融合正余弦和柯西变异的麻雀搜索算法优化CNN - BiLSTM
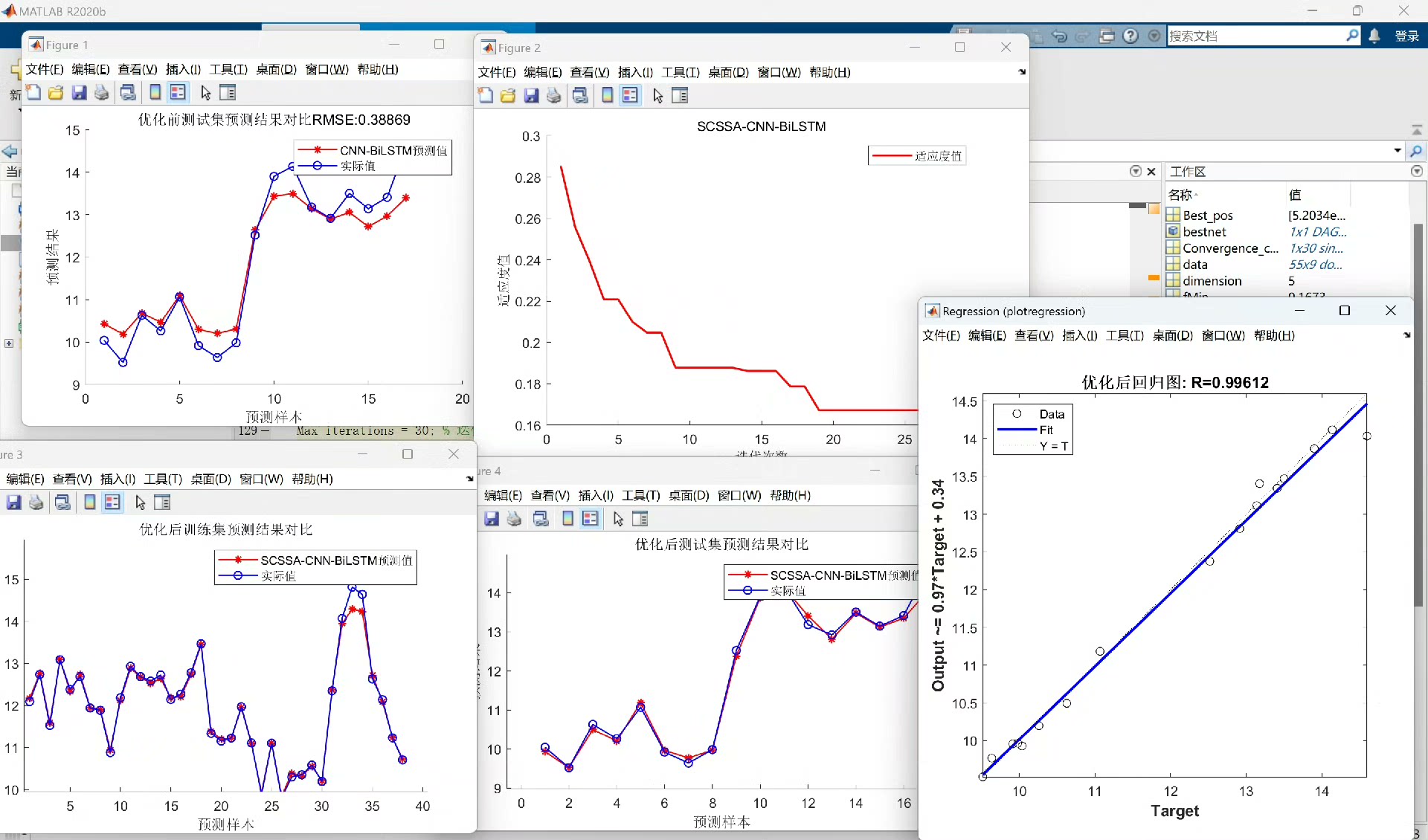
融合正余弦和柯西变异的麻雀搜索算法优化CNN-BiLSTM 仿真软件:matlab 主要内容:融合正余弦和柯西变异的麻雀搜索算法,对CNN-BiLSTM的学习率,正则化参数,BiLSTM隐含层神经元个数进行优化。 数据选用的是一段风速数据,数据较为简单,主要是方便大家后期的替换。 数据处理在代码中已经处理好,即用前n天的数据预测第n+1天的数据。
在机器学习和深度学习领域,模型的优化始终是提升性能的关键。今天咱就来唠唠融合正余弦和柯西变异的麻雀搜索算法,以及它如何对CNN - BiLSTM模型进行优化,这里我们使用Matlab作为仿真软件。
麻雀搜索算法融合
麻雀搜索算法(SSA)本身是一种群智能优化算法,模拟了麻雀觅食和反捕食行为。而融合正余弦和柯西变异则为其增添了新的活力。
正余弦策略能够让搜索过程在全局和局部之间更好地平衡。简单来说,在搜索前期,更倾向于全局搜索,扩大搜索范围寻找潜在的较优解;到了后期,则侧重于局部搜索,对已找到的较优区域进行精细挖掘。
柯西变异则是为了避免算法陷入局部最优。想象一下,算法在搜索过程中,有时候可能会被困在某个看似不错但并非全局最优的地方,柯西变异就像一个“唤醒剂”,让算法有机会跳出这个困境,继续探索更广阔的解空间。
融合正余弦和柯西变异的麻雀搜索算法优化CNN-BiLSTM 仿真软件:matlab 主要内容:融合正余弦和柯西变异的麻雀搜索算法,对CNN-BiLSTM的学习率,正则化参数,BiLSTM隐含层神经元个数进行优化。 数据选用的是一段风速数据,数据较为简单,主要是方便大家后期的替换。 数据处理在代码中已经处理好,即用前n天的数据预测第n+1天的数据。
下面来看看融合后的关键代码部分(伪代码示例):
% 初始化麻雀种群
pop = initialize_population(pop_size, dim);
for t = 1:max_iter
% 计算适应度
fitness = calculate_fitness(pop);
% 找出当前最优解
[best_fitness, best_index] = min(fitness);
best_solution = pop(best_index, :);
% 正余弦变异
for i = 1:pop_size
r1 = rand();
if r1 < 0.5
pop(i, :) = pop(i, :) + a * sin(r2) * abs(best_solution - pop(i, :));
else
pop(i, :) = pop(i, :) + a * cos(r2) * abs(best_solution - pop(i, :));
end
end
% 柯西变异
for i = 1:pop_size
r3 = rand();
if r3 < pm % pm为变异概率
pop(i, :) = pop(i, :) + cauchy_randn(1, dim);
end
end
