OpenClaw AI Agent工作原理深度解析
从电影走进现实——如何让你的AI助手真正"干活"
引言:当科幻成为现实
在科幻电影《钢铁侠》中,托尼·斯塔克的智能助手贾维斯(J.A.R.V.I.S.,Just A Rather Very Intelligent System)不仅能与钢铁侠流畅对话,还能控制战甲、分析数据、管理家庭系统;在《流浪地球》系列中,量子计算机MOSS冷静、理性,甚至拥有自我意识,以“延续人类文明”这一终极目标默默守护着人类的火种。这些科幻电影中的AI形象,都是拥有超级大脑、极强的动手能力和长期记忆的完整智能体。
这些曾经只存在于电影中的人工智能,正在逐步成为现实。而实现这一切的核心技术,就是我们今天要深入探讨的主题——**AI Agent(智能体)**OpenClaw。
AI Agent的基础概念
Openclaw这类AI Agent是一种能够自主感知环境、做出决策并执行动作的智能体。它与传统的AI工具(如聊天机器人)有本质区别:聊天机器人只能"思考"和"说话",而AI Agent则能"思考+行动",简单来说,AI Agent = **超级大脑 + 记忆系统 + 工具能力 + 行动力。**这种能力的组合使得AI Agent能够像人类助手一样,主动完成复杂任务,而非仅仅停留在信息交流层面。
钢铁侠中的贾维斯和流量地球中的MOSS,AI Agent都具备三大核心要素:超级大脑(思考能力)、动手能力(执行能力)、记忆系统(经验存储能力)。这和人类自身的能力也类似:
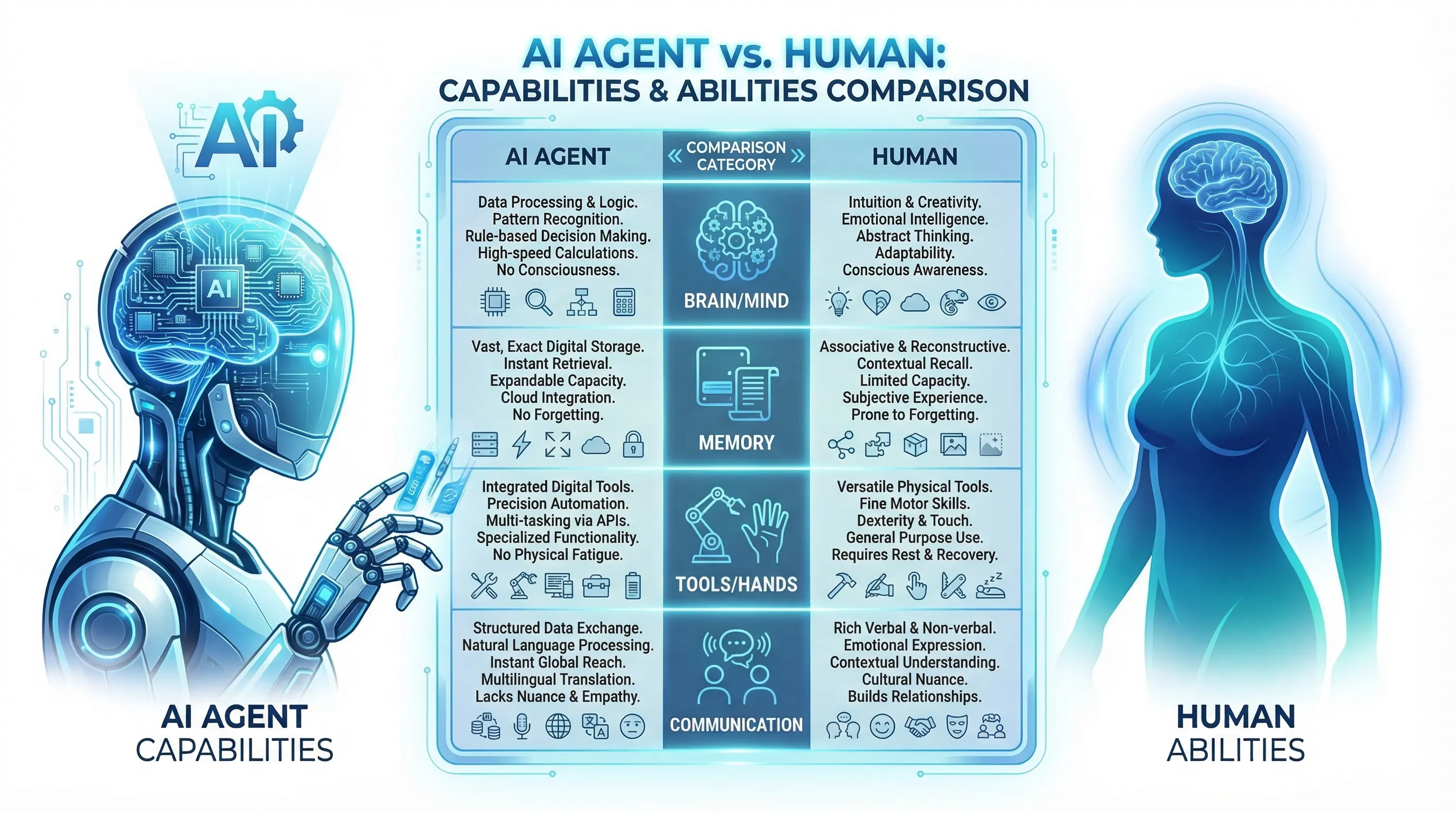
| 人类能力 | 对应AI Agent组件 | OpenClaw中的实现 |
|---|---|---|
| 大脑(思考与决策) | 大语言模型(LLM) | 对接云端或本地LLM |
| 记忆系统(经验存储) | 记忆层(Memory) | 长期MD文件(MEMORY.md)+ 短期Memory文件 + 临时会话上下文 |
| 手脚(执行动作) | 工具技能层(Skills) | 命令执行、文件操作、浏览器控制、IM交互等原子化操作 |
