深度学习的补充:残差网络ResNet(迁移学习)&神经网络做回归(人脸关键点)部分
一、迁移学习
迁移学习是指利用已经训练好的模型,在新的任务上进行微调,迁移学习可以加快模型训练速度,提高模型性能,并且在数据稀缺的情况下也能很好的工作。
步骤:
- 选择预训练的模型和适当的层
- 冻结训练集的参数
- 在新数据集上训练新增加的层或者修改的层
- 微调训练模型的层
- 评估和测试
这里我们选的模型就是残差模型,ResNet,对图像处理能力比较强。
二、残差网络ResNet
1.传统的cnn(卷积神经网络)存在的问题
卷积神经网络都是通过卷积层和池化层的叠加组成的,在实际实验中发现,随着卷积层和池化层的叠加,学习效果不会逐渐变好,反而出现俩个问题:
1)梯度爆炸和梯度消失:梯度消失:若每一层的误差梯度小于1,反向传播时,网络越深,梯度越趋近于0 梯度爆炸;若每一层的误差梯度大于1,反向传播时,网络越深,梯度越来越大
2)退化问题
层数越高,错误率更高些
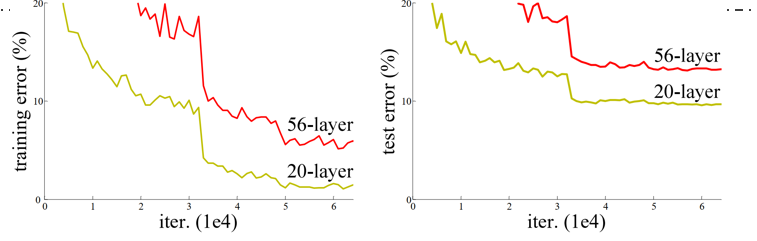
2.解决方法
- 梯度爆炸和消失:通过数据的预处理以及在网络中使用 BN(Batch Normalization)层来解决。
- 深层网络的退化:可以人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为 残差网络 (ResNets)。
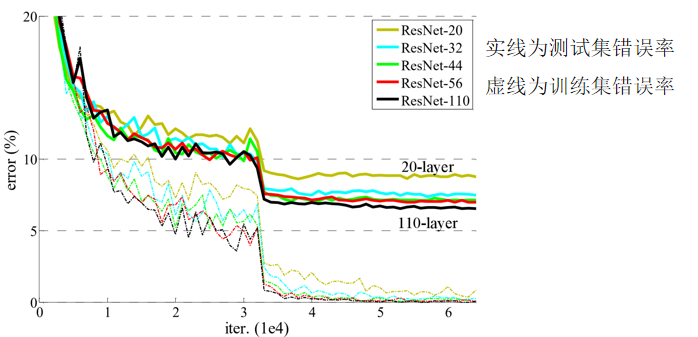
2.残差网络
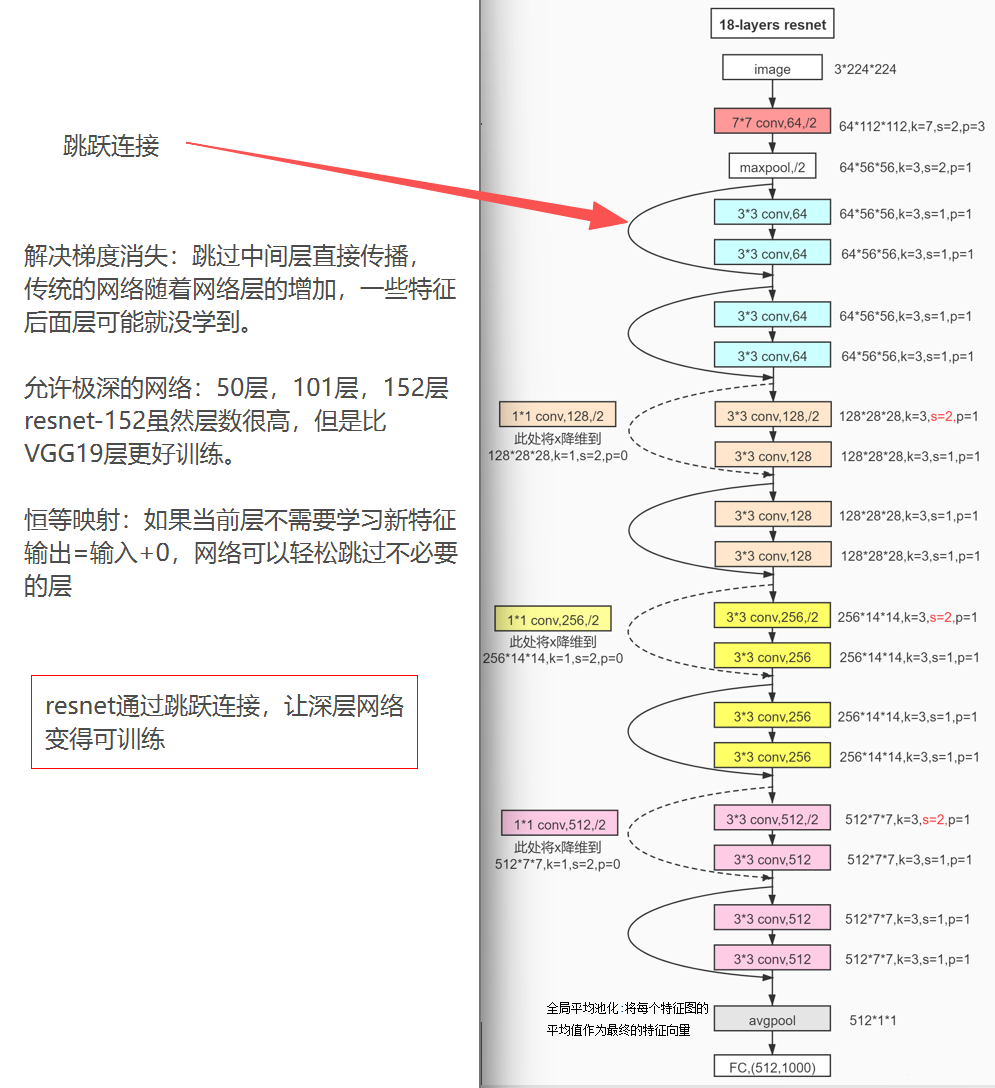
其实比传统的cnn还有一个好处就是,传统的cnn我们需要确定图片的大小,图片大小修改了我们后面搭建的网络有些数值也是需要修改的,但是残差网络就不需要,就是因为最后使用了全局平均池化。无论图片多大最后都池化为1了。
(池化的作用:一种降采样,减少数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。常见的池化层:最大池化、平均池化、全局平均池化、全局最大池化)
但即使如此,我们也有要求残差网络下输入的图片大小,但不是网络结构限制,而是计算资源限制。一般我们都传入224x224的图片。
其他层数的残差网络:
根据这个规律我们可以推测出别的层数的网络结构
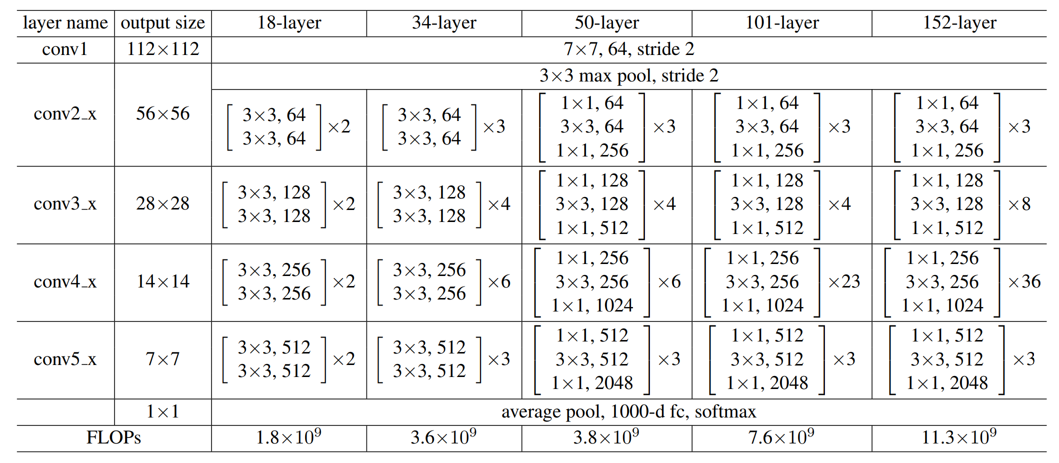
三、搭建模型(迁移学习方法残差网络结构,依旧拿食物识别例子实验)
用别人已经训练好的模型,我们是需要修改的,因此我们有两种思路:训练其中一层;在模型后面增加一层
1.先训练其中一层,这里我们选择最后一层
import torch#搭建网络
from torch.utils.data import Dataset,DataLoader#处理图片数据集,之前我们的数据都是用pandas和numpy
import numpy as np
from PIL import Image#画图板
from torchvision import transforms#对数据进行处理工具,尤其是图片
