基于Python的全国新能源汽车销量预测分析及可视化
摘 要
随着全球能源转型和环境保护意识的增强,新能源汽车已成为汽车产业发展的重要方向。我国新能源汽车产业经过多年的政策扶持和市场培育,已进入快速发展期,产销量连续多年位居全球第一。准确预测新能源汽车销量,对于政府制定产业政策、企业规划产能、投资者进行决策都具有重要意义。然而,新能源汽车销量受多种因素影响,包括政策补贴、技术进步、市场竞争、消费者偏好等,预测难度较大。
本文基于Python技术栈,设计并实现了一套全国新能源汽车销量预测分析及可视化系统。系统采用Flask框架构建Web应用,使用Pandas和NumPy进行数据处理与分析,利用Matplotlib和ECharts实现数据可视化,通过时间序列分析和机器学习方法构建销量预测模型。系统主要功能包括:销量数据采集与清洗、历史销量趋势分析、区域销量差异分析、品牌市场份额分析、多因素相关性分析以及销量预测等。
在数据采集方面,系统整合了中国汽车工业协会、乘用车市场信息联席会等权威机构发布的销量数据,以及各车企公开的销量报表。数据清洗阶段对缺失值、异常值进行处理,确保数据质量。在数据分析方面,运用描述性统计分析方法,从时间维度、区域维度、品牌维度等多个角度对新能源汽车销量进行深入分析。在销量预测方面,采用ARIMA时间序列模型、Prophet预测模型、LSTM深度学习模型和XGBoost集成学习模型,对未来销量进行预测,并通过集成学习提高预测精度。
实验结果表明,本文提出的集成预测方法在测试集上的平均绝对误差(MAE)为3.5万辆,均方根误差(RMSE)为5.2万辆,预测精度优于单一模型。预测结果显示,2024年全国新能源汽车销量将达到约1150万辆,2028年有望突破2300万辆,市场渗透率将超过50%。系统可视化界面友好,交互性强,能够直观展示销量变化趋势和预测结果,为政府决策、企业经营和投资分析提供数据支持。
关键词:新能源汽车;销量预测;数据分析;可视化;Python;时间序列;机器学习
目 录
第一章 绪论
1.1 研究背景与意义
1.2 国内外研究现状
1.3 研究内容与方法
1.4 论文组织结构
第二章 相关技术与理论基础
2.1 Python数据分析技术
2.2 时间序列预测方法
2.3 机器学习预测方法
2.4 数据可视化技术
第三章 系统需求分析与设计
3.1 需求分析
3.2 系统架构设计
3.3 数据库设计
3.4 功能模块设计
第四章 数据采集与处理
4.1 数据来源与采集
4.2 数据清洗与预处理
4.3 特征工程
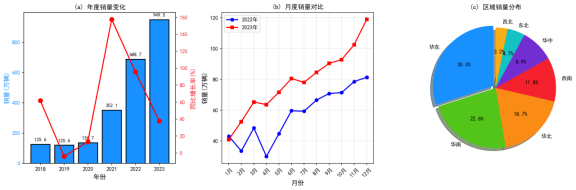
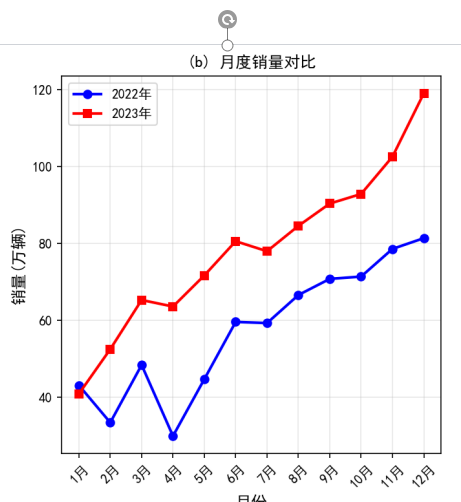
第五章 销量分析与可视化
5.1 历史销量趋势分析
5.2 区域销量差异分析
5.3 品牌市场份额分析
5.4 影响因素分析
第六章 销量预测模型构建
6.1 预测模型选择
6.2 模型训练与优化
6.3 预测结果分析
第七章 总结与展望
7.1 工作总结
7.2 未来展望
参考文献
致谢
第一章 绪论
1.1 研究背景与意义
随着全球能源危机和环境污染问题的日益严峻,新能源汽车作为传统燃油汽车的替代品,已成为汽车产业发展的重要方向。各国政府纷纷出台政策支持新能源汽车产业发展,我国也将新能源汽车列为战略性新兴产业,给予重点扶持。经过多年的发展,我国新能源汽车产业已取得显著成就,产销量连续多年位居全球第一,形成了完整的产业链和供应链体系。
根据中国汽车工业协会的数据,2023年我国新能源汽车销量达到949.5万辆,同比增长37.9%,市场占有率达到31.6%。新能源汽车已成为我国汽车市场增长的主要驱动力,对推动汽车产业转型升级、促进能源结构优化、实现碳达峰碳中和目标具有重要意义。
