终于有人把 AI Memory 讲透了!2026 最新综述:4W分类与多智能体记忆机制全攻略,建议全文收藏!
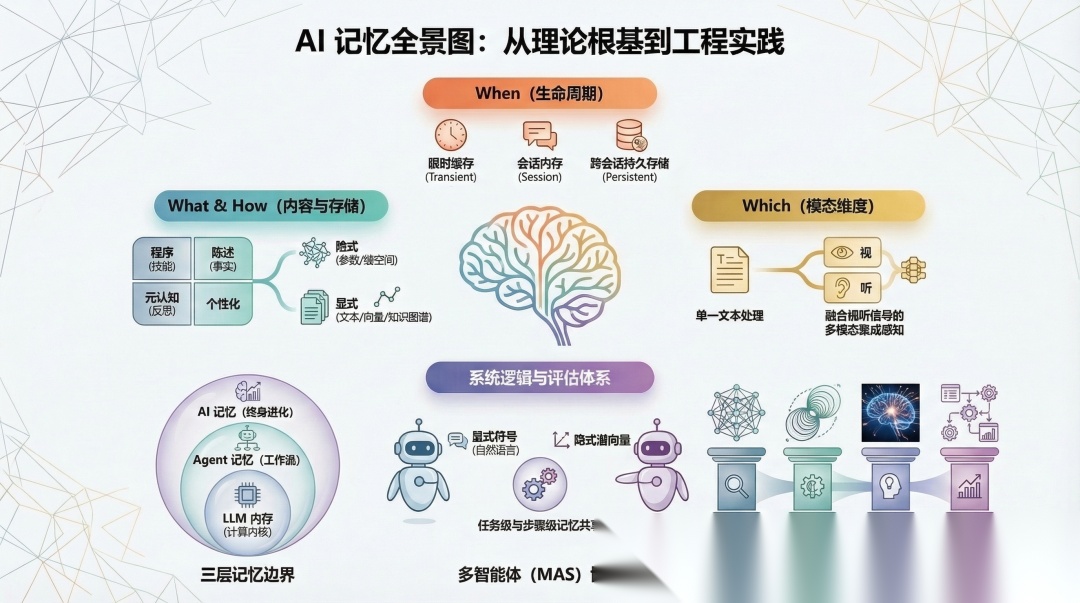
上面这张图基本就是整篇论文的中文导读版:中间是 4W 分类和三层边界,下面是多智能体协作与四维评估,左右两侧分别是内容/存储、模态,以及单智能体到多智能体的展开。
如果只抓论文的主线,可以概括成一句话:
这篇综述想做的,是把零散的 memory 研究,从“很多方法”整理成“一个可以对齐讨论的问题空间”。
为什么今天还要单独讨论 AI Memory
论文的出发点很直接。
随着 LLM-driven agents 进入真实场景,系统正在从“一次性任务执行”转向“continuous adaptation、evolving capabilities、accumulation of experiences”。但标准 LLM 仍然有两个结构性限制:
- • 上下文窗口有限,很难承载超长文本和跨会话交互
- • 缺少历史经验的有效积累与复用机制,系统天然是 stateless 的
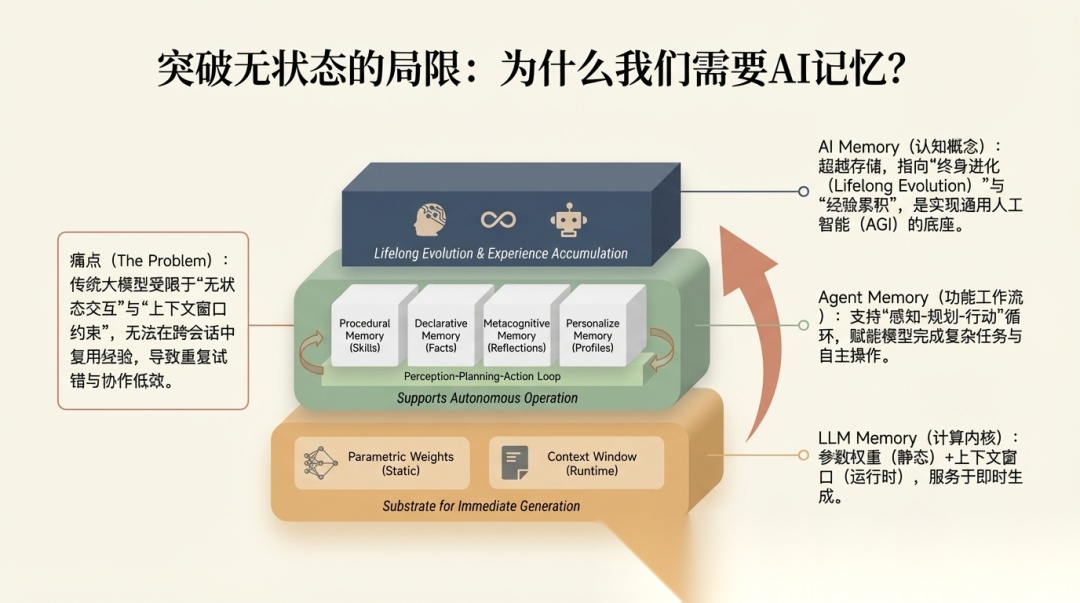
论文的判断是,AI memory 的价值远不止“记住用户偏好”这么小。它本质上是帮系统从 reactive processing(你问我答)走向 proactive intelligence(主动规划、主动优化)。实际案例也在印证这一点:OpenAI 在 2024 年给 ChatGPT 加上了 Memory 功能,跨会话记住用户偏好;开源社区这边,MemoryOS 框架率先提出了“记忆操作系统”的概念,把记忆的存储、更新、检索、生成统一抽象成一套接口。
论文还特别拉出了三个层级的区分,这个很关键:
- • LLM Memory:低层的 computational kernel,主要包括参数化记忆和运行时上下文窗口
- • Agent Memory:围绕 perception-planning-action loop 组织起来的 functional workflow
- • AI Memory:更高层的 cognitive concept,强调 lifelong evolution、long-term persistence 和 adaptation
后面全文基本都是从这个边界划分展开的。
顺带说一下,论文在这里还厘清了几组容易混淆的概念:
- • Memory vs Knowledge:Memory 是动态的、有时间戳的、随交互演化的;Knowledge 是稳定沉淀下来的事实和模式。两者之间有转化关系——被反复验证的 memory 可以巩固成 knowledge。
- • Memory vs Context:Context 只是当前推理窗口里的临时缓冲,用完就丢;Memory 是持久化的应用层状态,跨会话存在。
