别再让用户盯着空白等!AI Skill 长耗时执行的优雅处理方案
🚀 本文收录于Github:AI-From-Zero 项目 —— 一个从零开始系统学习 AI 的知识库。如果觉得有帮助,欢迎 ⭐ Star 支持!
如果一个Skill执行耗时很长,你会如何处理?
一、沉默等待:最糟糕的用户体验
耗时Skill最容易犯的工程错误是"沉默等待"——用户发出消息,然后什么反馈都没有,几十秒后要么收到结果,要么收到一个冷冰冰的报错。
说人话就是: 想象你去餐厅点了一份牛排,服务员收了单子后就消失不见,30分钟后突然端上牛排或者告诉你"厨房没肉了"。整个过程中你不知道订单是否被接受、厨师是否在做、还需要等多久。这种体验让人焦虑又无助。
这是把同步思维套在异步问题上的典型症状。正确的处理方式分三个层次:
- 立即给用户确认(ack)
- 任务异步执行
- 完成后主动推送
超时和重试是在"任务异步执行"这一层处理的,用户反馈是贯穿全程的信息流,不是事后的补丁。
对于OpenClaw,这个问题尤其具体:Skill由Brain调用,执行结果要回到ReAct循环,用户界面是Telegram/WhatsApp这类消息平台。消息平台天然支持异步推送,是处理长任务的理想载体——你发出任务,去做别的事,完成了收一条通知,这就是Agent最理想的交互形态。
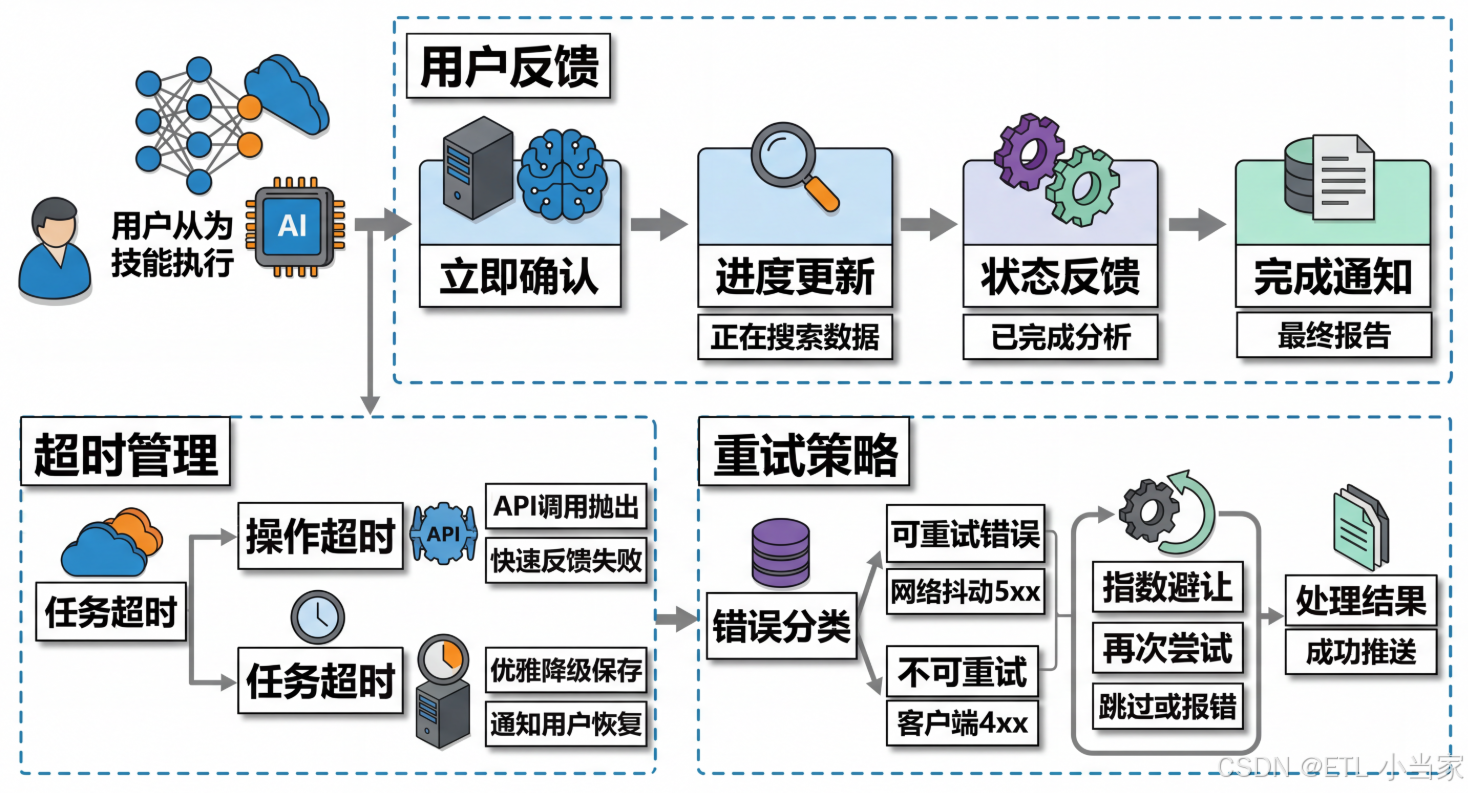
二、用户反馈:不要让用户盯着空白等
Skill开始执行的第一件事,应该是立刻告诉用户"我收到了,正在处理"。这不只是UX优化,是对用户信任的基本尊重。
进度反馈的最佳实践
OpenClaw支持Telegram的draft streaming(边思考边显示草稿),但对于真正的长任务(分钟级),还需要主动的阶段性进度更新:
// Skill 内部的进度反馈模式
async function longRunningSkill(context, params) {
const { sendProgress } = context; // Gateway 注入的推送函数
await sendProgress('🔍 正在搜索相关资料...'); // 立刻反馈
const searchResults = await searchWithTimeout(params.query, 30_000);
await sendProgress(`📄 找到 ${searchResults.length} 条结果,正在分析...`);
const analysis = await analyzeWithTimeout(searchResults, 60_000);
await sendProgress('✍️ 正在生成报告...');
const report = await generateReport(analysis);
return { success: true, report }; // 最终结果回到 Brain
}
进度消息的设计原则
| 原则 | 好的例子 | 坏的例子 |
|---|---|---|
| 信息量 | “已处理3/5个文件” | “正在处理” |
| 频率控制 | 每5-10秒一条 | 每秒多条 |
| 状态明确 | “第2步:分析完成,进入第3步” | “还在运行” |
| 可操作性 | “需要2分钟,可以稍后查看” | “请等待” |
