Learn to Explain: Multimodal Reasoning via Thought Chains for Science Question Answering

这是一篇由加州大学洛杉矶分校、亚利桑那州立大学与艾伦人工智能研究所(AI2)联合撰写的研究论文,发表于NeurIPS 2022,核心聚焦科学问题问答场景中的多模态推理与可解释性。论文提出了大规模多模态科学问答数据集 SCIENCEQA,首次为科学问题标注了配套的 “讲义(Lecture)” 与 “解释(Explanation)”,并设计了基于思维链(Chain-of-Thought, CoT)的语言模型,通过生成讲义和解释模拟人类多步推理过程,显著提升了模型在科学问答任务中的性能与可解释性。
一、研究背景与核心问题
1.1 研究动机
AI 系统的长期目标是像人类一样可靠决策并高效学习复杂任务。人类在解决问题时会遵循明确的思维链推理过程,并通过解释表达出来;而传统深度学习模型多为 “黑箱”,仅输出最终结果,无法揭示推理逻辑,难以验证其对任务的理解程度与泛化能力。
在科学问题问答领域,现有研究存在明显不足:
- 数据集缺陷:要么缺乏答案的解释标注,要么局限于单一文本模态,且规模小、领域多样性有限;
- 模型局限:现有多模态方法难以同时理解多模态内容、整合外部知识并完成多跳推理,且生成结果缺乏可解释性。
科学问题问答需要领域特定知识与显式多跳推理,模型若无法提供解释,其可靠性与可信任度将大打折扣。因此,亟需构建含解释标注的多模态科学问答数据集,并探索能生成思维链的模型方法。
1.2 核心问题
- 如何构建覆盖多模态、多领域、大规模的科学问答数据集,并为答案提供详细的推理解释标注?
- 语言模型能否通过生成思维链(讲义 + 解释)模拟人类推理过程,提升科学问答的性能与可解释性?
- 思维链在少样本学习与微调场景中,是否能帮助模型更高效地学习(用更少数据达到相当性能)?
1.3 研究贡献
- 构建了SCIENCEQA 数据集:包含 21,208 个多模态选择题,覆盖自然科学、社会科学、语言科学三大领域,首次为大部分问题标注了 “讲义(通用背景知识)” 与 “解释(具体推理过程)”;
- 验证了思维链的有效性:在少样本(GPT-3)与微调(UnifiedQA)场景中,生成思维链均能提升模型问答性能,且 65.2% 的生成解释达到人类标注标准;
- 探索了数据效率优势:思维链能帮助模型高效学习,UnifiedQA(CoT)仅用 40% 的训练数据,即可达到无 CoT 模型用全量数据的性能。
二、SCIENCEQA 数据集构建
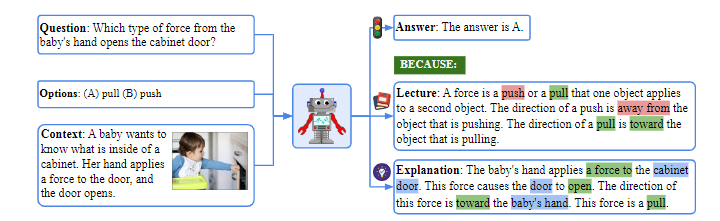
SCIENCEQA 是首个大规模多模态科学问答数据集,专为评估模型的多模态理解、多跳推理与可解释性设计,数据来源于 K-12 科学课程,确保了领域多样性与教育场景适配性。
2.1 数据集核心特征
每个数据样本包含 “问题 - 选项 - 多模态上下文 - 正确答案 - 讲义 - 解释” 六部分,结构如图 1 所示:
- 问题(Question):覆盖三大领域的科学问题,长度 3-141 词,平均 12.11 词;
- 选项(Options):2-5 个选项,平均 4.40 词;
- 多模态上下文(Context):包括文本上下文(48.2%)、图像上下文(48.7%,含自然图像 14.0%、图表 34.8%)、两者皆有(30.8%)或无上下文(33.9%);
- 讲义(Lecture):83.9% 的样本包含,提供解决同类问题的通用背景知识;
- 解释(Explanation):90.5% 的样本包含,揭示针对该问题的具体推理过程。
2.2 数据集规模与分布
表格
| 统计指标 | 数值 | 关键说明 |
|---|---|---|
| 总问题数 | 21,208 | 含 9,122 个独特问题 |
| 领域覆盖 | 3 大主题、26 个子话题、127 个类别、379 项技能 | 自然科学(如物理、生物)、社会科学(如历史、经济)、语言科学(如语法、修辞) |
| 上下文类型 | 文本 10,220 个、图像 10,332 个、两者皆有 6,532 个 | 图像含图表、自然场景图,文本含说明性文字、数据描述 |
| 标注覆盖率 | 讲义 17,798 个(83.9%)、解释 19,202 个(90.5%) | 讲义提供通用知识,解释对应具体推理链 |
| 数据拆分 | 训练集 12,726 个、验证集 4,241 个、测试集 4,241 个 | 拆分比例 60:20:20,确保分布一致性 |
2.3 与现有数据集的差异
SCIENCEQA 在规模、模态、领域多样性、标注完整性上均超越现有科学问答数据集:
