Adadelta一个拒绝手动设置学习率的优化算法
为什么需要 Adadelta?
在深度学习的优化算法演化史中,每一个新方法的诞生都是为了修补前一个的伤口。Adadelta 出现于 2012 年,作者 Matthew Zeiler 发表在 arXiv 的一篇论文里,它的诞生动机非常明确——修复 Adagrad 的两个致命缺陷。
Adagrad 的核心思想是:对每个参数维护一个历史梯度平方的累积,用它来自适应地缩放学习率。频繁更新的参数获得更小的学习率,稀疏参数获得更大的学习率——这在 NLP 等稀疏场景中表现优秀。
Adagrad 的问题在于:梯度平方是单调累积的,学习率只减不增,训练到后期几乎停滞。
更深一层:Adagrad 仍然需要手动设置全局学习率 η,而这个超参数对训练结果极为敏感。Adadelta 的目标是同时解决这两个问题。
算法的两个核心思想
思想一:用指数衰减窗口替代全量累积
不积累所有历史梯度,而是用**指数移动平均(EMA)**来近似一个滑动窗口内的梯度均方值:
E[g2]t=ρ⋅E[g2]t−1+(1−ρ)⋅gt2E[g^2]_t = \rho \cdot E[g^2]_{t-1} + (1 - \rho) \cdot g_t^2E[g2]t=ρ⋅E[g2]t−1+(1−ρ)⋅gt2
RMS[g]t=E[g2]t+ε\text{RMS}[g]_t = \sqrt{E[g^2]_t + \varepsilon}RMS[g]t=E[g2]t+ε
衰减系数 ρ(通常取 0.95)决定了历史记忆的长度。当 ρ = 0.95 时,大约 20 步之前的梯度信息权重已衰减到不足 35%,有效抑制了历史梯度的过度积累。
下图展示了 Adagrad 与 Adadelta 对历史梯度权重分配的本质差异:
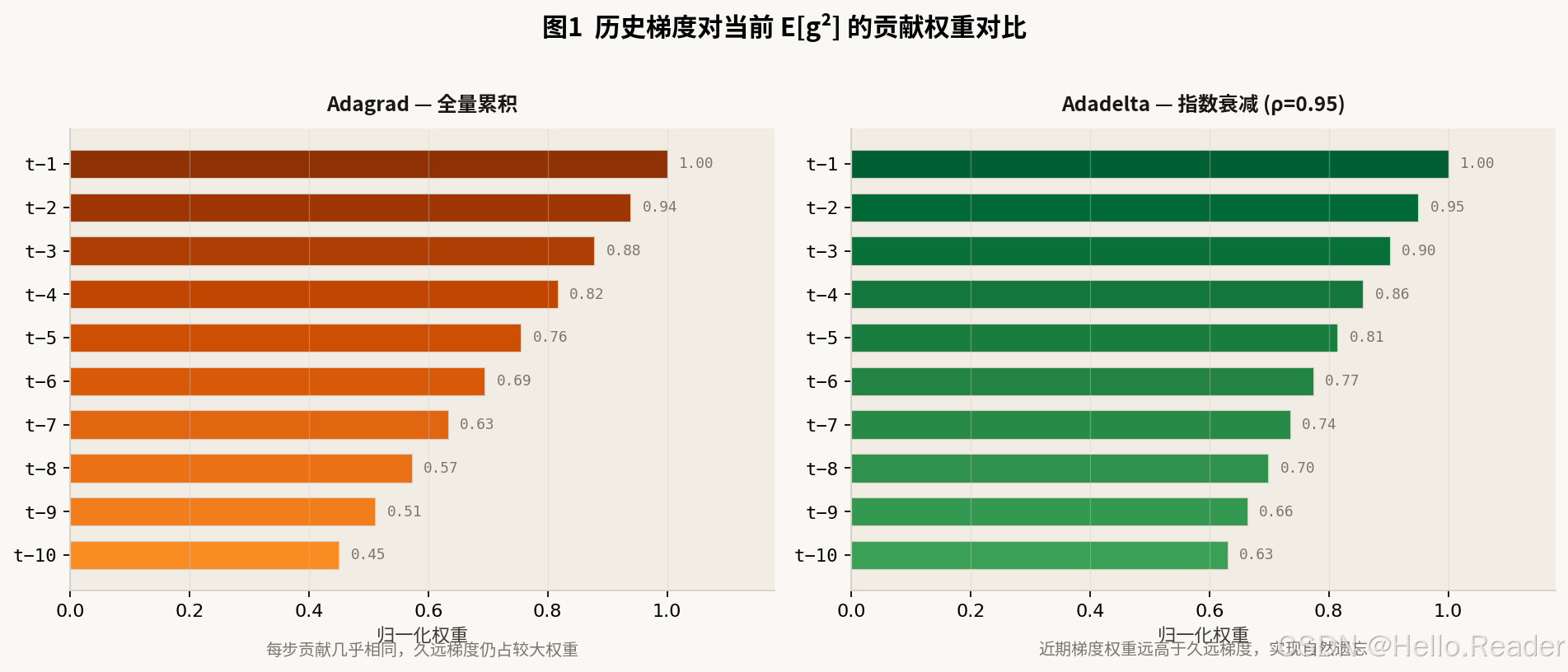
图1:每行代表过去第 t 步的梯度对当前 E[g²] 的贡献权重。Adagrad 所有历史步贡献接近均等;Adadelta 近期步权重远高于远古步,实现了自然的遗忘。
思想二:用参数更新量的 RMS 替代全局学习率