- • Memory vs Experience:Memory 是原始记录(“发生了什么”),Experience 是从原始记录里蒸馏出来的高阶认知(“学到了什么”)。
这几组区分看起来简单,但在实际系统设计里经常被搅成一团。论文把它们拆开说,对后面的分类和架构讨论很有帮助。
理论基础:论文不是直接从向量库开始讲
这篇综述没有直接从工程组件往下拆,而是先回到认知心理学和神经科学。
论文在 Theoretical Foundations 里重点引了三套基础:
- • Atkinson-Shiffrin Tri-Store Model
- • Working Memory Model
- • Complementary Learning Systems Theory, CLS
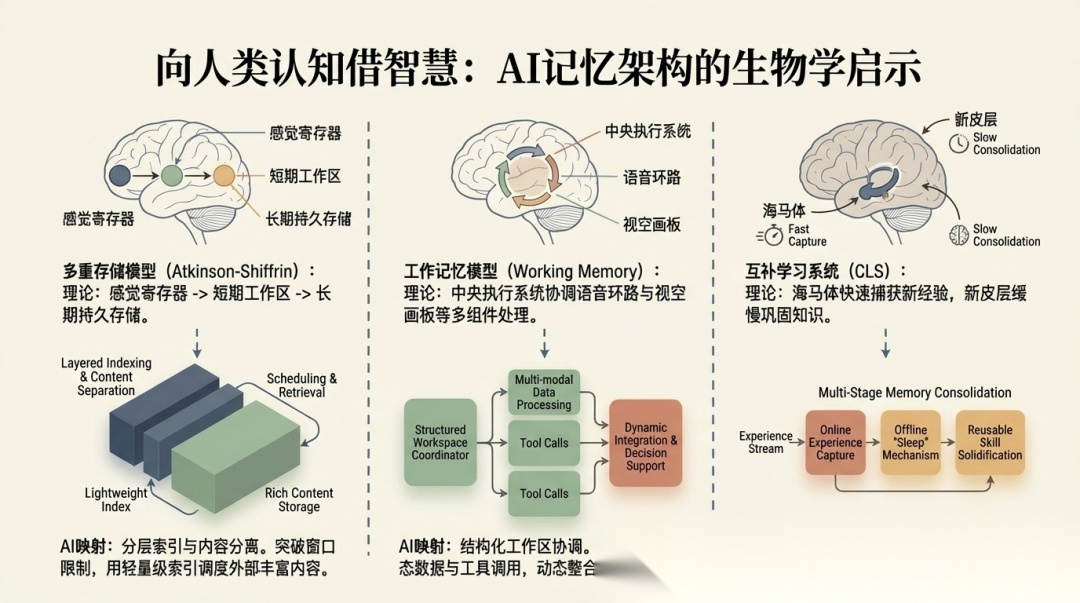
基于这三套理论,论文抽出了三个对 AI 系统非常有用的设计模式:
1. Index and content separation
也就是索引与内容分离。
简单说就是不要把所有东西都塞进工作上下文。维护紧凑的 episodic keys 做索引,真正需要的时候再通过 retriever 把详细内容拉回来。MemoryOS 就是这个思路——用轻量索引动态调度外部存储块进有限的 context window。
2. Multiphase consolidation
也就是多阶段巩固。
刚发生的事不必立刻写入长期记忆。更好的做法是经过 summary → reflection → skill extraction 这样的多阶段处理,逐步蒸馏成更通用的长期知识。Generative Agents 的"反思"机制和 Voyager 的技能库都是这个思路的具体实现。
3. Structured workspace coordination
也就是结构化工作区协调。
工作记忆不是一个单一缓存,而是多组件、多缓冲区的协调系统——语言走语言的通道,视觉走视觉的通道,中间有个"中央执行器"统一调度。对应到 Agent 设计,就是 M3-Agent 那种由 controller 统一协调感知、记忆、行动模块的架构。
一句话概括这一节:AI memory 不是单一存储问题,而是组织、调度、巩固与协调问题。 搞清楚这个,后面很多设计选择就自然了。
4W Memory Taxonomy:这篇论文最核心的框架
这部分是全文最核心的贡献。论文提出了一套 4W Memory Taxonomy,用四个问题把所有 memory 工作拉到同一个坐标系里。
它对应四个核心问题:
- • When:记忆存在多久,能被访问多久
- • What:记忆捕获什么信息
- • How:记忆如何表示与存储
- • Which:记忆处理哪种信息模态
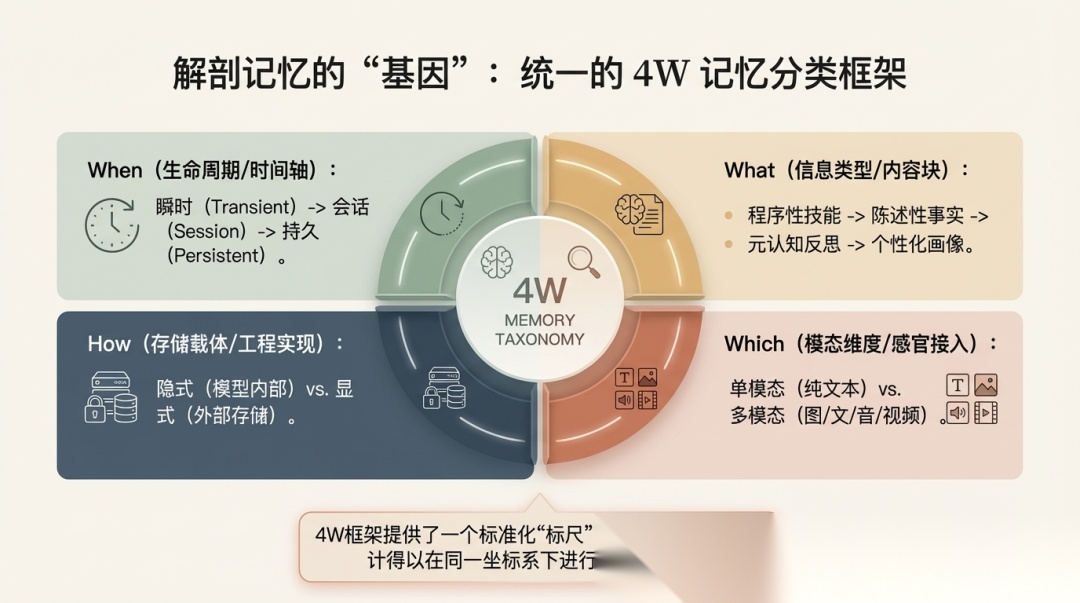
