Matter | MERMaid:基于视觉-语言模型的化学反应PDF自动挖掘与知识图谱构建研究
在数据驱动的科学研究范式日益成熟的今天,如何高效地从海量科学文献中提取、整合和利用知识已成为加速科学发现的核心挑战。尤其在化学领域,大量宝贵的反应数据仍以图表、流程图等视觉形式封存于PDF文献中,难以被机器直接读取和利用。近日,多伦多大学Alán Aspuru-Guzik团队在Matter期刊发表研究成果,提出了一种名为MERMaid(Multimodal Aid for Reaction Mining)的端到端化学数据数字化平台,该平台利用视觉-语言模型(VLM)的多模态推理能力,实现了从PDF文献中自动提取反应信息并构建知识图谱的完整流程,端到端准确率达87%,为化学知识的自动化挖掘与智能化应用提供了新范式。

研究背景与科学问题
科学文献是人类知识积累的重要载体,而化学反应数据的数字化对于构建机器可操作的知识库、消除自主实验系统的冷启动问题、以及训练数据密集型AI模型具有关键意义。尽管Harvard Clean Energy Project、Materials Project、Open Reaction Database等数据库的建设取得了显著进展,但大量化学信息仍以非结构化形式存储于传统期刊论文和专利文献中。
从科学文献的图形元素中提取数据面临三重挑战:其一,PDF格式缺乏语义元数据,图形元素与其说明文字的联合分割困难;其二,科学图表需要多模态推理和领域特定的上下文理解能力;其三,将提取内容结构化为机器可操作的格式需要解决术语标准化和歧义消解等问题。现有工具如ChemDataExtractor和OpenChemIE或聚焦于文本处理,或依赖于非科学文档优化的布局解析器,难以满足复杂科学图表的解析需求。