这是 Adadelta 最精妙的地方。Zeiler 做了一个单位分析(Units Analysis):
| 量 | 单位 |
|---|---|
参数 x |
[units] |
损失 L |
scalar |
梯度 g = ∂L/∂x |
1/[units] |
普通更新 η·g |
1/[units](与 x 不匹配!) |
Adadelta 更新 RMS[Δx]/RMS[g]·g |
[units](单位自洽 ✓) |
因此,用历史参数更新量的均方根来替代全局学习率:
Δxt=−RMS[Δx]t−1RMS[g]t⋅gt\Delta x_t = -\frac{\text{RMS}[\Delta x]_{t-1}}{\text{RMS}[g]_t} \cdot g_tΔxt=−RMS[g]tRMS[Δx]t−1⋅gt
E[Δx2]t=ρ⋅E[Δx2]t−1+(1−ρ)⋅Δxt2E[\Delta x^2]_t = \rho \cdot E[\Delta x^2]_{t-1} + (1-\rho) \cdot \Delta x_t^2E[Δx2]t=ρ⋅E[Δx2]t−1+(1−ρ)⋅Δxt2
这样,算法完全不需要手动指定学习率。
完整算法流程
每一次迭代,Adadelta 按以下五步执行:

图2:五个步骤的依赖关系一目了然。步骤③是核心,分子分母都是 RMS 形式,保证了单位自洽。
用 Python 伪代码表示如下:
# 初始化(一次性)
E_g2 = zeros_like(x) # 梯度均方的 EMA
E_dx2 = zeros_like(x) # 更新量均方的 EMA
eps = 1e-6
# 每步迭代
g = compute_gradient(x) # ① 计算梯度
E_g2 = rho * E_g2 + (1 - rho) * g**2 # ② 更新梯度 EMA
RMS_g = sqrt(E_g2 + eps) # ③ 计算梯度 RMS
delta_x = -sqrt(E_dx2 + eps) / RMS_g * g # ④ 计算更新量(无需学习率!)
