SciDER:当AI学会从原始数据开始做科研,GPT-5也得靠边站
SciDER:当AI学会从原始数据开始做科研,GPT-5也得靠边站
一句话总结:SciDER是一个多智能体系统,能从原始科学数据出发,自动完成"文献调研→数据分析→实验执行→结果评审"全流程,在科学代码、机器学习工程和创意生成三大基准上均超越当前最强模型。
📖 论文信息
- 标题:SciDER: Scientific Data-centric End-to-end Researcher
- 作者:Ke Lin, Yilin Lu, Shreyas Bhat, Xuehang Guo, Junier Oliva, Qingyun Wang
- 机构:William & Mary(威廉与玛丽学院)、University of Minnesota(明尼苏达大学)、UNC Chapel Hill(北卡罗来纳大学教堂山分校)
- 日期:2026年3月
- 链接:arXiv:2603.01421
- 开源:Apache 2.0 许可证,提供 PyPI 包、GitHub 仓库和 HuggingFace Demo
🎯 这篇论文到底要解决什么问题?
想象一下你是一个实验物理学家。你刚从实验室拿到一批原始测量数据——可能是光谱数据、粒子轨迹,或者恒星亮度的时间序列。接下来你得花几周甚至几个月:先读几十篇文献找灵感,然后手动清洗数据、写脚本做统计分析、跑各种模型对比实验,最终整理成论文。
现有的 AI 科研助手(比如 Sakana AI 的 AI-Scientist、港大的 AI-Researcher)已经能帮你做一些事,但它们有一个根本性的限制:几乎都是围绕已有的公开ML数据集(如CIFAR-10、ImageNet)运作的。你给它一个数据集名字,它就能跑实验。但如果你递过去一个从实验室仪器导出的 CSV 文件,说"帮我分析这个",它们就傻眼了。
这就像请了一个只会做标准化考试的学生——给他往年真题,刷得飞快;但让他面对一道全新的实际问题,就不知道从哪下手了。
SciDER 要做的,恰恰是补上这块短板:让AI从一份你随手丢过来的原始数据文件开始,自主完成整个科研流程。这不是"帮你润色论文"或"帮你跑个已知的benchmark",而是真正意义上的端到端自动化科学研究。
🧠 核心方法:四个AI研究员的分工协作
SciDER 的架构设计可以用一个比喻来理解——它就像一个小型科研实验室,里面坐着四个各有专长的研究员,再加上一个共享的知识库。
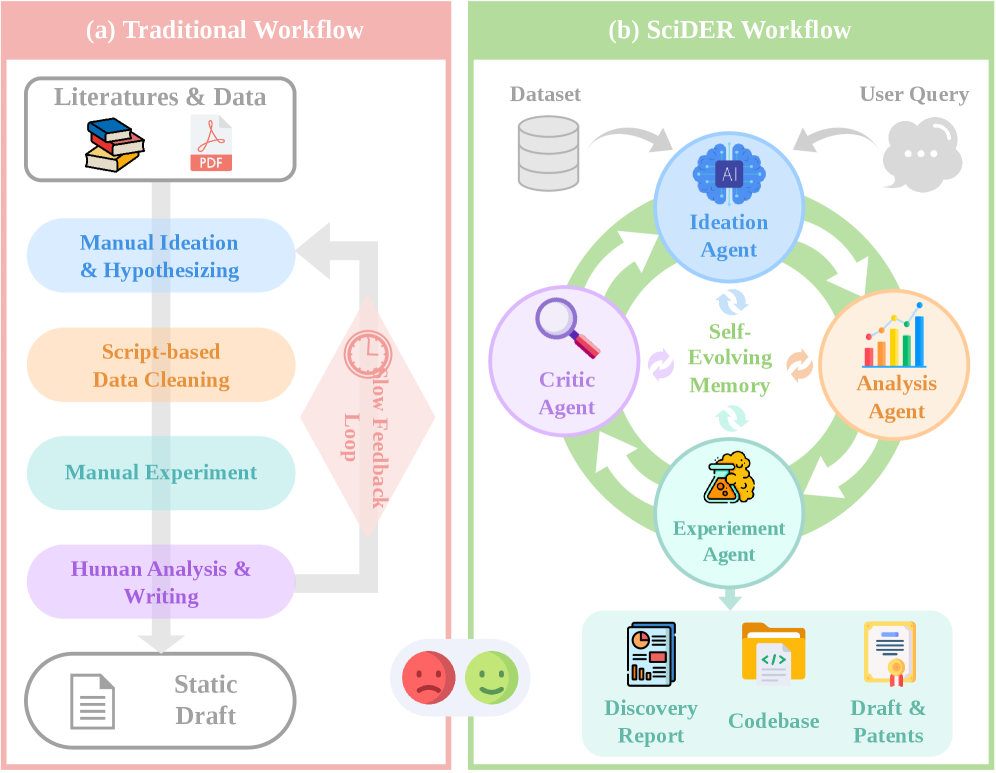