这套框架真正有用的地方不是多了几个名词,而是它把很多原本混在一起讨论的问题拆开了——你说的"记忆"到底是哪个维度的?
1. When:生命周期

生命周期分成三类:
- • Transient memory
- • Session memory
- • Persistent memory
其中 transient 更像即时处理阶段的输入缓冲,session 对应一次任务或一次会话中的 working memory,persistent 则强调跨会话、跨任务、长期可复用。
2. What:记忆类型
Memory type 分成四类:
- • Procedural memory:技能、行动序列、工具调用方式
- • Declarative memory:事实、事件、观察
- • Metacognitive memory:反思、自我能力评估、表现跟踪
- • Personalized memory:用户偏好、关系、画像
这四类里,前两类最常见,后两类是很多 Agent 系统开始真正“长期化”之后才会变得重要的部分。
3. How:存储形式
How 分成两大类:
- • Implicit storage:parametric、latent
- • Explicit storage:raw memory、vector database、structured graph
4. Which:模态维度

模态分成:
- • Single-modal memory
- • Multimodal memory
这里论文专门提到 Socratic Representation Paradigm。也就是用 multimodal-to-text 的方式,把异构模态先转成结构化文本,再以语言作为统一中介来存储和检索。
这是目前多模态 memory 中一条越来越受关注的表示路线。
单智能体部分:论文系统梳理了四类架构
到了单智能体部分,论文先总结了四类主流架构范式:
- • Hierarchical architectures
- • OS-like architectures
- • Cognitive-evolution architectures
- • Graph and temporal architectures
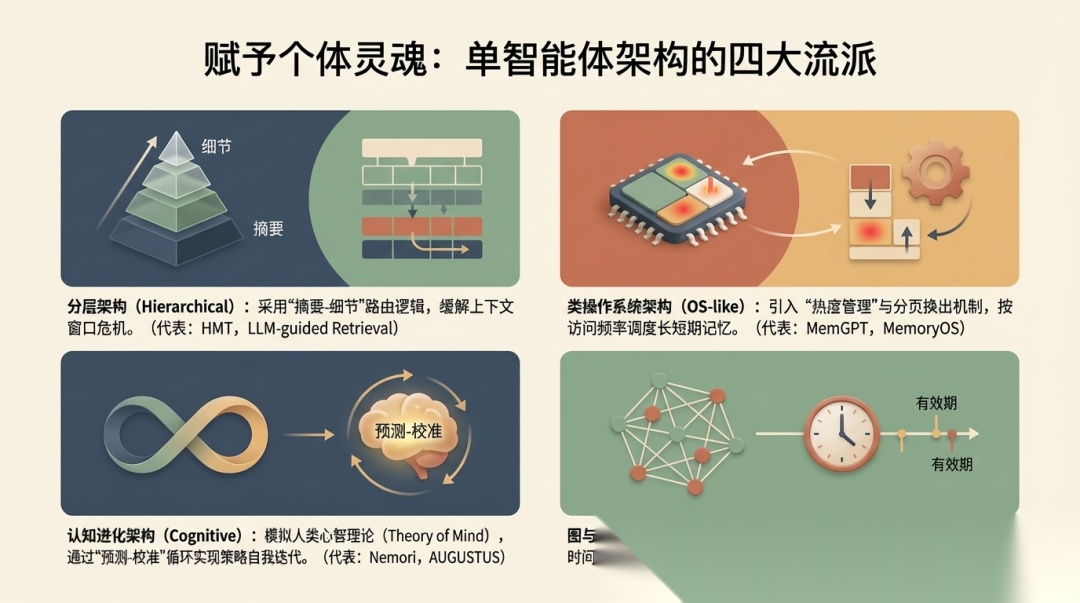
简单理解就是:
-
• Hierarchical:通过摘要层和细节层缓解上下文窗口压力
-
• OS-like:把 memory 当成可调度资源,强调换入换出和统一管理
-
• Cognitive-evolution:强调预测、校准、反思和自我迭代
-
• Graph/Temporal:用图结构和时间轴处理实体关系、状态变化和多跳推理
-

• Basic functions:Storage、Retrieval、Updating
-
• Advanced functions:Evolution、Association
