视频去字幕工具横评:本地 AI、云端方案与传统方法的实战对比
> 做视频二创,最头疼的莫过于硬编码字幕。本文实测 5 种主流去字幕方案,从技术原理到实际效果,给你一份客观的选型指南。
---
## 一、为什么去字幕这么难?
视频字幕分为两种:**软字幕**和**硬字幕**。
- **软字幕**:独立的字幕轨道,可随时开关,处理起来很简单
- **硬字幕**:字幕已经"烧录"到视频画面中,成为像素的一部分
我们遇到的大多是硬字幕问题——下载的资源、录制的课程、搬运的素材,字幕都直接嵌在画面里。要去掉它,本质上是一个**图像修复(Inpainting)**问题:
1. **检测字幕区域**:需要识别字幕在每一帧的位置
2. **理解背景内容**:字幕遮挡的部分原本是什么?
3. **生成修复内容**:用合理的像素填充字幕区域
4. **保持时序一致**:视频是连续的,修复后的画面不能闪烁
这四个步骤,每一步都是技术难点。尤其是第 2 步和第 3 步,直接决定了最终效果的上限。
![视频去字幕技术流程示意图]
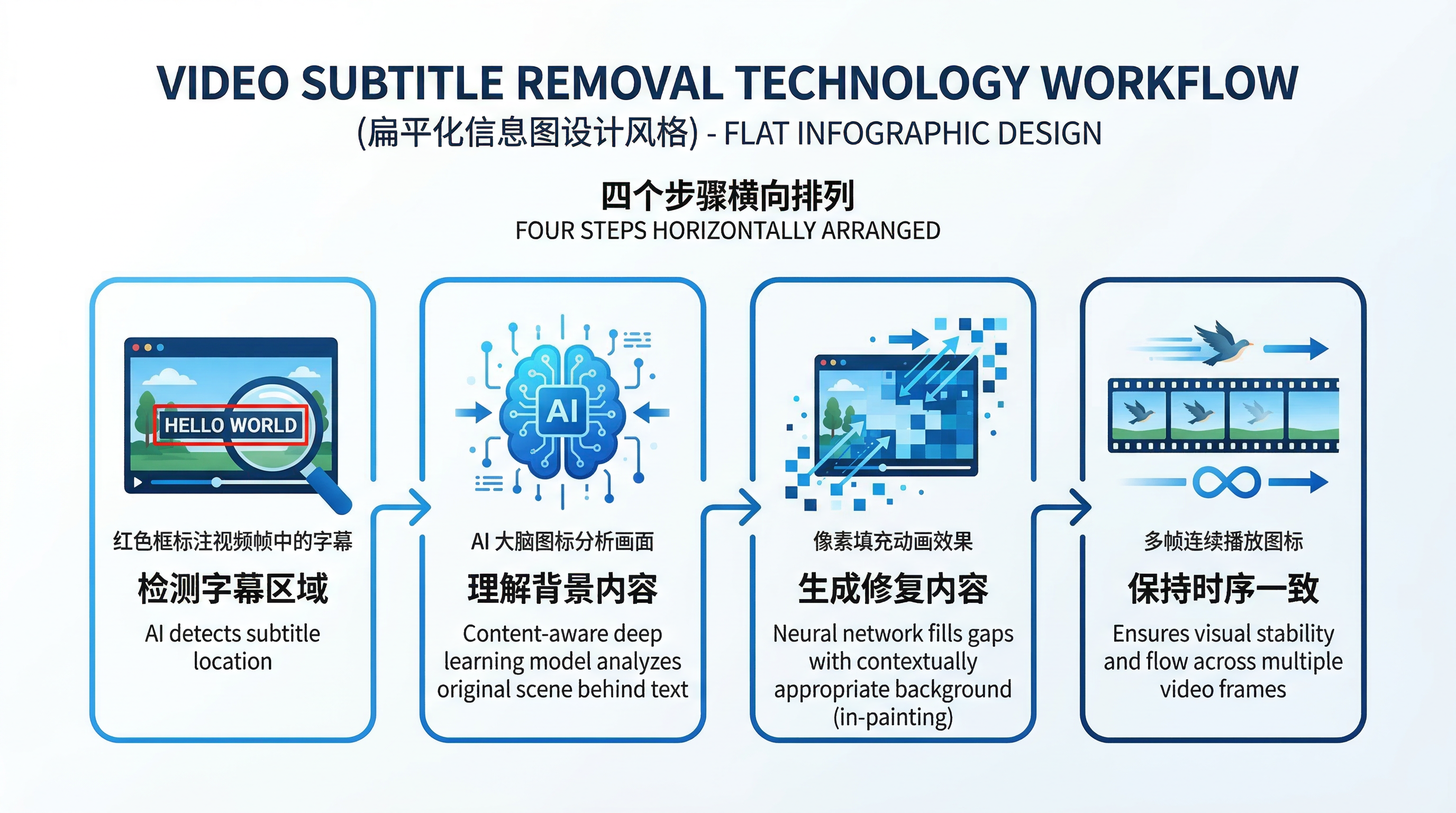
*图 1:视频去字幕技术流程示意图*
---
