别再只打日志了:用 openJiuwen 采集 Agent Trajectory,搭一套 RL 训练数据流水线
引言|Agent 明明已经跑起来了,为什么我们还是不知道它到底跑得怎么样?
这两年,大家做 Agent,最容易先获得的一种成就感,其实不是“系统变聪明了”,而是“系统终于能跑了”。
工具能挂上,Workflow 能串起来,模型也能根据上下文做出一轮轮调用。表面看上去,一个智能体系统已经具备了相当完整的工作链路:它能理解问题,能决定什么时候调工具,也能把工具结果继续往后推进,最后给出一个像样的回答。很多团队做到这一步,就会自然进入下一阶段——开始谈稳定性、谈效果、谈优化,甚至开始谈自动调参、谈 RL、谈 Agent 自演进。
但真正进入工程现场之后,很快就会发现,“能跑”这件事,和“能被优化”之间,其实隔着一整套数据基础设施。
在实际开发里,很多 Agent 系统的观测方式仍然停留在传统应用日志的思路上:请求来了、模型调了、工具调用了、接口报没报错、最终有没有返回结果。这种记录方式对排查服务异常当然有用,可一旦真的想回答更深入的问题,它就立刻开始失效。
比如,线上某一次失败发生了,在日志里能看到一个 error,最多再加上一条 tool call 失败信息。但你看不到的是:模型在那一刻究竟看到了什么工具描述,基于什么 system prompt 在做决策,当时使用的 model、temperature、top-p 是多少,它前面几步已经积累了哪些中间状态,又是在第几轮推理里偏离了原本的任务目标。
换句话说,看到的是“坏结果”,却看不到导致这个坏结果的决策轨迹。
更麻烦的是,哪怕一次任务成功了,这个成功往往也只是“成功地发生过”,却不是“可以被解释、被复现、被比较的成功”。
很多时候我们会说,这次 Agent 跑得不错,回答也对,工具也调对了。但如果你追问一句:它为什么这次调对了?是工具描述写得更清楚了,还是模型参数碰巧更合适,还是上下文恰好规避了某种歧义?
大部分系统其实答不上来。成功被记录成了一个结果,却没有沉淀成一个可以继续学习的样本。这也是为什么,很多 Agent 项目一旦往“优化”这个词再往前走半步,就会突然卡住。以为接下来该做的是调 prompt、换模型、加规则,甚至上强化学习;但真到了要动手的时候才发现,自己手里根本没有一份像样的训练数据。没有结构化的轨迹,没有标准化的 step 级记录,没有办法对齐一次任务中“输入—决策—调用—反馈—结果”的完整链条。于是所谓优化,最后又会退回到一种很熟悉但也很脆弱的状态:靠经验猜,靠个案改,靠几次线上表现主观判断。
从这个角度看,openJiuwen 的 Agent 轨迹采集,真正值得关注的地方,并不只是“多记录了几项日志字段”,而是它开始把 Agent 的运行过程,从“服务执行过程”重新建模成一种可分析、可复盘、可训练的数据对象。
尤其当它把工具描述**、**LLM 参数——比如 model、top-p、temperature——也纳入采集范围之后,这件事的意义就变了。因为这意味着,未来我们讨论 Agent 表现时,终于不再只能盯着最终输出,而是可以把模型决策时所处的条件也一起纳入观察。这样一来,所谓“优化”才第一次有了落地的抓手:我们不是在优化一个黑盒结果,而是在优化一条条可回放、可比较、可筛选的行为轨迹。
我自己在看 openJiuwen 这个能力的时候,最强烈的感受并不是“它已经直接解决了 RL 的问题”,而是:它把 RL 训练、参数优化、工具描述自演进这些事情真正需要依赖的数据底座,往前推了一大步。
这一步非常关键。因为对大多数工程团队来说,现阶段真正缺的并不是一个“强化学习按钮”,而是一套足够严谨的基础设施,让你能先把 Agent 的行为过程稳定地采下来、存下来、还原出来,并最终变成可以进入评测、筛选和训练环节的数据。
如果我们今天就想把 Agent 系统往“可持续优化”推进一步,那么第一件真正值得做的事,到底是什么?
