你以为大模型在“思考“?其实它只是在努力“回忆“
你以为大模型在"思考"?其实它只是在努力"回忆"
一句话总结:Google Research 发现,让大模型"思考"不仅能解数学题,还能帮它回忆起本来答不上来的简单事实——背后的两个机制像极了人类考试时的"草稿纸效应"和"联想记忆"。
论文标题:Thinking to Recall: How Reasoning Unlocks Parametric Knowledge in LLMs
作者:Zorik Gekhman, Roee Aharoni, Eran Ofek, Mor Geva, Roi Reichart, Jonathan Herzig
机构:Google Research, Technion - Israel Institute of Technology, Tel Aviv University
论文链接:arXiv:2603.09906
一、引子:一个反直觉的现象
想象一个场景:考试时遇到一道简单的填空题——"清朝最后一个皇帝是谁?"你明明知道答案,但就是想不起来。这时候你在草稿纸上随手写了几个清朝的年号、几个王爷的名字,突然"溥仪"两个字就蹦了出来。
这个场景看起来很日常,但如果我告诉你,大语言模型(LLM)也在做同样的事情呢?
过去一年,“推理模型"成了AI圈最热的词。OpenAI的o系列、DeepSeek-R1、Gemini 2.5——这些模型在回答问题前会先"想一想”,生成一段内部推理过程(reasoning trace)。对于数学证明、代码生成、多步推理这些需要逻辑链条的任务,推理的价值显而易见。但Google Research的这篇论文提出了一个让人挠头的问题:
对于那些根本不需要"推理"的简单事实问题,开启推理模式为什么也能大幅提升正确率?
“法国的首都是哪里?”——这种问题需要什么推理步骤?不需要分解、不需要逻辑链、不需要多步计算。模型要么知道,要么不知道。但实验结果清楚地表明:开启推理后,模型能答对的问题范围显著扩大了。
这篇论文通过一系列精心设计的对照实验,拆解出了两个关键机制,并揭示了一个潜在的风险。接下来我们深入看看。