其中 Updating 是论文讲得比较细的一部分。它把 updating 分成四种:
- • incremental updates
- • corrective updates
- • consolidation updates
- • forgetting updates
这个分类很重要,因为它说明 memory 不是“写进去就结束”,而是一个持续 revising、replacing、consolidating 的动态过程。
再往上一层,论文还讨论了两个高级能力:
- • Self-Evolution:把原始经历逐渐蒸馏为可复用的 skills、policies、prompts
- • Association:把文本、视觉、音频、时间、实体等碎片线索整合成 coherent situational models
也就是说,memory 在这里已经不只是“记住过去”,而是在支持系统把过去变成后续能力。
多智能体部分:重点不再是个体记忆,而是共享机制
论文在单智能体部分的结尾甩出了一个问题:现有的 memory 架构基本都是给单 Agent 设计的。直接搬到多智能体场景,就会出现三类结构性失败:
- • memory misalignment
- • the redundancy cycle
- • stagnation of collective intelligence
这三个问题,就把话题自然地引到了多智能体记忆。
第一部分:Communication Mechanisms
论文把通信分成了两大类:
- • explicit communication
- • implicit communication
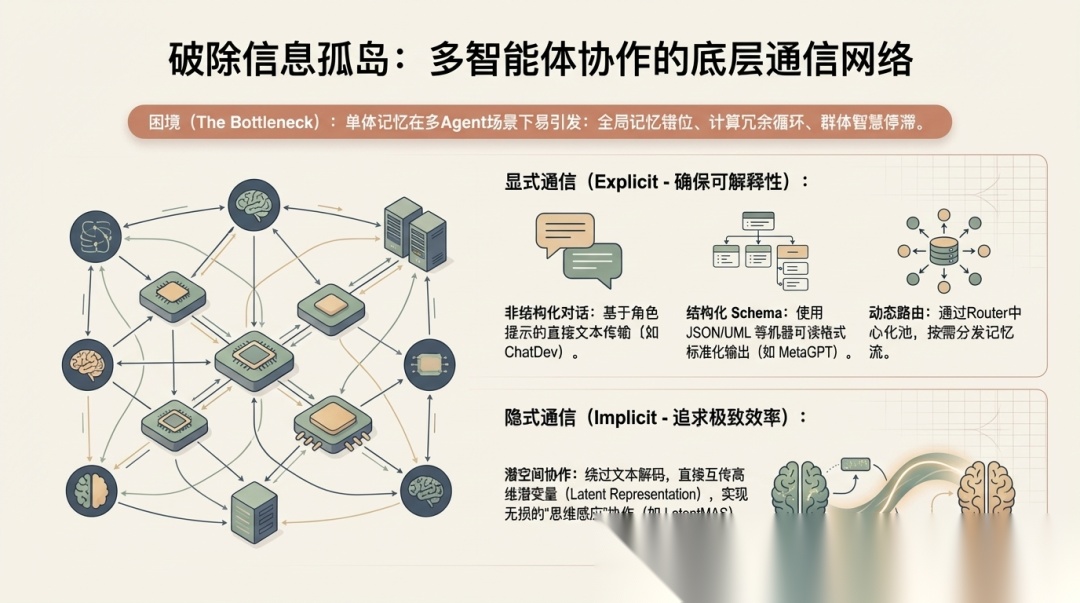
其中 explicit communication 又覆盖了一条连续谱:
- • 非结构化自然语言
- • 结构化 schema
- • 动态分配与路由
implicit communication 则更接近 latent representation、dense communication、thought-to-thought 这条路线,目标是减少自然语言解码带来的开销。
第二部分:Memory Sharing Mechanisms
共享机制按粒度分成两类:
- • Task-Level Memory Sharing
- • Step-Level Memory Sharing
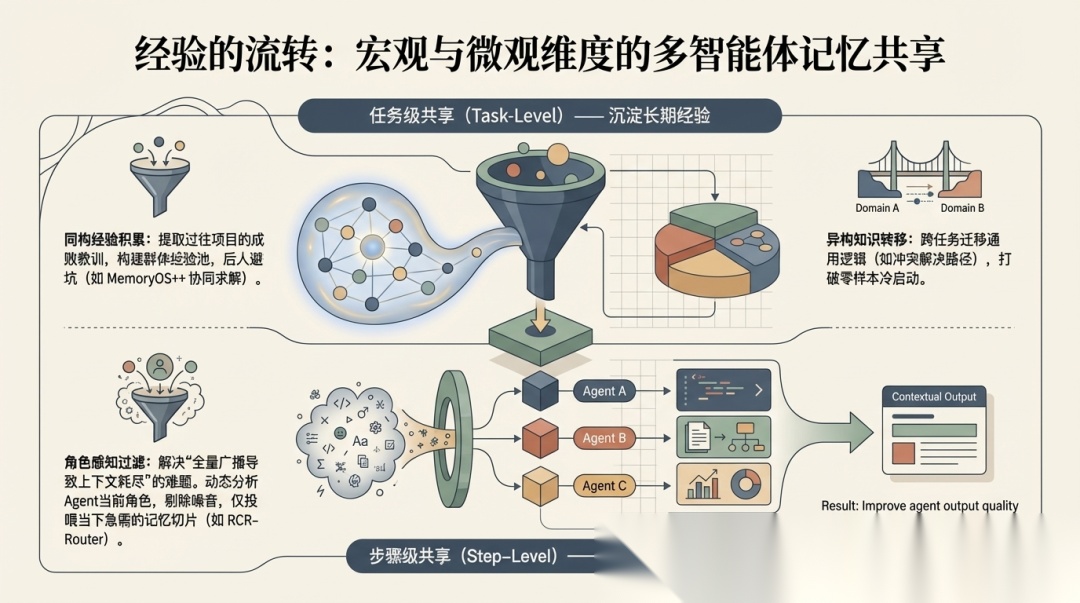
区分很直观:
- • task-level 关注 knowledge retention、experience transfer 和 longitudinal evolution
- • step-level 关注 granular workflow 中的信息精确分配
step-level 里有个关键问题值得展开说一下:noise-context trade-off。