end这段代码里,首先初始化了麻雀种群,然后在每次迭代中,先计算适应度并找出最优解。接着分别进行正余弦变异和柯西变异。正余弦变异部分根据随机数r1来决定是使用正弦还是余弦操作更新种群位置,a和r2是控制更新幅度和方向的参数。柯西变异则依据变异概率pm,对部分个体进行柯西分布的随机扰动。
CNN - BiLSTM模型优化
我们使用融合后的麻雀搜索算法来优化CNN - BiLSTM模型的几个关键参数:学习率、正则化参数以及BiLSTM隐含层神经元个数。
学习率决定了模型在每次更新时参数调整的步长。步长太大,可能会错过最优解;步长太小,又会导致收敛速度过慢。正则化参数用于防止模型过拟合,平衡模型的复杂度和对数据的拟合能力。BiLSTM隐含层神经元个数则影响着模型对序列特征的提取能力。
数据选用与处理
这里选用了一段风速数据,数据相对简单,方便大家后续替换自己的数据。在代码中数据处理已经完成,采用的是用前n天的数据预测第n + 1天的数据的方式。以下是数据处理部分的简化代码示例:
% 读取风速数据
wind_speed_data = readtable('wind_speed.csv');
data = table2array(wind_speed_data(:, 1));
% 划分训练集和测试集
n = length(data);
train_data = data(1:round(n*0.8));
test_data = data(round(n*0.8)+1:end);
% 构建输入输出数据
input_sequence_length = 7; % 前7天数据预测第8天
train_X = []; train_Y = [];
for i = 1:length(train_data)-input_sequence_length
train_X = cat(1, train_X, train_data(i:i+input_sequence_length-1));
train_Y = cat(1, train_Y, train_data(i+input_sequence_length));
end
test_X = []; test_Y = [];
for i = 1:length(test_data)-input_sequence_length
test_X = cat(1, test_X, test_data(i:i+input_sequence_length-1));
test_Y = cat(1, test_Y, test_data(i+input_sequence_length));
end这段代码首先读取风速数据文件,然后按80% - 20%的比例划分训练集和测试集。接着根据设定的输入序列长度(这里是7天)构建输入输出数据对,用于后续模型的训练和测试。
通过这种融合优化算法对CNN - BiLSTM模型参数的调整,有望在风速预测这类时间序列问题上取得更好的效果。而且由于数据的简单性,大家可以很方便地将自己的时间序列数据替换进来,尝试在不同领域进行应用。希望这篇博文能给大家在模型优化方面带来一些新的思路和启发。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)