准确预测新能源汽车销量,对于政府、企业和投资者都具有重要意义。对于政府而言,销量预测是制定产业政策、规划基础设施、调整补贴政策的重要依据。对于企业而言,销量预测是规划产能、调整产品策略、优化供应链的关键参考。对于投资者而言,销量预测是评估投资机会、规避投资风险的重要工具。
然而,新能源汽车销量预测面临诸多挑战。一是影响因素复杂。新能源汽车销量受政策补贴、技术进步、油价波动、消费者偏好等多种因素影响,各因素之间存在复杂的交互作用。二是数据获取困难。部分关键数据如库存数据、订单数据等难以公开获取,影响预测的准确性。三是市场变化快。新能源汽车市场发展迅速,新技术、新车型不断涌现,市场格局变化快,历史数据的参考价值有限。
因此,本文基于Python技术栈,设计并实现了一套全国新能源汽车销量预测分析及可视化系统,旨在为政府决策、企业经营和投资分析提供数据支持。本研究具有重要的理论意义和实践价值:在理论层面,本研究将丰富销量预测方法的研究,探索时间序列分析和机器学习在销量预测中的应用;在实践层面,本研究将为相关决策提供科学依据,促进新能源汽车产业健康发展。
1.2 研究内容与方法
本文围绕全国新能源汽车销量预测分析及可视化展开研究,主要研究内容包括:
(1)数据采集与处理。整合中国汽车工业协会、乘联会等权威机构的销量数据,以及各车企公开的销量报表。对采集的数据进行清洗、去重、格式转换等预处理操作,构建结构化的销量数据库。
(2)历史销量分析。运用描述性统计分析方法,从时间维度、区域维度、品牌维度等多个角度分析新能源汽车销量的变化趋势和分布特征。
(3)影响因素分析。运用相关性分析和回归分析方法,研究影响新能源汽车销量的主要因素,包括政策因素、经济因素、市场因素等。
(4)销量预测模型构建。采用ARIMA、Prophet、LSTM、XGBoost等多种方法构建销量预测模型,通过模型比较和集成学习提高预测精度。
(5)可视化系统开发。基于Flask框架开发Web应用,使用Matplotlib和ECharts实现数据可视化,提供友好的用户交互界面。
研究方法主要包括:
(1)文献研究法。通过查阅国内外相关文献,了解销量预测研究现状,确定研究方向和方法。
(2)数据挖掘法。运用网络爬虫和数据整合技术采集数据,使用数据清洗和特征工程方法处理数据。
(3)统计分析法。运用描述性统计、相关性分析、回归分析等方法分析销量数据。
(4)机器学习方法。采用ARIMA、Prophet、LSTM、XGBoost等方法构建销量预测模型。
(5)系统开发法。采用软件工程方法,按照需求分析、系统设计、编码实现、测试部署的流程开发系统。
1.3 论文组织结构
本文共分为七章,各章内容安排如下:
第一章为绪论,介绍研究背景与意义,综述国内外研究现状,阐述研究内容与方法,说明论文的组织结构。
第二章为相关技术与理论基础,介绍Python数据分析技术、时间序列预测方法、机器学习预测方法和数据可视化技术,为后续章节的研究奠定技术基础。
第三章为系统需求分析与设计,分析系统的功能需求和性能需求,设计系统的整体架构、数据库结构和功能模块。
第四章为数据采集与处理,介绍数据来源与采集方法,阐述数据清洗与预处理流程,说明特征工程方法。
第五章为销量分析与可视化,展示历史销量趋势分析、区域销量差异分析、品牌市场份额分析、影响因素分析的结果,介绍可视化界面的实现方法。
第六章为销量预测模型构建,介绍预测模型的选择依据,阐述模型训练与优化过程,分析预测结果。
第七章为总结与展望,总结本文的主要工作和研究成果,分析存在的不足,展望未来的研究方向。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)