【2026 最新】Spaceship Titanic Kaggle 入门实战:从数据清洗到 XGBoost 交叉验证
大家好!我是保禄,今天带大家刷一遍 Kaggle 经典入门题 Spaceship Titanic(太空旅客预测)
前文:

欢迎来到2912年,在这里,你的数据科学技能被需要来破解宇宙之谜。我们收到了来自四光年外的传输,情况不妙。
泰坦尼克号是一艘一个月前下水的星际客轮。船上载有近13,000名乘客,首次航行,将来自太阳系的移民运送到三颗新可居住的系外行星,这些行星环绕着附近恒星运行。
在绕行半人马座阿尔法星前往第一个目的地——炎热的55坎克里E号时,这艘不小心的泰坦尼克号飞船撞上了隐藏在尘埃云中的时空异常。遗憾的是,它最终遭遇了与千年前同名者相似的命运。虽然飞船完好无损,但近一半的乘客被传送到了另一个维度!
为了帮助救援队伍和找回失踪乘客,你必须利用从飞船受损计算机系统中回收的记录,预测哪些乘客被异常现象运送。
帮助拯救他们,改变历史!
很多新手刚接触这个比赛时,容易遇到三个问题:
- 特征工程不知道从哪下手,只会用原始数据跑模型
- 模型评估只靠简单的
train和test的原始文件,成绩波动大 - XGBoost 版本报错(这也是我调代码时遇到最多的坑,主要是版本更新问题)
这篇文章会用 Jupyter Notebook 分步实战的方式,一次性解决这些问题,带你搭建一个稳健的 Baseline
一、环境准备与数据加载
我们还是采用conda的环境去进行虚拟环境配置,方便我们管理环境,具体如何配置见我的上篇博客:【机器学习实战】泰坦尼克号存活率预测(基于Jupyter Notebook完整教程,准确率85%+)_泰坦尼克号 机器学习-CSDN博客
首先,我们把需要的库都导进去,并且解决中文绘图乱码的问题。
1.1 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from xgboost import XGBClassifier, plot_importance
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.metrics import accuracy_score
# 设置绘图风格(解决中文显示问题)
sns.set_style('whitegrid')
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 忽略警告
import warnings
warnings.filterwarnings('ignore')
print("环境初始化完成!")1.2 加载数据
去 Kaggle 官网把数据下载下来,解压后放在 data 文件夹里。
这里附上kaggle的数据下载链接官网:Spaceship Titanic | Kaggle
# 加载数据
train_df = pd.read_csv('data/train.csv')
test_df = pd.read_csv('data/test.csv')
print("训练集形状:", train_df.shape)
print("测试集形状:", test_df.shape)运行结果示例:
训练集形状: (8693, 14)
测试集形状: (4277, 13)
二、简单的探索性数据分析 (EDA)
在 Notebook 里,我们要养成 “边看数据边思考” 的习惯。
2.1 先看一眼数据长啥样
# 查看前 5 行
train_df.head()
2.2 检查缺失值
这步非常重要,太空旅客数据集的缺失值还是挺多的。
# 查看缺失值情况
print("训练集缺失值统计:")
train_df.isnull().sum().sort_values(ascending=False).head(10)2.3 可视化标签分布
看看 “被传送” 和 “没被传送” 的人是不是差不多,这决定了我们能不能用准确率(Accuracy)当评估指标。
# 可视化:标签分布
plt.figure(figsize=(6, 4))
sns.countplot(x='Transported', data=train_df)
plt.title('乘客传送情况分布 (Transported)')
plt.show()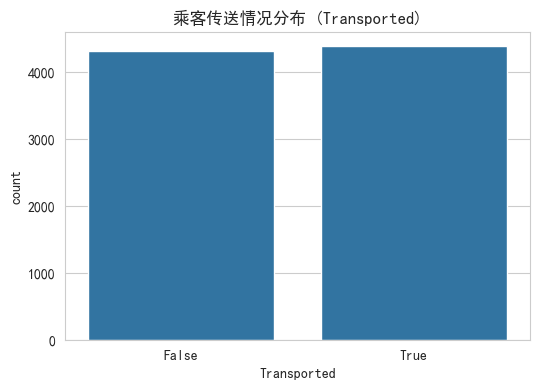
我们来看看 CryoSleep(休眠状态)这个特征,直觉上休眠的人可能更容易被传送?
