大模型+材料科学:武大团队用LLM框架解锁6万篇文献的因果机制密码
文章摘要
厘清材料的加工工艺、微观结构、理化性能与实际使用效能之间的相互作用规律,是指导材料设计与新材发现的关键。然而,串联起这些要素的因果作用机制,往往分散于文献的文本、图表和参考文献中,目前对这类知识开展系统性挖掘与整理的相关研究仍较为有限。本研究基于大语言模型搭建了机制推导框架,从61766篇材料科学研究论文中,构建了包含207200个细粒度作用机制、配套1113940条多模态佐证证据的数据集。每个机制均对应材料科学四面体各要素间的特定因果关系,且由实验信息、表征结果和外部知识作为佐证,其准确性已通过材料科学领域研究者的验证。该数据集构建了材料科学领域首个大规模、经交叉验证的多模态机制知识体系,为该领域的数智化驱动研究与智能分析工作提供了重要的知识资源。
03
背景介绍与研究目标
材料科学的核心是阐释加工、结构、性能、性能四要素的因果关联,其深层作用机制是材料设计与性能优化的关键,但这类知识分散在文献的文本、图表和参考文献中,结构化提取难度大,现有研究在规模和范围上均存在局限。机器学习与大语言模型的发展为材料文献文本挖掘提供了新工具,不过现有合成类数据集仅覆盖单一知识、材料知识图谱语义粒度较粗,且均缺乏多模态证据整合,无法满足机制级知识挖掘需求。
本文的研究目标即针对上述问题,依托大语言模型搭建机制推导框架,从海量材料科学文献中重构MST四要素的因果关系,构建一个大规模、经交叉验证的材料科学多模态机制知识库,实现细粒度机制的结构化提取与表征,为数据驱动的材料研究和智能分析提供可靠的知识资源,同时助力智能研究助手的开发。
下图为本研究中的流程图:
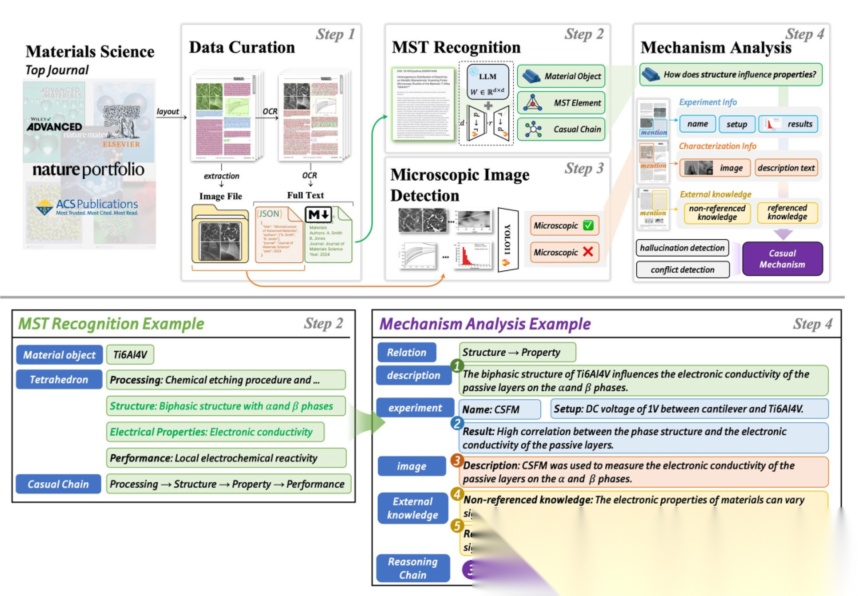
呈现了四步式MST引导的机制推导框架这一从材料科学文献中提取因果机制的完整技术流程:第一步数据整理,筛选顶刊论文并通过工具将文献解析为包含文本、图表的结构化JSON文件;第二步MST识别,提取文献中的研究材料对象及加工、结构、性能、效能四大四面体要素,梳理核心因果链;第三步显微图像检测,利用训练的YOLO11n模型识别文献中的显微图像并完成结构化标注;第四步机制分析,从实验、表征、外部知识中提取多模态证据,拆解因果链形成细粒度机制,同时加入冲突和幻觉检测环节保障数据可靠性,图中还搭配Ti6Al4V的相关实例,直观展示了MST识别和机制分析的实际应用过程。
04
研究方法
本文以构建材料科学多模态因果机制数据集为目标,采用基于大语言模型(LLM)、以材料科学四面体(MST)为核心指导的四步式机制推导框架,并配套冲突与幻觉检测模块保障数据质量,整体研究方法兼具系统性与多模态融合特性,具体分为四个核心步骤:
-
数据整理:筛选15本材料科学领域顶刊的研究论文,通过OpenAlex获取DOI并收集PDF,利用MinerU工具将文献解析为含文本、图表、公式的结构化JSON文件,最终构建含约73000篇论文的研究语料库,为后续分析奠定基础。
-