二、实验设计:如何科学地"捉鬼"
2.1 为什么用 pass@k 而不是 accuracy
这里有一个重要的实验设计选择。如果只看单次回答的准确率(pass@1),我们很难分辨"推理帮助模型回忆起了新知识"还是"推理只是让模型更稳定地输出已知答案"。
作者采用了 pass@k 指标:给模型同一个问题采样 k 次,只要有一次答对就算通过。这个指标衡量的不是"模型多稳定",而是"模型的知识边界在哪里"。如果 pass@100 在开启推理后显著提升,说明推理真的解锁了模型"本来不知道"的答案,而不仅仅是提高了已知答案的输出概率。
这个思路非常聪明。打个比方:如果你抽奖100次都没中过,说明你确实没有中奖的可能;但如果多给你100次机会你就能中一次,那说明你本来就在奖池里,只是概率太低。pass@k 就是在测试这个"奖池边界"。
2.2 模型和数据集
实验使用了三个支持推理开关切换的"混合模型":
- Gemini-2.5-Flash(Google 轻量级推理模型)
- Gemini-2.5-Pro(Google 旗舰推理模型)
- Qwen3-32B(通义千问开源推理模型)
选择"混合模型"的好处是可以在完全相同的参数下,仅切换推理开关来对比效果,排除了模型架构差异带来的干扰。
数据集方面使用了两个闭卷QA基准:
- SimpleQA-Verified:1000个经过人工验证的事实问题,涵盖多种主题
- EntityQuestions:1000个模板化的实体关系问题(4种关系类型),控制变量更严格
2.3 核心指标 Ω(N)
为了量化"推理对记忆提取的帮助程度",作者定义了 Ω(N) 指标:
Ω ( N ) = ∑ k = 1 N w k ⋅ Δ ( k ) ∑ k = 1 N w k \Omega(N) = \frac{\sum_{k=1}^{N} w_k \cdot \Delta(k)}{\sum_{k=1}^{N} w_k} Ω(N)=∑k=1Nwk∑k=1Nwk⋅Δ(k)