如果把全局状态广播给所有 Agent,很快就会造成上下文膨胀和注意力稀释。所以 RCR-Router 这类 role-aware context routing,实际上是在优化协作中的信息流,而不是单纯做检索。
评测部分:论文给出了一套比较完整的评价坐标
评测这部分,很多综述会一笔带过,但这篇论文花了整整一节来讲。它先承认了一个事实:这个方向目前缺乏统一标准。然后给出了一套四维 taxonomy:
- • Memory Retrieval Capability
- • Dynamic Updating Capability
- • Advanced Cognitive Capability
- • System Efficiency
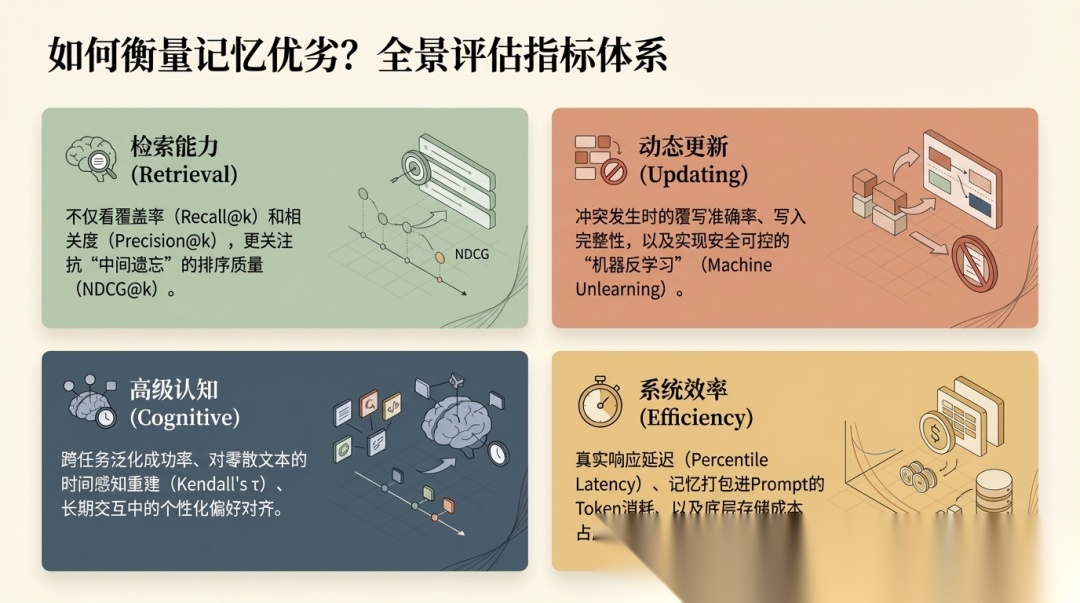
这四类下面,论文又列了相对具体的评价对象和 benchmark。
例如:
- • 静态检索能力:LoCoMo、LongBench、RULER
- • 动态更新能力:MemoryAgentBench、MemoryBench、HaluMem
- • 个性化长期记忆:LongMemEval、PERSONAMEM
- • 多模态记忆:Video-MME、MLVU、LVBench、EgoSchema
除了 benchmark 列表,论文还点出了评测里三个真正棘手的问题:
-
- dataset construction 成本高
-
- performance attribution 很模糊
-
- evaluation metrics 缺少统一而动态的标准
第二点在实际开发中尤其扎心——一个任务失败了,到底是 memory retrieval 出错还是 reasoning/planning 出错?现有的 benchmark 基本分不清。这也是为什么论文专门把评测纳入统一讨论:如果测不准,做什么优化都是盲人摸象。
应用部分:论文把场景分成单体与多体两大类
在 Section 7,论文没有只停在理论层面,而是把具体的 memory-enabled 应用分成了两大类:
- • Single-Agent Memory Applications
- • Multi-Agent Memory Applications
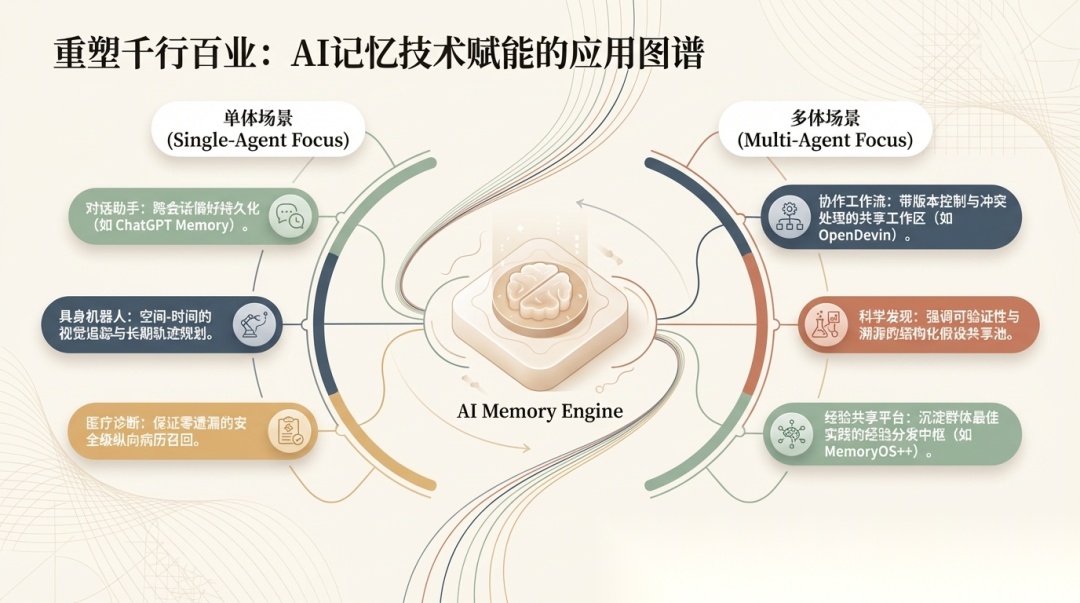
单体场景里,论文提到的方向都很具体:
- • 对话助手:ChatGPT Memory、Claude memory tool、MemGPT、BaiJia MemoryOS——都在做跨会话的用户画像和偏好持久化
- • 具身机器人:Voyager 在 Minecraft 里攒技能库,Home-Robot 做物体级空间记忆
- • 医疗诊断:Doctor AI 基于多次就诊的 EHR 时序做风险预测,Ada Health 和 Buoy Health 跨会话保持症状历史
