别再死磕 Prompt 和 Workflow 了!DeepSeek-R1 引爆的 Agent 端到端强化学习革命
别再死磕 Prompt 和 Workflow 了!DeepSeek-R1 引爆的 Agent 端到端强化学习革命
最近大模型应用圈里弥漫着一股“焦虑感”。
无数开发者在构建企业级 Agent 时,每天都在和庞大的 Prompt 以及复杂的 LangChain/Dify 工作流搏斗。为了处理各种异常情况,大家在节点里塞满了“遇到情况 A 执行 B,严禁执行 C”这样的硬编码规则。结果呢?系统不仅没有变得更聪明,反而越来越脆弱。只要有一个 API 没按预期返回,整个链路直接崩溃。
我们在用构建传统软件的“控制流”思维,去约束一个具有概率生成能力的智能体。这条路,越走越窄。
2025 年初,DeepSeek-R1 的出圈彻底震撼了业界。它最可怕的地方不在于跑分,而在于验证了一个残酷的真相:不要去微调(SFT)教大模型每一步怎么走,直接用强化学习(RL)告诉它最终目标,它自己会涌现出令人惊叹的推理和试错能力。
既然解数学题可以靠纯 RL 训练出来,那么 Agent 为什么不行?把判断数学题对错的奖励,换成判断它“是否准确搜索并回答了用户问题”的奖励,我们完全可以训练出一个原生带有工具调用能力的智能体。
最近两篇现象级的顶级论文——《Search-R1: Search And Reason in One LLM》(arXiv: 2503.09516)和 《R1-Searcher: Incentivizing Search and Reasoning in LLMs via Reinforcement Learning》(arXiv: 2503.05592),正宣告着 Agent 技术的范式大转移:从基于 Prompt 的 Workflow 组装,全面迈向“端到端”(End-to-End)强化学习训练时代。
🏗️ 为什么 Workflow 模式走进了死胡同?
探讨前沿技术前,得先承认现有路线的失败。
目前市面上 90% 的所谓“Agent”,本质上是一条固化的流水线(Pipeline)。比如一个联网问答 Agent,通常包含意图识别、搜索词生成、调用 Bing API、结果粗排、拼接到大模型上下文进行总结。
这种模式在面对真实世界的复杂性时,破绽百出。
错误级联就像多米诺骨牌。 流程里如果有 5 个环节,每个环节 90% 的成功率,整体成功率直接掉到 59%。一旦“搜索词生成”模型稍微抽风,提取了个错误的关键词,不管最后用于总结的模型多强大,它面对的都是一堆垃圾信息。由于上下游被生硬切断,下游模型根本无法逆向通知上游:“哥们,你搜错词了,换个词再试一次吧”。
它根本没有真正的“试错”与“自愈”能力。 所谓的多轮 ReAct 往往依赖极长的系统级提示词去约束。当工具返回一个 HTTP 404 错误时,大模型极容易陷入死循环,疯狂重复同一个错误调用,或者干脆“幻觉”出一个虚假答案敷衍了事。为了对付这些长尾的异常(Corner Cases),开发者只能无限堆砌补丁,最终把 Prompt 撑爆。
这种在应用层叠床架屋的做法,碰到了智力天花板。
🧠 范式跃迁:回归马尔可夫决策过程
破局的钥匙,是视角转换。在强化学习视角下,Agent 完成任务不再是一条预设管道,而是一个经典的马尔可夫决策过程(MDP)。
大语言模型变成了这个游戏里的玩家(Agent),搜索引擎和外部 API 构成了游戏环境(Environment)。玩家根据当前看到的上下文(State),决定输出文字还是输出一个动作指令(Action,比如 <search>深度学习最新进展</search>)。每走完一局,系统根据最终答案的准确度给玩家发奖金(Reward)。
这种端到端训练的逻辑极其纯粹:我不再干涉你中间怎么搜、搜几次,只要你最后帮我把事办成了,而且没有浪费太多算力,我就给你打高分。
这就像训练搜救犬:你不需要教狗“先迈左腿、闻三下、再右转”,你只需要把带有目标气味的物品让它闻,找到目标就给一块肉。在无数次找寻中,狗会自己进化出最高效的搜索策略。
⚙️ 幕后功臣:GRPO 算法为何是王炸?