import torch.nn as nn
import torchvision.models as models#包含了很多搭建好的模型
from torchvision.models import ResNet18_Weights#这里面都是被训练好的模型这里的数据预处理,读取图片,训练函数,测试函数和之前cnn搭建的模型中是一样的可以直接复制
data_transforms = {
…………
}
class food_dataset(Dataset):
…………
def train(dataloader, model, loss_fn, optimizer):
…………
def test(dataloader, model, loss_fn):
…………
return accuracy这里其实就相当于搭建网络,和之前定义cnn类一个性质,加载好别人训练好的模型之后,就要把所有层w权重修改权限全部冻结,然后对最后一层(也就是我们要训练的那一层进行修改),原模型的输出是1000个神经元,但是我们食物分类里面拢共是20个类别,所以这里我们设置为20。
最后w修改权限只给需要解冻的层解冻,也就是我们要训练的最后一层,这里我们还对我们训练的这层的函数进行保存,存在我们定义的一个列表里面。(后面添加一层只有这里是改变的,其他都不变)
# 加载预训练模型
resnet_model = models.resnet18(weights=ResNet18_Weights.DEFAULT)#调用了resnet-18网络
# 冻结所有参数(只训练最后一层)
for param in resnet_model.parameters():#这个在优化器里面也有提到过,获取参数
print(param)
param.requires_grad = False#冻结权重修改权限
# 修改最后一层输出类别,把原定的默认1000修改为这里的二十类,适应我们的模型需要
in_features = resnet_model.fc.in_features # 获取原输出维度512
resnet_model.fc = nn.Linear(in_features, 20) # 创建一个全连接层
##只训练最后一层参数
params_to_update = []#保存需要训练的参数,仅仅包含全连接层的参数
for param in resnet_model.parameters():
if param.requires_grad: # 只收集需要训练的参数
params_to_update.append(param) # 这种写法是收集所有需要训练的参数然后这里也是和cnn训练模型一样的,可以拿过来直接用
training_data = ……
test_data = ……
train_dataloader = ……
test_dataloader = ……
device = "cuda" if torch.cuda.is_available() else "mps" if torch.backends.mps.is_available() else 'cpu'