进度消息要有实际信息量——"正在处理"毫无意义,"已处理3/5个文件"才有意义。同时要控制频率,每隔5-10秒一条,太频繁反而是噪音。
三、超时:两层超时,语义不同
超时需要区分两个层次,它们的语义和处理方式不同:
操作级超时(Operation Timeout)
- 作用范围:单个外部API调用
- 触发后果:立刻throw,让上层决定是否重试
- 典型设置:5-30秒
// 带超时的 fetch 封装
async function fetchWithTimeout(url, options = {}, timeoutMs = 10_000) {
const controller = new AbortController();
const timer = setTimeout(() => controller.abort(), timeoutMs);
try {
const response = await fetch(url, { ...options, signal: controller.signal, });
if (!response.ok) throw new Error(`HTTP ${response.status}`);
return await response.json();
} catch (err) {
if (err.name === 'AbortError') {
throw new Error(`Request timed out after ${timeoutMs}ms`);
}
throw err;
} finally {
clearTimeout(timer);
}
}
任务级超时(Task Timeout)
- 作用范围:整个Skill的总执行时限
- 触发后果:取消所有子操作,保存当前进度,告知用户可恢复
- 典型设置:2-10分钟
// 任务级超时用 Promise.race
async function skillWithTaskTimeout(skillFn, taskTimeoutMs = 120_000) {
const timeoutPromise = new Promise((_, reject) =>
setTimeout(() => reject(new Error('Task timeout')), taskTimeoutMs)
);
return Promise.race([skillFn(), timeoutPromise]);
}
超时策略对比
| 超时类型 | 处理方式 | 用户体验 | 适用场景 |
|---|---|---|---|
| 操作级 | 立即失败,可能重试 | 快速反馈 | 单个API调用 |
| 任务级 | 优雅降级,保存进度 | 可恢复操作 | 复杂长任务 |
四、重试:不是所有错误都值得重试
重试策略的核心是区分可重试错误和不可重试错误:
async function retryableSkillStep(fn, stepName, maxRetries = 3) {
const NON_RETRYABLE = [400, 401, 403, 404, 422];
for (let attempt = 0; attempt <= maxRetries; attempt++) {
try {
return await fn();