其中 Δ ( k ) = pass@k O N − pass@k O F F \Delta(k) = \text{pass@k}_{ON} - \text{pass@k}_{OFF} Δ(k)=pass@kON−pass@kOFF,权重 w k = k w_k = k wk=k。
这个加权设计有其用意:更高的 k 值对应的是更难的"边界知识",给它们更大的权重意味着我们更关注推理在知识边界上的突破能力,而非在简单问题上锦上添花。
三、核心发现:推理确实扩展了知识边界
3.1 pass@k 曲线:全面碾压
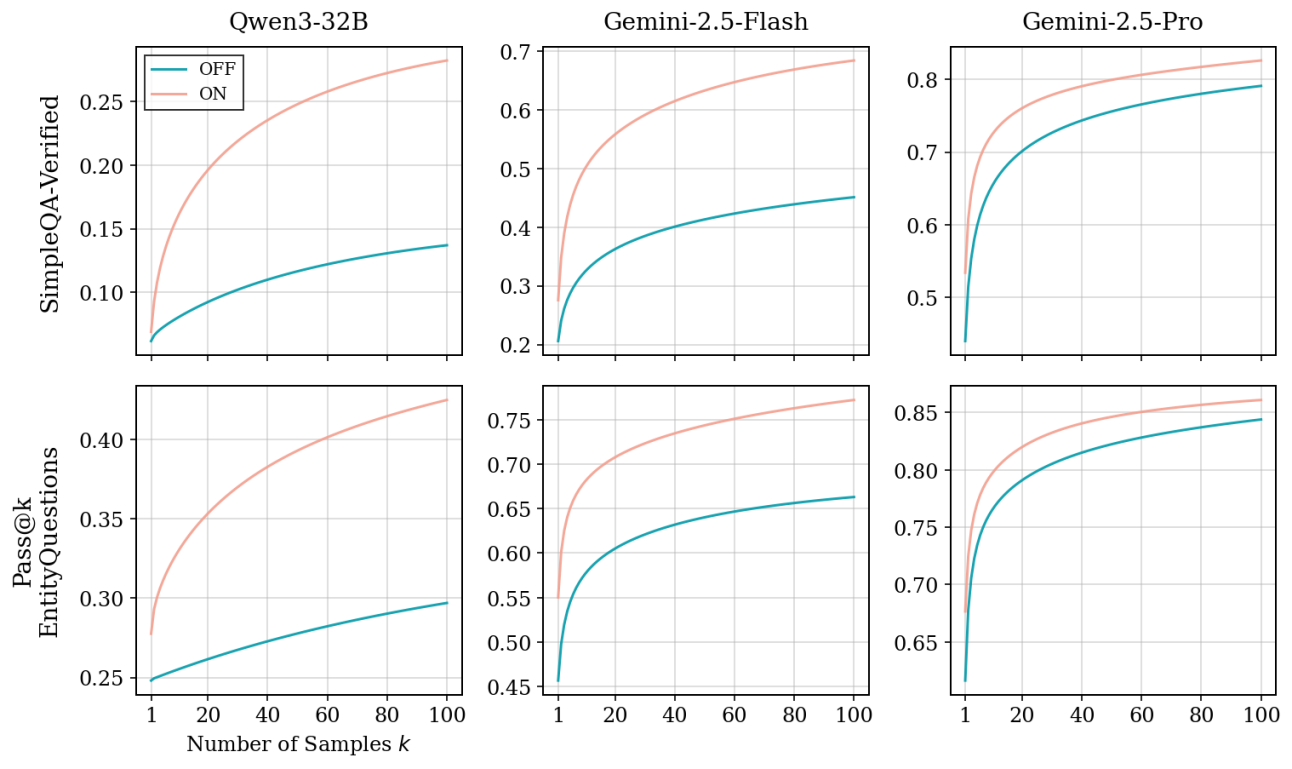
上图展示了三个模型在两个数据集上的 pass@k 曲线。蓝色线(ON)始终高于橙色线(OFF),而且随着 k 的增大,差距不但没有缩小,反而进一步拉开。
最直观的数字:Qwen3-32B 在 SimpleQA-Verified 上,推理模式的 pass@100 几乎是非推理模式的两倍。这意味着开启推理后,模型能从参数中"挖掘"出大量原本无法触及的正确答案。
这不是"同一批知识回忆得更稳定",而是"知道了以前不知道的东西"。
3.2 弱模型获益更多
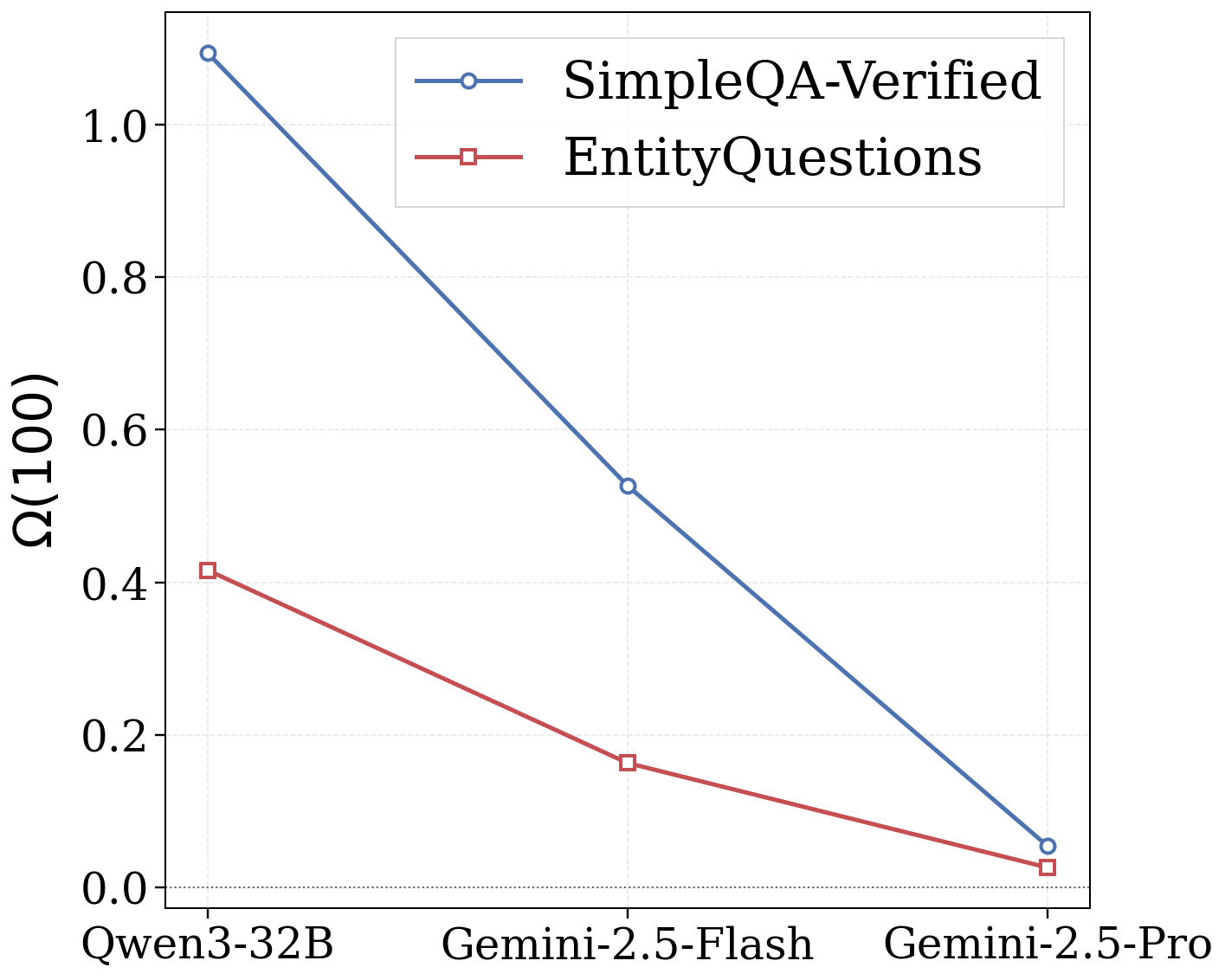
从 Ω(100) 指标来看,一个清晰的趋势浮现:模型能力越弱(pass@1越低),从推理中获益越多。
这就像考试中的差生和优等生:优等生本来就能轻松回忆起大部分知识,草稿纸对他的帮助有限;但对差生来说,草稿纸上的涂涂画画可能就是唤醒模糊记忆的关键。
另一个有趣的观察是:SimpleQA-Verified 上的 Ω 普遍高于 EntityQuestions。这很可能是因为 SimpleQA 的基线准确率更低(更多"边界知识"可以被解锁),而 EntityQuestions 的模板化问题本身就相对容易,提升空间自然更小。
3.3 问题复杂度不是决定因素
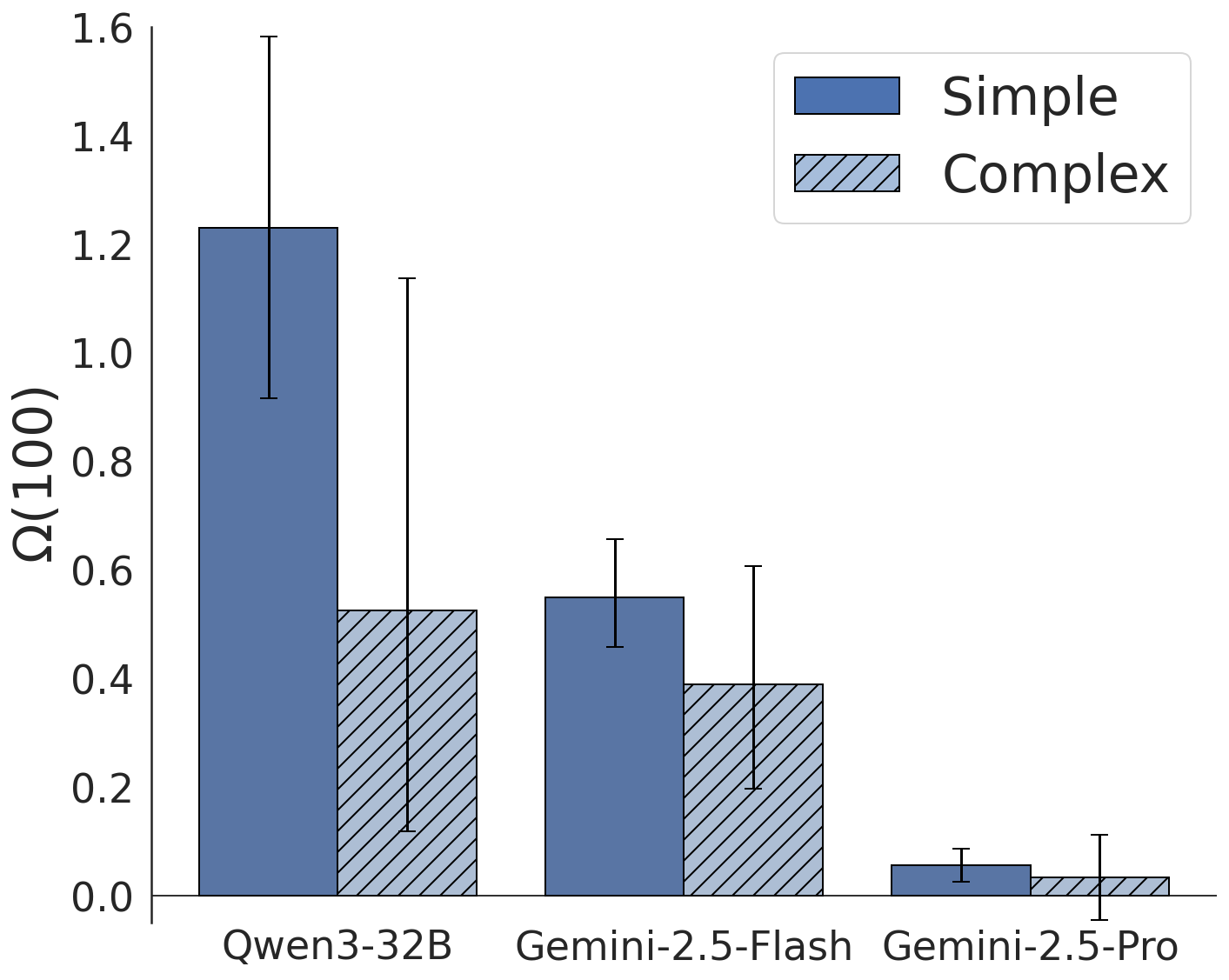
一个自然的反驳是:“也许SimpleQA里的问题并不’简单’,推理帮助的其实是那些需要多步分解的复杂问题?”