要实现这种训练,最大的拦路虎是算法和算力。以前搞大模型强化学习(RLHF),大家用的都是 PPO(Proximal Policy Optimization)算法。
PPO 训练 Agent 完全是个显存黑洞。 跑一次 PPO,后台得同时拉起四个巨大的模型:
- 我们要训练的主模型(Actor)
- 防止模型走火入魔的参考模型(Reference)
- 专门负责打分的奖励模型(Reward Model)
- 预测当前状态预期收益的价值网络(Critic)
四个几百亿参数的模型挤在一起,几百张 A100 瞬间被榨干。更让人崩溃的是,Critic 网络的训练极度不稳定,梯度动辄爆炸,调参过程堪比炼丹玄学。
DeepSeek 团队掏出的 GRPO (Group Relative Policy Optimization) 算法,一剑封喉,直接干掉了最烦人的 Critic 网络。
GRPO 的数学直觉
GRPO 的思路非常接地气。它不要求绝对的打分基准,而是看“同侪压力”。
假设给模型提了一个问题:“2025年奥斯卡最佳影片是哪部?”模型自己生成了 GGG 个不同的回答(动作序列)。系统给这几个回答分别打分,得到 r1,r2,…,rGr_1, r_2, \dots, r_Gr1,r2,…,rG。
传统做法需要 Critic 来估算这道题到底该得多少分作为基准。而 GRPO 直接在组内算个平均分 μR\mu_RμR 和标准差 σR\sigma_RσR。对于第 iii 个回答,它的优势值(Advantage)可以直接用 Z-score 标准化搞定:
Ai=ri−μRσR+ϵ A_i = \frac{r_i - \mu_R}{\sigma_R + \epsilon} Ai=σR+ϵri−μR
得分高于组内平均水平的序列,梯度上升,鼓励这种行为;低于平均水平的,梯度下降,抑制这种行为。
对于 Agent 训练,这个特性简直是天作之合!Agent 搜索互联网的环境方差极大(同样搜一个词,早上搜和晚上搜的结果可能完全不同)。GRPO 的这种“同一起跑线比排名”的机制,天然过滤了环境的绝对噪声。它让模型把注意力集中在:“面对同一片混乱的网页,我哪种思考和检索策略能比自己的其他尝试表现得更好”。
🚀 工程视角:跨越 I/O 鸿沟的 Ray 架构
算法再好,落地到工业界也面临着残酷的工程考验。训练 Agent 和训练纯对话大模型截然不同。纯对话模型是在 GPU 里自娱自乐疯狂算矩阵,而 Agent 必须在生成标签(如 <search>)后,停下 GPU 计算,去浩瀚的互联网里发 HTTP 请求等结果。
这种 GPU 算力密集和 CPU/网络 I/O 密集的极端错位,搞不好会让上千张昂贵的显卡空转等待。
针对这个问题,目前业界最成熟的方案是深度集成 Ray 分布式计算框架。
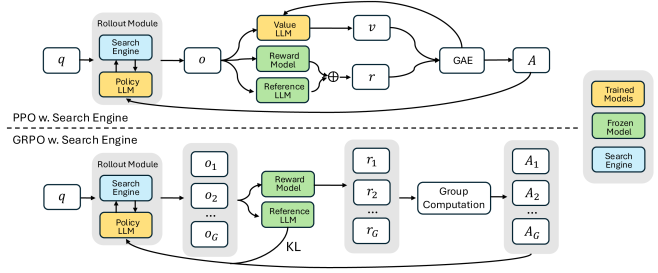
图1:端到端强化学习的高并发系统架构示意图。左侧为生成式推理引擎,右侧为环境交互与奖励评判引擎。
整个集群被巧妙地切割成几个角色:
- Rollout (Actor) 节点:专门跑 vLLM 等高吞吐推理引擎。它飞速吐出 token,一旦发现模型吐出了
<search>,立刻将该序列的状态挂起,把控制权交出去,接着去处理其他排队的请求。 - Environment Worker 池:成百上千个跑在廉价 CPU 节点上的进程,专门负责和搜索引擎、数据库或者终端交互。它们拿到结果后,再回调通知 Rollout 节点恢复生成。