- • 推荐系统:Amazon Personalize 和 Google Gemini 都在做基于长期交互历史的偏好漂移适配
多体场景里,重点则变成了协作和共享:
- • 协作工作流:MetaGPT、AutoGen、CrewAI 这些框架都在用共享 workspace 做多 Agent 协调,核心是并发控制和产出溯源
- • 科学发现:SciAgents 和 PaperQA 通过带出处的结构化知识库让多个 Agent 共建可追溯的推理链
- • 金融决策:FinGPT、OpenBB 在维护时间敏感的共享信念状态,同时保证每条建议都能追溯到证据
- • 经验共享平台:MemoryOS++ 是论文里提到的第一个专门做群体经验共享的平台,把个体记忆升级成可跨用户复用的群体经验池
不管是单体还是多体,论文想说的都是同一件事:memory 不是锦上添花,而是让 Agent 在真实场景中真正可用的底层支撑。
挑战与未来方向:论文最后把问题收在三类挑战和三条趋势上
论文把当前面临的障碍归成三类:
- • architectural conflicts
- • theoretical and methodological challenges
- • security risks and operational complexities
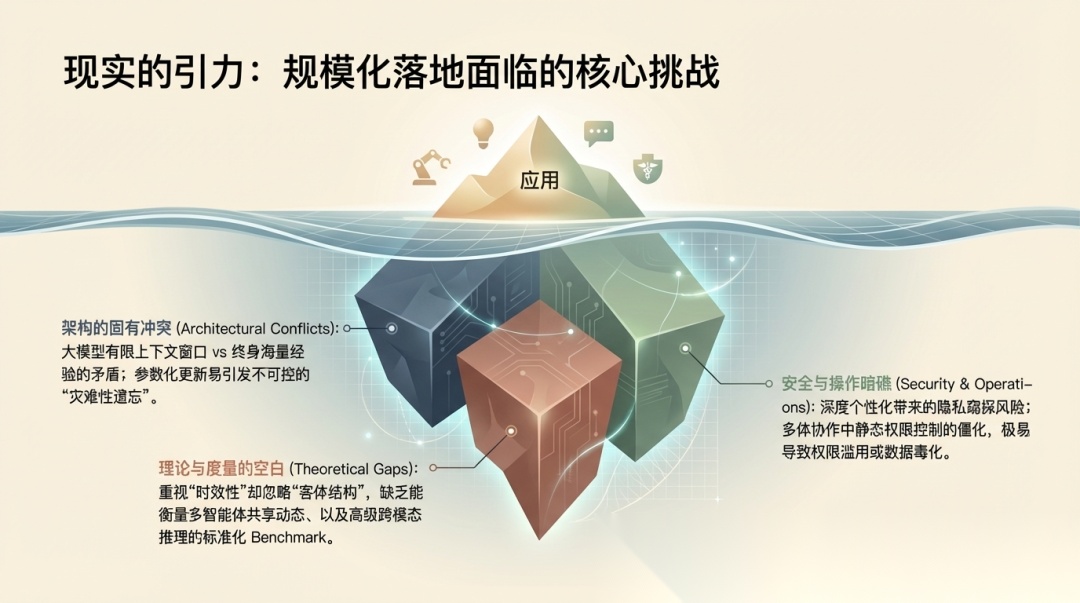
翻译成工程语言就是:
- • 大模型上下文窗口和终身海量经验之间的结构冲突
- • 对 memory 本身的理解仍不完整,评测标准也不成熟
- • 个性化与共享 memory 带来的隐私、权限、治理与运维复杂性
至于未来往哪走,论文给了三条主线:
- • brain-inspired mechanisms
- • from memory to experience
- • self-evolving collective memory

其中最核心的一句话:memory architectures must evolve from passive retrieval to active adaptive systems。下一阶段不再只是“把过去取回来”,而是:
- • 用更接近类脑机制的方式处理稳定性与可塑性的平衡
- • 把 unstructured logs 变成 structured priors
- • 让共享记忆从 global blackboard 走向更安全、更稳健的 collective memory
架构师怎么用这套框架:4W 变成设计决策
读到这里,理论和分类都讲完了。但如果我今天就要设计一个 Agent 的记忆系统,这篇论文到底能给我什么直接可用的东西?
我试着把 4W 框架翻译成四个架构决策问题,结合论文里提到的系统做了个对照:
决策 1:When — 你的记忆需要活多久?
| 场景 | 生命周期选择 | 典型实现 |
