保证了整体方向的可控性,又保留了局部执行的灵活性。
举个🌰假设Agent的任务是“组织一场公司团建活动”:
- • 纯Plan-and-Execute:先规划出完整方案(场地选择、餐饮预订、活动安排),然后逐一执行。如果预定场地时发现满员,计划可能卡住,需要人工介入。
- • 纯ReAct:每一步都思考:“现在该干什么?哦,先找场地……找到了,下一步订餐……” 虽然灵活,但可能绕弯路,且用户无法提前知晓整体方案。
- • 结合方案:先用Plan-and-Execute生成一个初步计划:“确定日期 → 预订场地 → 安排餐饮 → 设计活动”。执行“预订场地”这一步时,如果遇到满员,Agent立即启动ReAct模式,动态搜索替代场地、调整日期,甚至修改后续餐饮和活动安排。整个过程既保持了计划的框架,又具备了应变能力。
5. 工具使用(Tool Use)
在前几节中,我们介绍了Agent的大脑(LLM)、记忆(Memory)和规划(Planning)模块。但一个只会思考、不会行动的智能体,终究只是“纸上谈兵”。工具使用模块,正是Agent连接外部世界的桥梁,让它能够真正“动手”解决问题。
工具使用模块的核心作用是:赋予Agent调用外部工具的能力,以突破LLM自身的局限性。
LLM虽然强大,但存在三个天然短板:
-
- 知识截止日期:无法获取训练数据之后的新信息
-
- 无法访问私有数据:无法查询企业内部数据库、用户个人数据
-
- 缺乏执行能力:只能生成文本,无法操作外部系统
工具使用模块解决了这些问题。通过调用各种工具,Agent可以:
- • 获取实时信息:查询天气、股票价格、最新新闻
- • 操作外部系统:发送邮件、创建日历事件、操作数据库
- • 执行精确计算:调用计算器、代码解释器
- • 访问知识库:检索企业文档、专业数据库
通俗理解:如果把LLM比作一个博学的顾问,那么工具就是他的“手脚”和“感官”——让他不仅能说,还能查、能算、能做。
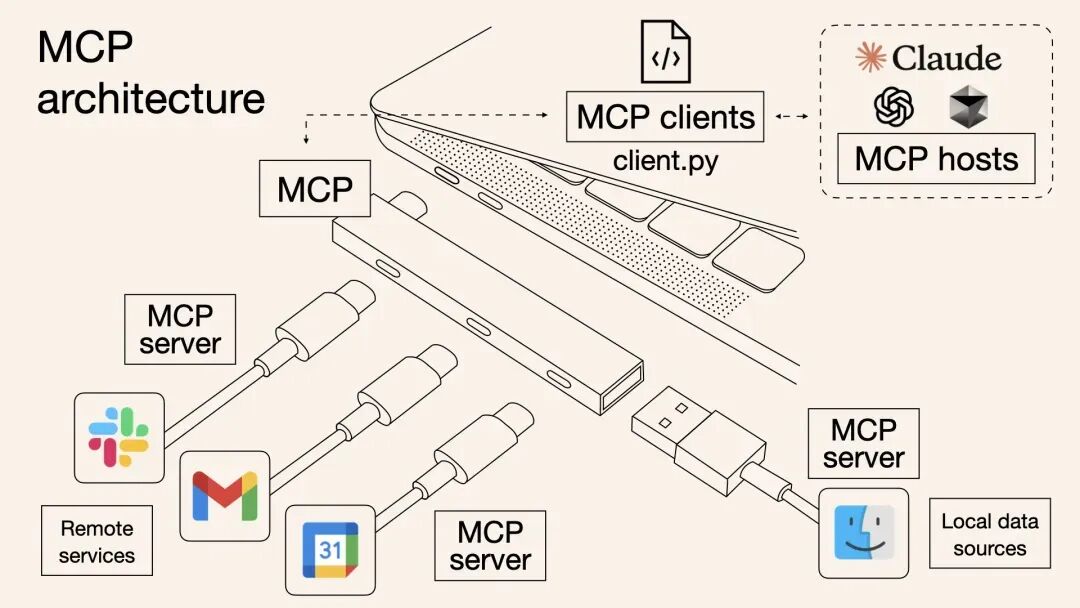
目前,工具使用主要有通过Function Calling(与外界交互的基本能力) + MCP协议(标准化外界交互)实现。
| 维度 | Function Calling | MCP协议 |
|---|---|---|
| 本质 | LLM的原生能力,一种调用机制 | 工具接入的标准化协议 |
| 定位 | 解决“如何调用”的问题 | 解决“如何接入”的问题 |
| 实现方 | LLM厂商提供支持 | 社区推动的开放标准 |
| 适用范围 | 单个函数的调用 | 整个工具生态的互联 |
| 与LLM关系 | LLM直接输出函数调用 | Agent作为客户端连接MCP服务器 |
在MCP出现之前,每个工具都需要单独适配:
- • 天气API有一套调用方式
- • 数据库查询有另一套方式
- • 企业内部系统又有自己的接口
开发者需要为每个工具编写适配代码,重复劳动且难以维护。MCP的出现,就是为了解决这个问题——标准化工具接入,让工具接入像插拔U盘一样简单。
6. Agent各模块的协同工作
在前面的章节中,我们逐一拆解了Agent的四大核心模块:大语言模型(LLM)、记忆模块(Memory)、规划模块(Planning) 和 工具使用(Tool Use)。它们各自承担着独特的职责——LLM负责理解与决策,记忆模块存储与检索信息,规划模块分解任务与动态调整,工具模块连接外部世界。