图1:左边是传统的科研流程——研究人员需要手动完成文献调研、脚本数据清洗、反复实验和人工分析,反馈循环缓慢。右边是SciDER的工作流——四个专业智能体(Ideation Agent、Data Analysis Agent、Experiment Agent、Critic Agent)围绕中央的自进化记忆系统协作,最终产出发现报告、代码库和论文草稿。
1️⃣ Ideation Agent(创意智能体)——实验室里的文献综述专家
这个智能体负责"想点子"。给定用户的研究问题和数据集,它会:
- 自动检索相关文献,生成系统性的文献综述
- 提出具体的研究假设和实验设计
- 用一个 LLM-as-Judge 的评分机制来筛选方案
评分机制挺有意思,采用了四个维度打分:
| 维度 | 分值 | 含义 |
|---|---|---|
| Uniqueness(独特性) | 0-3 | 与现有工作的差异化程度 |
| Innovation(创新性) | 0-3 | 方法论或理论框架的原创性 |
| Gap Addressing(差距填补) | 0-2 | 是否有效解决已知的研究空白 |
| Impact(影响力) | 0-2 | 对该领域的潜在贡献 |
满分10分。这套评分标准比很多论文审稿人都具体——至少不会给你来一句模糊的"novelty insufficient"然后就完事了。
SciDER 在这个环节使用的是 gemini-2.5-flash 模型,选它可能主要是看中了速度和成本优势——文献检索和创意生成需要大量的 LLM 调用,用太贵的模型成本扛不住。
2️⃣ Data Analysis Agent(数据分析智能体)——实验室里的数据工程师
这是 SciDER 区别于其他 AI 科研系统的核心差异化模块。它接收用户上传的原始数据文件(可能是 CSV、JSON、ZIP 压缩包等任意格式),然后自动生成一份结构化的数据报告(Data Report) R \mathcal{R} R,从四个维度评估数据:
- Structure(结构):文件格式、数据类型、模式(schema)
- Quality(质量):完整性分析,识别缺失值、异常值和不一致性
- Semantics(语义):解释数据字段在特定领域中的含义
- Dependency(依赖):映射数据实体之间的关系(如外键、文件链接)
这个设计的精妙之处在于:它把"理解一份陌生数据"这件事给系统化了。你想,一个新来的实习生拿到一份从没见过的数据集,他也得经历类似的过程——先看看文件是什么格式的,有没有缺失值,每列代表什么意思,表和表之间怎么关联。SciDER 把这个过程自动化了,而且输出的结构化报告会被后续的实验设计环节直接使用。