E_dx2 = rho * E_dx2 + (1 - rho) * delta_x**2 # ⑤ 更新更新量 EMA
x = x + delta_x # ⑥ 应用
在椭圆形损失面上的收敛行为
一个经典测试场景是椭圆形碗形损失函数 L(x,y)=(x/3)2+y2L(x, y) = (x/3)^2 + y^2L(x,y)=(x/3)2+y2。这个函数在 x 轴方向"宽",在 y 轴方向"窄",代表参数曲率各向异性的真实情况:
- SGD 在宽方向步子过大,会沿 y 轴方向剧烈震荡;
- Adagrad 初期表现适当,但随着梯度平方累积,后期几乎停滞;
- Adadelta 自动适配各维度曲率,稳定收敛。
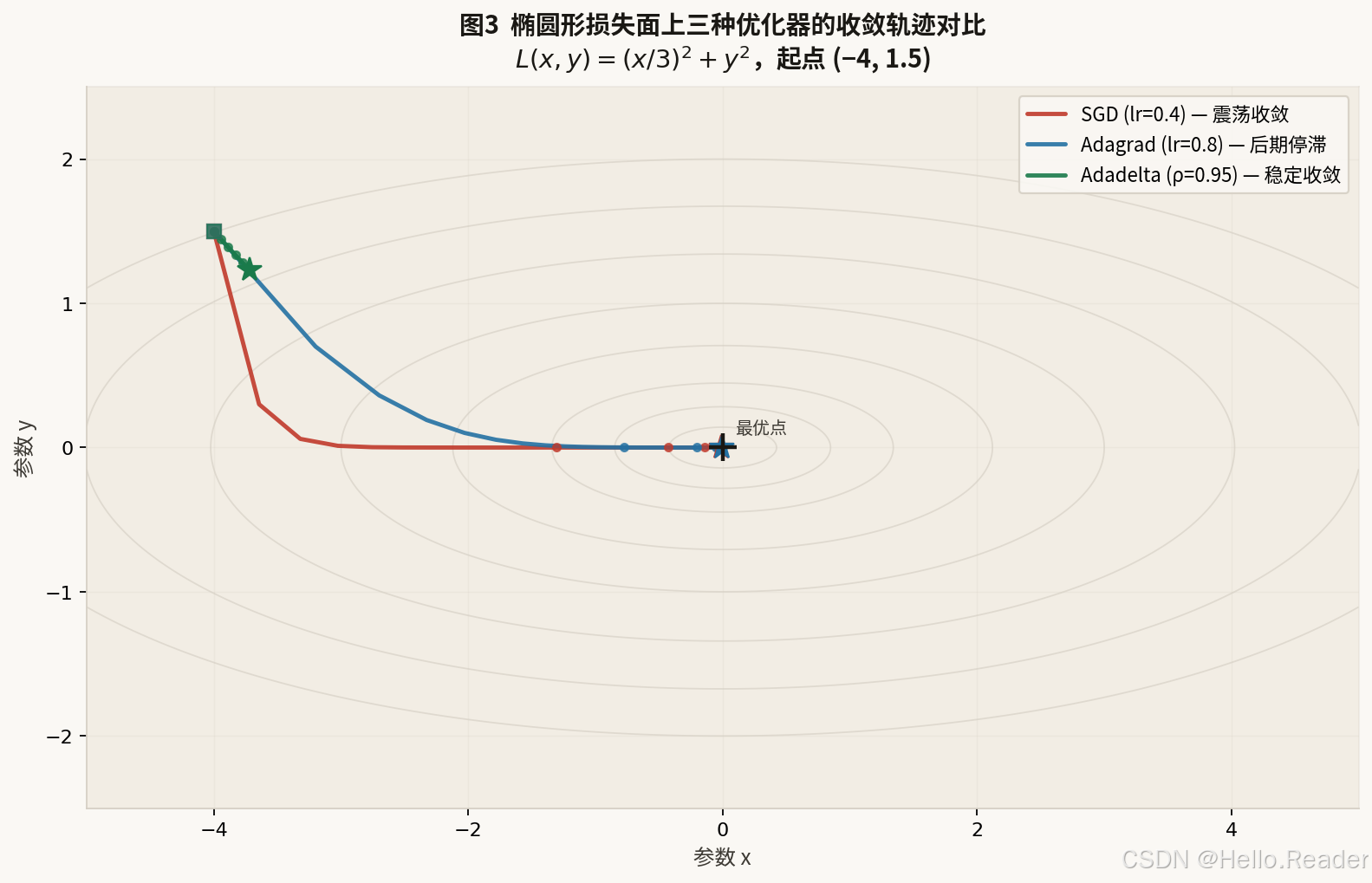
图3:起点均为 (−4, 1.5),★ 表示最终位置,■ 表示起点。红色 SGD 路径震荡明显;蓝色 Adagrad 中途近乎停止;绿色 Adadelta 沿较直路径稳步收敛至最优点。
超参数详解
Adadelta 只有两个超参数,且均不敏感,这是其最大优势之一:
| 超参数 | 典型值 | 作用 | 敏感度 |
|---|---|---|---|
ρ (rho) |
0.90 ~ 0.95 | 指数衰减系数,控制历史梯度的记忆长度。越大窗口越长,越平滑。 | 低 |
ε (epsilon) |
1e-6 ~ 1e-8 | 防止分母为零的数值稳定项。对结果影响极小。 | 极低 |
| 学习率 | — | 无需设置,这正是 Adadelta 的核心创新。 | 不存在 |
ρ 的物理含义:在 ρ = 0.95 时,有效历史窗口长度约为 1/(1−ρ)=201/(1-\rho) = 201/(1−ρ)=20 步。100 步之前的梯度权重约为 0.95100≈0.0060.95^{100} \approx 0.0060.95100≈0.006,近乎被遗忘。
下图展示了不同 ρ 值对有效窗口和权重衰减速度的影响:
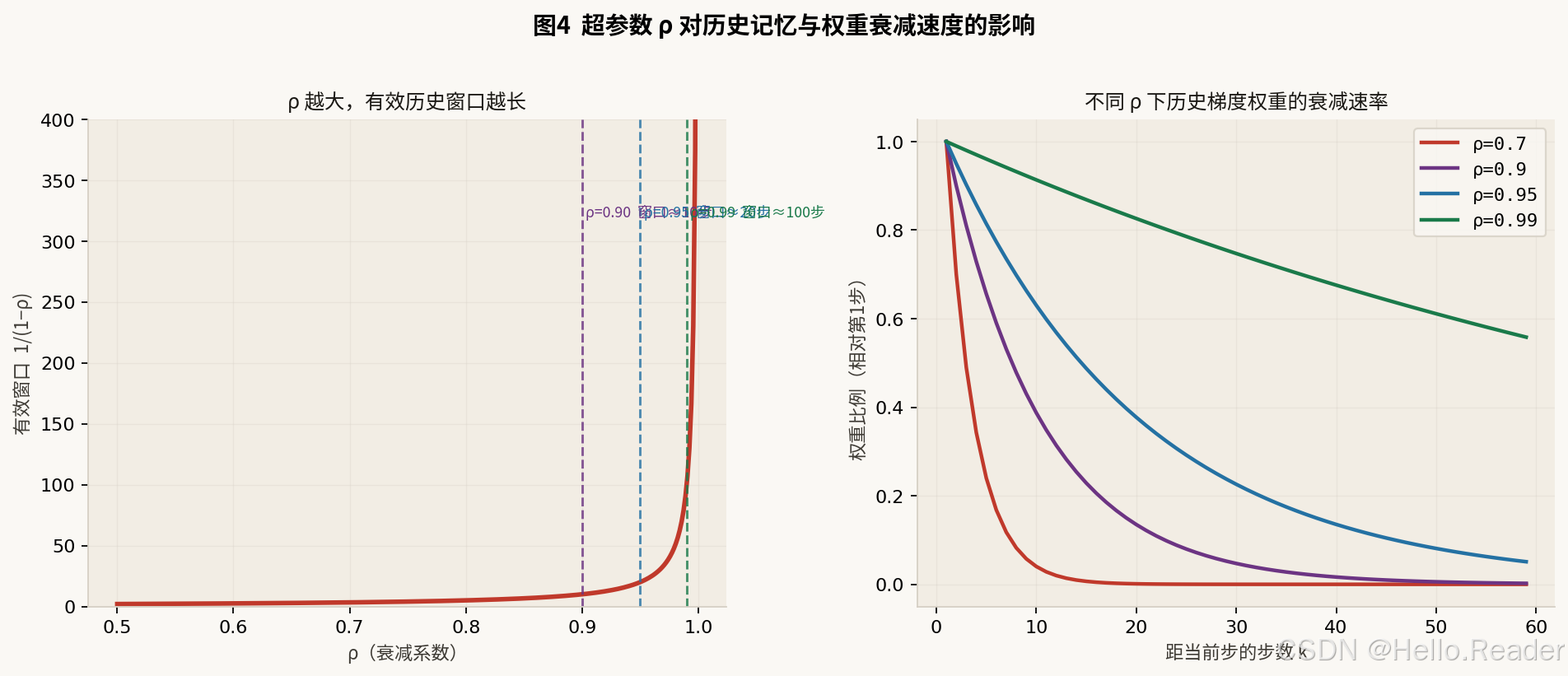
图4(左)ρ 越大,有效窗口 1/(1−ρ) 越长,算法"记忆"越长;(右)不同 ρ 下历史梯度权重的衰减速率对比。
与其他优化器的横向比较
| 算法 | 需要学习率 | 历史梯度 | 适用场景 | 主要缺陷 |
|---|---|---|---|---|
| SGD | ✗ 必须设置 | 无 | 通用,配合 momentum | 调参困难,各向异性差 |
| Adagrad | ✗ 必须设置 | 全量累积 | 稀疏特征(NLP) | 学习率单调递减 |
| RMSProp | ✗ 必须设置 | 指数衰减 | RNN / 非平稳 | 仍需手设学习率 |
| Adadelta | ✓ 无需设置 | 指数衰减 | 通用,免调参 | 后期收敛精度弱于 Adam |
| Adam | ✗ 必须设置 | 一阶 + 二阶矩 | 当前最广泛使用 | 泛化有时弱于 SGD+momentum |
算法演化脉络:Adagrad → Adadelta → RMSProp → Adam,每一步都是对前者缺陷的精确回应。
在 PyTorch 中使用
PyTorch 内置了 Adadelta,接口极为简洁:
import torch.optim as optim
optimizer = optim.Adadelta(
model.parameters(),
rho=0.9, # 衰减系数,默认 0.9
eps=1e-6, # 数值稳定项,默认 1e-6
weight_decay=0 # L2 正则项(可选)
)
# 训练循环与普通优化器完全一致
for batch in dataloader:
optimizer.zero_grad()
loss = criterion(model(batch[0]), batch[1])
loss.backward()
optimizer.step()