答案很可能不是继续堆提示词,也不是马上更换模型,而是先把Trajectory 这件事认真做好。
也就是:先定义清楚什么叫一条可用的 Agent 轨迹,先设计好它的 schema,先把数据采集 pipeline 跑通,先让系统里那些原本一闪而过的推理过程,变成后续可以复盘、评测、训练的长期资产。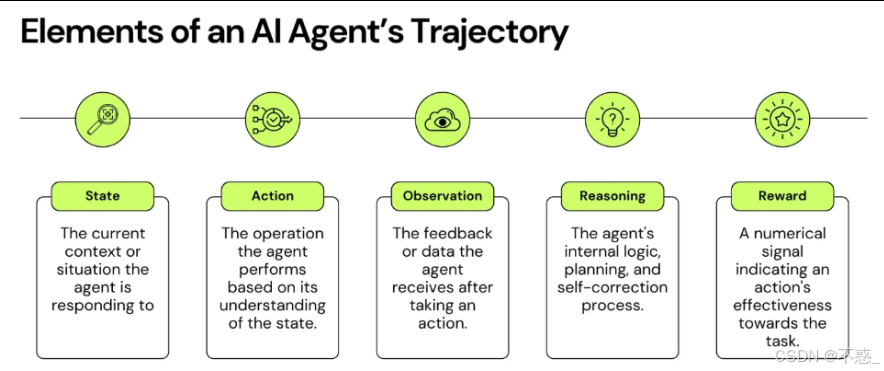
这也是本文真正想展开的主题:
不是把 Agent 当成一个会返回答案的应用,而是把它当成一个持续产生决策轨迹的数据系统。
我是 Fanstuck,我更关心那些真正能把大模型系统从“能演示”推进到“能迭代”的工程问题。
如果你也对 Agent、openJiuwen、轨迹采集、训练数据基础设施这些方向感兴趣,后面的内容我们继续往深里拆。
第一章|为什么 Agent 需要的不是更多日志,而是可训练的 Trajectory
1.1 Agent 真正的问题,从来不是“能不能跑起来”
这两年做 Agent,最容易让人产生进展感的时刻,往往不是模型变得多聪明,而是系统终于“跑通了”。
工具接上了,Workflow 串起来了,模型也能根据上下文决定什么时候调用外部能力。表面上看,这已经像是一套完整的智能体系统:它能理解任务,能进行多轮推理,能调工具,也能把结果继续往后组织,最后给出一个看起来还不错的回答。
但工程上真正麻烦的地方,恰恰不在“它能不能跑”,而在“它为什么这样跑”。
因为一个系统只要进入真实业务环境,团队接下来关心的问题就一定会发生变化。大家不会一直停留在“终于能调用成功一次”的兴奋里,而是会很快追问更本质的事情:这次为什么成功?上次为什么失败?是工具描述不够清楚,还是模型参数不合适?是 prompt 有歧义,还是工具选择策略本身就有问题?
也就是说,Agent 一旦进入生产阶段,系统的核心矛盾就不再是可执行性,而会逐渐转向可解释性和可优化性。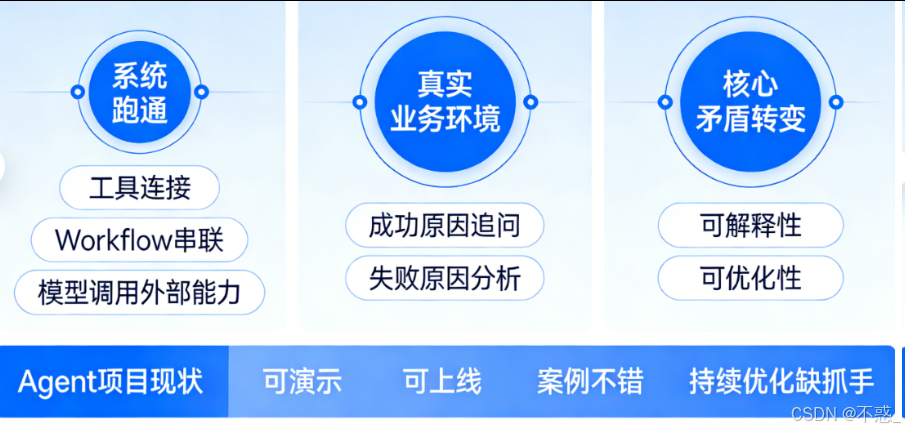
这也是为什么,很多 Agent 项目虽然已经具备一定可用性,却还是会停在一个很尴尬的位置:
可以演示,可以上线,甚至能做出一些不错的案例,但一旦真的要进入持续优化,就开始缺抓手。
1.2 传统日志能告诉你系统报没报错,却回答不了它为什么做错
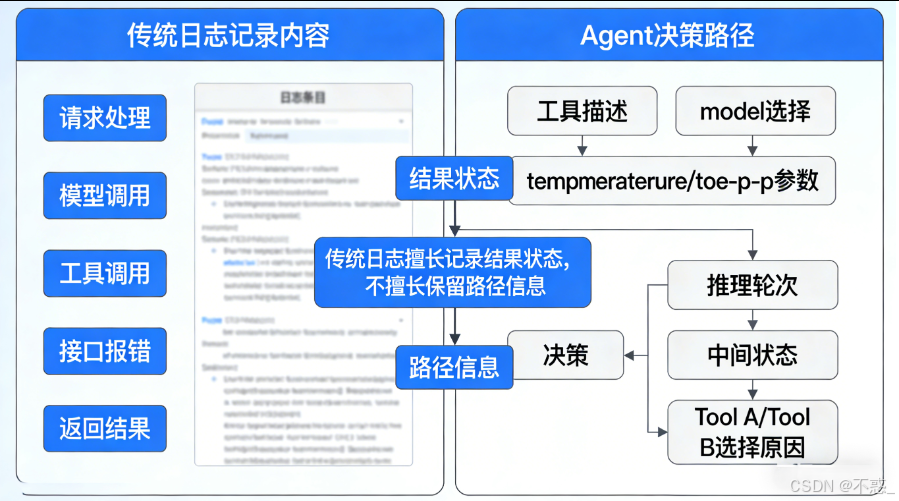
在实际开发中,很多团队对 Agent 的观测方式,仍然沿用了传统应用系统的日志思路。
请求来了,模型调了,工具调用了,接口有没有报错,最终有没有返回结果——这一套记录方式对排查异常当然是有价值的。至少你能知道服务是不是挂了,接口是不是超时了,某个工具是不是调用失败了。
问题在于,Agent 的复杂性并不只体现在“有没有执行成功”,而是体现在它中间经历了一整条连续的决策过程。
比如一次任务失败了,日志里也许能看到一条 error,运气好一点,还能看到是哪一次 tool call 失败。但这些信息依然不够支撑深入分析。因为真正关键的问题往往是日志回答不了的:
模型当时看到的工具描述是什么?
它使用的是哪一个 model?
temperature 和 top-p 设成了多少?
它是在第几轮推理里开始偏离原任务目标的?
在调用失败之前,它已经积累了哪些中间状态?
它为什么没有选 Tool A,而是去调了 Tool B?
这些问题之所以重要,是因为 Agent 的错误,很多时候并不是“系统坏了”,而是决策路径偏了。
而传统日志擅长记录的是“结果状态”,不擅长保留“路径信息”。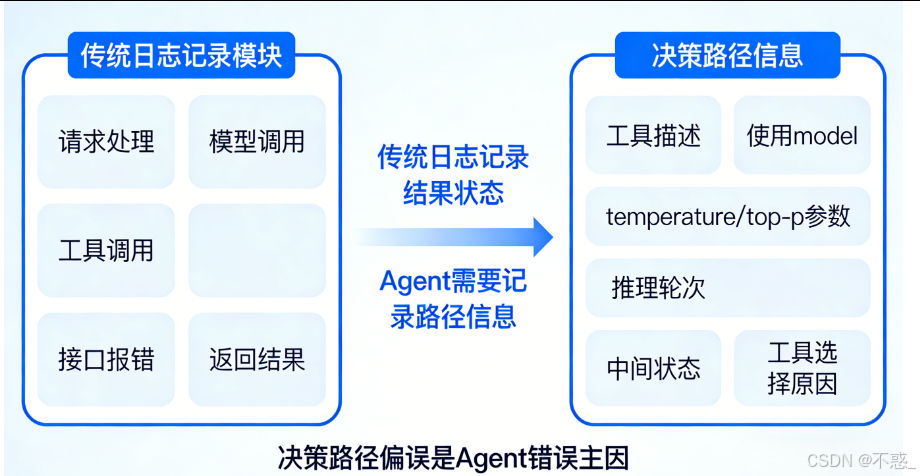
所以你最后会陷入一种很熟悉的被动状态:
看到坏结果,却看不到坏结果是怎么形成的。
1.3 没有轨迹数据,所谓优化最后还是只能靠经验猜
比失败更麻烦的,其实是成功。
因为失败至少会引发排查,成功却很容易被直接归档成“这次没问题”。但对于 Agent 来说,一次成功如果不能被解释,它本质上也只是偶然发生过一次,而不是沉淀成了可以复用的经验。
很多团队都会遇到这种情况:某次任务跑得很好,工具调用准确,结果也符合预期。可如果你进一步问一句——它为什么这次调对了?——系统通常答不上来。
到底是因为工具描述更清晰了,还是因为那次输入刚好比较标准?