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(params_to_update, lr=0.001) # 优化器
model = resnet_model.to(device)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.5) # 调度器
best_acc = 0
epochs = 10
…………
print("Dnoe!")
print(f'最佳模型:准确率{best_acc:.2f}%')2.添加一层
导入模块和一些类定义以及后面训练都不变,主要就是加载模型那块
# 加载预训练模型
class resnet_New(nn.Module):
def __init__(self):
super(resnet_New, self).__init__()
# 加载预训练的resnet18
self.resnet = models.resnet18(weights=ResNet18_Weights.DEFAULT)#调用了18网络
self.new=nn.Linear(1000,20)
def forward(self,x):
x=self.resnet(x)
out=self.new(x)
return out
model=resnet_New()
# 冻结所有参数(只训练最后一层)
for param in model.resnet.parameters():#冻结原来的部分
print(param)
param.requires_grad = False#冻结权重修改权限
##只训练最后一层参数
params_to_update = []#保存需要训练的参数,仅仅包含全连接层的参数
for param in model.new.parameters():#只训练添加这层
# if param.requires_grad: # 这个不需要是因为我们新建的这层是没有参数的默认是True所以就不需要判断了
params_to_update.append(param) # 这种写法是收集所有需要训练的参数最后正确率能达到百分之90以上
之前的煤矿识别也可以用神经网络进行训练,可以得到很好的结果
四、CNN神经网络做回归
上面是我们利用神经网络进行分类,除此之外神经网络也能进行回归,回归问题预测一般都是连续值,一般我们进行分类对训练的模型评估标准是召回率,正确率,准确率这些,做回归的时候我们的评估标准是R²,在之前机器学习的时候我们也有提到过回归的评估标准。
R²(决定系数)衡量回归模型拟合数据的好坏。
R² = 1 - (SS_res / SS_tot) 其中:
- SS_res = 残差平方和(模型预测值与真实值的差异)
- SS_tot = 总平方和(真实值与均值的差异
取值范围:(-∞, 1]
- R² = 1:完美拟合(所有点都在预测线上)
- R² = 0:模型和简单取均值效果一样
- R² < 0:模型比简单取均值还差
1.人脸关键点的识别(回归)部分
人脸关键点就是让机器识别人脸各个部位,可以用于人脸识别,美颜,表情分析,疲劳监测等方面。就类似于让人认识脸的五官。当然关键点不止有五个,通常是68个关键点,这让机器能给人脸建立精准的坐标,把人脸量化。