作者对此做了细致的分析:将问题分为"简单"和"复杂"两类,分别计算 Ω。结果显示,两类问题的 Ω 置信区间高度重叠,没有统计显著差异。也就是说,推理对简单问题和复杂问题的帮助程度基本一致。
这排除了"推理只在复杂问题上有用"的解释,进一步确认:推理的核心作用不是逻辑分解,而是改善知识提取本身。
四、机制一:计算缓冲效应——"草稿纸"本身就有用
4.1 实验:用废话填充推理
为了测试"推理token的语义内容是否重要",作者设计了一个大胆的实验:
- ON:正常推理模式
- ON Dummy:将推理轨迹替换为与原始长度相同的无意义填充词(“Let me think.” 重复N次),然后让模型生成最终答案
- ON Single Dummy:只用一次 “Let me think.”
- OFF:关闭推理
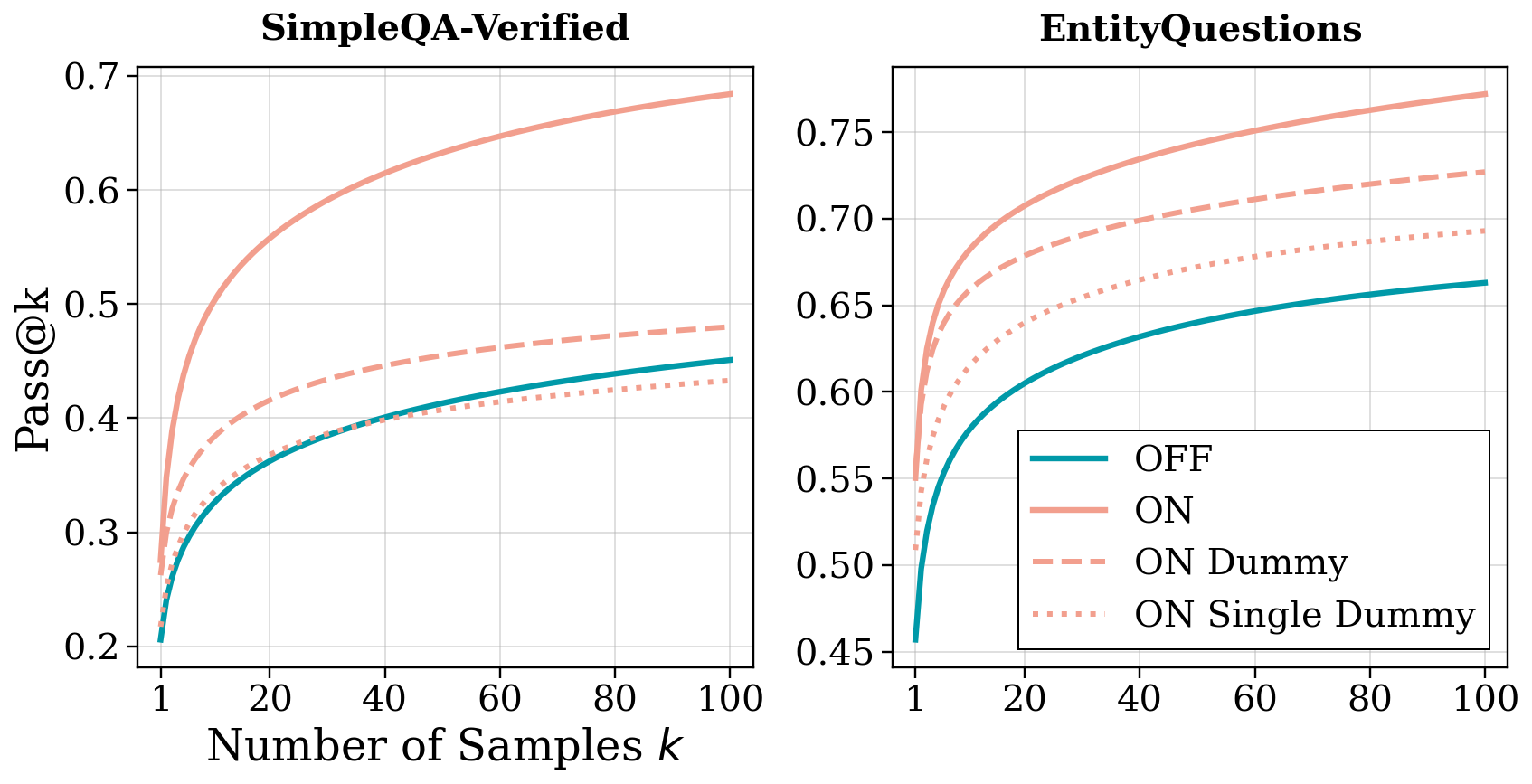
结果出人意料:
| 模式 | SimpleQA (pass@1) | EntityQuestions (pass@1) |
|---|---|---|
| OFF | 0.206 | 0.457 |
| ON Single Dummy | ~0.22 | ~0.50 |
| ON Dummy(匹配长度) | 0.262 | 0.554 |
| ON(完整推理) | 更高 | 更高 |
即便推理内容完全是废话,仅仅是多处理了一些token,模型的回忆能力就提升了。在 SimpleQA 上从 0.206 跳到 0.262,提升了约 27%。