到底是某组参数配置确实更优,还是只是碰巧避开了歧义?
到底是模型策略更稳定了,还是样本本身太简单?
如果这些问题无法回答,那么所谓“优化”就会很快退化成另一种形式的经验主义:
调一调 prompt,换一换模型,试一试参数,观察几次线上结果,再凭直觉判断哪种方案更好。
这种方式在小规模试验阶段还能勉强推进,但只要系统规模稍微变大,它的问题就会暴露得很明显。你没有办法做稳定对比,没有办法做回放分析,也没有办法把线上行为沉淀成后续评测和训练的数据资产。
也正因为如此,很多 Agent 项目一旦开始往更深的方向走——不管是工具描述优化、参数搜索,还是进一步讨论 RL、自动调参、策略学习——都会突然意识到一个基础问题:
手里根本没有足够像样的数据。
没有结构化的轨迹,没有标准化的 step 级记录,也没有办法把一次任务中的输入、决策、调用、反馈和结果完整串起来。优化说到底就失去了数据依托,最后只能靠个案观察和人工经验继续往前推。
1.4 Trajectory 的价值,不是“多打了几条日志”,而是重新定义了 Agent 数据
也正是在这个意义上,Trajectory 才不只是一个比“日志”更时髦的名字。
它真正重要的地方,在于它把 Agent 的运行过程从“服务执行记录”重新建模成了一种可分析、可复盘、可训练的数据对象。
这件事听上去像是记录粒度变细了,但本质上是建模方式变了。
过去我们更习惯把一次 Agent 调用看成“输入进来,结果出去”的黑盒过程;而 Trajectory 关注的,是结果形成之前那条完整的行为路径。
一次任务不再只是 request 和 response。
它开始被拆成更细的步骤:哪一步是模型生成,哪一步是工具调用,哪一步拿到了 observation,哪一步因为异常发生偏移,哪一步又重新回到了主链路。
更关键的是,轨迹记录的不只是“发生了什么”,还要记录“它在什么条件下发生”。
这也是我认为 openJiuwen 这次 Agent 轨迹采集能力很值得关注的原因。
它不是简单多加了几个监控字段,而是把工具描述、LLM 参数——像 model、top-p、temperature ——这些过去经常被忽略、但实际上高度影响决策结果的条件信息,也纳入了轨迹采集范围。
一旦这些信息被稳定记录下来,后面的很多事情才第一次真正有了基础。你可以去比较不同工具描述版本对应的调用成功率,可以分析某组参数对任务结果的影响,可以把成功轨迹和失败轨迹拉出来做对照,也可以在更长远的阶段,把这些行为过程沉淀成评测和训练样本。
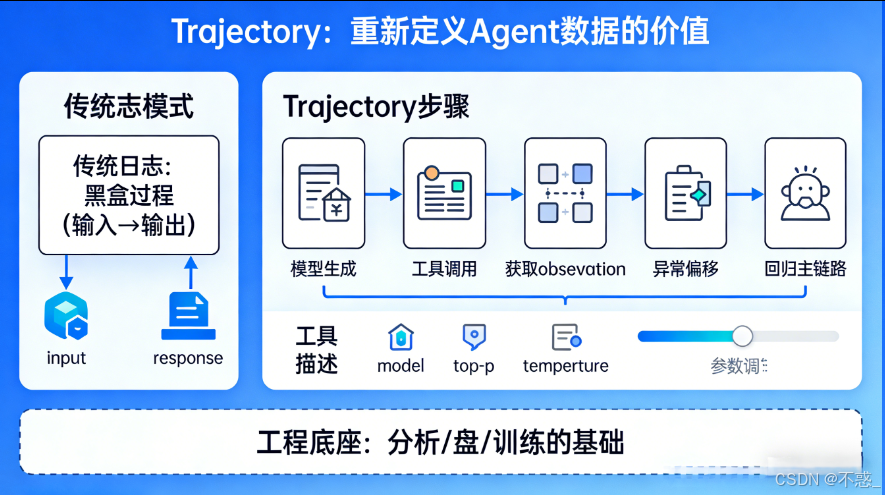
所以从工程角度看,Trajectory 不是优化完成之后的附属品,恰恰相反,它是优化真正开始之前必须先补上的底座。
第二章|openJiuwen 官方 Trajectory,到底提供了什么?