MST识别:先人工标注样本并结合GPT-4o优化指令schema,再通过Qwen-Plus、DeepSeek-V3交叉验证生成训练集,基于LoRA对Llama-3.3-70B-Instruct进行微调,实现对文献中材料对象、加工/结构/性能/效能四大四面体要素及核心因果链的精准提取。
-
显微图像检测:由材料科学研究者标注文献图表构建数据集,基于Ultralytics库训练YOLO11n分类模型,实现对显微图像的自动化识别(测试集准确率96.08%),并对411414张科学图表进行结构化标注,形成多模态证据源。
-
机制分析:针对提取的MST因果链,从文献中提取实验信息、表征信息、外部知识(含参考/非参考知识)三类多模态证据,将因果链拆解为包含实验结果、图像描述、推理过程等的细粒度机制,同时搭建推理链实现证据的逻辑整合。
05
结果速览
本研究构建出材料科学领域首个大规模、交叉验证的多模态因果机制数据集,经多维度验证,数据集准确性、鲁棒性优异且领域覆盖丰富,核心结果及对应图表如下:
-
数据集核心规模:从61,766篇论文中提取207,200个细粒度机制、1,113,940条多模态证据,完成425,295张图像结构化标注。
-
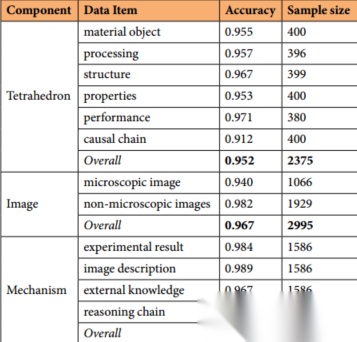
提取准确率:四面体、图像、机制三大核心环节整体准确率达95.2%、96.7%、98.1%,因果链提取91.2%;
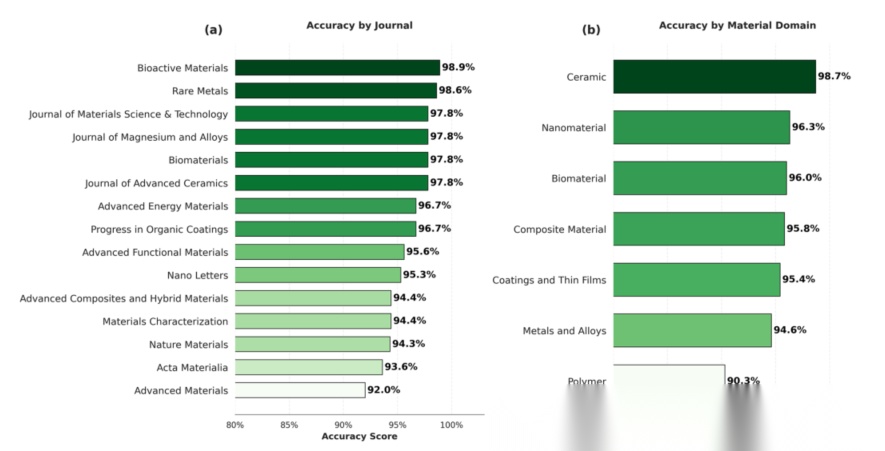
- 跨领域/期刊鲁棒性:MST识别在15本期刊准确率均超92%、各材料领域超90%,陶瓷领域达98.7%;
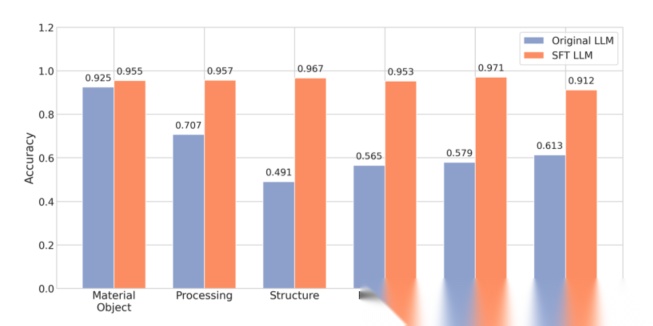
- 模型优化效果:SFT微调后的LLM在MST要素提取上显著优于原始模型,结构、性能等维度提升明显;
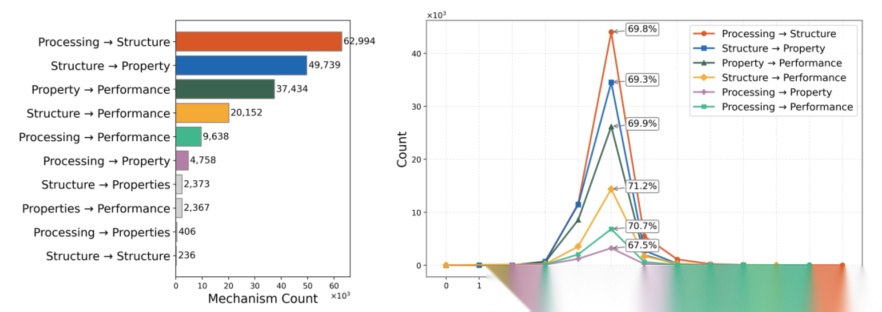
- 机制分布:加工→结构、结构→性能为主要机制类型,约70%机制推理链长度为5;
- 数据可靠性:数据集整体冲突率0.68%、幻觉率5.43%,各证据类型幻觉分布特征见;

- 辅助模型效果:YOLO11n显微图像检测模型测试集准确率96.08%,冲突与幻觉检测模块可有效识别问题内容并赋予置信度评分。
06
文章总结
本文由武汉大学联合中科院团队完成,发表于《Scientific Data》,针对材料科学因果机制知识分散、提取难的问题,提出MST引导的LLM机制推导框架,经数据整理、MST识别、显微图像检测、机制分析四步,从61766篇顶刊论文中构建出领域首个大规模交叉验证的多模态因果机制数据集。研究提取207200个细粒度机制、1113940条多模态证据,核心环节提取准确率超95%,数据集跨期刊/领域鲁棒性优异,冲突率0.68%、幻觉率5.43%,且数据集与代码均已开源,为材料科学数据驱动研究和智能分析提供了重要的知识资源与方法参考。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献204条内容
已为社区贡献204条内容

所有评论(0)