这意味着什么?Transformer 在生成推理 token 的过程中,内部的注意力机制和前馈网络在进行额外的"隐式计算"。这些计算与文本的语义内容无关,而是利用多层网络的迭代处理来"预热"或"激活"与问题相关的参数空间。
4.2 长度的非单调效应
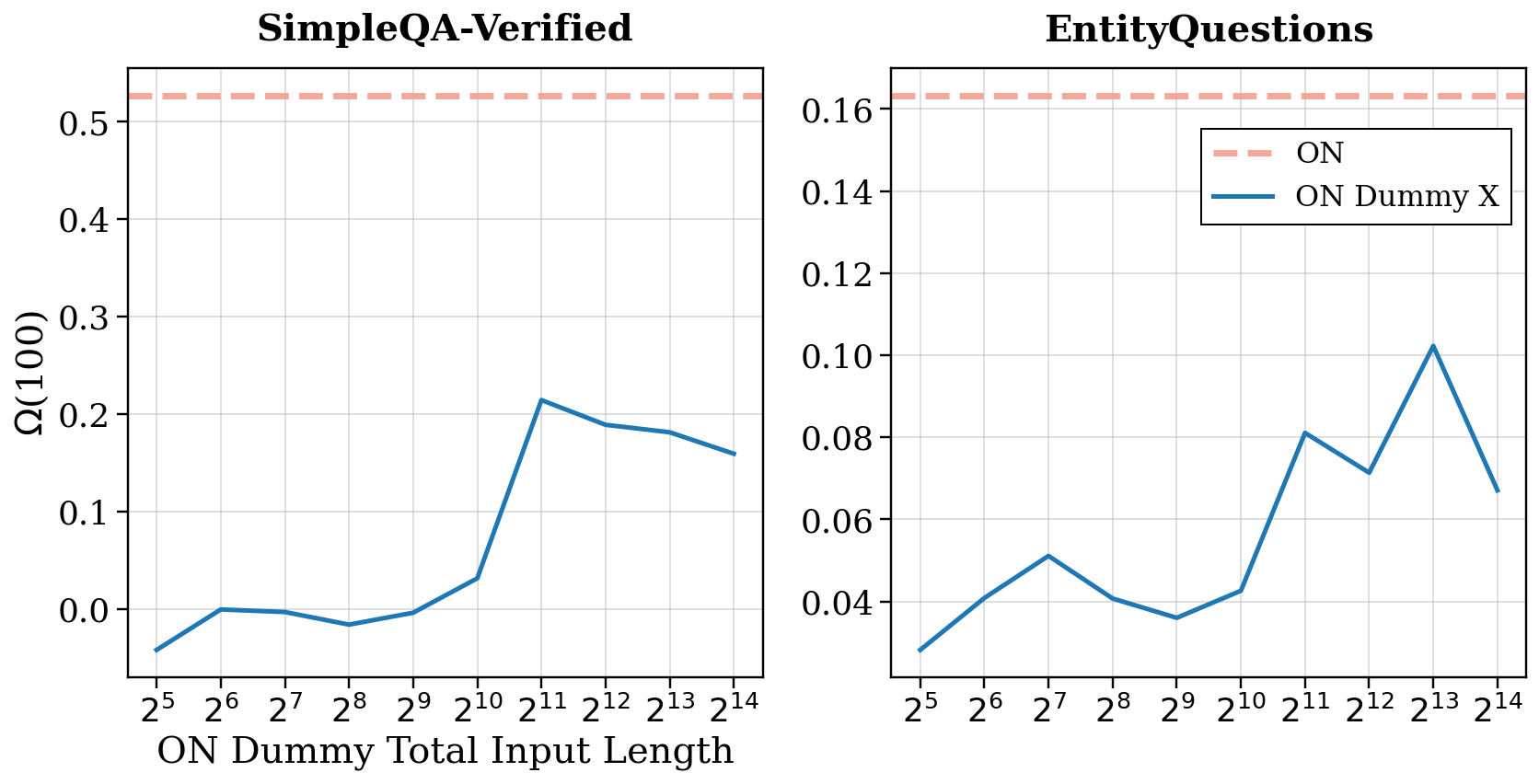
更有趣的是,增加虚拟推理的长度并非单调有益。性能在大约 2048 tokens 处达到峰值,之后开始饱和甚至下降。这像极了人类考试时在草稿纸上瞎写——写一页有助于唤醒记忆,但如果你花半小时写了十页废话,反而会分散注意力。
这个发现也暗示了一个工程应用方向:如果你只需要"计算缓冲"效果,不需要花费大量token在真正的推理上,一段适中长度的"预热"可能就够了。
4.3 深层含义:Transformer 的隐式计算
这个发现触及了一个更深层的理论问题:Transformer 的前向传播中到底在做什么?
传统理解是,每个token的生成依赖于之前所有token的注意力分布。但计算缓冲效应告诉我们,即使之前的token在语义上毫无意义,模型也能利用这些额外的前向传播步骤来进行某种形式的"深度检索"。
一个可能的解释是:模型的知识存储在参数中的方式并不总是能被直接访问的。某些知识可能需要多次前向传播才能被"激活"——就像深埋在地下的水脉,需要多钻几次才能打到。推理 token 提供的额外计算步骤,相当于给了模型更多次"钻探"的机会。
五、机制二:事实启动效应——"联想记忆"的力量
5.1 实验设计
计算缓冲效应只能解释推理收益的一部分。那么推理轨迹的语义内容是否也有独立贡献?