} catch (err) {
const isLastAttempt = attempt === maxRetries;
const isNonRetryable = NON_RETRYABLE.includes(err.status);
if (isLastAttempt || isNonRetryable) {
return {
success: false,
stepName,
retryable: !isNonRetryable,
attempts: attempt + 1,
error: err.message,
};
}
const delay = 500 * Math.pow(2, attempt); // 500ms, 1s, 2s
await sleep(delay);
}
}
}
const sleep = ms => new Promise(resolve => setTimeout(resolve, ms));
错误分类指南
| HTTP状态码 | 错误类型 | 是否重试 | 原因 |
|---|---|---|---|
| 4xx系列 | 客户端错误 | ❌ 不重试 | 请求本身有问题 |
| 5xx系列 | 服务端错误 | ✅ 重试 | 服务器临时故障 |
| 网络超时 | 连接问题 | ✅ 重试 | 网络抖动 |
| 认证失败 | 权限问题 | ❌ 不重试 | 凭证无效 |
五、完整的长任务处理流程
把三者串联起来,形成完整的用户体验:
用户发起任务
↓
立即确认:"收到!正在处理..."
↓
启动异步任务(带任务级超时)
↓
任务执行中 → 阶段性进度更新(每5-10秒)
│ ↓
│ 操作级超时? → 重试或标记失败
│ ↓
└─── 任务级超时? → 保存进度,通知用户
↓
任务完成 → 推送最终结果
用户看到的完整反馈流
- 即时确认:“🔍 开始处理您的请求…”
- 进度更新:“📄 已分析50个文档,找到12个相关结果”
- 可能的重试:“⚠️ 网络不稳定,正在重试第2次…”
- 完成通知:“✅ 报告生成完成!共3页,包含关键发现摘要”
异常情况处理
- 操作失败:“❌ 第3步失败:API返回404错误,跳过此步骤继续”
- 任务超时:“⏰ 任务超时(2分钟),已保存当前进度。回复’resume’继续”
- 完全失败:“💥 任务失败:所有重试都已用尽。建议检查输入参数”
六、设计哲学:信任与透明
用户看到的每一条反馈,都应该帮助他决定下一步做什么:
- 超时告诉他能不能恢复
- 失败告诉他是否要重试
- 成功给他足够的信息判断结果是否可用
沉默等待、然后扔一个无上下文的报错,是最差的体验。
在Agent时代,长任务处理不仅仅是技术问题,更是信任建立的过程。每一次及时的反馈都在告诉用户:“我在工作,你可以信任我”。
核心原则总结
- 永远不要沉默:即使没有进展,也要告知用户状态
- 提供可操作信息:进度数字比模糊描述更有价值
- 优雅处理失败:失败时提供恢复选项,而不是终结对话
- 尊重用户时间:预估时间并遵守承诺
好的长任务处理,让用户感觉是在和一个可靠的助手合作,而不是在等待一个黑盒系统。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 22
22 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)