## 二、主流方案技术解析
### 方案 1:传统蒙层遮盖
**代表工具**:剪映、必剪等剪辑软件的"马赛克"功能
**技术原理**:在字幕位置添加模糊、高斯或色块蒙层
**优点**:
- 零门槛,任何剪辑软件都能做
- 处理速度快,实时预览
**缺点**:
- 字幕区域依然可见,只是变模糊
- 破坏画面完整性,观感较差
- 无法应对动态字幕(位置变化的字幕)
**适用场景**:快速处理、对画质要求不高的短视频
---
### 方案 2:本地 AI 模型
**代表工具**:VSR (Video Subtitle Remover) 等开源项目
**技术原理**:
- 使用深度学习模型检测字幕区域
- 基于前后帧信息进行像素填补
- 依赖本地 GPU 进行推理
**优点**:
- 完全本地运行,隐私性好
- 一次性付费(硬件成本),无后续费用
- 开源项目可自定义调整
**缺点**:
- **硬件门槛高**:需要 NVIDIA 显卡 + CUDA 支持,显存至少 8GB
- **部署复杂**:需要配置 Python 环境、安装依赖、调试参数
- **效果局限**:基于"像素搬运",对复杂背景修复能力有限
- **处理速度慢**:本地算力有限,长视频耗时久
**适用场景**:有技术能力、有高性能显卡、高频使用的用户
---