这里我我们只对人脸五个关键点进行检测
import torch
from torch.utils.data import Dataset, DataLoader
from PIL import Image
from torchvision import transforms
import torch.nn as nn
import os此前我们使用CNN网络做食物的分类,对食物图片进行预处理,其中包括,图片裁剪,数据增强,归一化等。图片处理首先得有图片,所以也有个图片加载的功能。无论做回归还是分类,对图片的加载和处理都是少不了的流程。所以这里我们基本上是可以拿过来用。但有些细节和处理还是不一样。
我们要注意我对对图片的大小要求,这里大小影响后续我们对CNN的一些参数的设置。
'''数据预处理'''
data_transforms = {
'train':
transforms.Compose([ # 数据增强
transforms.Resize([70, 70]), # 先把图片缩放到7070,为了增强特征
transforms.RandomCrop(64), # 64,要求
transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转
transforms.RandomVerticalFlip(p=0.5),
transforms.ColorJitter(brightness=0.1, contrast=0.1), # 调整亮度#,saturation=0.1,hue=0.1
transforms.ToTensor(), # 转成张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
'test':
transforms.Compose([
transforms.Resize([64, 64]),
transforms.ToTensor(), # 转成张量
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}加载图片,从我们train文件中获取图片名字,和标签。
名字是为了后续加载图片,标签是为了和预测值进行对比。
将图片名字和imgdata进行路径拼接,就能得到图片的路径。根据图片路径模型就能加载图片进行训练。这里和食物分类不同的是食物分类是从训练集图片上获得图片特征然后归类,就像人学习某件东西的特征把这个东西和他的名字name联系起来,之后遇到这种特征的东西就归类为name中。
而这里机器要从图片上获得特征,在机器的‘脑子里’,人脸信息,比如说眼睛,嘴巴这些不是像人一样这样去称呼的,对于机器来说他们,这些名称对应的点只是一些数据,数值?矩阵?等,他们学习的是这个数据左边应该有什么数据,上面应该有什么数据……就像人们口中眼睛上面有眉毛,鼻子下面有嘴巴一样。所以他们从训练集图片学到的就是"这种像素排列模式",等我们有图片测试他就会利用它学到的‘规律’然后对这个新图片进行关键点识别。