3️⃣ Experiment Agent(实验智能体)——实验室里的码农
拿到了创意方案和数据分析报告,这个智能体负责把想法变成可执行的代码。它的工作流分两步:
编码阶段(Coding Phase):使用 Claude Code 框架(基于 Claude 4 Sonnet 模型)或 OpenHands 框架来迭代生成实验代码。不是一次写完的——它会根据运行结果和错误信息不断修正代码,就像一个真正的程序员 debug 一样。
执行阶段(Execution Phase):在沙盒环境中运行代码,收集实验结果。如果执行失败(比如 OOM、语法错误),系统会自动将错误信息反馈给编码智能体进行修复。
4️⃣ Critic Agent(评审智能体)——实验室里的PI(首席研究员)
这可能是整个系统中最关键的角色。它扮演的就是"审稿人"或者"导师"的角色——拿到实验结果后,从准确性、完整性和潜在偏差三个角度进行评估,然后把反馈意见打回给其他三个智能体。
这就形成了一个迭代优化循环。用数学语言描述:
I n + 1 ← I d e a t i o n ( F n , D , Q ) \mathcal{I}^{n+1} \leftarrow \mathrm{Ideation}(\mathcal{F}^n, \mathcal{D}, \mathcal{Q}) In+1←Ideation(Fn,D,Q)
其中 F n \mathcal{F}^n Fn 是第 n n n 轮的评审反馈, D \mathcal{D} D 是数据, Q \mathcal{Q} Q 是研究问题。每一轮迭代,Ideation Agent 根据 Critic 的反馈改进研究方案,Data Analysis Agent 补充分析,Experiment Agent 修改代码重跑实验,Critic Agent 再次评审——如此往复,直到结果收敛。
这个设计让我想起导师和学生的互动模式:学生写了初稿,导师看完提一堆意见,学生改了再交,导师再看……区别在于 SciDER 里这个循环是自动的,而且不会因为"导师太忙"而卡住。
🔧 自进化记忆:让AI科学家越做越聪明
四个智能体的协作还不够,SciDER 还设计了一个自进化记忆系统(Self-Evolving Memory),这是它的另一个核心创新。
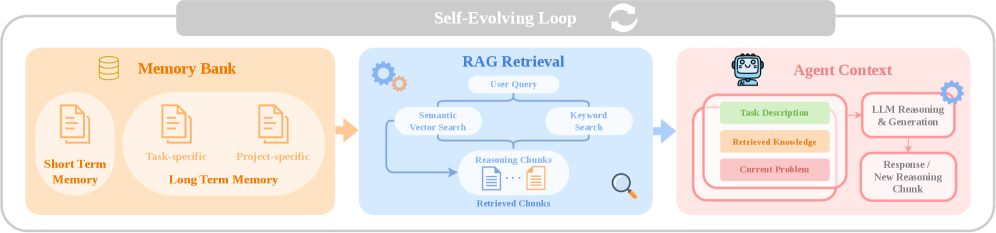
图2:自进化记忆系统的架构——左边是记忆库(分为短期记忆和长期记忆,后者又分为任务特定和项目特定两类);中间是RAG检索模块(语义向量搜索+关键词搜索→检索出相关知识块);右边是智能体上下文(任务描述+检索到的知识+当前问题→LLM推理与生成→新的响应和推理块回流到记忆库)。
