大厂6年算法工程师亲授:小白也能快速入门大模型的最少必要知识
先跟大家自我介绍下,我有6年大厂算法工程师从业经验,2022年之前主要深耕CV(计算机视觉)和NLP(自然语言处理)两大方向,算是见证了传统AI的发展迭代;从2023年开始,我全面转向大模型领域,至今平均每年主导3个大模型相关核心项目,同时也深度参与组内其他重点项目,积累了从项目落地到团队协作的全套实战经验。
这些年,我既当过面试官,筛选过大模型方向的候选人,也作为候选人经历过行业竞争,前前后后的经历让我沉淀了很多实用干货。今天这篇内容纯粹是个人经验复盘分享,没有任何广告植入,可能会带有我个人的实战视角,大家理性参考、批判吸收就好。
我写这篇内容的目标很明确:不搞冗余铺垫,只告诉你最少、最必要,且能让你真正动手干起来的大模型入门知识。现在网上的大模型教程、技术文章五花八门,内容看似全面,但大多会列出一长串知识点清单,反而让新手无从下手,甚至产生学习焦虑,越看越迷茫。
我想帮大家跳出这个误区,聚焦在那些绕不开、面试必问、实际干活必需的核心知识点上。这里提前说明:如果你想系统地、学术化地夯实大模型理论基础,我的方法可能显得有些“功利”;但如果你是编程小白、刚接触AI的程序员,想快速摸到大模型的门槛,知道劲该往哪里使,少走弯路,那今天的内容绝对适合你,建议收藏反复看。
结合我6年的算法经验,尤其是近3年的大模型实战,我把入门大模型必须掌握的知识,梳理成了五大核心模块:数学基础、深度学习基础、大模型核心知识、计算机基础、数据工程。其中最重要、最急迫,也是和过去传统AI工程师区别最大的,就是第三块——大模型核心知识,新手可以优先攻克这部分。
第一,大模型核心,重中之重是Transformer
你必须彻底理解这个架构。我强烈建议你动手。学会怎么用自己电脑的CPU,去调试一个迷你版的大模型。真:正动手“跑”一遍,看着数据怎么流动、参数怎么更新,比你读十篇教程都管用。
它内部的数学核心,尤其是自注意力机制,你必须搞懂:它的计算过程和为什么它如此强大。
Transformer主要衍生出两个方向:以BERT为代表的Encoder-only架构,和以GPT系列为代表的Decoder-only架构。当前行业的主流是Decoder-Only,你需要重点理解它如何通过“掩码”实现单向生成。