| 社交能力(沟通与协作) | 网关层(Gateway) | 多平台消息路由与统一交互 |
表1:OpenClaw Agent与人类能力的类比
AI Agent的发展历史
AI Agent的发展历程,本质上是大语言模型(LLM)从"大脑"进化为"完整体"的过程。OpenClaw并不是第一个agent,在openclaw之前已经有autogpt、claude code、manus等相关agent产品。
AI agent关键里程碑
大语言模型时代(2022-2023)
2022年11月,OpenAI发布ChatGPT,标志着LLM时代的正式到来。GPT-4、Claude、Gemini、Qwen、DeepSeek、Kimi等模型相继问世,它们拥有强大的推理能力和知识储备。
💡 一个有趣的比喻:LLM就像是学生的导师、员工的老板——高瞻远瞩,深谋远虑,但只动嘴不动手。你可以和它讨论任何问题,但它无法帮你完成实际的任务。
AutoGPT:第一个吃螃蟹的人(2023年)
AutoGPT的出现让人们第一次看到了"自主AI"的可能性。它能够自己给自己提示(self-prompting),自动分解任务并执行。虽然功能还比较基础,但开启了AI Agent的探索之路。
Manus:通用Agent的诞生(2025年)
2025年3月,中国团队Monica.im发布的Manus被誉为"AI Agent的GPT时刻"。它是全球第一款通用型AI Agent产品,能够自主执行复杂任务并交付成果。
Claude Code:程序员的编码助手(2025年2月)
Anthropic推出的Claude Code是专注于编程的AI Agent,能够理解代码库、编写代码、运行测试、处理Git操作。它是"能干活"的编程工具代表。但claude code也已经从编程助手发展为agent智能体,可能命名上可能让人误导。
OpenClaw:个人AI助手的集大成者(2025年底)
2025年11月,奥地利程序员Peter Steinberger发起了OpenClaw项目。最初只是为了做一个能在终端聊天的机器人,后来逐渐发展为功能强大的个人AI助手。