imgdata文件夹下一共有150张图片(这里我们不以训练结果为目的,只是介绍方法,所以数据集很少,没有进行目的性的大量收集)其中前一百张实训练集,后五十张是测试集
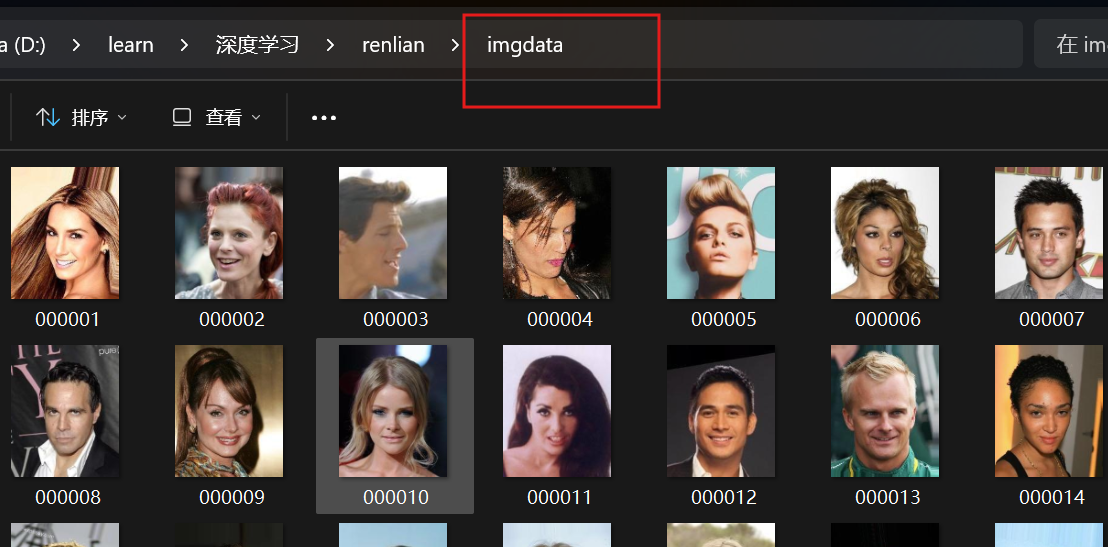
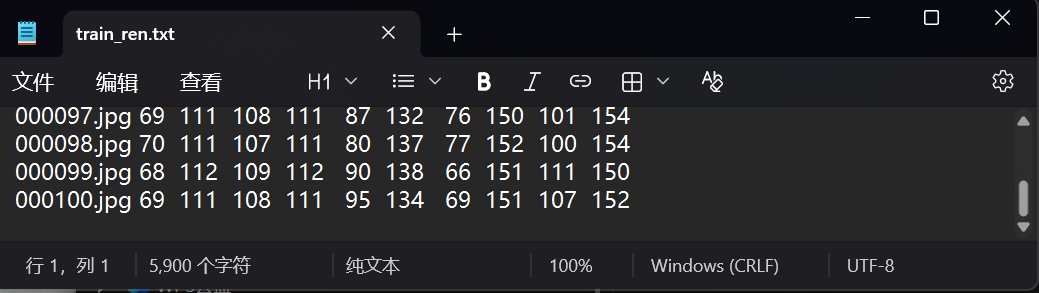
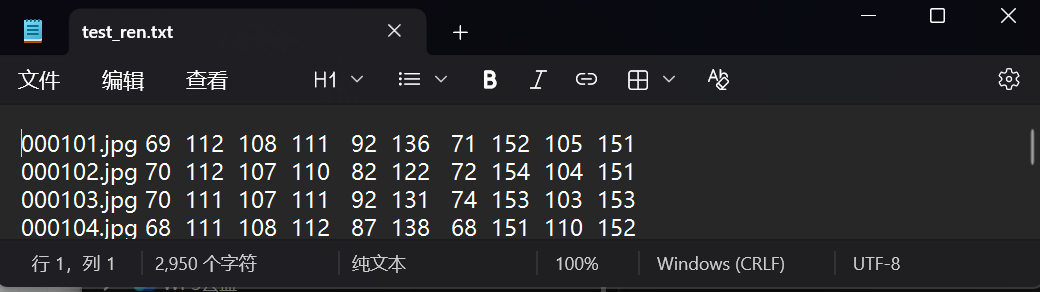
这里我们只对人脸五个关键点进行识别,在图片上一个点对应一个坐标x值和y值,所以这个文件里每张图片后面都有对应的十个值,也就是五个坐标,对应我们五个关键点的识别,把这些点的坐标和图片对应拿个机器训练。
class ren_dataset(Dataset):
def __init__(self, file_path, transform=None): # 从train.txt
self.file_path = file_path
self.imgs = []
self.labels = []
self.transform = transform
# 获取txt文件所在目录
txt_dir = os.path.dirname(os.path.abspath(file_path))
# 图片在 imgdata 文件夹下
img_dir = os.path.join(txt_dir, "imgdata")
with open(self.file_path) as f:
for line in f:
line = line.strip()
if not line:
continue
parts = line.split()
if len(parts) != 11:
continue
img_name = parts[0] #第一列是图片名称
#自动拼接完整路径:也就是在imgdata中找到对应图片
img_path = os.path.join(img_dir, img_name)
label_list = [float(x) for x in parts[1:]]#除第一列其他均是标签
self.imgs.append(img_path)
self.labels.append(label_list)
def __len__(self): #返回数据集大小
return len(self.imgs)
def __getitem__(self, idx): #读取图片,如果有transform就处理,返回图片和标签
image = Image.open(self.imgs[idx])
if self.transform:
image = self.transform(image)
label = torch.tensor(self.labels[idx], dtype=torch.float32)
return image, label上面是神经网络做回归人脸关键点识别的图片加载和图片处理,下篇博客将会继续后续训练的代码

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 23
23 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)