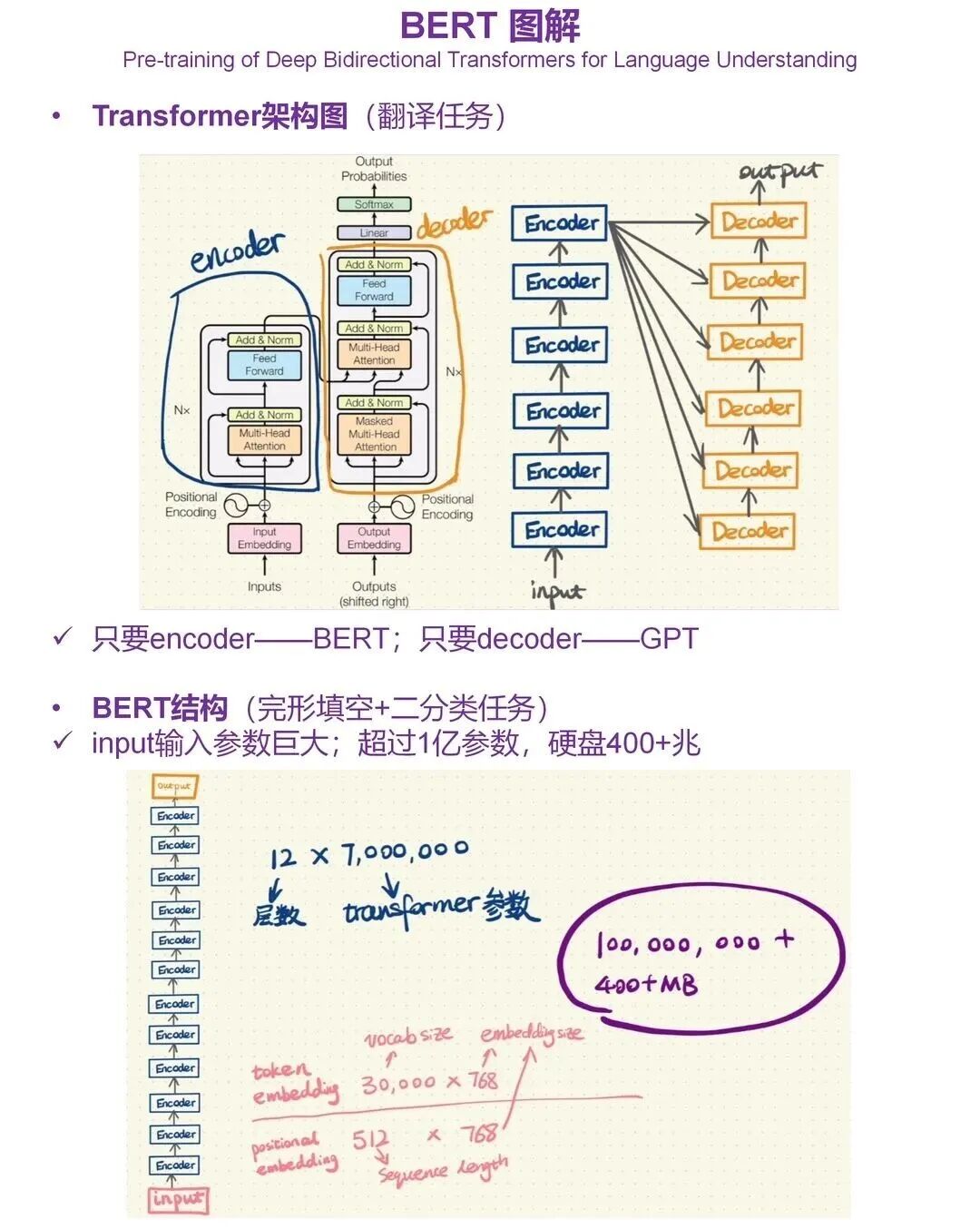
除了架构本身,还要理解位置编码和词嵌入这些基础组件是干什么的,它们是怎么让模型理解顺序和语义的。
工具生态上,HuggingFace和它的Transformers库是你未来最亲密的工具,尤其是Huggingface,所有一流的开源的数据集和模型都会放在上面。必须玩熟。这就像Python程序员要熟悉pip一样,它是获取开源模型、数据集和工具链的第一站,你要熟练掌握如何搜索、加载、使用和贡献。
在技术流程上,预训练和指令微调的原理要清楚。实话实说,很多人(包括我)都没机会参与从头预训练一个千亿参数模型的项目,这需要巨大的资源。但微调是你几乎:必然要接触的。
有哪些主流微调方法(全参数、LoRA、QLoRA等)?它们各自适用什么场景?这些面试120%会问。同时,混合精度训练和DeepSpeed这类框架的基本思想也要懂,它们是为了解决大模型训练中显存不足和速度慢的核心技术。
与训练紧密相关的还有显存与规模估算。这是非常实在的工程能力。给你一个几B参数的模型,你大概要估算需:要多少显存,怎么设置batch_size,要不要用梯度累积,大概需要几张卡才跑得起来。
面试官很喜欢问这类:问题,比如“训练一个13B的模型,在A100上大概要怎么配置?”这背后涉及到你对模型参数量、激活值、优化器
状态的内存占用,以及数据并行、张量并行等基础分布。式的理解。对齐技术方面,你不用去啃强化学习教材,但必须知道DPO、PPO这些方法是怎么被应用到大模型“对齐”上的,核心思想是什么。最好能亲手跑过一个简单的对齐代码项目,了解整个流程。
推理阶段,KVCache和模型量化是当前加速推理、降低部署成本的核心手段,你得明白它们解决了什么问题,以及大概是怎么实现的。评估和测评同样关键。模型训好了,怎么向老板或团队证明它有效?你需要知道常见的评估指标。
在文本生成任务中,ROUGE、BLEU这些自动指标虽然不完美,但依然是主流汇报依据。而对于模型本身的困惑度PPL,则是内部评估语言建模能力的重要标:准。理解这些指标的含义和局限,是必备技能。
对于分类任务,召回率、精确率、准确率、混淆矩阵无比重要。对于检测任务,MAP系列是基础中的基础。