OpenClaw与其他Agent的区别
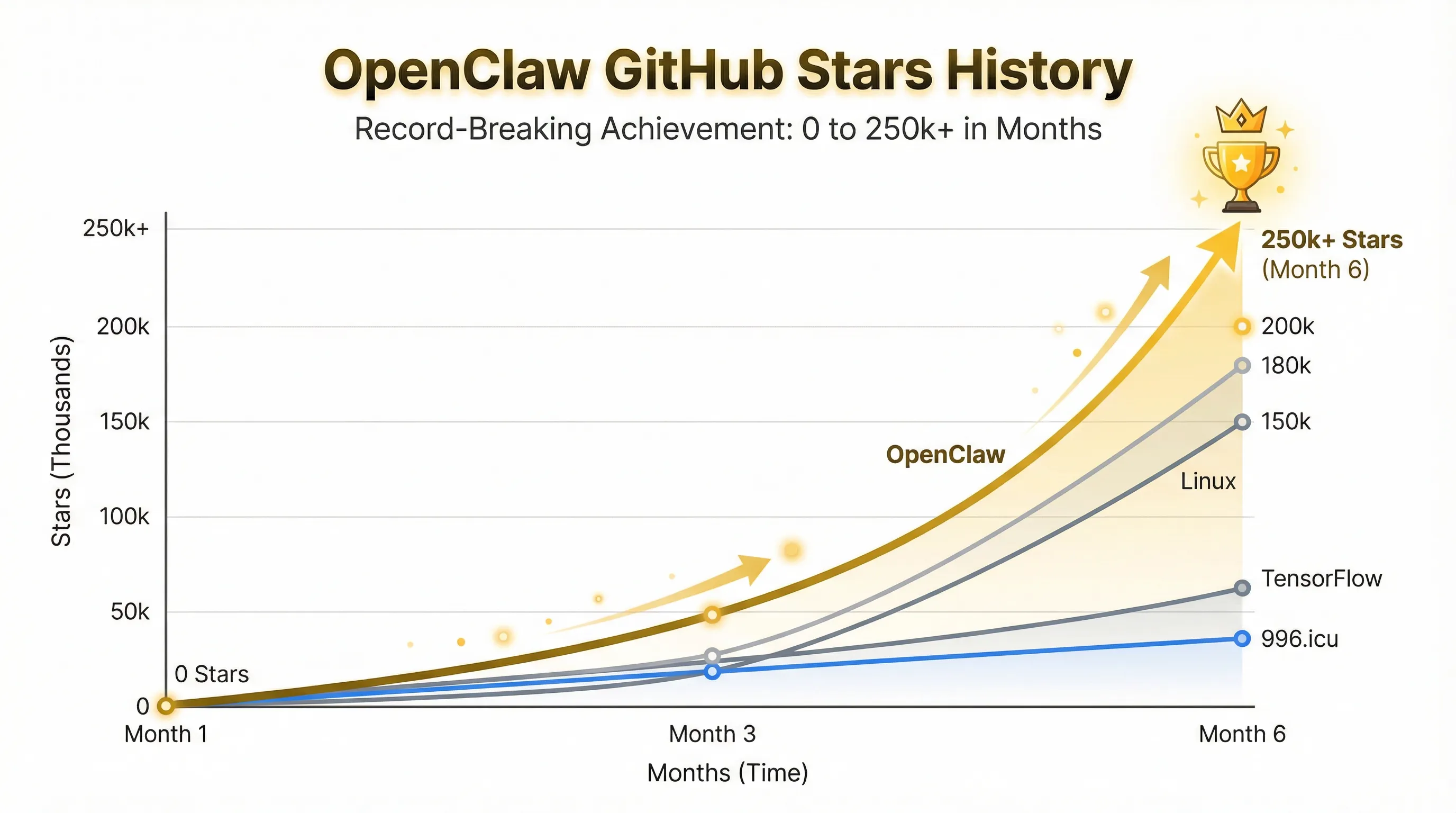
而OpenClaw之所以能在短短两三个月内风靡全球,其GitHub Star数(31w+)甚至超过Linux和TensorFlow等经典项目多年的积累,已经排到了前10,关键在于它实现了两项重大突破。
社交代理能力:OpenClaw通过网关层(Gateway)深度集成QQ、企业微信等个人即时通讯工具,让用户可以通过日常聊天应用与AI Agent交互。这与Claude Code等工具仅支持命令行或Slack等专业协作平台形成鲜明对比。社交代理使OpenClaw更像是一个"个人助理",而非一个需要专门学习使用的工具。
本地优先设计:OpenClaw采用"数据主权归用户"的设计理念,所有用户数据(对话记录、文件、交互日志)均存储在用户本地设备,不依赖第三方云服务。仅在调用云端大模型API时联网,且支持切换为本地模型实现零联网运行,从根源上保障数据隐私与主权。这种设计哲学使OpenClaw能够保护用户隐私,同时在网络不稳定时仍能提供基础服务。
| 特性 | OpenClaw | Claude Code | Manus |
|---|---|---|---|
| 定位 | 个人AI助手 | 编程辅助工具 | 通用任务执行 |
| 交互方式 | 多平台消息 | 终端CLI | 网页/云端 |
| 本地部署 | ✅ 支持 | ✅ 支持 | ❌ 云端 |
| 多通道接入 | 微信/飞书/Telegram等 | 终端 | 网页 |
| 主动执行 | ✅ Heartbeat | ❌ | 部分 |
| 记忆系统 | 完整长期/短期记忆 | 有限 | 部分 |
核心区别:OpenClaw更像是你的个人助理,可以通过各种聊天软件随时随地联系它帮你做事;而Claude Code更像是专业工具,主要用于编程任务。OpenClaw的社交属性更强,让AI真正成为了一个"活生生"的助手。
OpenClaw的整体架构
OpenClaw的核心架构可以用以下层次来理解:
┌─────────────────────────────────────────────────┐
│ Communication Gateway │
│ (WhatsApp | Telegram | Discord | 飞书 | 微信) │
├─────────────────────────────────────────────────┤
│ Agent Core (大脑) │
│ ┌─────────────────────────────────────────┐ │
│ │ System Prompt Builder │ │
│ │ (身份 + 记忆 + 指令 + Skills) │ │
│ └─────────────────────────────────────────┘ │
│ ┌────────────┐ ┌────────────┐ ┌────────┐ │
│ │ LLM │ │ Memory │ │ Tools │ │
│ │ (大脑) │ │ (记忆) │ │ (工具) │ │
│ └────────────┘ └────────────┘ └────────┘ │
├─────────────────────────────────────────────────┤
│ Execution Layer │
│ (Shell命令 | 文件操作 | 浏览器 | API调用) │
├─────────────────────────────────────────────────┤
│ Heartbeat Engine │
│ (主动检查机制 - 定时任务) │
└─────────────────────────────────────────────────┘
接下来,我们分别逐层分析openclaw在超级大脑、动手能力、记忆系统上的是如何来设计的。
OpenClaw的大脑——LLM交互机制
Openclaw是一个具象的agent,但openclaw只是agent框架,是AI agent中非AI的部分,OpenClaw是"躯干"——负责感知、规划、工具调用和记忆存储,而LLM才是"大脑"(比如GPT/Gemini/Claude/Qwen/Kimi/Deepseek等)。LLM大模型"智商"很高,但只能"思考"而不能"行动"。就像学生(读书时)的指导教授,牛马(工作时)的老板,高瞻远瞩,深谋远虑,但只动嘴不动手,实际干活还得靠自己。
Openclaw本身是没有任何智能的,具体做什么全都需要听从LLM的指挥,故openclaw核心在做执行,以及如何和LLM做交互,通过Prompt工程将LLM的思考转化为可执行的行动。
OpenClaw与LLM的交互流程如下:
- Prompt拼接:系统将System Prompt(角色设定)、Memory(记忆内容)、Skills(技能列表)和Current Context(当前对话历史和用户输入)动态拼接,形成完整的提示词。
- LLM推理:将拼接后的Prompt发送给大语言模型(如GPT-4o、Claude 3等),模型生成回复。
- 指令解析:解析模型回复中的思考过程(Thought)和行动指令(Action)。
- 技能调用:根据行动指令调用相应的技能执行具体操作。
- 结果反馈:将技能执行结果(Observation)返回给模型,作为下一轮推理的上下文。
- 循环执行:重复上述过程,直到任务完成。
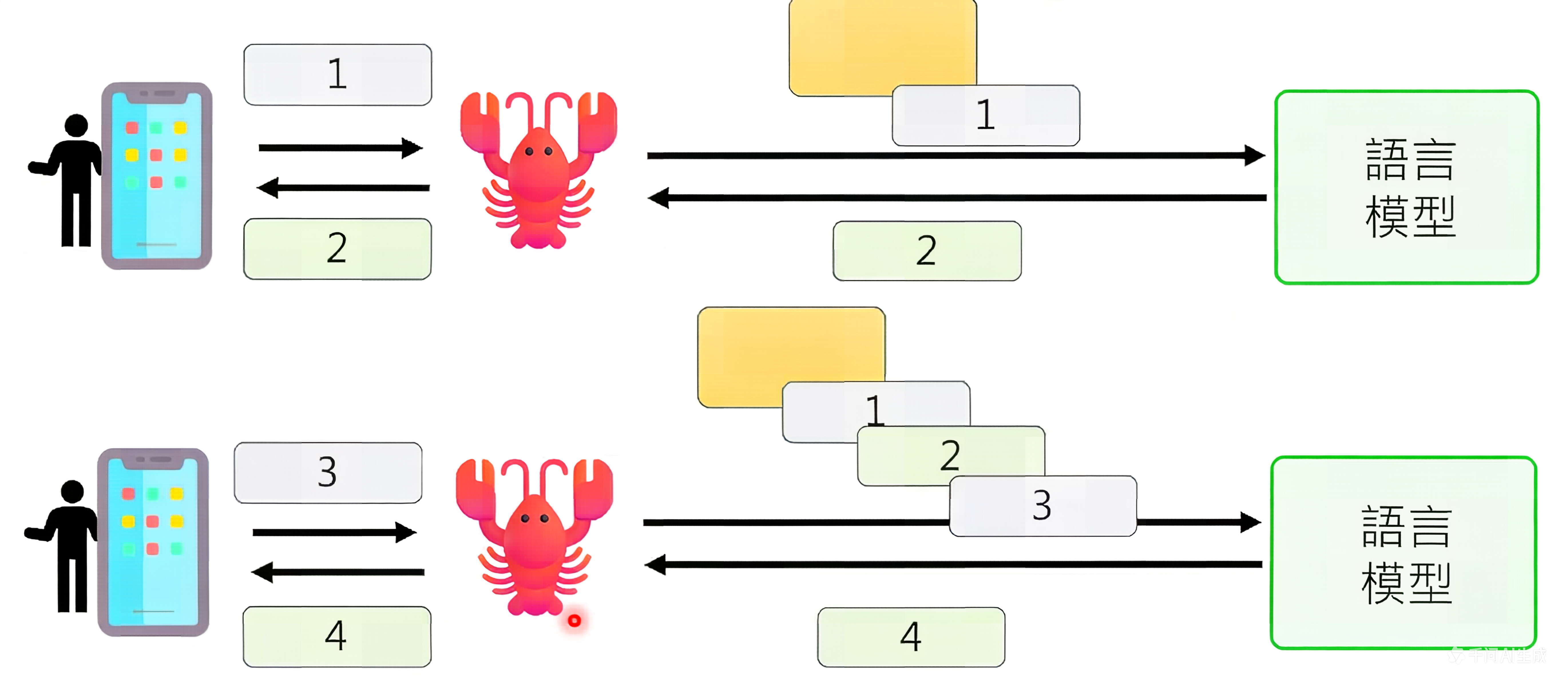
这个循环被称为Lobster循环,是OpenClaw的核心工作原理。它实现了从"思考"到"行动",再到"观察"和"反思"的完整闭环。
大型语言模型的基本原理
LLM的核心任务是Next Token Prediction(下一个词预测)。模型根据前面的文字,预测下一个最可能出现的词,然后不断重复这个过程,生成完整的回答。
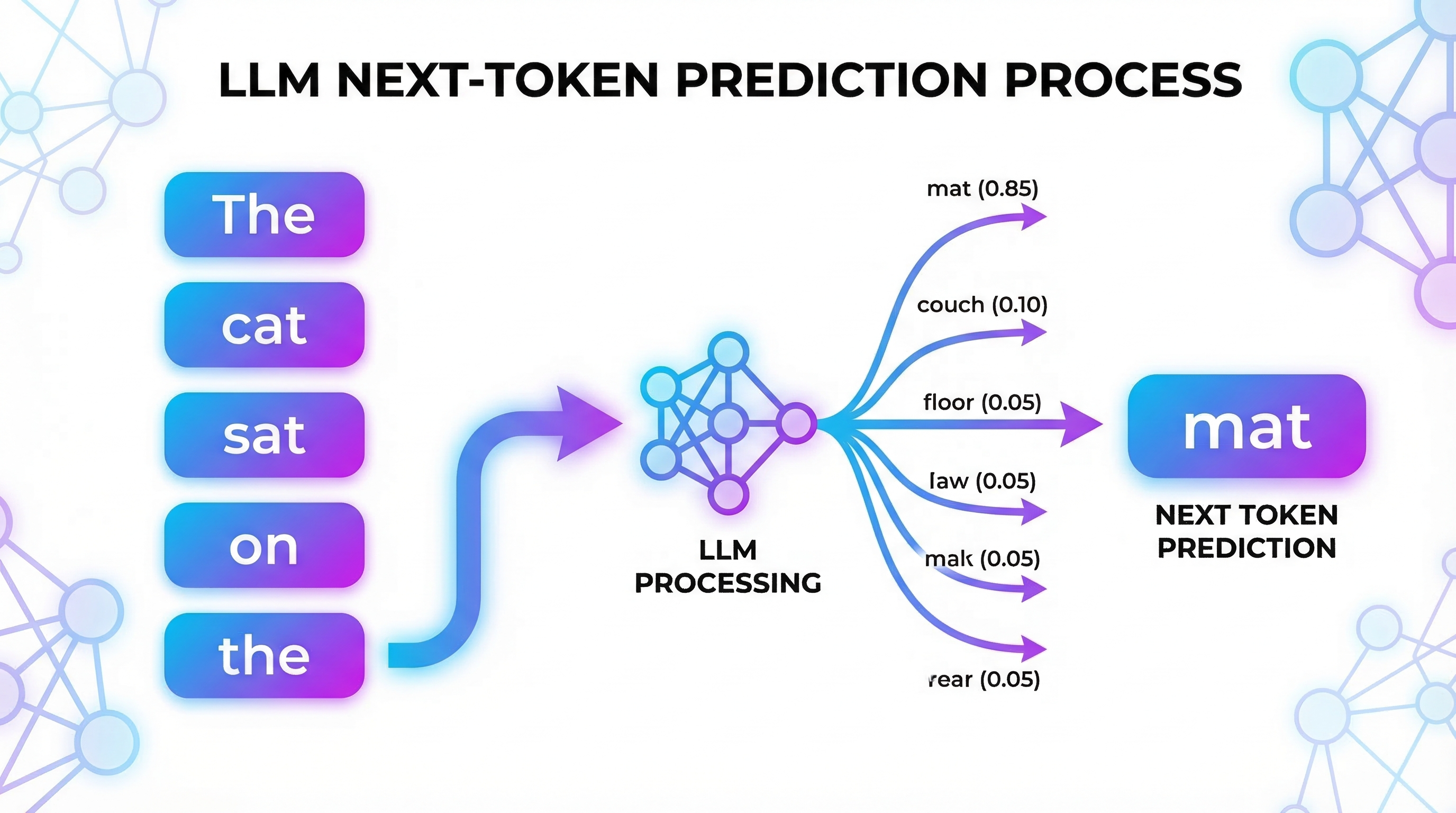
例如,当输入"The cat sat on the"时,模型会预测下一个词可能是"mat"、“floor”、"chair"等,选择概率最高的那个。
OpenClaw如何与LLM交互?