作者用一个精妙的实验来回答:
- 用 Gemini-2.5-Flash 在推理模式下回答问题,提取推理轨迹中的事实陈述
- 关闭推理,将这些事实作为上下文(context)提供给模型
- 对比多种条件:
- OFF:纯关闭推理
- OFF Dummy:关闭推理 + 等长填充词上下文
- OFF Facts:关闭推理 + 事实列表上下文
- ON Dummy:推理模式 + 虚拟推理轨迹
- ON Facts:推理模式 + 事实列表覆盖推理轨迹
- ON:完整推理模式
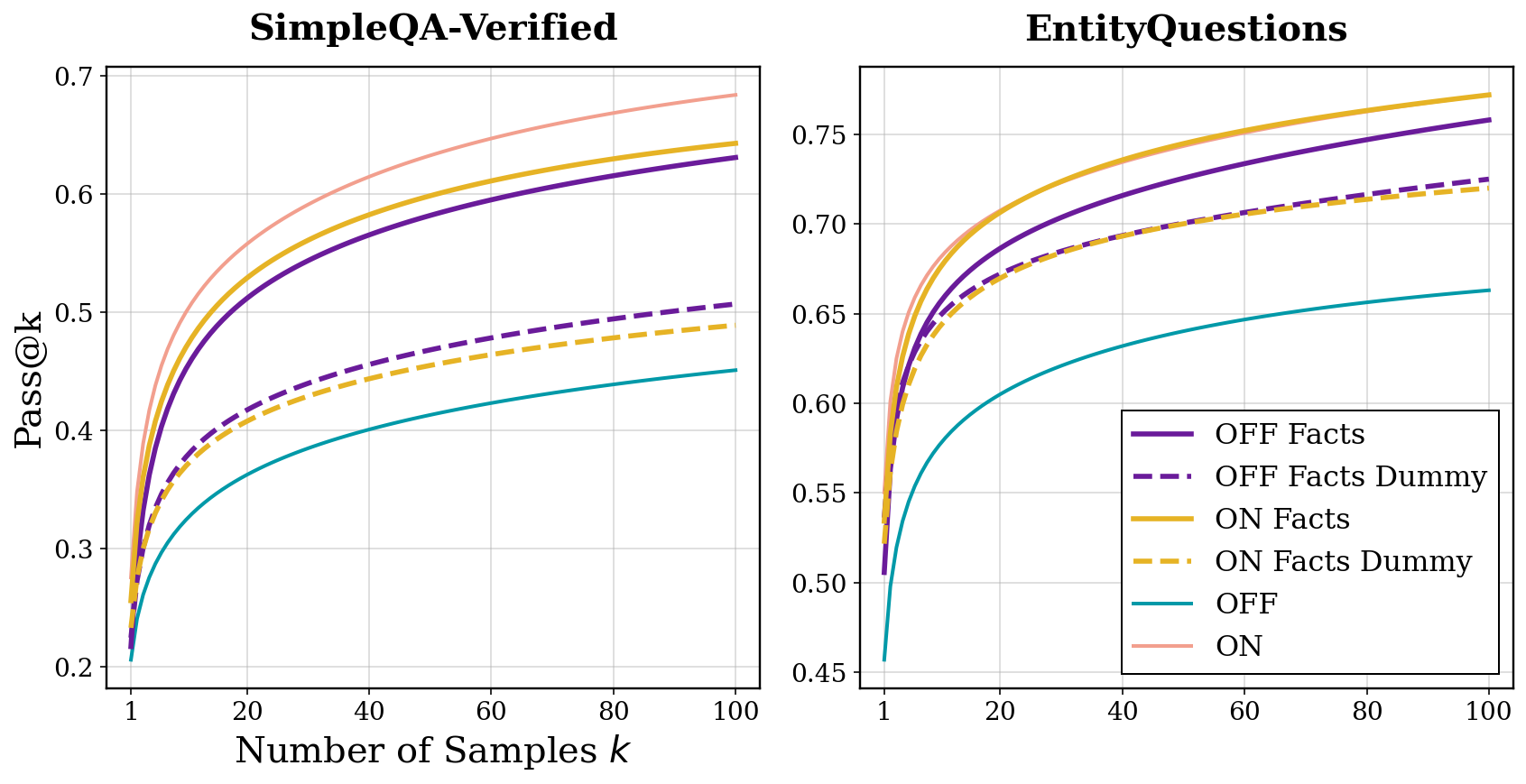
5.2 结果解读
结果非常漂亮:
- OFF Facts 显著优于 OFF Dummy:同样长度的上下文,有语义的事实远比无意义填充词有效。这直接证明了事实的语义内容有独立价值。
- ON Facts 在 EntityQuestions 上接近甚至匹敌完整推理 ON:仅用一个事实列表就能达到完整推理的效果,而且消耗的 token 更少。
- 事实启动效应解释了推理收益的主体部分。
这就是"联想记忆"在起作用。当模型在推理过程中"说出"与问题主题相关的事实时,这些事实像多米诺骨牌一样,激活了相关的参数区域,最终让正确答案浮出水面。
举个具体的例子(论文中的案例):当被问到"尼泊尔第10任国王是谁"时,模型在推理过程中列举了前9任国王的名字。这些名字本身就是正确答案的"语义近邻",它们的出现大大提高了第10任国王名字被正确检索的概率。就像你在背一首长诗时,从头开始默念,自然就能接上后面忘记的部分。
5.3 实际应用:推理轨迹选择
基于以上发现,作者提出了一个直接的应用:通过筛选推理轨迹来提升准确率。
| 选择策略 | SimpleQA-Verified | EntityQuestions |
|---|---|---|
| Regular(随机选择) | 27.9 | 56.9 |
| Only Facts(保留含事实的轨迹) | 30.2 (+8.2%) | 58.4 (+2.6%) |
| Only Correct Facts(保留含正确事实的轨迹) | 31.3 (+12.2%) | 59.8 (+5.1%) |
在测试时,如果我们能判断推理轨迹中的事实是否正确(比如通过外部知识库验证),然后只保留那些包含正确事实的轨迹,准确率可以在 SimpleQA 上提升 12.2%。这是一个在工程上非常实用的策略。
六、暗面:幻觉的传播链
6.1 生成式自检索的代价
事实启动是一把双刃剑。当模型在推理中生成了正确的中间事实,正确答案更可能被检索到;但如果模型生成了错误的中间事实(幻觉),情况就完全反转了。
作者对推理轨迹中的事实陈述进行了真实性标注,然后统计了包含幻觉事实 vs 不包含幻觉事实的轨迹的最终答案正确率:
| 轨迹类型 | SimpleQA 正确率 | EntityQuestions 正确率 |
|---|---|---|
| Clean(无幻觉中间事实) | 41.4% | 71.1% |