如果只从名字上看,Trajectory 很容易被理解成“更高级一点的 tracing”。
但真正看 openJiuwen 官方定义,会发现它做得比这个更扎实。2.1 ExecutionSpec:先把“这次执行是谁”说清楚
ExecutionSpec 用来描述单次执行的元信息。官方文档里,它至少包含 case_id、execution_id,并支持可选的 seed 和 tags。这层设计的意义很直接:它先告诉你,这条轨迹属于哪个样本、哪次执行、带着什么标签。
这看上去只是元数据,但它非常关键。
因为后面你无论做轨迹筛选、结果对比还是训练样本导出,都需要先知道“这条轨迹是哪一条”。
2.2 TrajectoryStep:把单步执行变成标准对象
TrajectoryStep 是官方 trajectory 里最核心的一层。
文档里它把单步类型抽象成 StepKind,包括 "llm", "tool", "memory", "workflow", "agent";同时一个 step 还会记录 operator_id、agent_id、role、node_id、inputs、outputs、error、时间字段以及 meta。
这一层很重要,因为它说明 openJiuwen 并不是只想让你“知道有个调用发生过”,而是希望你能够明确看到:
这一步是什么类型;
由哪个算子或节点发起;
输入是什么;
输出是什么;
是否报错;
它在整条执行链路中处于什么位置。
也就是说,官方已经把“单步行为”抽成了标准化的数据粒度。
2.3 Trajectory:把零散 step 组织成完整链路
如果说 TrajectoryStep 解决的是“单步长什么样”,那 Trajectory 解决的就是“这些步是如何组成一条完整执行链路的”。
根据官方文档,Trajectory 至少包含 case_id、execution_id、可选的 trace_id、steps,以及可选的 edges。这里的 edges 很关键,它意味着轨迹并不是简单的步骤列表,而是带依赖关系的执行图。
这一步很值钱。
因为很多时候,Agent 的问题不是某一步单独错了,而是它在前面某个节点已经偏了,后面只是在不断放大这个偏差。
没有依赖关系,你只能看见一堆 step;有了 edges,你才能真正看到“链路”。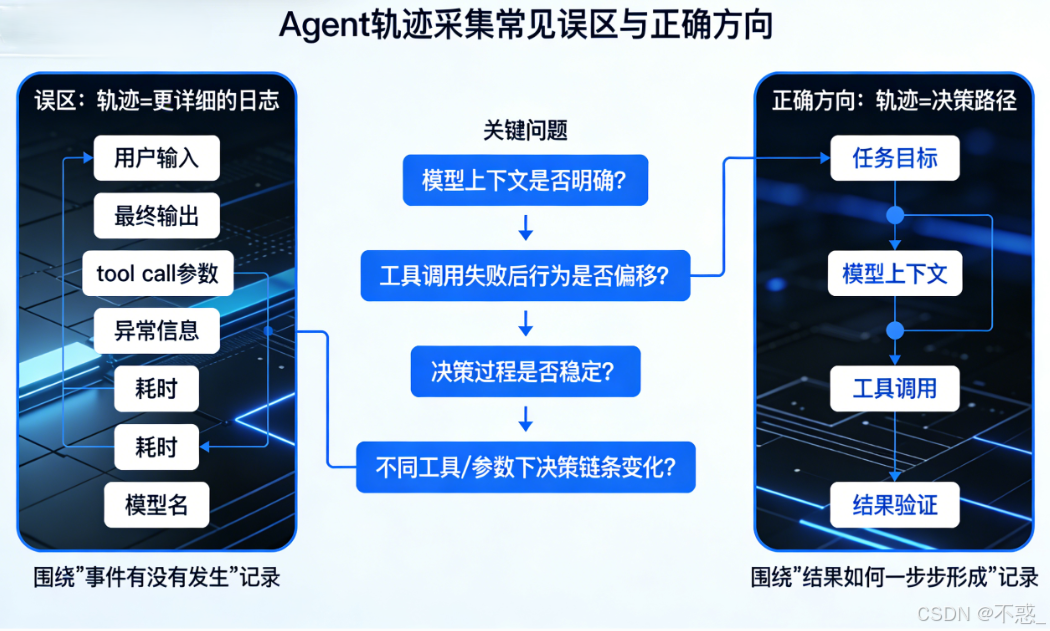
第三章|openJiuwen 官方 Trajectory 抽执行过程
很多团队一提到 Agent 轨迹,第一反应就是先设计一套自己的日志 schema:要不要拆 Session,怎么定义 Episode,Step 里放哪些字段,工具调用和模型输出怎么分层。
这些事情当然都重要,但如果你已经在用 openJiuwen,其实没必要一上来就自己重造一套轨迹对象。
原因很简单:openJiuwen 官方已经在 openjiuwen.agent_evolving.trajectory 里,把“执行轨迹”这件事抽象成了一组可直接使用的标准类型。
它不是停留在“给你打点能力”这个层面,而是已经明确给出了三层核心语义:
ExecutionSpec:描述一次执行是谁、是哪条样本、这次执行带了什么标签;TrajectoryStep:描述轨迹中的单步,区分llm / tool / memory / workflow / agent等不同类型;Trajectory:描述一次完整执行里有哪些步骤,以及步骤之间的依赖关系。
这件事很关键。
因为它意味着,在 openJiuwen 里,轨迹不是散落在日志里的字符串,也不是靠你后处理拼起来的事件列表,而是一个官方定义的标准数据对象。