RAG是解决模型知识幻觉和私有化问题的关键应用范:式,在应用中很重要,必须掌握一两个最基本的RAG方法。
第二,深度学习基础
梯度下降及其变种是训练的基石。损失函数是模型的“指挥棒”,你得理解交叉熵、均方误差这些常见损失函数,以及它们如何引导模型学习。
Dropout、层归一化、残差连接、各种优化器、学习率调度这些经典概念也必须牢牢掌握,它们是构建和稳定深度网络的工具箱。卷积神经网络的基础也要了解,因为在多模态模型中,处理图像的部分其骨干网络可能还是CNN的变体或受其启发。
至于RNN和LSTM,我的建议是,你不必再花大量时间深究其代码实现和复杂公式,但一定要了解其基本思想和工作机制。因为面试中一个非常经典的问题是:“为什么:Transformer能几乎取代RNN?”
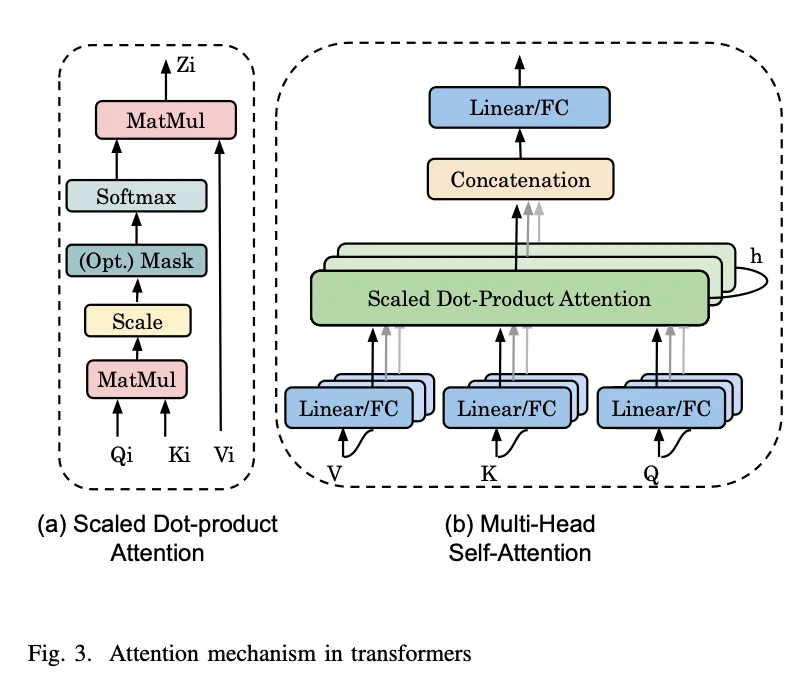
这时候,如果你能从并行计算能力和长程依赖建模这两个根本痛点出发,对比解释Transformer的优势,会显得你的理解非常深刻。了解旧技术,是为了更懂新技术的革命性。
传统机器学习,比如支持向量机、线性/逻辑回归,在我的大模型研发项目里确实没有直接用过,面试中也极少被问到。
但这很可能是一种幸存者偏差。如果你时间极度紧张,急于入门,可以先跳过它们的实现细节;但我强烈建议你在之后,抽空了解一下支持向量机这类经典算法的核心思想(比如“最大间隔”),这对你形成完整的机器学习直觉非常有好处。
第三,数学基础:
我默认你大学里学过微积分、线性代数、概率论,并且考试通过了。但“学过”和“在AI中能用”是两码事,你必须重新激活并熟练运用以下核心:
线性代数:重点是矩阵乘法、转置、求逆等运算,以及张量的概念。我们的模型参数、输入数据、中间激活值全都是张量,这是所有计算的载体。概率论:这是我认为最重要的数学分支。
条件概率、贝叶斯定理、常见概率分布(如正态分布),这些思想在理解模型的不确定性、生成过程、损失函数设计时无处不在。微积分:核心是求导和链式法则。这是梯度下降和反向传播的理论根基,是所有模型赖以训练和优化的基础。
第四,计算机与工程基础:
四件套:Python、PyTorch、Git、Linux。_Linux是模型训练和部署的主流环境,基本的文件操作、进程管理、环境配置命令必须熟练。