实用建议:在需要快速验证一个新架构时,Adadelta 是非常好的选择——你不需要花时间调学习率,可以把精力放在模型设计上。当模型验证可行后,再切换到 Adam 或 AdamW 做精调往往能获得更好的最终精度。
总结
Adadelta 是深度学习优化算法演进链条中的一个重要节点,它提出了两个至今仍影响深远的思想:
- 指数衰减均方替代全量累积——被 RMSProp 和 Adam 继承,成为现代自适应优化器的标配;
- 单位自洽的无学习率更新——一个极为优雅的理论贡献,从根本上消除了对全局学习率的依赖。
虽然在今天的工程实践中,Adam 已经取代了 Adadelta 的位置,但理解 Adadelta 对于深刻掌握自适应学习率的本质非常有价值。理解它,就理解了 Adam 为何有效的一半。
算法的演化是一部解题史:每个优化器都是对上一个缺陷的精确回应。
参考资料
- Zeiler, M. D. (2012). ADADELTA: An Adaptive Learning Rate Method. arXiv:1212.5701
- Duchi, J., Hazan, E., & Singer, Y. (2011). Adaptive Subgradient Methods for Online Learning and Stochastic Optimization. JMLR.
- Ruder, S. (2016). An overview of gradient descent optimization algorithms. arXiv:1609.04747
深度学习优化算法系列 · 标签:Adadelta 梯度下降 自适应学习率 PyTorch

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 24
24 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)