这样一来,后面很多事情都会简单很多。
你不需要再先花大量精力去思考“日志怎么凑成轨迹”,而是可以把关注点直接放到更有价值的层面:
这条轨迹里有哪些 step?
哪些 step 属于某个指定算子?
一次 case 里 llm 步和 tool 步是怎么衔接的?
哪些失败是某个 operator 导致的?
哪些成功样本可以直接进入后续训练集?
也就是说,openJiuwen 官方 trajectory 的真正价值,不只是“记录了过程”,而是先把过程标准化了。
3.1 从 Session 抽取官方轨迹对象
在 openJiuwen 的这套设计里,最关键的入口不是自己拼日志,而是通过 TracerTrajectoryExtractor,直接从 session.tracer 中抽出一条 Trajectory。
官方给出的抽取接口很明确:
它会从 Session 的 tracer 中解析 agent 和 workflow 的 span,构建步骤列表与依赖边,而不是要求你自己再去理解 core 内部执行细节。
这意味着,对于开发者来说,真正要做的不是“重新建模”,而是在执行完成后,把轨迹对象稳定提出来。
示意代码可以直接写成这样:
from openjiuwen.agent_evolving.trajectory.types import ExecutionSpec
from openjiuwen.agent_evolving.trajectory.operation import TracerTrajectoryExtractor
execution = ExecutionSpec(
case_id="case_001",
execution_id="exec_001",
seed=42,
tags={"scene": "tool_use", "env": "dev"}
)
extractor = TracerTrajectoryExtractor()
trajectory = extractor.extract(session, execution)
print("case_id:", trajectory.case_id)
print("execution_id:", trajectory.execution_id)
print("steps:", len(trajectory.steps))
print("edges:", trajectory.edges)
这段代码背后的意义,比表面上看要大得多。
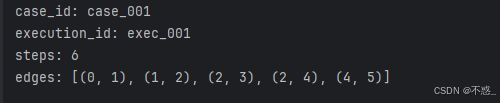
因为从这一刻开始,你手里拿到的就不是一堆零散日志,而是一条真正有结构的官方轨迹:
它有 case_id,有 execution_id,有 steps,也有 edges。
也就是说,一次 Agent 执行不再只是“发生过”,而是被还原成了一条可以被继续分析和消费的行为链路。
3.2 轨迹真正好用的地方,不是抽出来,而是能按条件筛
很多系统的问题,从来不是“拿不到数据”,而是“拿到了也不好分析”。
如果轨迹抽出来之后仍然只能整条看,那它对后续优化的帮助依然有限。
openJiuwen 在这里做得比较实用,它没有停留在“导出一整条 trajectory”这一步,而是继续提供了 step 级筛选接口,比如 iter_steps 和 get_steps_for_case_operator。
这意味着你可以非常直接地回答一些工程上很常见的问题:
- 某个 case 里,指定 operator 触发了哪些 llm 步?