但一个真正的智能体,绝不是这四个模块的简单堆砌。真正的魔力,来自它们之间的无缝协同。就像一支交响乐团,每个乐手都有自己的乐谱,但只有当他们按照指挥的节奏默契配合时,才能奏出恢弘的乐章。
在宏观层面,Agent处理一个任务通常会经历以下五个阶段:
-
- 感知与理解:接收用户输入,LLM结合短期记忆(当前对话上下文)理解用户意图。
-
- 记忆检索:从长期记忆中召回与当前任务相关的历史信息或知识。
-
- 规划与决策:LLM作为“大脑”,基于当前状态(用户输入 + 短期记忆 + 检索到的长期记忆)进行推理,生成行动计划(可能涉及任务分解、步骤排序)。
-
- 执行与交互:按照计划调用外部工具(如搜索、API),获取实时信息或执行操作。
-
- 学习与更新:将本次交互中的重要信息(如用户偏好、新知识)存入长期记忆,供未来参考。
这个流程不是单向的直线,而是一个循环迭代的过程——Agent可能在执行某一步后,根据观察到的结果重新回到规划阶段,调整后续计划。
让我们用一个贯穿全篇的例子来展示这些模块如何协同工作。假设用户向Agent提出这样一个请求:“我下周末想去南京放松两天,喜欢安静的自然风光,预算2000元左右,帮我规划一下行程。”
第1步:感知与理解(LLM + 短期记忆)
- • 短期记忆:当前对话刚刚开始,短期记忆中只有用户这一条输入。
- • LLM:解析用户输入,提取关键要素:时间(下周末)、地点(南京)、偏好(安静、自然风光)、预算(2000元)、任务类型(行程规划)。LLM意识到这是一个需要多步操作的复杂任务,必须调用其他模块。
第2步:记忆检索(长期记忆)
- • 长期记忆:Agent查询向量数据库,看是否有与该用户或类似任务相关的历史记录。
- • 检索结果:发现该用户三个月前曾询问过“南京有什么小众景点”,当时用户提到“不喜欢人多的地方”。这个信息被召回,放入短期记忆,供后续参考。
第3步:规划与决策(规划模块 + LLM)
- • LLM(作为规划器):结合用户当前请求和历史偏好,LLM开始规划。它采用 Plan-and-Execute 的思路,先生成一个粗粒度的计划:
-
- 查询下周末南京的天气(影响户外活动安排)。
-
- 根据天气和“安静自然风光”的偏好,推荐合适的景点。
-
- 规划两天的行程顺序,估算交通和门票费用。
-
- 搜索预算内的住宿(人均2000元,住宿预算约1000元)。
-
- 整合所有信息,生成最终行程建议。
- • 规划模块:将这个计划记录在短期记忆中,作为后续执行的蓝图。同时,规划模块会监控每一步的执行状态。
第4步:执行与交互(工具使用 + 观察)
现在Agent开始按计划执行,但每一步都不是机械的——它会在每个行动后观察结果,动态调整。
子任务1:查询天气
- • 思考(LLM):第一步需要天气信息。我可以调用天气API。
- • 行动(工具模块):调用天气API,参数:南京,下周末。
- • 观察:API返回——周六多云,14-21℃;周日晴,15-22℃。非常适合户外活动。
- • 更新短期记忆:天气信息被暂存。
子任务2:推荐景点
- • 思考(LLM):天气很好,可以推荐自然风光类景点。需要从长期记忆中检索南京适合安静自然风光的景点,同时参考用户历史偏好(喜欢人少的地方)。
- • 行动(工具模块):查询内部知识库(或调用景点API),条件:南京,自然风光,评价“安静”“人少”。
- • 观察:返回候选列表——紫金山探险公园周边步道、中山植物园(南园)、明孝陵石象路、灵谷寺、清凉山公园、燕子矶公园。
