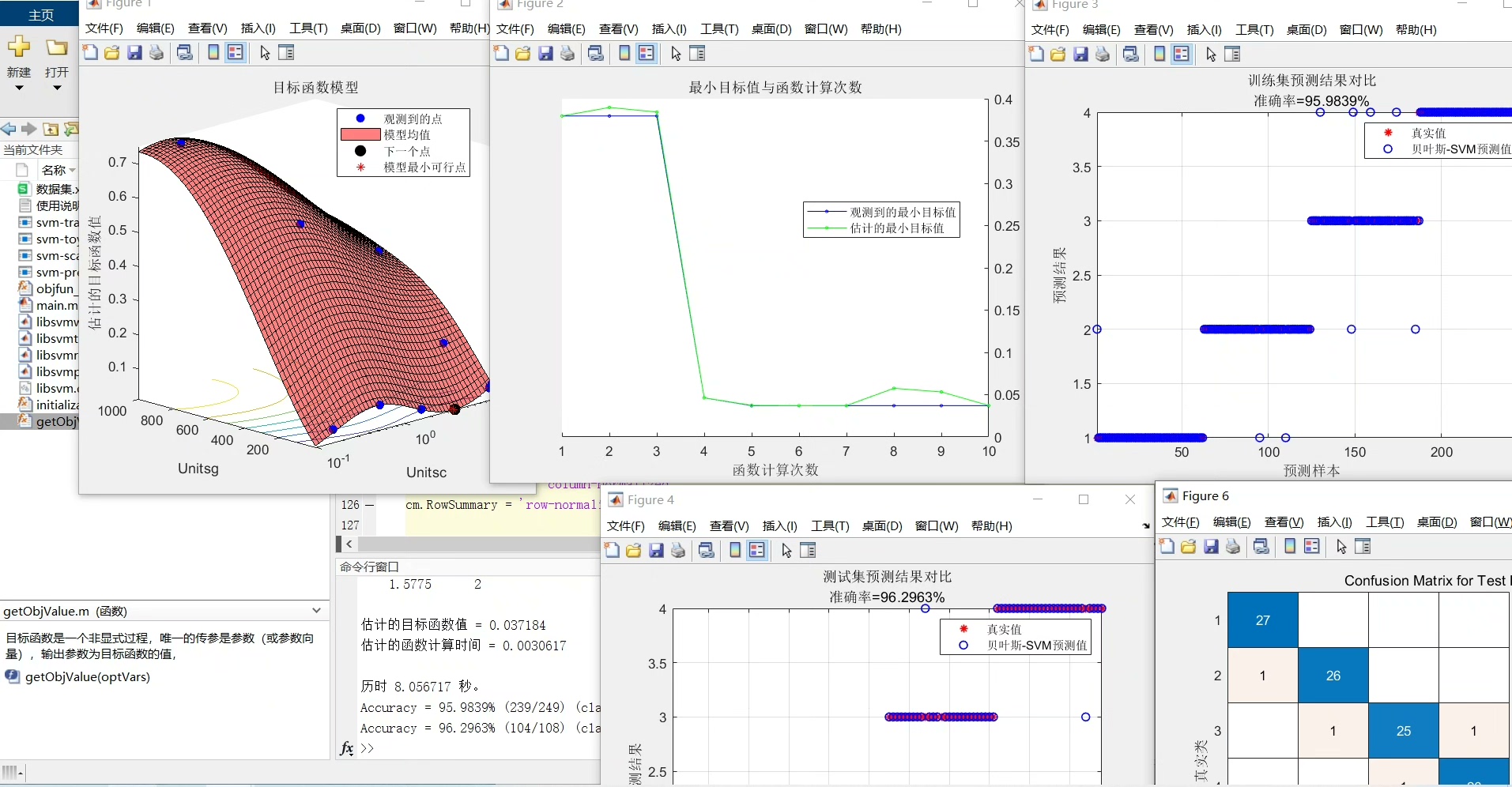
Bayes-SVM:多特征输入下的数据分类预测利器
bayes-SVM贝叶斯优化支持向量机的数据分类预测,bayes-SVM分类预测,多特征输入模型。 多特征输入单输出的二分类及多分类模型。 内注释详细替换数据就可以用,迭代优化图,混淆矩阵图。
在数据挖掘与机器学习的领域中,准确的分类预测一直是备受关注的重点。今天咱们来聊聊 Bayes-SVM,也就是贝叶斯优化支持向量机,看看它在多特征输入模型的二分类及多分类任务中是如何大展身手的。
多特征输入模型概述
传统的分类问题可能只依赖单一特征,但现实世界的数据往往包含多个维度的信息。多特征输入模型正是为了更好地利用这些丰富的数据,从而提升分类预测的准确性。比如在预测客户是否会购买某产品时,我们可以考虑客户的年龄、购买历史、浏览习惯等多个特征,以此构建一个更全面的预测模型。
Bayes-SVM 原理简述
支持向量机(SVM)本身就是一种强大的分类算法,它通过寻找一个最优超平面来分隔不同类别的数据点。而贝叶斯优化则是在这个基础上,通过贝叶斯方法来优化 SVM 的超参数,使得模型能够达到更好的性能。简单来说,贝叶斯优化可以帮助我们在众多超参数组合中,更快更准地找到那个能让 SVM 发挥最佳效果的组合。
代码实现与分析
下面咱们通过一段 Python 代码来看看 Bayes-SVM 在多特征输入单输出的二分类任务中的实现。
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
import matplotlib.pyplot as plt
from skopt import BayesSearchCV
from skopt.space import Real, Categorical, Integer
# 生成多特征的二分类数据
X, y = make_classification(n_samples=1000, n_features=10, n_classes=2, random_state=42)
# 将数据分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 定义SVM分类器
svm = SVC()
# 定义贝叶斯优化搜索空间
space = {
'C': Real(0.01, 1000, prior='log-uniform'),
'kernel': Categorical(['linear', 'rbf', 'poly']),
'degree': Integer(1, 5)
}
# 使用贝叶斯优化进行超参数调优
bayes_cv_tuner = BayesSearchCV(
estimator=svm,
search_spaces=space,
n_iter=50,
cv=5,
random_state=42,
n_jobs=-1
)
# 模型训练
bayes_cv_tuner.fit(X_train, y_train)
# 预测
y_pred = bayes_cv_tuner.predict(X_test)
# 计算混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=conf_matrix)
disp.plot()
plt.show()代码分析
- 数据生成与划分:
-makeclassification函数生成了具有 10 个特征的二分类数据,总共 1000 个样本。这里模拟了一个多特征输入的场景。