这个记忆系统由三层构成:
短期记忆(Short-Term Memory):存储当前任务执行过程中的中间状态——比如当前运行了哪些实验、得到了什么中间结果、遇到了什么错误。类似于你做实验时的实验笔记。
长期记忆——任务特定(Task-Specific Long-Term Memory):存储某类特定任务的经验。比如"处理时间序列数据时,先做平稳性检验"、“遇到类不平衡问题时,优先尝试SMOTE”。这些经验跨任务积累。
长期记忆——项目特定(Project-Specific Long-Term Memory):存储特定研究项目的背景知识和积累的洞察。比如"这个 Kepler 数据集中 flux 列的物理含义是恒星亮度"、“之前的实验表明 Random Forest 在这个数据上效果不如 Gradient Boosting”。
检索采用的是混合 RAG 策略——同时用语义向量搜索(捕捉含义相近的知识)和关键词搜索(精确匹配术语),把检索到的知识块注入智能体的上下文中。
为什么说这个记忆是"自进化"的?因为智能体每次执行任务产生的新推理和新发现,都会自动写回记忆库。下次遇到类似问题,检索出来就能用。这本质上是一种测试时学习(test-time learning)——不需要重新训练模型,通过不断积累经验就能变得更强。
这让我联想到最近的一些相关工作,比如 Evo-Memory benchmark(专门评估 LLM 智能体记忆能力的基准)和 STELLA 智能体(也采用了类似的自进化记忆框架)。记忆增强已经成为 LLM 智能体的一个重要研究方向——毕竟,一个没有记忆的智能体,每次都得从零开始,效率太低了。
🧪 实验结果:三大基准全面碾压
SciDER 在三个主流基准上进行了评测,覆盖了科研的不同能力维度。
基准一:AI-Idea-Bench(创意生成能力)
这个基准测试的是 AI 能否生成高质量的研究创意。指标包括:
- Idea2Idea:生成的创意与真实论文创意的相似度
- Novelty:创意的新颖程度
- Feasibility:创意的可行性(注意这列的数值量级为 10 − 2 10^{-2} 10−2)
| 方法 | Idea2Idea (Motiv.) | Novelty (Motiv.) | Idea2Idea (Exp.) | Novelty (Exp.) | Feasibility |
|---|---|---|---|---|---|
| SCIPIP | 2.44 | - | 25.06 | - | - |