- • 思考(LLM):需要筛选出真正安静且自然风光好的地方。紫金山区域有很多徒步路线,中山植物园植物丰富,明孝陵石象路秋季很美但可能人多,清凉山公园位于市区相对小巧,燕子矶有江景但稍远。结合用户“安静”偏好,优先选择紫金山深处的步道和植物园。
- • 更新短期记忆:候选景点列表(初步筛选:紫金山徒步道、中山植物园、灵谷寺)被暂存。
子任务3:规划行程与预算
- • 思考(LLM):需要安排两天的行程,避免奔波。紫金山区域景点集中,可以全部安排在钟山风景区内。第一天上午徒步紫金山(如从蒋王庙上山,经天文台到头陀岭),下午逛中山植物园;第二天游览灵谷寺和明孝陵石象路(尽量早去避开人流)。同时要考虑交通和餐饮预算。
- • 行动(工具模块):调用地图API,计算景点间的交通时间和费用;调用餐饮API,估算当地简餐人均价格。
- • 观察:紫金山各景点之间公交车或共享单车方便,单次票价2-3元;餐饮人均40-70元(鸭血粉丝汤、小笼包等)。
- • 思考(LLM):交通和餐饮预算可控。接下来需要找住宿,预算剩余约1500元(总预算2000 - 交通50 - 餐饮400 = 1550元),可住两晚品质不错的民宿。
- • 行动(工具模块):调用住宿API,搜索南京钟山风景区附近民宿,价格<700元/晚,评价“安静”“环境好”。
- • 观察:返回两家候选——A民宿(650元/晚,近下马坊,有庭院),B民宿(620元/晚,近孝陵卫,背靠紫金山)。
- • 思考(LLM):两家都符合预算和安静要求。可以给用户两个选择,并生成详细行程。
- • 更新短期记忆:所有收集到的信息(天气、景点、交通、住宿)都已齐备。
第5步:生成最终回答(LLM + 短期记忆)
- • LLM:整合短期记忆中所有中间结果,生成一份结构清晰、考虑周全的行程建议。
- • 最终回答(Agent输出):
根据你的需求(安静自然风光、预算2000元),我为你规划了以下南京周末行程:
Day1(周六)
上午抵达南京,建议入住A民宿(650元/晚,近下马坊)。下午从蒋王庙步道上紫金山,沿途森林茂密,游客较少,到达头陀岭可俯瞰南京城(全程约2-3小时)。下山后前往中山植物园南园,欣赏热带植物和宁静的湖景,傍晚在植物园附近品尝地道鸭血粉丝汤(人均40元)。
Day2(周日)
早餐后前往灵谷寺(公交202路直达),寺内古树参天,环境清幽,可登灵谷塔远眺。中午在灵谷寺素斋馆用简餐(人均50元)。下午游览明孝陵石象路(从灵谷寺步行或乘景区接驳车),这段路在清晨或傍晚人少时格外宁静,神道两侧的石兽和秋色(或四季常青)非常治愈。傍晚返程。
预算预估:住宿650 + 餐饮240 + 交通30 = 920元,远低于2000元预算。如果你更喜欢B民宿(620元/晚,近孝陵卫,背靠山林),也可以调整行程。
需要我帮你查询具体民宿的空房情况或预订吗?
第6步:学习与更新(长期记忆)
- • 本次交互的重要信息:用户对“安静”“人少”“自然风光”的偏好再次被强化;用户本次最终选择了A民宿(假设用户后续反馈)。
- • 写入长期记忆:Agent将“用户→偏好南京紫金山区域的安静徒步路线”“用户→倾向于选择有庭院的民宿”等信息存入向量数据库。下次该用户再提问时,Agent能提供更个性化的服务。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献78条内容
已为社区贡献78条内容

所有评论(0)