# 可视化:休眠状态 vs 传送情况
plt.figure(figsize=(6, 4))
sns.countplot(x='CryoSleep', hue='Transported', data=train_df)
plt.title('休眠状态 (CryoSleep) 与传送的关系')
plt.show()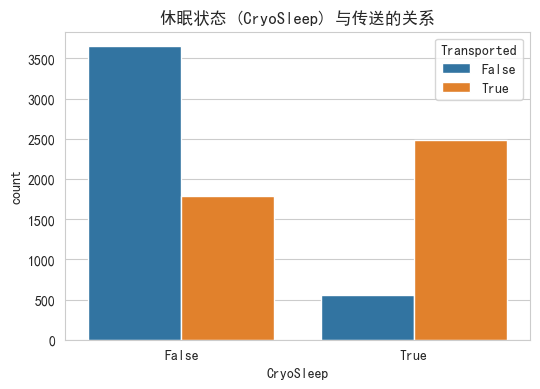
结论: 果不其然!休眠的人大部分都被传送了,这个特征非常重要。
三、特征工程
这一步我们把训练集和测试集拼在一起处理,保证编码一致性。
# 先保存一下原始测试集(最后提交要用来取 PassengerId)
original_test_df = test_df.copy()
# 合并训练集和测试集
all_df = pd.concat([train_df, test_df], axis=0, ignore_index=True)
print(f"合并后总数据量: {all_df.shape}")3.2 提取新特征
原始数据虽然只有 13 列,但我们可以通过组合提取出更多有用的信息。
# ====== 1. 提取新特征 ======
# 1.1 从 PassengerId 提取 Group (组号) 和 GroupSize (组队人数)
# 思路:一起旅行的人(同组)可能会一起被传送
all_df['Group'] = all_df['PassengerId'].apply(lambda x: x.split('_')[0])
all_df['GroupSize'] = all_df.groupby('Group')['Group'].transform('count')
# 1.2 计算总消费金额
# 思路:把所有消费加起来,看一个人的总消费能力
money_cols = ['RoomService', 'FoodCourt', 'ShoppingMall', 'Spa', 'VRDeck']
all_df['TotalSpent'] = all_df[money_cols].sum(axis=1)
all_df['IsSpent'] = (all_df['TotalSpent'] > 0).astype(int) # 是否消费过
# 1.3 拆分 Cabin (甲板/房间号/舷侧)
# 思路:原始 Cabin 是 "B/0/P" 这种格式,拆成三个单独特征
all_df['Cabin'] = all_df['Cabin'].fillna('Unknown/Unknown/Unknown')
cabin_split = all_df['Cabin'].str.split('/', expand=True)
all_df['Deck'] = cabin_split[0]
all_df['Num'] = pd.to_numeric(cabin_split[1], errors='coerce')
all_df['Side'] = cabin_split[2]
print("新特征提取完成!")3.3 缺失值填充
针对不同类型的列,我们用不同的填充策略。
# ====== 2. 缺失值填充 ======
# 数值型:中位数 (不受极端值影响)
num_cols = ['Age', 'Num'] + money_cols
for col in num_cols:
all_df[col] = all_df[col].fillna(all_df[col].median())
# 分类型:众数 (出现次数最多的那个)
cat_cols = ['HomePlanet', 'Destination', 'Deck', 'Side']