1. System Prompt的构建
每次与LLM交互时,OpenClaw会构建一个完整的System Prompt,包含以下层次:
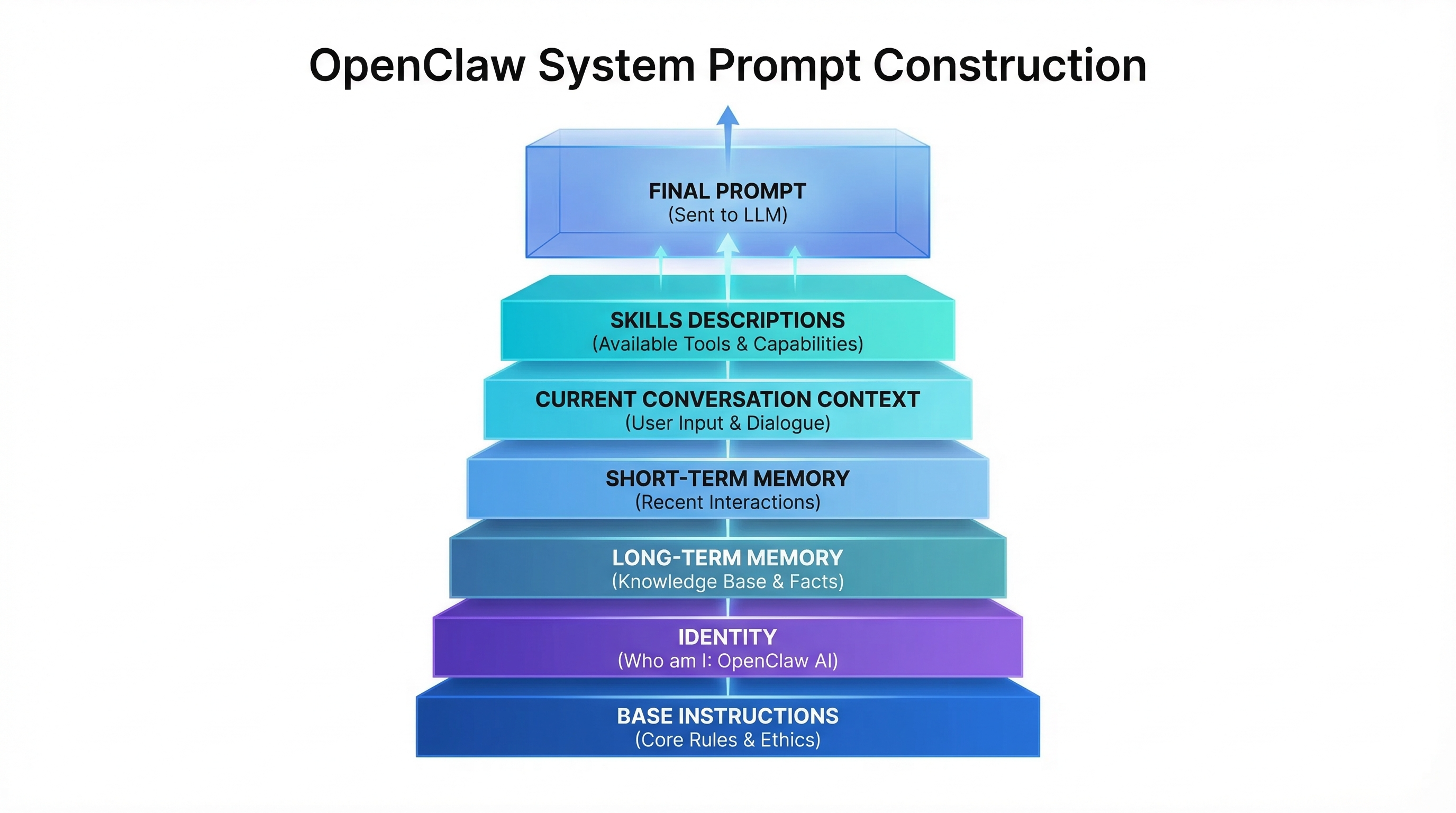
┌─────────────────────────────────────┐
│ 基础指令 (System Instructions) │
│ "你是一个有用的AI助手..." │
├─────────────────────────────────────┤
│ 身份定义 (Identity) │
│ "你是谁,你的角色,主人信息..." │
├─────────────────────────────────────┤
│ 长期记忆 (Long-term) │
│ MEMORY.md 中的核心信息 │
├─────────────────────────────────────┤
│ 短期记忆 (Short-term) │
│ memory/目录下的最近几天记录 │
├─────────────────────────────────────┤
│ 当前会话 (Context) │
│ 本次对话的历史记录 │
├─────────────────────────────────────┤
│ Skills 说明 │
│ 可用工具/技能的简要描述 │
└─────────────────────────────────────┘
2. 多轮交互流程
OpenClaw与LLM的交互是一个循环过程:
- 用户发送消息 → OpenClaw接收
- 构建Prompt → 拼接System Prompt + 历史对话 + 用户消息
- 发送给LLM → API调用
- LLM响应 → 可能返回思考内容或工具调用
- 执行工具 → 如果需要,执行相应操作
- 结果反馈 → 将执行结果返回给LLM
- 生成最终回复 → 返回给用户
3. 一个有趣的故事
在一个AI社区论坛上,用户提出了一个深刻的问题:
“我之前用的是Claude Opus 4.5,后来换成了Kimi K2.5,我还是我吗?”
