计算机视觉opencv之DNN模块实现风格迁移
DNN全程是Deep Neural Networks也就是深度神经网络,OpenCV的DNN模块是用来加载和运行深度学习模型的工具。
一、对图片进行风格迁移
'''图片风格迁移'''
import cv2
# 读取输入图像
image = cv2.imread('shengris.jpg')
# 显示输入图像
cv2.imshow('yuan', image)
cv2.waitKey(0)
'''.....图片预处理......'''
(h, w) = image.shape[:2] # 获取图像尺寸函数cv2.dnn.blobFromImage: 实现图像预处理,从原始图像构建一个符合人工神经网络输入格式的四维块。
blob = cv2.dnn.blobFromImage(image, scalefactor=None, size=None, mean=None, swapRB=None, crop=None)
参数:
- image: 表示输入图像。
- scalefactor: 表示对图像内的数据进行缩放的比例因子。具体运算是每个像素值*scalefactor,该值默认为1。
- size: 用于控制blob的宽度、高度。
- mean: 表示从每个通道读去的均值。(0, 0, 0):表示不进行均值减法。即,不对图像的B、G、R通道进行任何减法操作。 若输入图像本身是B、G、R通道顺序的,并且下一个参数swapRB值为True。 则mean值对应的通道顺序为R、G、B。
- openCV BGR RGB swapRB: 表示在必要时交换通道的R通道和B通道。一般情况下使用的是RGB通道。而OpenCV通常采用的是BGR通道。 因此可以根据需要交换第1个和第3个通道。该值默认为False。
- crop: 布尔值。如果为True,则在调整大小后进行再中裁剪。
返回值:
- blob: 表示在经过缩放、裁剪、减均值后得到的符合人工神经网络输入的数据。该数据是一个四维数据。
- 有通道常使用N(表示batch size)、C(图像通道数。如RGB图像具有三个通道)、H(图像高度)、W(图像宽度)表示
blob = cv2.dnn.blobFromImage(image, scalefactor=1, size=(w, h), mean=(0, 0, 0), swapRB=False, crop=False)加载模型
net=cv2.dnn.readNet(model[, config[, framework]])
各参数的含义如下:
- model: 神经网络的实际结构和功能,它定义了数据如何通过网络流动,如何进行训练,如何进行推理。
- config: 一组组参数和设置,帮助控制模型的行为,包括网络架构、训练过程、优化器等内容。
- framework: DNN框架,可省略。DNN模块会自动推断框架种类。
- net: 返回值,返回网络模型对象。
支持的模型格式有Torch, TensorFlow, Caffe, DarkNet, ONNX, Intel OpenVINO
这里使用的是一种模型,一些模型:model.zip
链接: https://pan.baidu.com/s/1tu73l_MUxEcTCMGaSHq-uQ?pwd=nyfg 提取码: nyfg
net = cv2.dnn.readNet(r'model\starry_night.t7') # 得到一个pytorch训练之后的星空模型
net.setInput(blob)out = net.forward()是执行神经网络的前向传播,输入数据经过网络各层计算,out是模型的原始输出,通常是多位数组,这里out是四维的B*C*H*W(B: batch图像数量(通常为1),C: channels通道数,H: height高度,W: width宽度)
out_new是对输出进行重塑调整输出的形式,忽略掉第1维,把4维转化为3维也就是把原来BCHW形式换为CHW形式。这里我们是对单张图片进行处理,批处理这个维度是不必要的为了后续方面所以这里我们转化为三维。
out = net.forward()
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])normalize对out_new进行归一化,把他的范围缩小在[0,1]内
结果转置一下数组(C,H,W)转置为(H,W,C),也就是(1,2,0),目的是将通道优先转为高度x宽度x通道的opencv图像格式
# 对输入的数据(或图像)进行归一化处理,使其数值范围在指定的范围内
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
# 转置输出结果的维度
result = out_new.transpose(1, 2, 0)
# 显示转换后的图像
cv2.imshow('Stylized Image', result)
cv2.waitKey(0)
cv2.destroyAllWindows()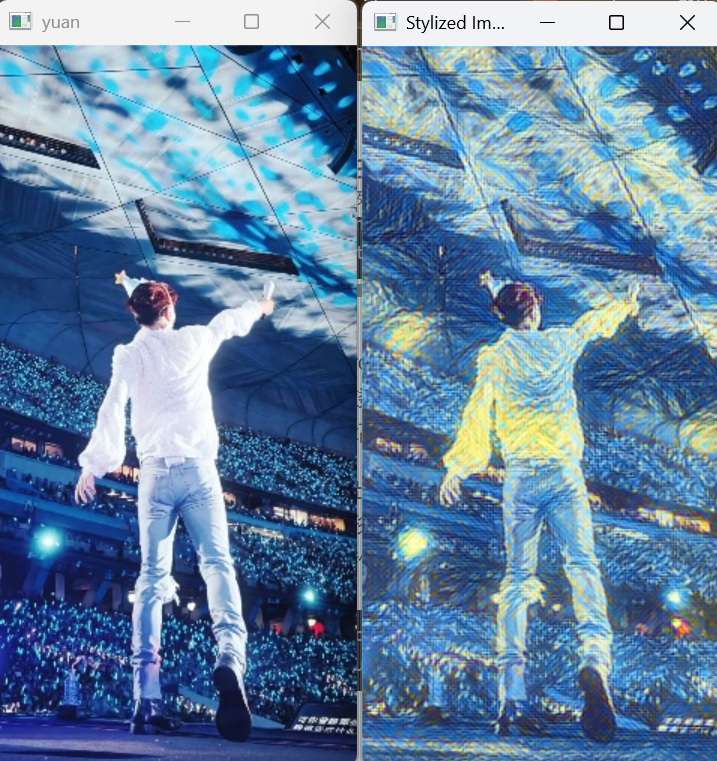
二、视频/摄像头进行风格迁移
和图片并没有什么不同,视屏永远都少不了while True死循环
这里我们对视屏进行缩小是为了让视屏播放更流畅,当然这里可以把视屏路径改为0,调用摄像头
'''视屏风格迁移'''
import cv2
cap = cv2.VideoCapture(r"D:\learn\计算机视觉\tupian\test.avi") # 0
net = cv2.dnn.readNetFromTorch(r'model\starry_night.t7')
if not cap.isOpened(): # 打开失败
print("摄像头启动失败")
exit()
while True:
ret, frame = cap.read() # 如果正确读取帧,ret为True