| Hallucinated(有幻觉中间事实) | 26.4% | 32.2% |
差距触目惊心。在 EntityQuestions 上,包含幻觉事实的轨迹,最终答案正确率从 71.1% 骤降到 32.2%——砍掉了一半多。
6.2 问题内对比:排除混淆因素
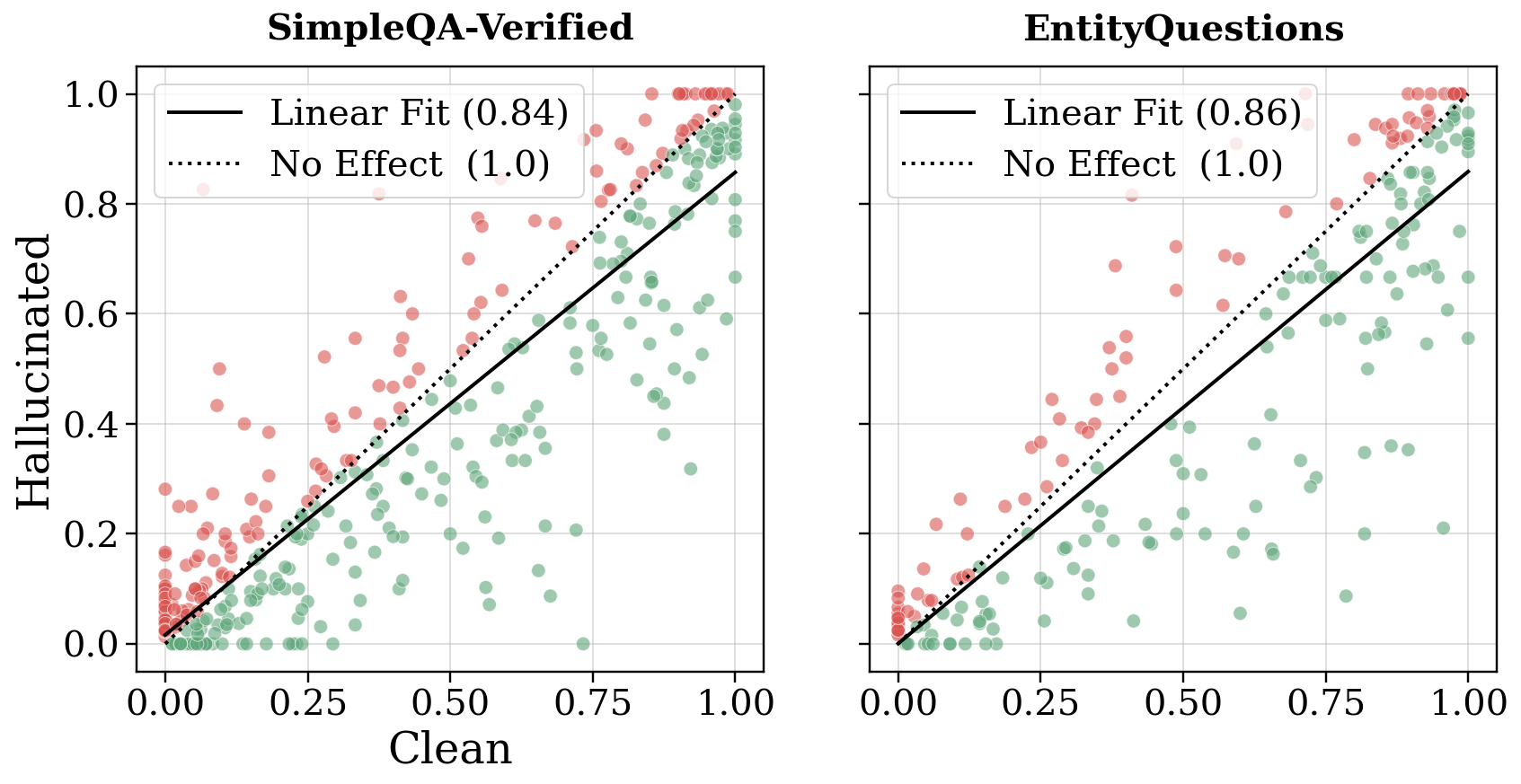
一个合理的质疑是:“也许产生幻觉的轨迹本身就对应更难的问题,所以正确率低不是因为幻觉,而是因为问题难。”
为了排除这个混淆因素,作者做了一个精细的问题内对比:对于同一个问题的多次采样(k=100),分别统计 Clean 轨迹和 Hallucinated 轨迹的正确率,然后做回归分析。
上图中,每个点代表一个问题。X轴是该问题下 Clean 轨迹的正确率,Y轴是 Hallucinated 轨迹的正确率。如果幻觉没有影响,点应该分布在对角线上。实际结果是:
- 回归斜率 0.84(SimpleQA)和 0.86(EntityQuestions),均显著小于 1
- 大部分点落在对角线下方(红色),即 Hallucinated 轨迹的正确率系统性地低于 Clean 轨迹
这意味着,即使控制了问题难度,幻觉中间事实依然会显著降低最终答案的正确率。幻觉不是"弱问题"的副产品,而是一个独立的伤害因素。
6.3 幻觉传播的机制
这个发现的深层含义是:推理模型中存在一条"幻觉传播链"。模型在推理中生成的中间内容不是"写完就扔"的草稿,而是会反过来影响后续生成的锚点。一个错误的中间事实会把模型的"检索方向"带偏,就像考试时在草稿纸上写错了一个公式,后面的计算就全歪了。
这对推理模型的部署提出了严肃的警告:推理时间越长、中间步骤越多,幻觉传播的风险也越大。盲目增加推理长度不仅浪费token,还可能适得其反。
七、个人分析与思考
7.1 这篇论文做对了什么
首先,实验设计的严谨性值得学习。作者没有简单地对比 ON 和 OFF 的准确率然后宣布"推理有用",而是通过 pass@k 指标区分了"知识边界扩展"和"输出稳定性提升",通过 Dummy 实验分离了"计算缓冲"和"语义内容"两个变量,通过问题内对比排除了"问题难度"这个混淆因素。每一步都在做减法,层层剥离,最终锁定因果关系。这是做机制研究的典范。
其次,实用价值明确。推理轨迹选择策略(Table 1)是一个可以立刻落地的工程方法。在RAG系统中,我们可以对模型的推理轨迹进行事实性验证,优先采用包含正确中间事实的轨迹,这比单纯的 self-consistency(多数投票)更有针对性。
7.2 局限与疑问
模型覆盖范围有限。实验只用了三个模型(两个 Gemini + 一个 Qwen),且都是"混合模型"。对于 DeepSeek-R1、OpenAI o系列这些纯推理模型,结论是否成立还需验证。特别是,不同模型的推理训练方式不同(RLHF、GRPO、蒸馏),计算缓冲和事实启动的相对贡献可能会有显著差异。