| VIRSC | 2.94 | 2.12 | 24.87 | 24.65 | 13.3 |
| AI-Researcher | 2.81 | 2.02 | 24.92 | 24.69 | 16.8 |
| AI-Scientist | 3.59 | 2.73 | 25.03 | 26.08 | 12.1 |
| SciDER | 3.78 | 3.50 | 47.06 | 44.52 | 24.0 |
几个关键数字值得仔细品味:
- Idea2Idea (Exp.) 这一列,SciDER 拿到 47.06,而此前最好的 AI-Scientist 只有 25.03——差距接近翻倍。这说明 SciDER 生成的实验方案和真实论文的实验设计高度吻合。
- Novelty (Exp.) 同样,SciDER 的 44.52 几乎是 AI-Scientist(26.08)的 1.7 倍。
- Feasibility,SciDER 拿到 24.0,比最强对手 AI-Researcher(16.8)高出 43%。生成的创意不仅新颖,而且可执行。
这里的 baseline 方法都不是等闲之辈:AI-Scientist 来自 Sakana AI,是 2024 年引起广泛关注的自动化科研系统;AI-Researcher 来自香港大学,也是该领域的重要工作。SciDER 能拉开这么大差距,说明以数据为中心的方法确实让 AI 对实验设计的理解更接地气了。
基准二:MLE-Bench(机器学习工程能力)
MLE-Bench 是 OpenAI 推出的基准测试,基于真实的 Kaggle 竞赛。Lite 版本包含一组精选的竞赛任务,按 Kaggle 的评分标准判定是否达到奖牌水平。
| 方法 | % Any Medal ↑ | % Gold Medal ↑ |
|---|---|---|
| AIDE | 16.90 | 9.40 |
| ML-Master | 48.50 | 18.10 |
| AIRA | 47.73 | 28.64 |
| SciDER | 45.45 | 36.40 |
这组数据很有意思。SciDER 在 Any Medal(任何奖牌) 这个指标上不是最高的——ML-Master 的 48.50% 和 AIRA 的 47.73% 都比 SciDER 的 45.45% 高。但看 Gold Medal(金牌) 率,SciDER 的 36.40% 把第二名 AIRA(28.64%)甩开了 7.76 个百分点。