for col in cat_cols:
all_df[col] = all_df[col].fillna(all_df[col].mode()[0])
# 布尔型:特殊处理 (统一转 0/1)
bool_cols = ['VIP', 'CryoSleep']
for col in bool_cols:
all_df[col] = all_df[col].astype(str).str.lower().map({'true': True, 'false': False})
all_df[col] = all_df[col].fillna(False).astype(int)
print("缺失值填充完成!")3.4 编码与收尾
把分类变量变成数值变量,然后拆分回训练集和测试集。
# ====== 3. 编码与收尾 ======
# 独热编码 (One-Hot Encoding)
all_df = pd.get_dummies(all_df, columns=['HomePlanet', 'Destination', 'Deck', 'Side'])
# 删除无用列
drop_cols = ['PassengerId', 'Name', 'Cabin', 'Group']
all_df = all_df.drop(columns=drop_cols)
# 拆分回训练集和测试集
train_processed = all_df.iloc[:len(train_df)].copy()
test_processed = all_df.iloc[len(train_df):].copy()
print(f"处理后训练集形状: {train_processed.shape}")
print(f"处理后测试集形状: {test_processed.shape}")四、模型训练
这里我用了 5 折分层交叉验证,他比简单的划分训练 / 验证集更稳健。
那什么是五折分层交叉验证了?
五折分层交叉验证(5-Fold Stratified Cross-Validation),是结合了 5 折交叉验证与分层抽样的机器学习模型评估方法,核心解决普通随机交叉验证在类别不平衡数据集上的分布偏移问题,保证每一折的标签类别分布与原始全集完全一致,最终得到更稳定、无偏的模型泛化性能评估结果。
适用与不适用场景
- ✅ 适用场景:所有分类任务(二分类 / 多分类),尤其是类别不平衡数据集、小样本数据集;广泛用于模型性能评估、超参数调优(如网格搜索 + 分层 5 折交叉验证)。
- ❌ 不适用场景:
- 回归任务(连续标签无法按类别分层,需用分箱后分层的变种方案);
- 时序数据(时序数据不可随机拆分,需用时间序列交叉验证,避免未来数据泄露)。
| 维度 | 五折分层交叉验证 | 普通 5 折交叉验证 |
|---|---|---|
| 类别不平衡适配 | 完美适配,每折分布与全集一致,稀有类别不会缺失 | 极易出现分布偏移,稀有类别样本分布不均,评估失真 |
| 评估稳定性 | 5 轮结果波动小,均值无偏,更能反映模型真实泛化能力 | 结果方差大,易受随机拆分的运气影响,误判模型好坏 |
| 适用场景 | 全部分类任务,尤其小样本、类别失衡场景 | 仅类别分布均衡的分类任务 |
# 准备特征矩阵 X 和标签 y
X = train_processed.drop(columns=['Transported'])
y = train_processed['Transported'].astype(int)
X_test_final = test_processed.drop(columns=['Transported'])4.1 交叉验证训练 (重点避坑!)