- 多模态支持:同时包含文本与图像上下文,适配真实科学问题的多模态表达需求;
- 领域覆盖广:突破仅自然科学的局限,新增社会科学与语言科学,涵盖更多技能点;
- 标注更丰富:首次大规模提供 “讲义 + 解释” 双标注,支持可解释性评估;
- 适配教育场景:问题来源于 K-12 课程,覆盖 1-12 年级,难度梯度合理。
三、模型设计:基于思维链的科学问答
论文设计了两类基于思维链的模型,分别适配少样本(GPT-3)与微调(UnifiedQA)场景,核心思路是让模型生成 “答案 + 讲义 + 解释” 的组合输出,模拟人类推理过程。
3.1 基线模型
为全面评估思维链的优势,设置了多类基线:
- 启发式基线:随机选择(Random Chance)、人类表现(Amazon Mechanical Turk 标注,平均准确率 88.40%);
- 零样本 / 少样本基线:UnifiedQA(零样本)、GPT-3(零样本 / 2-shot,无思维链);
- 微调基线:VQA 模型(如 VisualBERT、ViLT、Patch-TRM)、UnifiedQA(微调,无思维链)。
3.2 思维链模型设计
(1)UnifiedQA(CoT):微调场景
UnifiedQA 是文本问答 SOTA 模型,原始输出仅为答案。论文对其进行格式修改,微调后生成 “答案 + 讲义 + 解释” 的长文本序列,具体格式为:
The answer is [选项]. BECAUSE: [讲义内容] [解释内容]
通过这种方式,模型在输出答案的同时,必须完成思维链的生成,强制其模拟多步推理过程。
(2)GPT-3(CoT):少样本场景
采用思维链提示(Chain-of-Thought Prompting),在提示中包含 “问题 - 选项 - 上下文 - 答案 + 讲义 + 解释” 的示例,引导模型在少样本情况下生成思维链。提示格式如图 5 所示,核心是让模型学习 “先推理(生成讲义 + 解释)、后输出答案” 的逻辑(实际输出顺序为 “答案 + BECAUSE + 讲义 + 解释”)。
3.3 评估指标
- 问答性能:准确率(Accuracy),对于生成式模型(如 GPT-3、UnifiedQA),通过匹配最相似选项确定预测结果;
- 解释质量:自动指标(BLEU-1/4、ROUGE-L、语义相似度)+ 人类评估(相关性、正确性、完整性,三者均满足则为 “黄金标准解释”)。
四、实验结果与分析
实验分为三大核心部分:问答性能评估、解释质量评估、思维链的附加价值分析(数据效率、少样本提升等)。
4.1 问答性能核心结果
(1)整体性能排名(测试集准确率)
表格
| 模型类型 | 模型名称 | 平均准确率 | 关键提升 |
|---|---|---|---|
| 人类表现 | - | 88.40% | 基准上限 |
| 少样本模型 | GPT-3(CoT,2-shot) | 75.17% | 比无 CoT 提升 1.20% |
| 微调模型 | UnifiedQA(CoT,QCM→ALE) | 74.11% | 比无 CoT 提升 3.99% |
| VQA 模型 | VisualBERT | 61.87% | 多模态模型最优,但远低于语言模型 + CoT |
| 随机基线 | - | 39.83% | 最低性能基准 |
关键结论:
- 语言模型 + 思维链显著超越 VQA 模型,证明在科学问答中,文本推理(尤其是思维链)比单纯多模态融合更重要;
- GPT-3(CoT)在少样本场景下达到 75.17%,接近微调模型性能,体现了思维链在少样本学习中的优势;
- UnifiedQA(CoT)微调后性能提升 3.99%,验证了思维链在有监督场景中的有效性。
(2)不同维度性能分析
- 领域维度:自然科学(NAT)准确率最高(GPT-3(CoT)达 75.44%),社会科学(SOC)最低(66.09%),因社会科学需更多常识与上下文整合;
- 上下文维度:文本上下文(TXT)任务准确率最高(77.55%),图像上下文(IMG)最低(66.42%),因图像 caption 存在信息损失;
- 年级维度:1-6 年级(G1-6)准确率(76.80%)高于 7-12 年级(68.89%),高年级问题需更复杂的领域知识。
4.2 解释质量评估
(1)自动指标结果
表格
| 模型 | 格式 | BLEU-1 | BLEU-4 | ROUGE-L | 语义相似度 |
|---|---|---|---|---|---|
| UnifiedQA(CoT) | QCM→ALE | 0.397 | 0.370 | 0.714 | 0.811 |
| GPT-3(CoT) | QCM→ALE | 0.192 | 0.052 | 0.323 | 0.595 |