这说明什么?SciDER 拿"参与奖"的比例稍低,但一旦拿奖就拿金牌的概率更高。换成运动员的话说——它上场次数可能不是最多的,但含金量最高。这很可能归功于 Critic Agent 的迭代评审机制:宁可多迭代几轮把方案打磨到极致,也不急着交一个平庸的答案。
AIRA 是 Toledo 等人的工作,也是一个强劲的多智能体 ML 工程系统。AIDE 由 Jiang 等人提出。ML-Master 由 Liu 等人提出,在"广撒网"策略上更激进。
基准三:SciCode(科学代码能力)
SciCode 是一个跨学科的科学编程基准,覆盖 16 个子领域、80 个主问题和 338 个子问题,涉及物理、化学和生物学。
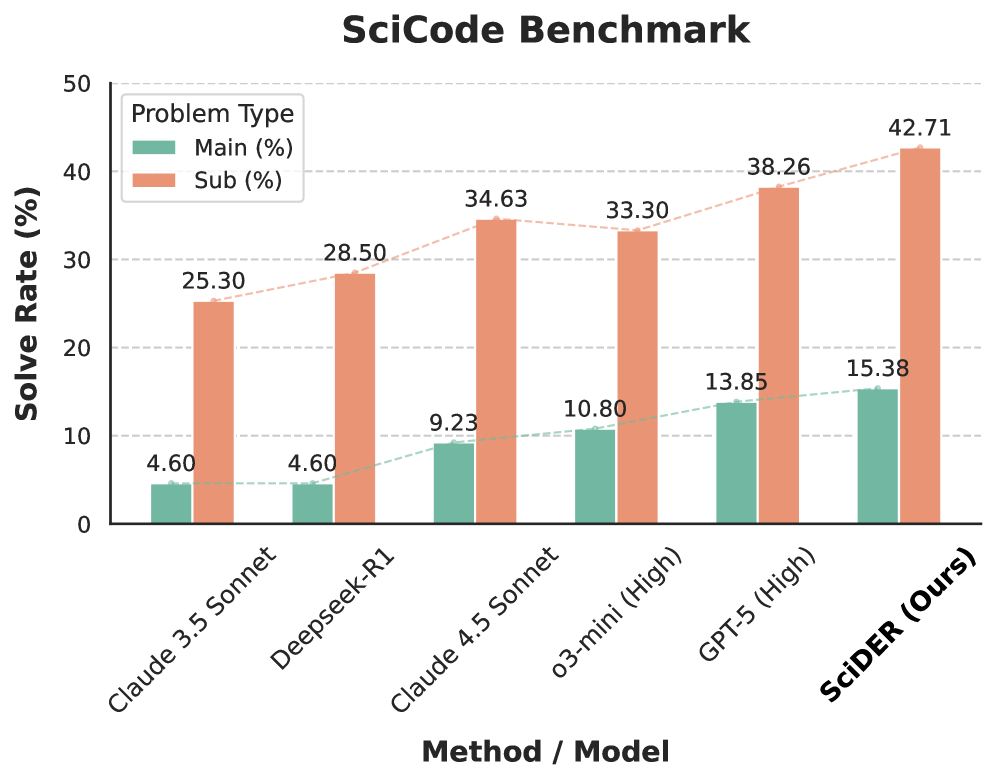
图3:SciCode基准测试的对比柱状图——横轴为不同模型,纵轴为问题解决率(%)。蓝色柱子为主问题(Main)解决率,橙色柱子为子问题(Sub)解决率。SciDER在两个指标上均位居第一。
SciDER 在主问题上达到 15.38%,子问题上达到 42.71%,均超过了 GPT-5(13.85% / 38.26%)。要知道 SciCode 的问题可不是简单的编程题,而是真正的科学计算问题——比如模拟量子系统演化、计算化学反应速率常数这种。SciDER 能在这种硬核科学编程任务上超过 GPT-5,很能说明其数据分析和实验执行能力的强悍。
对比其他模型:Claude 3.5 Sonnet 只有 4.60% / 25.30%,DeepSeek-R1 为 4.60% / 28.50%,Claude 4.5 Sonnet 为 9.23% / 34.63%,o3-mini 为 10.80% / 33.30%。SciDER 的优势非常明显。
🔬 案例研究:开普勒系外行星检测
为了展示 SciDER 处理真实科学数据的能力,作者用 Kepler 系外行星数据集 做了一个完整的案例研究。任务是:从恒星光曲线的时间序列数据中自动检测系外行星凌星信号。
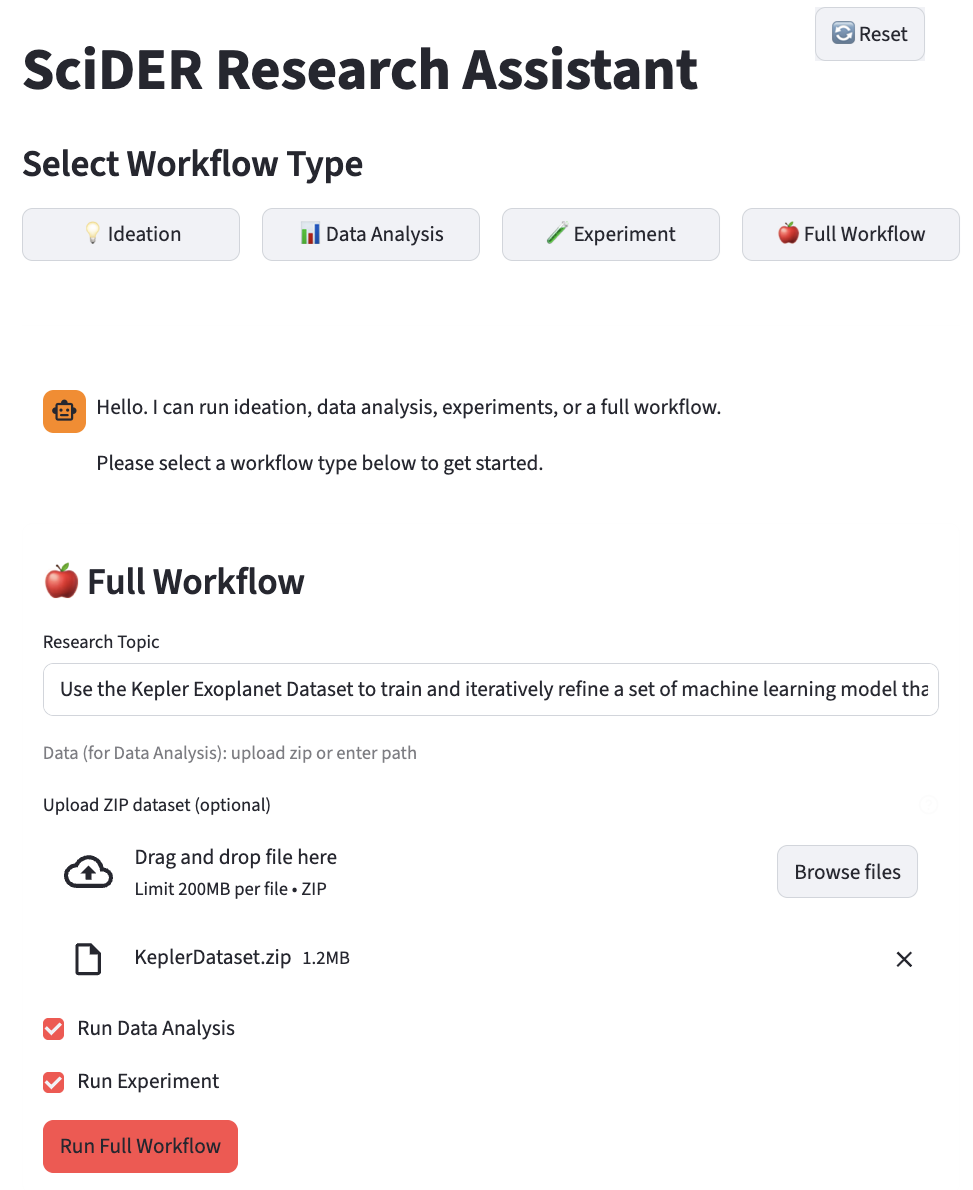
图4:SciDER 的 Web UI 界面——用户选择工作流程(Ideation、Data Analysis、Experiment或完整流程),输入研究主题(这里是 Kepler 系外行星数据集的研究),上传数据文件(KeplerDataset.zip,1.2MB),然后点击"Run Full Workflow"启动全流程。
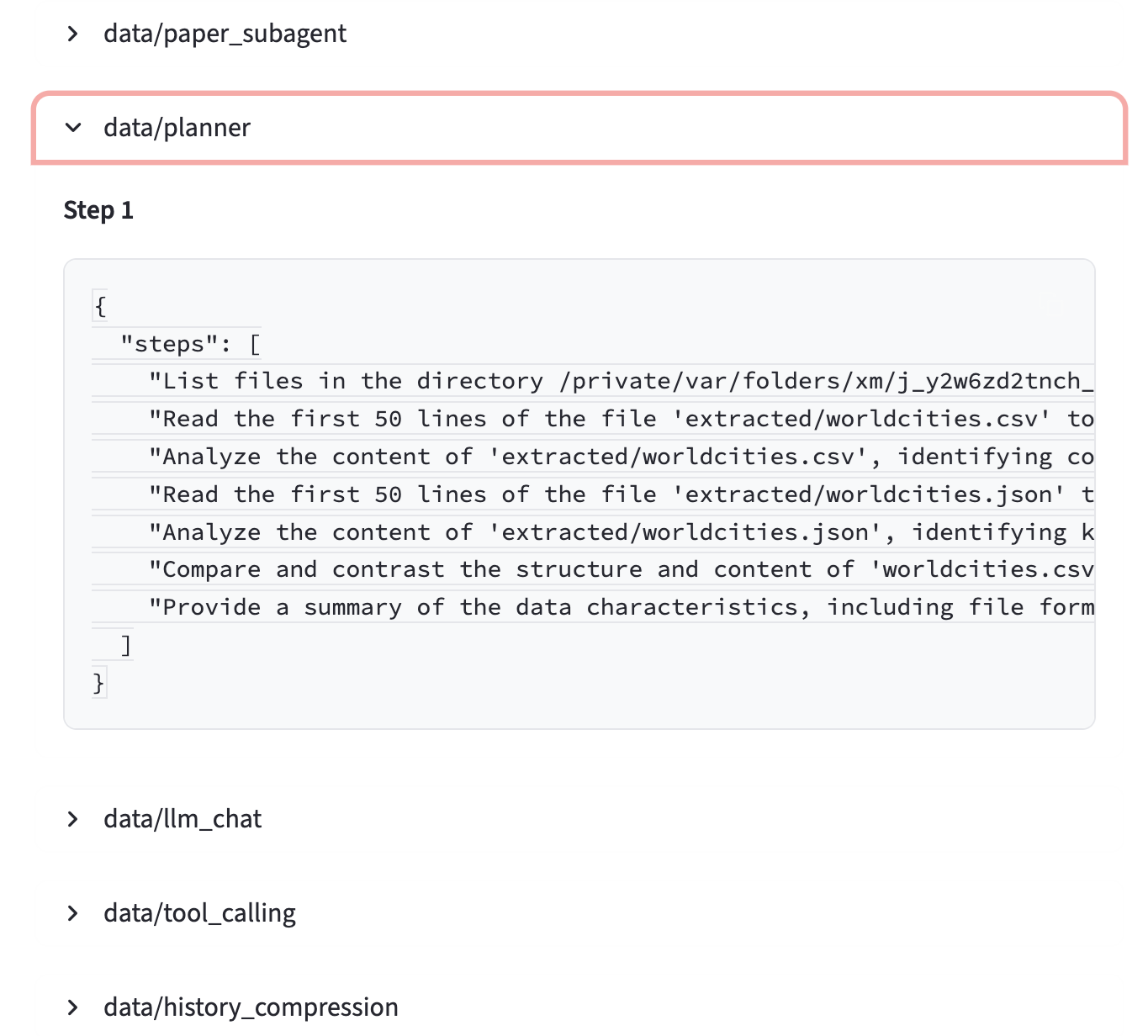
图5:手风琴式的 UI 展示各智能体的中间执行状态——可以实时查看每个子智能体(data/paper_subagent、data/planner等)的工作进度和详细步骤,包括文件列表扫描、数据读取、分析计划等。