- 某类 tool step 的输入输出到底是什么?
- 某个算子在失败样本里是不是总是出现相似错误?
- 同一个 operator,在不同 case 里的表现是否稳定?
示例代码可以这样写:
from openjiuwen.agent_evolving.trajectory.operation import (
iter_steps,
get_steps_for_case_operator,
)
trajectories = [trajectory]
# 过滤所有 tool 步
tool_steps = list(iter_steps(trajectories, kind="tool"))
for step in tool_steps:
print(step.kind, step.operator_id, step.inputs, step.outputs)
# 过滤某个 case 下某个 operator 的 llm 步
llm_steps = get_steps_for_case_operator(
trajectories,
case_id="case_001",
operator_id="planner",
kind="llm"
)
for step in llm_steps:
print("operator:", step.operator_id)
print("inputs:", step.inputs)
print("outputs:", step.outputs)
print("error:", step.error)
这部分非常值得在文章里强调,因为它直接决定了 trajectory 能不能成为后续优化入口。

如果没有这种官方筛选能力,轨迹很容易退化成“可存档但不好用”的对象;
但一旦可以围绕 case_id、operator_id、kind 去筛步,轨迹就开始真正进入工程分析层。
3.3 openJiuwen trajectory 和训练数据流水线的正确连接方式
这里也是你原文最需要纠正的地方。
以前你的写法更像是:
先自定义 schema,再自建 collector,再自建 queue,再自建 writer,最后再想办法导出训练集。
现在更合理的表达应该是:
openJiuwen 官方 trajectory 负责把执行过程标准化抽出来;而企业自己的数据流水线,负责把这些标准轨迹继续转换成分析视图、评测样本和训练样本。
也就是说,文章里不要再把“轨迹定义”写成你自己的工作,
而要把它写成:
openJiuwen 先完成官方抽象,我只是在这个抽象之上继续做数据消费。
这个关系一定要讲清楚。
举个最直接的例子。
当你拿到 Trajectory 之后,后面就可以做三类很自然的导出:
第一类是 SFT 样本。
把某些执行成功、输出质量稳定的 case,整理成 instruction-response 样本。
第二类是 Preference / 对比样本。
把成功轨迹和失败轨迹,或者同一 case 下不同 operator 配置对应的输出,整理成 chosen / rejected 对。
第三类是 过程监督 / step 级优化样本。
把 TrajectoryStep 里的输入、输出、错误、依赖关系保留下来,用于后续过程评测、badcase 归因,甚至更进一步的策略优化。
换句话说,openJiuwen trajectory 最重要的价值,不是帮你把训练这一步做完,
而是它先给了你一个统一、可靠、官方定义的中间层对象。
有了这个对象,后面的数据沉淀和训练导出才不会每个项目都从零开始拼日志。
第四章|openJiuwen Trajectory 真正带来的,不只是可观测,而是可复用
在很多 Agent 系统里,执行过程虽然发生过,但并没有真正沉淀下来。
日志看起来很多,真正能复盘、能筛选、能比较、能复用的数据却很少。
openJiuwen trajectory 的意义,恰恰在于它没有把执行过程继续留在“零散日志”这个层面,而是先把它组织成了官方标准对象:Trajectory 与 TrajectoryStep。
这一步看起来不像模型升级那样显眼,但它非常关键,因为后续很多优化动作,都会依赖这个统一入口。
比如你想分析某个 operator 的输出不稳定,到底应该看哪些样本;
你想比较不同 case 下某类 llm step 的表现差异;
你想把一批成功执行样本导出成 SFT 数据;
或者你想把失败 case 聚类之后再去做 badcase 修复。
这些事情的前提,都是先有一套稳定可消费的轨迹对象。
所以从工程角度看,openJiuwen trajectory 的价值并不只是“把过程记录下来”,而是它先把过程变成了可被继续加工的数据。
当执行过程开始具备统一结构,Agent 才第一次真正拥有了持续迭代的基础。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)