CUDA和显卡的基础知识也要了解,起码要知道你的代码是怎么在GPU上加速的,如何监控GPU利用率和显存使用,这是效率分析和问题排查的前提。
第五,数据工程
还有一个极其重要但常被新手忽视的方面:数据工程。在实际项目中,你可能要花50%甚至更多的时间在和数据:打交道:高质量的训练数据从哪里来?怎么清洗和过滤低质文本?如何对海量数据进行高效去重?
构造指令对时,指令和回复怎么配比效果更好?这部分经验非常依赖实践,是最难通过理论课教授的,往往需要在真实工作中:踩坑积累。但你必须意识到它的重要性,它直接决定了模型性能的上限。
补充:关于读论文
面对层出不穷的新论文,不必每篇都逐字精读,可以善用大模型帮你总结摘要和核心贡献,保持对领域动向的敏感,在需要时再深入阅读原文。
补充:关于Agent
Agent(智能体),在我个人的定位里,它们更偏向“大模型应用工程师”的核心技能,和我聚焦的“大模型算法工程师”侧重点有区别:
算法工程师(我聚焦的):更偏向“炼模型”。核心是怎么训练/微调/对齐一个更好的模型基座,研究的是模型本身的能力边界、ScalingLaw、高效训练和底层优化。这是所有上层应用的地基。
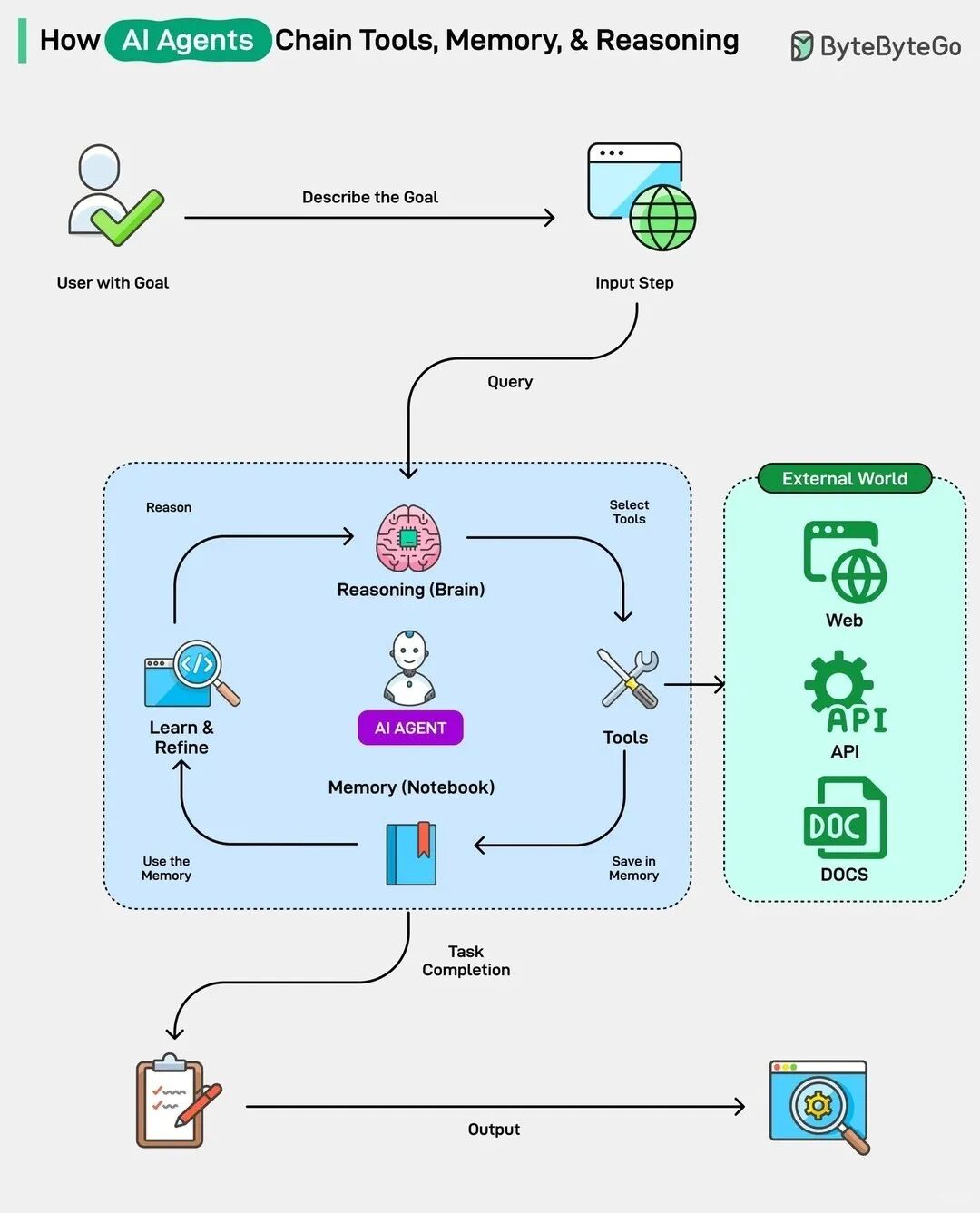
应用/Agent工程师:更偏向 “用模型”。核心是怎么基于现有模型基座(比如调用API或开源模型),结合外部工具(搜索、代码、APl)和知识(RAG),构建出能自动完成复杂:任务的智能体系统。这是在地基上盖高楼。
当然,这个界限正在模糊。优秀的算法工程师必须懂应用方向(否则不知道优化目标),优秀的应用工程师也必须懂算法基础(否则不会调优模型)
总结一下,最少必要的知识就是:吃透Transformer,玩转PyTorch和HuggingFace生态,搞懂微调/对齐/评估的完整流程,掌握显存估算和数据工程意识,激活核心数学,熟练Python+Linux四件套。
这里给大家精心整理了一份全面的AI大模型学习资源,包括:AI大模型全套学习路线图(从入门到实战)、精品AI大模型学习书籍手册、视频教程、实战学习、面试题等,资料免费分享!
👇👇扫码免费领取全部内容👇👇