|---|---|---|
| 实时感知/预处理 | Transient | KV Cache、输入缓冲 |
| 单轮任务/单次会话 | Session | Context Window、ReAct 的 think-observe-act loop |
| 跨会话个性化/长期助手 | Persistent | MemoryOS 的分层存储、Mem0 的外部记忆库、Zep 的时序知识图谱 |
大部分实际系统不会只用一种。论文里的 MemoryOS 就是典型的三层结构:短期(session buffer)→ 中期(热度分页)→ 长期(用户画像 + 事实沉淀),通过 heat score 动态决定什么时候做提升和淘汰。
决策 2:What — 你要存什么类型的记忆?
| 记忆类型 | 对应的系统能力 | 什么时候重要 |
|---|---|---|
| Procedural | 工具调用方式、任务分解计划 | Agent 需要复用动作序列时(如 Voyager 的技能库) |
| Declarative | 事实、事件日志、环境观察 | 需要精确事实回溯时(如医疗问诊的病历回溯) |
| Metacognitive | 反思、自我评估、策略反馈 | Agent 需要"从错误中学习"时(如 Reflexion) |
| Personalized | 用户偏好、画像、关系 | 长期助手、个性化推荐场景(如 ChatGPT Memory) |
这里有个很实际的观察:前两类在大多数系统里都有,后两类才是分水岭。 你的 Agent 能不能从失败中改进策略(Metacognitive),能不能记住不同用户的偏好差异(Personalized),决定了它到底是个"工具"还是个"助手"。
决策 3:How — 记忆用什么形式存?
| 存储形式 | 优势 | 劣势 | 适用场景 |
|---|---|---|---|
| Parametric(模型权重) | 推理时零检索延迟 | 更新代价大,灾难性遗忘 | 静态基础知识 |
| Latent(隐状态) | 紧凑高效 | 不可解释 | 全局语义压缩(如 MemoRAG) |
| Raw Text | 最高可解释性,与 LLM 天然对齐 | 随规模增长检索效率下降 | 对话历史、日志存储 |
| Vector DB | 语义检索效率高 | 缺乏显式结构 | 大规模相似性召回(RAG 系统) |
| Structured Graph | 多跳推理,关系建模 | 构建和维护成本高 | 复杂关系网络、时序事件链 |
论文里一个值得注意的数据对比:Mem0 把对话压缩到约 7k tokens,而 Zep 的图存储因为在每个节点缓存完整摘要,膨胀到超过 600k tokens——是原始上下文的 20 倍以上。这意味着 “用了知识图谱"不等于"更高效”,存储形式的选择必须和压缩策略一起考虑。
决策 4:Which — 你需要处理哪些模态?