UnifiedQA(CoT)的生成解释在自动指标上更接近人类标注,但自动指标仅能反映部分质量。
(2)人类评估结果
人类标注员从 “相关性、正确性、完整性” 三方面评估,结果如下:
表格
| 模型 | 相关率 | 正确率 | 完整率 | 黄金标准占比(三者均满足) |
|---|---|---|---|---|
| UnifiedQA(CoT) | 80.4% | 76.6% | 76.1% | 56.9% |
| GPT-3(CoT) | 88.5% | 78.8% | 84.5% | 65.2% |
关键结论:GPT-3(CoT)生成的解释更符合人类判断,65.2% 达到 “黄金标准”,证明思维链能有效提升模型的可解释性。
4.3 思维链的附加价值分析
(1)少样本学习上限探索
将人类标注的 “讲义 + 解释” 直接作为输入(而非让模型生成),GPT-3 的少样本准确率提升至 94.13%,比基础 CoT 模型(75.17%)提升 18.96%,证明解释中蕴含的推理信息尚未被模型完全利用,思维链仍有巨大优化空间。
(2)数据效率优势
如图 8 所示,UnifiedQA(CoT)在训练数据比例仅为 40% 时,准确率已达到无 CoT 模型用 100% 数据的水平,证明思维链能帮助模型更高效地学习,减少对训练数据的依赖。
(3)提示格式与示例数量影响
- 提示格式:同时包含讲义与解释的提示(QCM→ALE)性能最优且稳定性最强,仅含解释的提示(QCM→AE)方差较大;
- 示例数量:2-shot 提示效果最佳(GPT-3(CoT)达 75.17%),超过 2 个示例后性能下降,因提示长度增加导致信息冗余。
4.4 错误分析
模型失败案例主要分为两类:
- 多模态理解不足:图像 caption 缺乏细粒度信息(如图表数据、复杂场景细节),导致模型无法获取关键证据;
- 领域知识与推理缺陷:缺乏冷门领域知识(如语言科学中的拟人修辞术语),或生成的思维链存在逻辑错误(如混淆物理变化与化学变化)。
五、相关工作对比
表格
| 研究方向 | 代表工作 | 与本文核心差异 |
|---|---|---|
| 视觉问答(VQA) | VQA、GQA、CLEVR | 聚焦通用视觉问答,无科学领域适配性,缺乏解释标注 |
| 科学问答数据集 | AI2D、TQA、VLQA | 规模小、模态单一(多为文本或图表)、无完整的讲义 + 解释标注 |
| 思维链推理 | Wei et al. (2022)、Nye et al. (2021) | 多聚焦数学推理或纯文本任务,未探索多模态科学问答场景,且无大规模带解释标注的数据集 |
| 从解释中学习 | Mishra et al. (2021)、Narang et al. (2020) | 未结合多模态场景,且未系统验证思维链在少样本与微调场景中的双重优势 |
本文的核心创新在于:首次构建多模态 + 解释标注的科学问答数据集,并全面验证了思维链在多场景下的性能提升、可解释性增强与数据效率优势。
六、局限性与未来方向
6.1 局限性
- 图像信息损失:模型依赖图像 caption 获取视觉信息,caption 无法完全保留图像细节(如图表数据、复杂结构),影响多模态推理性能;
- 解释质量不均:部分生成的解释存在相关性不足、逻辑不完整问题,尤其是在复杂多跳推理场景;
- 领域覆盖局限:虽涵盖三大领域,但未涉及高等科学知识,且多为选择题,未支持开放式问答。
6.2 未来方向
- 优化多模态融合:直接处理图像特征,避免 caption 信息损失,提升复杂图像(如图表、示意图)的理解能力;
- 提升解释质量:设计更精细的思维链提示策略,或通过强化学习优化解释的相关性与完整性;
- 扩展任务场景:支持开放式科学问答、复杂科学问题求解(如实验设计、公式推导),覆盖更广泛的教育与科研场景。
七、结论
论文通过构建 SCIENCEQA 数据集与基于思维链的模型,系统探索了多模态科学问答的性能与可解释性优化路径。核心结论如下:
- 思维链能有效提升模型的科学问答性能,在少样本(GPT-3)与微调(UnifiedQA)场景中均有显著效果;
- 生成的思维链具有高可解释性,65.2% 的解释达到人类标注标准,为模型推理过程提供了透明化依据;
- 思维链能提升模型的数据效率,帮助模型用更少数据完成高效学习,为低资源场景下的模型优化提供了新思路。
SCIENCEQA 数据集与思维链方法为科学问答领域的研究提供了标准化工具与核心范式,对教育智能辅导、科学研究辅助等真实场景的落地具有重要参考价值。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)