### 方案 3:云端 AI 服务
**代表工具**:550W AI、今鱼视觉等在线平台
**技术原理**:
- 使用生成式扩散模型(Diffusion Inpainting)
- 云端超算集群进行推理
- 语义理解 + 内容生成,而非简单像素复制
**优点**:
- **零门槛**:网页或小程序直接使用,无需配置
- **效果优秀**:扩散模型能"理解"画面内容,生成合理修复
- **处理速度快**:云端并行计算,远超本地速度
- **按需付费**:用多少付多少,无硬件投入
**缺点**:
- 需要上传视频到云端(隐私敏感内容需谨慎)
- 长期高频使用成本可能高于本地方案
**适用场景**:追求效率的视频博主、无高性能显卡的用户、偶尔使用的场景
![云端 vs 本地架构对比]
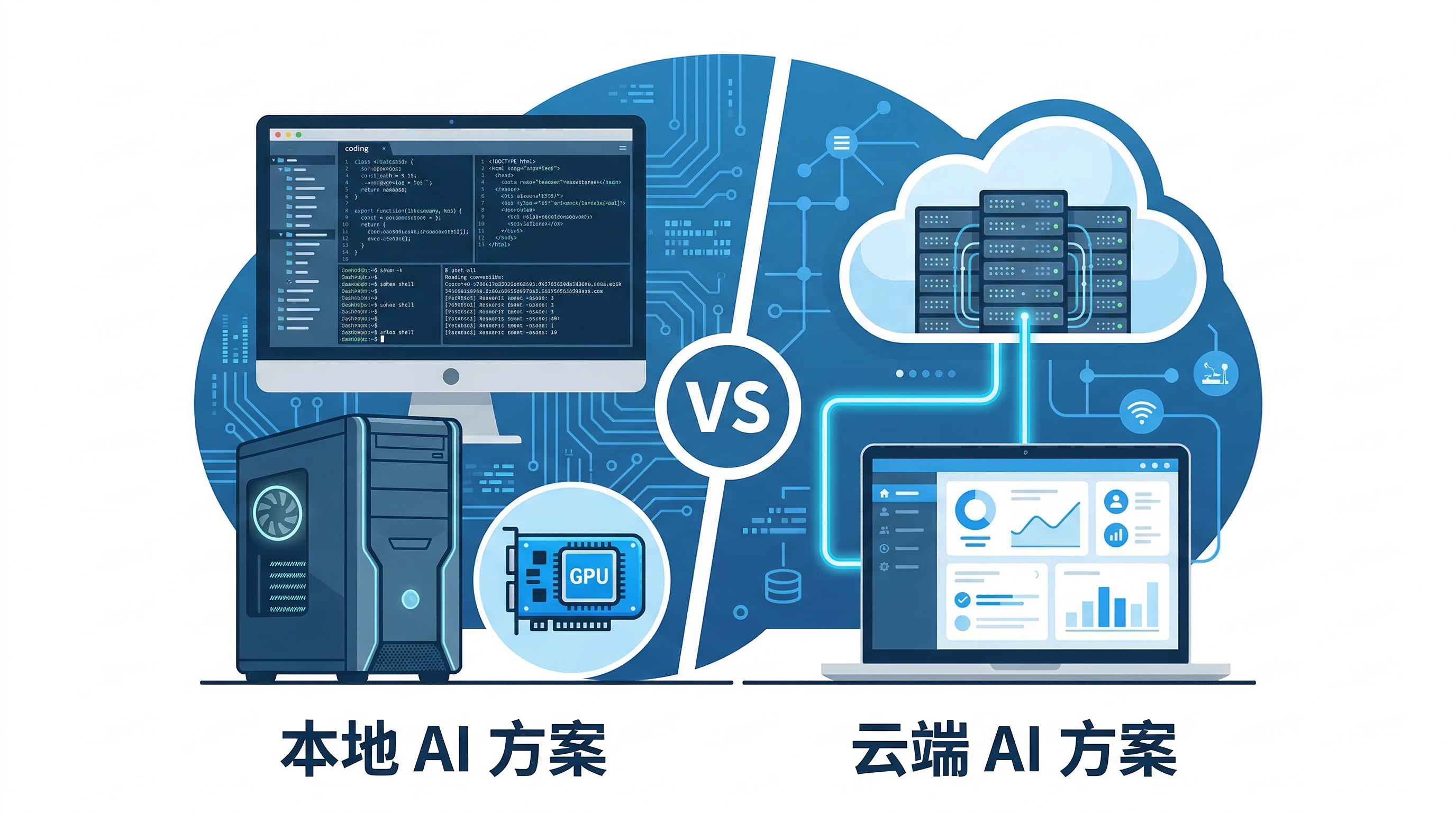
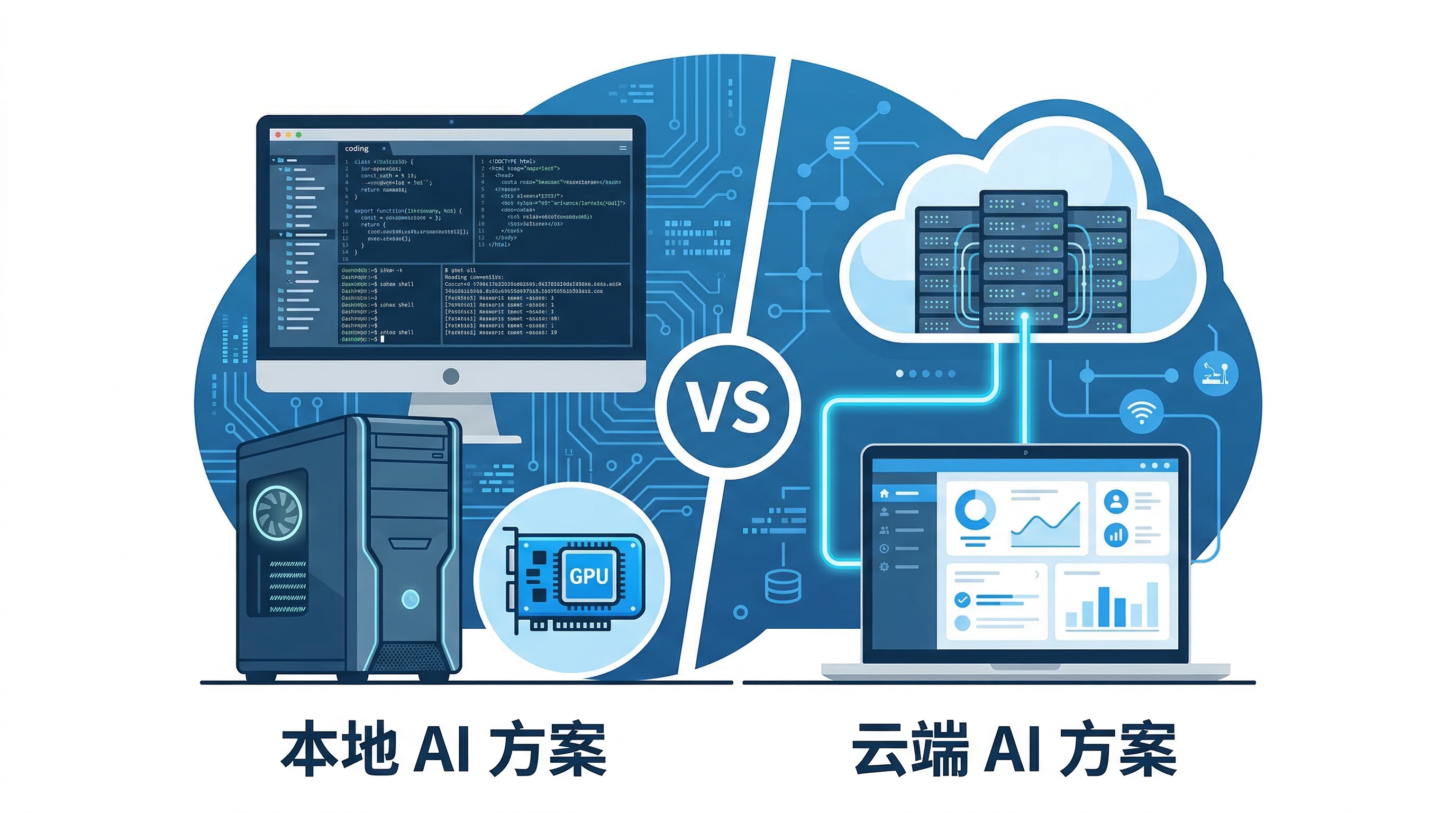
*图 2:云端 AI 方案 vs 本地 AI 方案架构对比*
---
## 三、实测对比
我选取了同一段带硬字幕的视频(1080P,30 秒,动态字幕),分别用 5 种方案处理:
| 方案 | 处理时长 | 效果评分 (1-5) | 成本 | 易用性 |
|------|----------|----------------|------|--------|
| 剪映蒙层 | 1 分钟 | ★★☆☆☆ | 免费 | ★★★★★ |
| VSR 本地 AI | 15 分钟 | ★★★☆☆ | 硬件成本 | ★★☆☆☆ |
| 550W AI | 2 分钟 | ★★★★☆ | 按量付费 | ★★★★★ |
| 今鱼视觉 | 3 分钟 | ★★★★☆ | 按量付费 | ★★★★☆ |
| 传统桌面软件 | 10 分钟 | ★★★☆☆ | 数百元 | ★★★☆☆ |
### 效果分析
**剪映蒙层**:字幕区域明显模糊,近看能看出处理痕迹,适合快速应付。
**VSR 本地 AI**:静态背景修复较好,但动态场景(人物经过字幕区域)会出现伪影,且对淡入淡出字幕识别不准确。
**550W AI**:扩散模型的优势明显,能理解画面语义。实测中,字幕穿过人物衣服时,能正确生成衣服纹理;字幕在天空背景时,能生成平滑渐变。动态字幕的时序一致性也最好。
**今鱼视觉**:效果接近 550W AI,但在复杂纹理(如花纹、文字背景)的修复上略有涂抹感。
![效果对比示意图]