-traintest_split函数将数据按 70%训练集,30%测试集的比例进行划分,这样我们就有了训练模型和评估模型的数据。 - SVM 与搜索空间定义:
- 首先定义了一个基本的 SVM 分类器svm = SVC()。
- 然后构建贝叶斯优化的搜索空间space,这里我们对C(惩罚参数,控制对错分样本惩罚的程度)在0.01到1000之间进行对数均匀采样;kernel有linear(线性核)、rbf(径向基核)、poly(多项式核)三种选择;degree(多项式核的阶数)在 1 到 5 之间取值。 - 贝叶斯优化与模型训练:
-BayesSearchCV类将贝叶斯优化与交叉验证结合起来。niter设置了迭代次数为 50,意味着它会尝试 50 组不同的超参数组合。cv = 5表示进行 5 折交叉验证,这样可以更准确地评估模型性能。
-bayescvtuner.fit(Xtrain, y_train)开始训练模型,在训练过程中,贝叶斯优化会根据之前的评估结果,智能地选择下一组超参数进行尝试,不断迭代优化。 - 预测与混淆矩阵:
-ypred = bayescvtuner.predict(Xtest)使用训练好的模型对测试集进行预测。
-confusion_matrix计算真实标签和预测标签之间的混淆矩阵,它可以直观地展示模型在各个类别上的分类情况。ConfusionMatrixDisplay将混淆矩阵可视化展示出来,通过plt.show()就能看到混淆矩阵图啦。
迭代优化图
在贝叶斯优化的过程中,我们可以记录每次迭代的模型性能指标(比如准确率、F1 值等),然后绘制迭代优化图。虽然上面代码没有直接生成这个图,但实现思路很简单。假设我们用一个列表 performance_list 来记录每次迭代的性能值,迭代结束后可以这样绘制:
import matplotlib.pyplot as plt
# 假设 performance_list 已经记录了每次迭代的性能值
iteration = range(len(performance_list))
plt.plot(iteration, performance_list)
plt.xlabel('Iteration')
plt.ylabel('Performance Metric')
plt.title('Bayes-SVM Iterative Optimization')
plt.show()这个图能让我们清楚地看到随着迭代次数的增加,模型性能是如何逐步提升的,帮助我们了解贝叶斯优化的效果。
多分类模型扩展
多分类任务与二分类类似,只是类别数量更多。在代码上,只需要将生成数据的类别参数修改一下就可以,比如 makeclassification(nclasses = 5)。SVM 本身支持多分类,通过一些策略(如 one - vs - rest 或 one - vs - one)来处理多分类问题,贝叶斯优化同样可以为多分类的 SVM 找到最优超参数,整个流程思路基本一致。
bayes-SVM贝叶斯优化支持向量机的数据分类预测,bayes-SVM分类预测,多特征输入模型。 多特征输入单输出的二分类及多分类模型。 内注释详细替换数据就可以用,迭代优化图,混淆矩阵图。
总之,Bayes-SVM 在多特征输入的二分类及多分类模型中展现出强大的性能,通过合理的代码实现和超参数优化,能够帮助我们在数据分类预测任务中取得更出色的成果。希望大家可以动手实践,探索这个有趣的算法。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)