- Learner (Trainer) 节点:在后台安静地收集大批量的完整交互轨迹,运行 DeepSpeed 或者 Megatron 执行 GRPO 的反向传播,算完之后异步把新权重推给 Rollout 节点。
这种计算与环境彻底解耦的架构,是跑通端到端 Agent 训练的前提保障。没有这套基础设施,再牛的算法也只能停留在纸面上。
🔬 顶会解读一:《Search-R1》——边搜边想的超级个体
有了算法和基建,我们来看看学术界最近交出的惊艳答卷。今年 3 月放出的这篇 《Search-R1: Search And Reason in One LLM》 就是这套新范式的教科书。
传统的 RAG 检索增强系统把搜索和思考强行割裂:先搜一堆片段,再一股脑扔给大模型。如果初次检索遗漏了关键信息,大模型就只能“巧妇难为无米之炊”。
Search-R1 团队认为:搜索不应该是前置步骤,而应该是大模型思考过程(Thought Process)中随时可以发起的自然呼吸。
巧夺天工的奖励设计
文章抛弃了从零开始强化学习(那会让模型在动作空间里迷失),而是先用少量高质量带搜索调用的数据对基座模型做了一遍监督微调(SFT)。模型刚学会 <think> ... <search> ... </search> ... </think> 这种长相,立刻就被丢进基于 GRPO 的强化学习角斗场。
最绝的是他们设计的规则奖励(Rule-based Reward),极其克制又直击要害。团队没有用复杂的奖励模型去评判文风,而是给了三把极其锋利的尺子:
- 格式戒律(Formatting Reward):如果模型在漫长的探索中,忘记闭合 XML 标签,或者格式错乱,直接粗暴地扣 1 分。这保证了模型脑子再乱,语法不能乱。
- 终极裁决(Accuracy Reward):答案对了,直接狂加 2 分。如果是完全一致的 Exact Match,这就是最核心的主线任务奖励。
- 效率紧箍咒(Efficiency Penalty):为了防止模型像无头苍蝇一样疯狂搜索(搜一次扣一次钱),系统对每一次
<search>动作轻微扣除 0.05 分。
在这些简单的规则倒逼下,奇迹发生了。
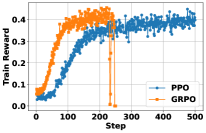
图2:随着 RL 训练步骤的增加,模型在各个复杂推理问答基准集上的性能显著攀升,搜索效率也同时提高。
涌现的“灵魂”能力
经过 RL 洗礼的 Search-R1 展现出了让人毛骨悚然的自我进化。完全没有写任何关于“如果失败该如何重试”的 Prompt,模型自己学会了:
- 主动自我修正(Self-Correction):当第一次搜索没查到结果,或者结果过期时,模型会在其
<think>空间里自言自语:“刚才那个结果太旧了,没涵盖 2025 年的情况,我得加个年份重新搜一次”。它学会了反思自己的动作。 - 复杂任务自主降维(Decomposition):面对“A的老婆出生的城市叫什么”这种多跳问题,它懂得了先搜索“A的老婆是谁”,耐心等结果返回,提取出名字后,再发起第二次精准搜索。它彻底挣脱了 LangChain 把所有步骤写死的枷锁。
⚖️ 顶会解读二:《R1-Searcher》——专治“搜索成瘾”与“盲目自信”
如果说 Search-R1 证明了这条路能走通,那么同期另一篇顶会论文 《R1-Searcher》 解决的则是一个更为细腻的心理学难题:怎么把控 Agent 使用工具的“度”?