MERMaid系统架构与核心模块
MERMaid采用模块化设计理念,由三个顺序连接的功能模块组成,分别负责PDF图表分割、多模态信息提取和知识图谱构建。
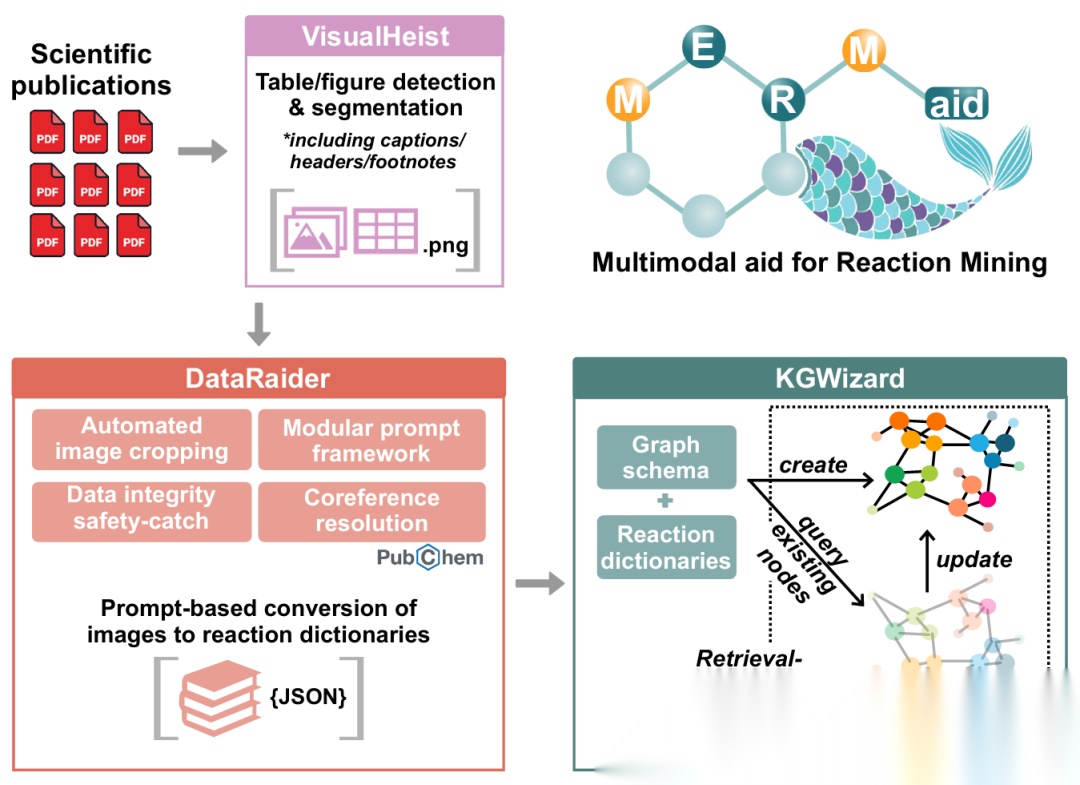
▲ Fig.1 | MERMaid的示意图概览,该系统集成了三个连续模块,分别用于PDF中图-注联合分割、图像到数据的多模态分析以及知识图谱构建。遗漏的案例主要源于边缘情况下的非常规格式选择。例如,连续图像之间的间距过于紧密会导致后续图像的标题被错误地截断
如图1所示,MERMaid的整体架构实现了从分散PDF图形数据到统一知识图谱的端到端转换。该系统的模块化特性使得各组件既可独立部署执行特定功能,也可无缝集成形成完整的知识提取流水线。
VisualHeist:PDF图表智能分割模块
VisualHeist是基于Microsoft Florence-2视觉基础模型微调的深度学习工具,用于从PDF文档中分割图形、方案图和表格及其相应的标题、题注和脚注。该模型在包含3,435幅图形和1,716个表格的多样化数据集上进行微调训练,涵盖主文、补充材料和未格式化档案论文等多种文档类型。
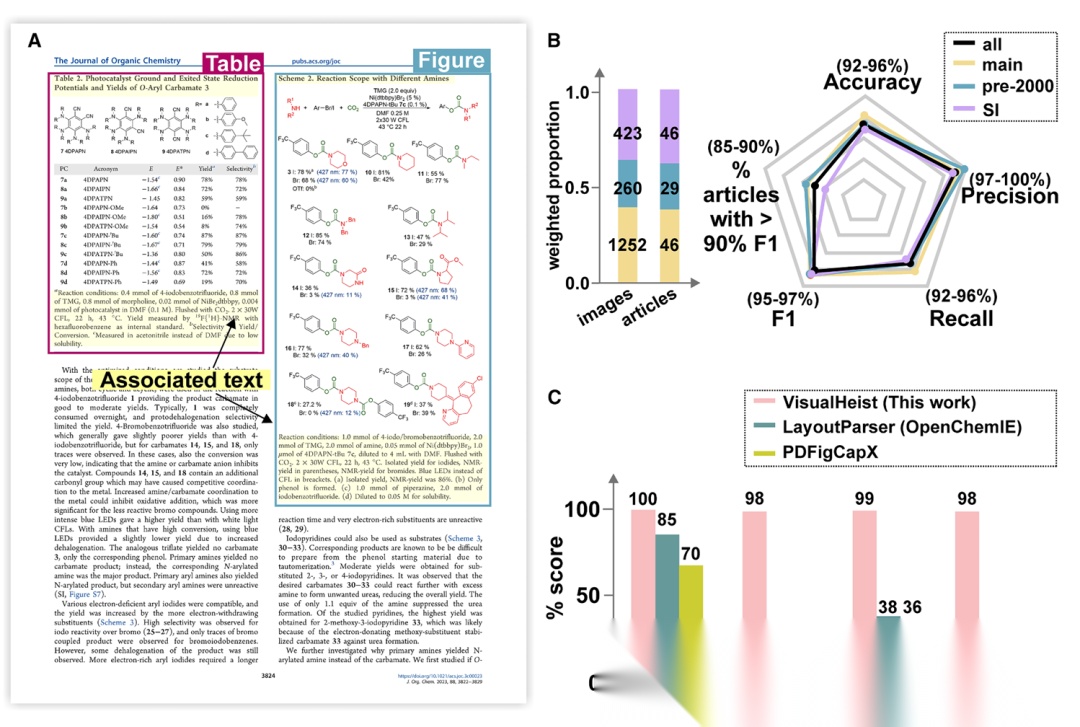
▲ Fig.2 | VisualHeist的性能评估 (A) 从PDF文档中识别和分割图片、示意图和表格及其相应标题和题头的示例描述。(B) 评估数据集中不同来源的图像和PDF文章的数量及分布统计(左),以及使用各种性能指标对VisualHeist进行的评估