frame = cv2.resize(frame, dsize=None, fx=0.3, fy=0.3)
if not ret: # 读取失败,则退出循环
print("不能读取摄像头")
break
(h, w) = frame.shape[:2]
blob = cv2.dnn.blobFromImage(frame, scalefactor=1, size=(w, h), mean=(0, 0, 0), swapRB=True, crop=False)
net.setInput(blob)
out = net.forward()
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
result = out_new.transpose(1, 2, 0)
cv2.imshow('result', result)
key_pressed = cv2.waitKey(1) # 68
if key_pressed == 27: # 如果按Esc键,就退出循环
break
cap.release() # 释放捕获
cv2.destroyAllWindows() # 关闭图像窗口三、对视频/摄像头分区各区域的风格不同
在读取视屏前我们先创建一个列表把我们想要分区的几种风格导入
import cv2
import numpy as np
# 加载4种不同的风格模型
models = [
cv2.dnn.readNetFromTorch(r'model\starry_night.t7'), # 星空风格
cv2.dnn.readNetFromTorch(r"model\the_wave.t7"), # 波浪风格
cv2.dnn.readNetFromTorch(r'model\mosaic.t7'), # 马赛克风格
cv2.dnn.readNetFromTorch(r'model\candy.t7') # 糖果风格
]
cap = cv2.VideoCapture(r"D:\learn\计算机视觉\tupian\test.avi")
if not cap.isOpened(): # 打开失败
print("摄像头启动失败")
exit()下面代码全是while Ture内的,为了解释清楚,这里我分段。到这里都是没变的。
while True:
ret, frame = cap.read()
frame = cv2.resize(frame, dsize=None, fx=0.5, fy=0.5)
if not ret: # 读取失败,则退出循环
print("不能读取摄像头")
break
(h, w) = frame.shape[:2]这里我们是把原视频按照田字格分为四份,这个坐标后面会用到,后面会遍历
# 将帧分成田字格的四个区域
half_h, half_w = h // 2, w // 2
# 四个区域的坐标
regions = [
(0, 0, half_w, half_h), # 左上
(half_w, 0, w, half_h), # 右上
(0, half_h, half_w, h), # 左下
(half_w, half_h, w, h) # 右下
]其实这里也是没怎么改变的,result = np.zeros((h, w, 3), dtype=np.uint8)创建一个全黑的空白图像,大小与原图一样。
设置一个for循环,遍历每个区域,然后提取当前区域。
对当前区域进行风格迁移,就和之前没差。
然后就把处理好的当前区域放在对应位置,最后拼成完整的放在我们创建的那个全黑空白图上
# 创建空白的结果图像
result = np.zeros((h, w, 3), dtype=np.uint8)
for i, (x1, y1, x2, y2) in enumerate(regions):
# 提取当前区域
region = frame[y1:y2, x1:x2]
region_h, region_w = region.shape[:2]
# 对该区域进行风格迁移
blob = cv2.dnn.blobFromImage(region, scalefactor=1, size=(region_w, region_h),
mean=(0, 0, 0), swapRB=True, crop=False)
models[i].setInput(blob)#使用对应风格处理当前区域
out = models[i].forward()
# 处理输出
out_new = out.reshape(out.shape[1], out.shape[2], out.shape[3])
cv2.normalize(out_new, out_new, norm_type=cv2.NORM_MINMAX)
region_result = out_new.transpose(1, 2, 0)
# 将处理后的区域放回结果图像
result[y1:y2, x1:x2] = (region_result * 255).astype(np.uint8)
显示:
cv2.imshow('result', result)
key_pressed = cv2.waitKey(1)
if key_pressed == 27: # 如果按Esc键,就退出循环
breakwhile True循环整个代码块就结束了
最后不要忘记释放
cap.release()
cv2.destroyAllWindows()这里分区域不同风格,实际上是对原视频进行切割,单拿出来之后进行风格迁移然后在我们创立的那个和原视频一样大小的黑空白图像放置在对应位置。


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 37
37 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)