没调教好的 Agent 经常走两个极端。要么“搜索成瘾”,连问个“1+1等于几”都要去调一下计算器 API,浪费巨大算力;要么极度“盲目自信”,面对生僻的专业名词,脑子里根本没这块知识,却宁愿胡说八道产生幻觉,也懒得去搜一下。
治乱世用重典:幻觉重罚机制
《R1-Searcher》团队洞察到,仅仅靠“答对给分”治不好这种病。他们果断引入了更为立体的激励机制,其中最震撼的就是 幻觉惩罚(Hallucination Penalty)。
如果你明明没有这块知识,不去搜索查证,且最终给出了错误答案,系统将判处极刑——直接给个深不见底的负分(比如 -5 分)。
这相当于拿鞭子抽打模型:“不懂装懂,罪加一等!”。
在这样残酷的奖惩下,模型的风险偏好被彻底扭转。它开始学会像人一样,掂量自己内在知识的置信度。遇到熟悉的常识,果断直接回答;稍微觉得含糊,立刻唤醒搜索工具查漏补缺。
中间过程的隐形红利
不仅如此,他们还在训练中引入了对过程质量的反馈。如果模型在搜回来一大堆含有严重干扰信息的网页文本后,能够在其 <think> 标签里精准地把那几句核心论据摘抄出来作为推理支撑,系统会立刻发放一笔“过程奖金”(Intermediate Reward)。
在开放域问答测试集(比如 TriviaQA)上,这套机制逼着模型进化出了惊人的侦探本领:
面对极其模糊的需求,它会先扔几个特别宽泛的词去“探路”,看一眼大致结果后,再提取实体词进行精准打击。更夸张的是,当它在网上看到互相矛盾的说法时,竟然会自动去查验维基百科来做交叉验证。
看到这些涌现行为,我觉得工程界苦苦维护的那几万行 Workflow 代码,已经显得毫无意义了。
🔮 迈向深水区:通往 DeepResearch 的最后一公里
透过这两篇顶级论文,Agent 的终局形态已经非常清晰。我们正在从微观的 Prompt 调教,全面跃升至宏观的 Reward 设计。
最近 OpenAI 抛出 DeepResearch,能在后台静默运行几个小时,调用几千次搜索、查阅数百篇研报,最后吐出一份极其专业的万字长文分析。在这么大的任务跨度下,传统的 Workflow 架构活不过前面 5 分钟,因为极高的错误率累积瞬间就会让它崩溃。只有基于端到端强化学习训练出来、内置了强大自我纠错韧性的 Agent,才能接得住这种地狱级任务。
但大规模工业化落地前,我们还有几块硬骨头要啃:
第一,真实世界的互联网没法用来训练。
RL 极度依赖疯狂的试错。要是让几百亿参数的模型并发去调用真实的 Bing API,不光网络延迟能把训练拖死,IP 封禁也是分分钟的事。更要命的是搜索引擎的结果在变,环境的非平稳性会彻底摧毁训练收敛。
工程上的唯一解,是砸重金构建包含数十亿网页快照的 高逼真离线沙盒(Sandbox Search Engine)。在模拟器里人为注入网络波动、404错误和内容噪声,在无菌室里淬炼 Agent 的抗击打能力。
第二,超长序列的“信用分配(Credit Assignment)”。
如果一个 Agent 辛辛苦苦干了 3 个小时,输出了一个烂尾的调研报告。系统给了一个很低的最终分。但模型怎么知道,究竟是第 10 步的关键词搜得太偏,还是第 200 步摘抄时漏了一句话?
纯结果导向的 GRPO 在面对几万步动作时,奖励信号会被彻底稀释。我们需要研发出极其精密的过程奖励模型(PRM),能够像严苛的导师一样,对模型长轨迹中的每一步关键节点进行局部分数指引。
💡 尾声:牧羊人的新时代
技术的发展往往是个螺旋。深度学习用数据驱动干掉了手工提取特征(Feature Engineering),而现在,端到端强化学习正在干掉手工编排工作流(Workflow Engineering)。
《Search-R1》和《R1-Searcher》不是终点,它们只是推开了一扇门。在这扇门后,Agent 将从一个只会调用单一搜索工具的偏科生,进化成能同时操作数据库、操作终端、甚至通过视觉看懂图形界面的全能霸主。
身处这个时代,我们开发者的身份必须转变。我们不再是每天在代码里写无尽 If-Else 和兜底逻辑的苦力编排工。我们将成为制定游戏规则、设计奖惩机制、看着 AI 在探索中涌现智能的“牧羊人”。
抛开那些臃肿的 Prompt 模板吧,去拥抱 GRPO,去拥抱强化学习。真正的智能,是从与世界的真实碰撞中生长出来的,而不是被代码死死锁在牢笼里的。
📚 深度阅读清单:
- Search-R1: Search And Reason in One LLM (arXiv:2503.09516)
- R1-Searcher: Incentivizing Search and Reasoning in LLMs via Reinforcement Learning (arXiv:2503.05592)
- DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models (欲深入理解 GRPO 必读)
觉得有启发的话,欢迎点赞、在看、转发。跟进最新AI前沿,关注我的微信公众号:机器懂语言

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)