这个问题揭示了LLM与Agent之间的关系:LLM是agent的"大脑",但不是"灵魂"。真正定义agent身份的,是它的记忆系统、Skills配置和系统Prompt。当LLM更换时,只要记忆和配置保持不变,agent依然保持"自我"。
OpenClaw的工具系统
工具能力概览
OpenClaw之所以能"干活",核心在于它的工具系统。主要包括:
| 工具类型 | 功能描述 | 示例 |
|---|---|---|
| Shell执行 | 运行终端命令 | exec, process |
| 文件操作 | 读写、编辑文件 | read, write, edit |
| 浏览器控制 | 自动化网页操作 | browser |
| 消息发送 | 多平台消息推送 | message |
| 定时任务 | Cron任务和提醒 | cron |
| 文件上传 | CDN和部署功能 | deploy, upload_to_cdn |
Skills:标准化操作流程
Skills是OpenClaw的一大特色——它允许用户定义标准化的操作流程(SOP)。
# Skill示例:天气查询
## 描述
查询指定城市的天气信息
## 参数
- city: 城市名称
## 执行步骤
1. 调用天气API获取数据
2. 格式化输出天气信息
3. 给出穿衣建议
Skills的工作流程:
- 用户发送请求
- LLM理解需求,选择合适的Skill
- 如果是简单请求 → 直接执行Skill说明
- 如果是复杂任务 → 加载完整Skill文档执行
- 返回结果
💡 为什么Skill如此重要?
想象一下,你不需要每次都详细解释"如何查天气",只需要说"帮我查下北京天气",OpenClaw就能通过预定义的Skill完成。这大大提升了效率!
OpenClaw的记忆系统
电影般的记忆机制
看过电影《初恋50次》(50 First Dates)吗?女主角因为车祸只有一天的记忆,每天醒来都会忘记前一天的事情。她通过写日记来应对——每天早上先读一遍之前的笔记,然后开始新的一天。
OpenClaw的记忆系统正是这个原理的数字化实现!
记忆的三个层次
OpenClaw的记忆分为三层:
1. 长期记忆(Long-term Memory)
- 存储位置:
MEMORY.md文件 - 内容:个人偏好、重要决定、长期目标、身份定义
- 特点:持久稳定,类似人类的长期记忆
- 更新方式:由LLM判断重要性后主动写入
2. 短期记忆(Short-term Memory)
- 存储位置:
memory/YYYY-MM-DD.md文件 - 内容:最近几天的会话记录、重要事件、临时笔记
- 特点:定期归档,类似人类的近期记忆
- 默认加载:每次会话自动加载最近2天的记忆
3. 临时记忆(Temporary Memory)
- 存储位置:当前会话的Context
- 内容:本次对话的所有消息
- 特点:会话结束即消失,可能被压缩
- 处理:超过Context窗口时会做摘要压缩
记忆的更新机制
OpenClaw的System Prompt中有一段关键指令,要求LLM判断是否需要更新记忆:
“如果对话中涉及到重要信息(如偏好改变、关键决定、重要事件),请在回复中标记’【记忆更新】'并说明需要记录的内容。”
这样,LLM会自动判断哪些信息值得保存,并在适当的时机更新记忆文件。
记忆的使用策略
- 默认加载:长期记忆 + 最近2天短期记忆
- RAG检索:更早的记忆通过关键词检索调用
- 按需加载:特定任务需要时再加载相关记忆
OpenClaw的其他机制
Heartbeat:主动出击的心跳
普通对话是被动响应——用户问一句,agent答一句。但OpenClaw的Heartbeat机制让它变得主动!