图2展示了VisualHeist的性能评估结果。在涵盖有机化学、无机化学、大气科学、电池、材料科学、金属有机框架、生物学等多个学科领域的121份PDF测试集上,VisualHeist在1,935幅图像上实现了超过93%的整体精确率、召回率、F1分数和准确率。值得注意的是,该模块对高度非结构化的补充材料表现出良好的鲁棒性,即使面对图文配对错位等复杂情况,在所有46份补充材料上的各项性能指标均保持在92%以上。测试集涵盖了1949年至今的文献,证明了系统对不同时期出版物格式变化的适应能力。
DataRaider:多模态信息提取模块
DataRaider是利用GPT-4o视觉-语言模型能力构建的信息提取工具,能够根据用户定义的键值结构从图像中提取特定信息,并将其转换为结构化反应字典。

▲ Fig.3 | DataRaider的性能评估 (A) 方法概览。使用RxnScribe对反应物和产物进行光学化学结构识别(紫色高亮显示);所有其他参数均通过VLM提取。图像在分析前进行裁剪。突出显示了将提取数据组织成有意义输出的关键挑战。(B) 我们的模块化方案示意图
图3详细展示了DataRaider的工作流程与技术方案。该模块的核心能力包括:脚注标签解析,能够将图像内的参考标签与其文本脚注描述正确关联;自主上下文补全,当表格中不同反应条目仅报告部分条件时,能够推断和对齐缺失的上下文信息。这种处理不完整或上下文依赖信息的能力对于应对科学文献中的常见挑战至关重要。
研究团队构建了MERMaid-100验证数据集,包含来自有机电合成、有机合成和光催化三个化学领域的100篇文献。评估结果显示,DataRaider在完整反应提取方面达到92%以上的准确率,表明其对不同化学领域术语和表达方式的良好适应性。
KGWizard:知识图谱构建模块
KGWizard作为文本到数据库的转换引擎,将反应字典重新组织为知识图谱格式。知识图谱的构建优势在于能够跨大规模数据集综合知识,促进发现反应之间新的关联洞见,而非将每个反应视为孤立实例。