因果方向的不确定性。幻觉传播实验虽然控制了问题难度,但仍存在一种可能:模型在某些采样中"状态不好"(比如注意力分布的随机波动),同时导致了中间幻觉和最终错误,而不是幻觉"导致"了错误。要彻底确认因果方向,可能需要更激进的干预实验,比如人为向 Clean 轨迹注入假事实。
计算缓冲的理论解释不够深入。论文证明了计算缓冲效应的存在,但没有深入探讨其神经网络层面的机制。这些额外的前向传播到底激活了什么?是注意力头的重新组合?是MLP层中的知识路径切换?这些问题需要更细粒度的 mechanistic interpretability 研究来回答。
7.3 对工程实践的启示
1. 推理预算分配策略
既然计算缓冲在 ~2048 tokens 处饱和,那对于简单事实问题,可以设计一种"轻量推理"模式:生成固定长度的推理 token(不需要是有意义的推理),然后直接输出答案。这比完整推理节省大量 token,同时保留了计算缓冲的收益。
2. 推理轨迹的质量监控
幻觉传播的发现意味着,在生产环境中对推理轨迹进行实时的事实性检查是有价值的。可以设计一个轻量级的 fact-checker,在推理过程中监控中间事实的可靠性,一旦检测到幻觉,就截断当前轨迹并重新采样。
3. RAG + 推理的协同设计
事实启动效应暗示了一种新的 RAG 范式:不是把检索到的文档直接拼在 prompt 里,而是让模型在推理阶段"自主检索"相关事实。当然,这需要模型具备可靠的参数化知识。一个折中方案是:先用 RAG 检索相关事实,然后以"推理轨迹"的形式注入,模拟事实启动效应。
4. 推理蒸馏的新视角
如果推理的核心价值不仅是逻辑分解,还包括知识激活,那推理蒸馏(把大模型的推理能力迁移到小模型)的策略可能需要调整。传统的蒸馏关注"推理步骤的正确性",但这篇论文提示我们也应该关注"推理过程中事实召回的丰富性"。
八、总结
这篇论文回答了一个看似简单实则深刻的问题:为什么让大模型"思考"能帮它回忆起更多事实?
答案分为两层:
- 计算缓冲:推理 token 提供了额外的前向传播步骤,让模型有更多机会从参数深处"挖掘"出正确答案。哪怕这些 token 是废话也有效。
- 事实启动:推理过程中生成的相关事实充当"语义桥梁",激活了正确答案所在的参数区域。这是推理收益的主要来源。
但天下没有免费的午餐。推理过程中的幻觉中间事实会反向传播,显著降低最终答案的正确率。推理模型不是"想得越多越好",而是"想得对才行"。
从更宏观的视角看,这篇论文揭示了一个深刻的洞察:推理和记忆在 LLM 中不是割裂的两个模块,而是深度耦合的。推理不仅服务于逻辑推导,更是知识检索的催化剂。这改变了我们对"推理模型到底在做什么"的理解——它们不只是在"思考",也在"回忆"。
或者用一句更接地气的话说:大模型的"推理",本质上是给自己出了一张"联想草稿纸"。草稿纸上写的内容越相关、越准确,最终的回忆就越可靠。但如果草稿纸上写满了胡话,那还不如不写。
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)