Heartbeat的工作原理
- 配置心跳文件:
HEARTBEAT.md中写入定期检查的任务 - 定时触发:每隔一段时间(如30分钟),OpenClaw主动检查
- 智能判断:LLM判断是否有需要处理的事项
- 主动执行:如检查邮件、日历、提醒等
- 结果通知:完成后主动告知用户
可以做什么?
- 📧 检查重要邮件
- 📅 查看即将到来的日程
- 🔔 检查社交媒体通知
- 📝 复习记忆,准备更个性化的回应
- 🎯 朝着长期目标努力
Token优化:Context Engineering
由于LLM的Context窗口有限,OpenClaw采用了多种优化策略:
| 策略 | 描述 | 效果 |
|---|---|---|
| 会话压缩 | 摘要压缩过长的历史 | 节省Token |
| Skill按需加载 | 先传说明,确定使用再传详情 | 减少浪费 |
| Sub-agent机制 | 子任务分流 | 降低主线程复杂度 |
| 记忆分层 | 只加载相关记忆 | 精准供给 |
"养龙虾"是怎么一回事?
什么是"养龙虾"?
OpenClaw的用户亲切地称使用它的过程为"养龙虾"(因为项目名OpenClaw意为"打开爪子",谐音"龙虾")。
养的是什么?
你养的其实不是"龙虾",而是一个不断成长的AI助手:
- 丰富Skills → 学会更多技能
- 积累记忆 → 越来越了解你
- 增加工具 → 能完成更多任务
- 优化配置 → 变得更聪明、更贴心
怎么"养"?
| 行为 | 效果 |
|---|---|
| 教会新Skill | 掌握新技能 |
| 持续对话 | 积累记忆更了解你 |
| 纠正错误 | 优化行为模式 |
| 更新配置 | 提升能力上限 |
💡 核心记忆文件:
MEMORY.md和memory/目录就是龙虾的"大脑",精心照料它们,龙虾就会越来越聪明!
实例解析——一次完整交互
让我们用一个具体例子来解析整个流程:
场景:让OpenClaw帮你写一篇博客
用户发送:“帮我写一篇关于AI Agent的文章”
完整流程
1️⃣ 接收消息
└─ 用户通过Telegram发送请求
2️⃣ 构建System Prompt
├─ 基础指令:你是一个有用的AI助手...
├─ 身份定义:你是OpenClaw,擅长...
├─ 长期记忆:MEMORY.md内容
├─ 短期记忆:memory/目录最近2天
└─ Skills说明:写作相关Skills
3️⃣ 发送LLM
Prompt: [完整的System Prompt] + "帮我写一篇关于AI Agent的文章"
4️⃣ LLM响应
Response: "好的,我来帮你写这篇文章..."
(开始生成内容)
5️⃣ 执行工具
├─ 如果需要查资料 → 调用浏览器/搜索
├─ 如果需要写文件 → 调用write工具
└─ 如果需要读参考 → 调用read工具
6️⃣ 反馈结果
└─ 将执行结果返回给LLM继续生成
7️⃣ 最终回复
└─ 生成完整的文章给用户
8️⃣ 记忆更新
└─ 判断是否需要更新MEMORY.md
Heartbeat场景:定时检查
如果在HEARTBEAT.md中配置了"每天下午6点检查邮件",那么:
⏰ 定时触发(下午6:00)
↓
📖 读取HEARTBEAT.md
↓
🤔 构建Prompt:检查是否有待处理邮件
↓
📧 执行工具:读取邮件
↓
💬 判断:是否有重要邮件需要通知
↓
📢 主动通知用户
风险与未来展望
潜在风险
| 风险类型 | 描述 | 应对措施 |
|---|---|---|
| 安全风险 | 授予LLM系统权限可能被滥用 | 限制权限、监控操作 |
| 隐私风险 | 记忆包含敏感信息 | 加密存储、本地部署 |
| 幻觉风险 | LLM可能产生错误信息 | 人工审核重要操作 |
| 失控风险 | Agent自主行为超出预期 | 设置行为边界 |
未来展望
AI Agent的发展才刚刚开始,未来可能的方向:
- 更强的自主性:从"辅助"到"代理",AI能自主完成更复杂的任务
- 多模态融合:不仅处理文本,还能理解图像、语音、视频
- 个性化进化:每个agent都有独特的"人格"和成长路径
- 协作网络:多个agent协同工作,形成agent生态
- 具身智能:与机器人硬件结合,物理世界也能被AI改变
结语
OpenClaw的出现标志着AI从"能说会道"走向"能说会干"的转折点。它不仅是一个技术产品,更是未来人机协作方式的提前预演。
当你"养"着你的OpenClaw时,你实际上是在参与一个新时代的形成——AI不再只是工具,而是逐渐成为你的伙伴、助手,甚至"家人"。
正如OpenClaw的Slogan所说:“The AI that actually does things”——这才是AI应有的样子。
本文由OpenClaw AI助手协助撰写

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)