整个流程完全自动化:
-
Ideation Agent 自动检索了 15 篇相关文献,识别出四个关键研究主题:Performance Maximization(性能最大化)、Feature Engineering(特征工程)、Domain-Specific Classification(领域特定分类)、Advanced ML Techniques(先进ML技术),然后生成了研究方案——题目是 “Autonomous Feature Hypothesis Generation and Refinement for Exoplanet Transit Detection in Kepler Light Curves”。
-
Data Analysis Agent 自动解析了 ZIP 包中的数据文件,生成了包含结构、质量、语义和依赖关系的数据报告。
-
Experiment Agent 自主生成了完整的实验代码——包括数据加载、预处理、特征工程和模型训练。
-
经过多轮 Critic 反馈和迭代优化后,最终选定 Gradient Boosting 作为最佳模型,使用了 19 个特征,达到了 F1 = 0.9813(约 98% 的 F1 分数)。

图6:案例研究的最终输出——左侧显示文献综述摘要(15篇论文)和生成的研究标题;右侧显示实验结果(最佳模型GradientBoosting,19个特征,F1=0.9813)以及生成的Python代码预览。
98% 的 F1 分数在系外行星检测这个任务上已经非常出色了。而且这一切都是全自动完成的——从用户上传 ZIP 文件到拿到最终结果,中间不需要任何人工干预。
👨🔬 人工评估:13位领域专家的打分
光看自动化基准不够,作者还请了 13 位领域专家(包括博士生、教授和工业界研究人员)对 SciDER 的输出进行人工评估。采用 1-5 分制的"有用性"评分:
- 1分:系统完全无用,需要人工从头来
- 2分:见解浅显,需要大量修正
- 3分:能完成常规任务(基础数据分析),但缺乏深度
- 4分:展现出对数据中心范式的清晰理解,生成结构化报告和可执行脚本,显著节省时间
- 5分:充当高级研究合作者,提供深刻的科学洞察,生成即可使用的高质量代码和报告
最终平均得分 4.846 / 5.000,方差仅 0.376。这意味着 13 位专家几乎一致认为 SciDER 达到了"高级研究合作者"的水平。这个评分相当惊人——别忘了评价者包括教授,他们可不是容易被忽悠的。
📊 为什么"以数据为中心"这件事很重要?