⚠️ 这里有个 2026 年最新的坑:如果你安装的是 xgboost>=2.0 的版本,early_stopping_rounds 必须写在 XGBClassifier 初始化里,不能写在 fit() 里,否则会报错:
TypeError: fit() got an unexpected keyword argument 'early_stopping_rounds'
下面是兼容新版本的代码:
# 采用 5折分层交叉验证
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
val_accs = []
models = [] # 保存每一折的模型,用于最后集成预测
for fold, (train_idx, val_idx) in enumerate(skf.split(X, y)):
print(f"\n>>>>>> 正在训练第 {fold+1} 折 <<<<<<")
X_train, X_val = X.iloc[train_idx], X.iloc[val_idx]
y_train, y_val = y.iloc[train_idx], y.iloc[val_idx]
# ✅ XGBoost 2.0+ 正确写法:所有参数放在初始化里
model = XGBClassifier(
n_estimators=1000, # 树的数量设多一点,配合早停
max_depth=4,
learning_rate=0.05,
subsample=0.8,
colsample_bytree=0.8,
reg_alpha=0.1,
reg_lambda=1,
random_state=42,
eval_metric='logloss', # 从 fit() 移到这里
early_stopping_rounds=50, # 从 fit() 移到这里
)
# ✅ fit() 里只留数据和 verbose
model.fit(
X_train, y_train,
eval_set=[(X_val, y_val)],
verbose=100 # 每100轮打印一次
)
# 评估
y_val_pred = model.predict(X_val)
acc = accuracy_score(y_val, y_val_pred)
val_accs.append(acc)
models.append(model)
print(f"第 {fold+1} 折验证准确率: {acc:.4f}")
print(f"\n✅ 5折交叉验证平均准确率: {np.mean(val_accs):.4f}")运行结果示例:
第 1 折验证准确率: 0.8051
...✅
5 折交叉验证平均准确率: 0.8120
五、特征重要性可视化
训练完模型,我们看看哪些特征最重要,这能帮我们理解模型在想什么。
# 展示最后一个模型的特征重要性
plt.figure(figsize=(10, 8))
plot_importance(models[-1], max_num_features=15, importance_type='weight', title='特征重要性 Top 15')
plt.show()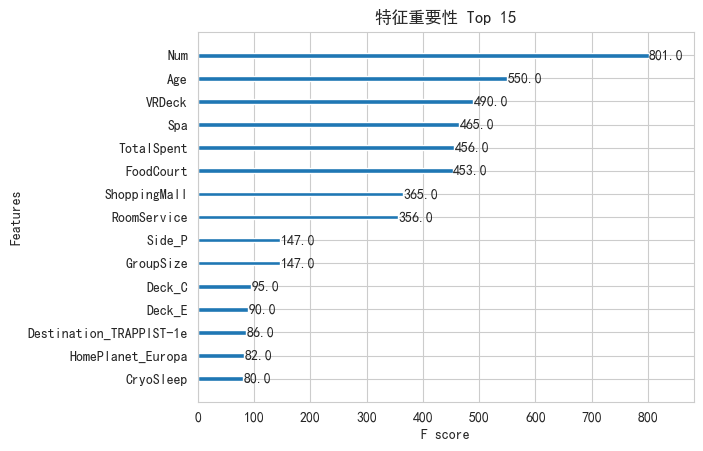
分析: 通常 TotalSpent(总消费)、CryoSleep(休眠)、Age(年龄)会排在前面,这符合我们的直觉。
六、预测并生成提交文件
最后,我们用保存下来的 5 个模型做集成预测(取平均),这比单模型效果更稳。
# 多模型集成预测 (取概率平均)
preds_proba = np.zeros(len(X_test_final))
for model in models:
preds_proba += model.predict_proba(X_test_final)[:, 1] / len(models)
# 概率转布尔值
final_preds = (preds_proba > 0.5).astype(bool)
# 保存文件
submission = pd.DataFrame({
'PassengerId': original_test_df['PassengerId'],
'Transported': final_preds
})
submission.to_csv("submission_final.csv", index=False)
print("提交文件已生成:submission_final.csv")
submission.head()把生成的 csv 文件提交到 Kaggle,你应该能拿到 0.80+ 的分数,作为入门 Baseline 已经非常不错了!
七、后续提升方向
这篇文章只是一个开始,如果你想把分数提到 0.82+,可以试试下面的方法:
- 超参数调优: 使用
Optuna或GridSearchCV搜索最佳的max_depth、learning_rate等。 - 尝试其他模型: 比如
LightGBM或CatBoost,它们和 XGBoost 各有千秋。 - 更精细的特征工程: 比如从
Name里提取姓氏,做目标编码(Target Encoding)
原创不易,如果这篇文章对你有帮助,欢迎 👍点赞、⭐收藏、➕关注! 有任何问题也可以在评论区留言,我会尽量回复~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)