如果只做文本,论文的建议是用 结构化文本记忆架构(如分层组织、差异化更新策略),而非简单追加原始对话历史。
如果需要多模态,论文指出两条路线:
- • Raw Modality Representation:直接编码为高维 embedding,保真度高但存储开销大
- • Socratic Representation Paradigm:先把图像/音频/视频转成结构化文本描述,以语言为统一中介——存储开销小、可解释性强,但依赖多模态到文本的对齐质量
对于大多数生产系统,论文建议的 Socratic 范式更务实:先把异构模态统一成文本,再走文本记忆的成熟管线。
代表性系统对比:MemoryOS vs Mem0 vs Zep
论文里提到了几十个系统,但做选型时不可能全看。这里挑三个论文重点讨论的开源系统,用 4W 维度做个快速对比:
| 维度 | MemoryOS | Mem0 | Zep |
|---|---|---|---|
| When | Session + Persistent(三层分级) | Persistent | Persistent |
| What | Declarative + Personalized | Procedural + Metacognitive + Personalized | Personalized |
| How | Text + Vector | Text + Vector + Graph | Graph(时序知识图谱) |
| 架构隐喻 | 操作系统(分页调度) | 生产级记忆服务 | 大脑海马体(情景 + 语义子图) |
| 核心创新 | Heat-based 分页升降策略 | 摘要 + 选择性更新管线 | 双时间轴 + 社区摘要检索 |
| 存储效率 | 中等 | 高(~7k tokens 压缩) | 低(可膨胀到 600k+) |
| 适合场景 | 个性化对话助手 | 需要快速集成的生产 Agent | 复杂关系推理、多跳查询 |
结论很朴素:没有"最好的"记忆架构,只有最匹配场景的取舍。 MemoryOS 适合需要精细上下文管理的长期助手;Mem0 适合要快速上线的生产场景;Zep 适合关系密集型任务,但存储膨胀是个实际的坑。
从论文到系统设计:三条实操建议
最后聊三个我觉得最值得带走的点:
1. 不要只建"记忆存储",要建"记忆生命周期"
前面说过,Updating 被论文分成了四种——增量、纠错、巩固、遗忘。这不是学术分类游戏,每一种对应的工程实现完全不同。
落到设计上就是:从一开始就把 write / read / update / consolidate / forget 五个操作当成一等公民来建模,别全塞进一个 CRUD 接口。MemoryOS 的 heat-based 升降策略、LightMem 的 sleep-time consolidation(离线时整理去重压缩长期记忆),都是把这件事认真做的例子。
2. 多智能体系统的第一个设计决策是通信粒度,不是模型选择
前面已经提到了 noise-context trade-off——全局广播会撑爆 context、稀释注意力。这其实意味着:
- • task-level sharing 用于跨任务经验沉淀(适合异步、离线处理)
- • step-level sharing 用于工作流内精确分配(需要 role-aware context routing)
- • 不要用 “shared blackboard” 当万能方案,而是根据 Agent 角色做信息裁剪
- • 论文特别提到 RCR-Router 这类基于角色感知的上下文路由:优化的不是"检索",而是"协作中的信息流"
3. 评测不是加分项,是架构必须回答的问题
前面评测部分提到的"性能归因"问题,在工程上的翻译就是:一个任务挂了,你能分清是 memory 的锅还是 reasoning 的锅吗?
如果 memory 和 reasoning 之间没有可观测的边界,这个问题永远答不上来。所以架构上值得做的一件事是:显式分离 memory layer 和 reasoning layer 的接口,让 memory 的输出(取回了什么、命中率、延迟)变成可度量的中间状态。论文给的四维评测框架(retrieval / updating / cognitive / efficiency)直接就能当你的监控仪表盘用。
写在最后
最后回到论文本身。如果只记一句话:
AI memory is not merely static storage, but a dynamic cognitive substrate critical for continuous learning and adaptation.
对我来说,这篇综述最大的价值不是某个具体方案,而是它给了 一套把零散的 memory 问题组织成结构化设计空间的方法:
- • 用 4W 框架(When / What / How / Which)拆解需求
- • 用 三层边界(LLM Memory → Agent Memory → AI Memory)定位你在哪个层面做设计
- • 用 三个认知设计模式(索引与内容分离 / 多阶段巩固 / 结构化工作区协调)指导架构选型
- • 用 四维评测(检索 / 更新 / 认知 / 效率)验证你的系统是否真正有效
如果你最近在做 Agent 或 Multi-Agent 相关的系统设计,这篇论文是一张非常好的总地图。希望这篇推文能帮你更快地把图上的关键节点连起来。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献200条内容
已为社区贡献200条内容

所有评论(0)