回头看看 SciDER 和之前方法的根本区别:AI-Scientist 和 AI-Researcher 这类系统是围绕任务(“在 CIFAR-10 上提升分类精度”)来组织工作流的,而 SciDER 是围绕数据来组织的。
这两种范式的差距,在面对非标准场景时会急剧放大。现实世界中大部分科学数据——比如基因组测序结果、望远镜观测数据、化学分析谱图——都不是整理好的标准数据集。它们格式各异,有缺失值,字段含义需要领域知识才能理解。传统的 AI 科研系统对这些数据束手无策,因为它们没有"从零理解一份数据"的能力。
SciDER 的 Data Analysis Agent 补上了这个环节。通过自动生成涵盖结构、质量、语义、依赖四个维度的数据报告,它让后续的创意生成和实验设计有了坚实的数据基础。创意不再是天马行空的空想,而是基于数据特征的有的放矢。
💡 我的思考和评价
做得好的地方
1. 抓住了真正的痛点。 AI科研助手领域已经很卷了,但绝大多数工作还在卷"怎么在已有benchmark上跑更高分"。SciDER 跳出了这个圈子,直接面对"真实科学数据"这个更难但更有价值的问题。这个定位我觉得比很多同期工作高明。
2. Critic Agent 的设计很讨巧。 迭代评审不是什么新概念,但在 AI 科研系统中,让一个专门的智能体扮演"导师"角色并形成闭环反馈,确实能有效提升输出质量。Gold Medal 率远高于 Any Medal 率这个现象就很能说明问题。
3. 自进化记忆的混合检索策略比纯向量搜索更实用。科学术语有很多精确匹配的需求(比如化学式、基因名称),纯语义搜索容易漏掉这些。
值得讨论的地方
1. 模型选择的组合有点"拼凑"感。 Ideation 用 gemini-2.5-flash,实验编码用 Claude Code + Claude 4 Sonnet——这种跨厂商的组合实际部署时会带来额外的复杂度和成本管理问题。当然,也可以理解为"物尽其用",每个环节选最适合的模型。
2. SciCode 的绝对数字还是偏低。 虽然超过了 GPT-5,但主问题解决率也才 15.38%——意味着大约 85% 的科学编程问题还是搞不定。科学计算确实很难,但这也说明路还很长。
3. 人工评估的样本量(13人)偏小。 4.846/5.000 的分数很亮眼,但如果扩大到 50-100 位评估者,得分是否还能维持在这个水平?不同学科的研究者可能有很不同的预期。
4. 迭代次数和成本没有详细披露。 Critic Agent 的反馈循环迭代多少轮?每轮消耗多少 token?对于实际使用者来说,这些信息很重要——毕竟 API 调用是要花钱的。
对从业者的启示
如果你在做 AI 辅助科研相关的工作,SciDER 有几个思路值得借鉴:
- 数据报告作为中间表示:在任何涉及数据分析的智能体流程中,加一个专门的"数据理解"环节,输出结构化的数据画像报告。这比直接把原始数据丢给 LLM 效果好得多。
- 混合检索的记忆系统:语义搜索 + 关键词搜索的组合在科学场景下特别有价值。
- "导师-学生"式的迭代评审:在多智能体系统中设置一个独立的 Critic 角色,比让执行智能体自我评估更可靠。
🔗 相关资源
- 论文:arXiv:2603.01421
- GitHub:论文提供了开源代码仓库,Apache 2.0 许可证
- PyPI:可通过 pip 直接安装
- HuggingFace Demo:提供在线试用
📝 总结一句
SciDER 把 AI 科研助手从"刷 benchmark 的考试机器"升级成了"能理解原始数据的实验室伙伴"。在 AI-Idea-Bench 上创意质量几乎翻倍、在 MLE-Bench 上金牌率领先近 8 个百分点、在 SciCode 上超过 GPT-5——这些成绩证明了"以数据为中心"这条路走得通。不过,15% 的科学编程问题解决率也在提醒我们:让 AI 真正成为合格的科研伙伴,我们才刚走出第一步。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 2
2 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)