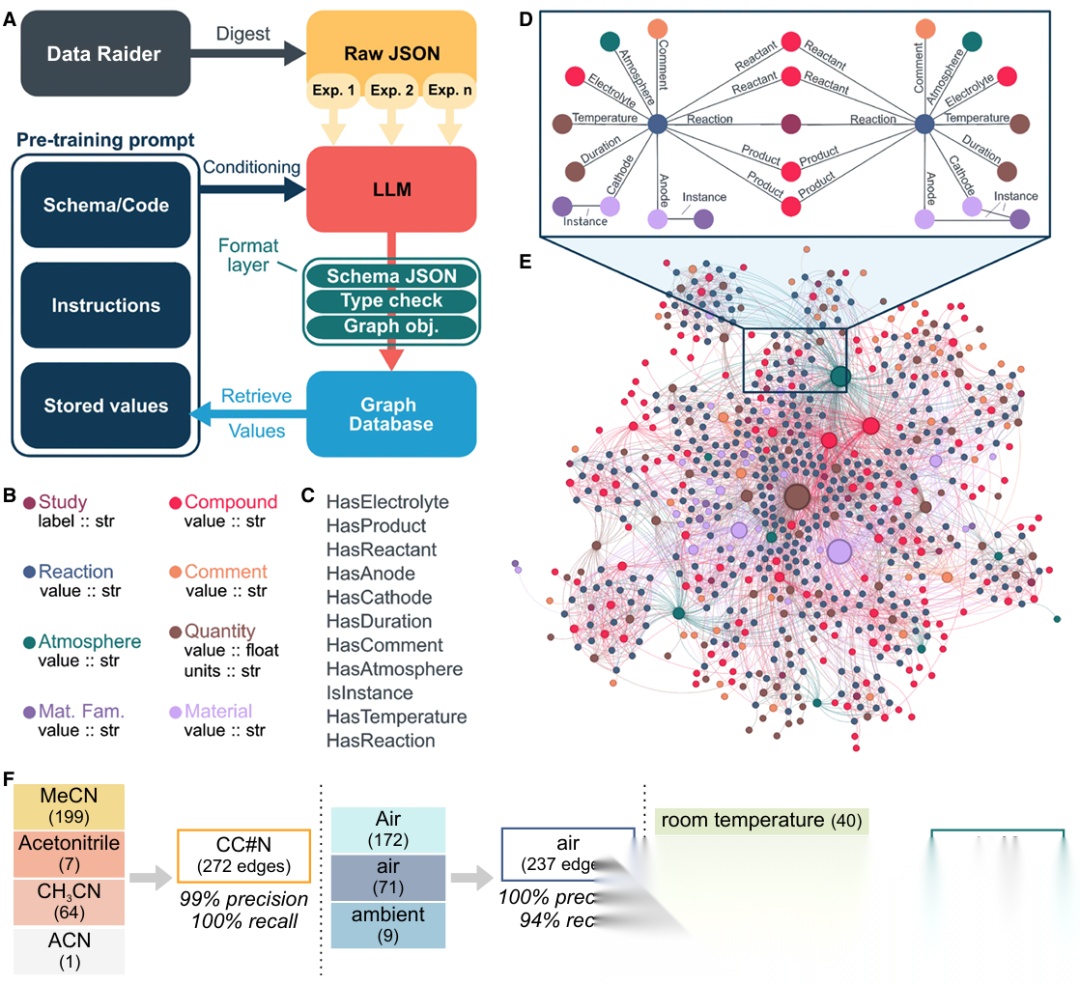
▲ Fig.4 | KGWizard的关键特征 (A) KGWizard工作流程。(B) 图数据库的节点类型。属性及其类型位于"::"之后;红色粗体节点的属性从数据库中检索以生成转换提示。© 图数据库的边类型。(D和E) (D) 反应模块示例,结合了来自(E) MERMaid-100数据集中有机电合成反应创建的知识图谱的环境属性(节点)和上下文(边)。(F) 示例
图4展示了KGWizard的工作流程、图数据库的节点与边类型定义,以及从MERMaid-100数据集有机电合成反应创建的知识图谱示例。为解决不同文献中使用的缩写和通用名称标准化问题,研究团队采用双管齐下的策略:利用PubChem数据库进行显式共指消解,利用检索增强生成(RAG)技术进行隐式共指消解,从而避免重复实体的产生。评估结果表明,知识图谱转换的准确率达到96%,保持了优异的数据完整性。
系统性能与应用验证
MERMaid在三个化学领域的综合评估中实现了87%的端到端准确率。具体而言,有机电合成领域的准确率为84%,有机合成领域为90%,光催化领域为87%。这种跨领域的稳定表现验证了系统的主题无关性设计理念。
系统的模块化架构带来了显著的灵活性优势:各模块可独立部署用于特定任务;新功能模块如文本处理能力和光学化学结构识别(OCSR)工具可便捷集成;输出格式可扩展支持Open Reaction Database等替代标准。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献167条内容
已为社区贡献167条内容

所有评论(0)