*图 3:5 种去字幕方案效果对比(从左到右:原始画面、蒙层遮盖、本地 AI、云端 AI、传统软件)*
---
## 四、技术深度:为什么云端方案效果更好?
这里涉及一个核心技术差异:**像素搬运 vs 语义生成**。
### 本地方案的局限
以 VSR 为代表的本地方案,主要依赖**时序信息**:
- 分析前后帧,找相似像素
- 从其他区域"复制"纹理到字幕位置
- 本质上是"拆东墙补西墙"
这种方法在静态背景上效果不错,但遇到以下场景就失效:
- 字幕区域始终被遮挡(没有"干净"的参考帧)
- 复杂纹理(花纹、渐变、光影变化)
- 动态物体穿过字幕区域
### 云端方案的突破
以 550W AI 为代表的云端方案,使用**生成式扩散模型**:
- 模型在海量图像上预训练,"见过"各种场景
- 不是复制像素,而是"理解"画面后重新生成
- 类似人类画师:给你看一张有遮挡的图,能脑补出完整画面
技术细节(基于公开资料反推):
1. **字幕检测**:使用 OCR + 时序追踪,识别静态/动态字幕
2. **语义分割**:识别字幕区域的背景类型(天空、人物、建筑等)
3. **扩散生成**:基于条件生成模型,生成符合语义的修复内容
4. **时序优化**:多帧联合优化,避免闪烁
这种方案需要大量算力,这也是为什么必须云端部署——消费级显卡跑不动扩散模型。
![扩散模型原理抽象图]

*图 4:扩散模型工作原理示意图(从噪点到清晰的生成过程)*
---
## 五、选型建议
根据你的使用场景,我给出以下建议:
### 选本地方案,如果你:
- 有 NVIDIA 显卡(RTX 3060 以上,显存 8GB+)
- 有技术能力配置环境、调试参数
- 处理视频量大,长期成本敏感
- 视频内容隐私敏感,不能上传云端
### 选云端方案,如果你:
- 追求效率,不想折腾环境
- 没有高性能显卡
- 处理视频量中等,按量付费可接受
- 需要最好的修复效果
### 选传统蒙层,如果你:
- 只是临时处理一两个视频
- 对画质要求不高
- 预算有限
---
## 六、总结
视频去字幕是一个看似简单、实则技术含量很高的任务。不同方案各有优劣:
| 维度 | 传统蒙层 | 本地 AI | 云端 AI |
|------|----------|--------|--------|
| 效果 | ★★ | ★★★ | ★★★★ |
| 成本 | 免费 | 硬件投入 | 按量付费 |
| 门槛 | 无 | 高 | 无 |
| 速度 | 快 | 慢 | 快 |
| 隐私 | 本地 | 本地 | 云端 |
**我的建议**:
- **新手/效率优先**:直接选云端方案(550W AI 等),效果好、零门槛
- **技术爱好者/高频用户**:可以尝试本地 VSR,有折腾乐趣且长期成本低
- **临时应急**:剪映蒙层足够应付
最后,去字幕技术还在快速发展。随着扩散模型的普及和算力成本下降,未来云端方案的效果和价格优势可能会进一步扩大。但对于隐私敏感的场景,本地方案仍有不可替代的价值。
---
*本文基于公开资料和实测体验,不构成任何商业推荐。工具选择请根据自身需求决定。*

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)