1. 成长路线图&学习规划
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
这里,我们为新手和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的学习成长路线。
2. 大模型经典PDF书籍
书籍和学习文档资料是学习大模型过程中必不可少的,我们精选了一系列深入探讨大模型技术的书籍和学习文档,它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。(书籍含电子版PDF)

3. 大模型视频教程
对于很多自学或者没有基础的同学来说,书籍这些纯文字类的学习教材会觉得比较晦涩难以理解,因此,我们提供了丰富的大模型视频教程,以动态、形象的方式展示技术概念,帮助你更快、更轻松地掌握核心知识。

4. 2026行业报告
行业分析主要包括对不同行业的现状、趋势、问题、机会等进行系统地调研和评估,以了解哪些行业更适合引入大模型的技术和应用,以及在哪些方面可以发挥大模型的优势。

5. 大模型项目实战
学以致用 ,当你的理论知识积累到一定程度,就需要通过项目实战,在实际操作中检验和巩固你所学到的知识,同时为你找工作和职业发展打下坚实的基础。

6. 大模型面试题
面试不仅是技术的较量,更需要充分的准备。
在你已经掌握了大模型技术之后,就需要开始准备面试,我们将提供精心整理的大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

7. 资料领取:全套内容免费抱走,学 AI 不用再找第二份
不管你是 0 基础想入门 AI 大模型,还是有基础想冲刺大厂、了解行业趋势,这份资料都能满足你!
现在只需按照提示操作,就能免费领取:
👇👇扫码免费领取全部内容👇👇

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献64条内容
已为社区贡献64条内容

所有评论(0)