GPT-5.4面向专业工作推出的能力最强、效率最高的前沿模型之一
GPT-5.4(2026 年 3 月 5 日发布) 是 OpenAI 推出的新一代通用人工智能模型。官方将其定位为:目前面向专业工作推出的能力最强、效率最高的前沿模型之一。
从能力定位来看,GPT-5.4 并不只是“回答问题更聪明”这么简单,而是进一步向 复杂任务处理、长文本理解、专业知识协作、多步骤推理与实际工作流集成 方向迈进。
对于企业用户、内容创作者、开发者、研究人员以及需要处理大量信息的专业岗位来说,GPT-5.4 的意义不仅在于“更强”,更在于它在 稳定性、上下文处理能力、跨场景应用能力 上的提升。
本文将从以下几个方面,带你全面了解 GPT-5.4:
-
GPT-5.4 的核心特性有哪些
-
100 万 Token 超长上下文窗口
到底是什么概念
-
这种超长上下文能力意味着什么
-
GPT-5.4 适合哪些场景
-
普通用户和专业用户应该如何理解它的价值
一、GPT-5.4 的定位:不仅是聊天模型,而是专业级 AI 工作引擎
过去很多人理解 AI 模型,往往停留在“写文案、改写句子、回答问题”的层面。
但 GPT-5.4 的定位已经明显不同,它更接近一种 通用型智能工作引擎。
简单来说,它具备以下几个方向上的特征:
-
更强的综合理解能力
不只是理解一句话,而是理解一整套复杂材料、上下文关系、任务目标和隐含要求。 -
更适合专业工作
包括研究分析、文档处理、知识整合、代码协作、流程生成、报告撰写等高强度任务。 -
更长的上下文记忆能力
一次可以处理极长内容,不必频繁“重新喂资料”。 -
更高的任务连续性
能够在一个较长工作链路中保持前后逻辑一致,不容易中途“失忆”。 -
更适合嵌入真实业务流程
比如客服系统、知识库问答、合同审阅、内部文档助手、编程 Copilot、数据分析助手等。
换句话说,GPT-5.4 已经不再只是一个“会聊天的 AI”,而是在向 生产力工具平台的核心模型 演化。
二、GPT-5.4 的核心特性有哪些?
1. 更强的复杂任务处理能力
GPT-5.4 的一大价值,在于它更擅长处理 复杂、链条长、包含多个条件的任务。
例如:
-
根据一份需求文档生成产品方案
-
阅读几十页资料后提炼要点并给出结论
-
结合历史上下文,持续优化同一篇内容
-
根据项目规范自动生成代码、注释和测试说明
-
从多个来源提取信息并形成结构化报告
传统 AI 在面对复杂任务时,常见问题是:
-
忽略条件
-
丢失上下文
-
输出前后不一致
-
长文中后段出现逻辑漂移
而 GPT-5.4 的改进方向,就是让模型在 长链路任务、专业语境、多约束条件 下仍然保持较好的稳定性。
2. 更强的长文本理解与整合能力
对于专业工作来说,真正困难的往往不是“生成一句话”,而是 理解几十页、几百页材料后再输出。
GPT-5.4 更适合做这类工作,比如:
-
阅读完整项目文档并总结重点
-
整理会议记录,形成可执行清单
-
对比多个合同版本差异
-
归纳论文、白皮书、政策文件内容
-
从超长知识库中提取关键信息
它的价值不只在“能读完”,更在于 能在读完之后保持结构化理解。
3. 更适合专业知识协作
GPT-5.4 面向“专业工作”的定位,意味着它不仅要会表达,更要能参与协作。
例如在以下工作中,它更容易发挥作用:
-
法务:辅助整理条款、梳理风险点
-
医疗信息管理:归纳文档、整理知识材料
-
金融研究:分析报告、行业比较、摘要提取
-
教育:生成课程提纲、知识点讲解、练习设计
-
技术开发:代码解释、架构说明、调试辅助、接口文档生成
当然,这并不意味着 AI 可以替代专业判断。
更准确地说,GPT-5.4 更像是一个 高效的智能副驾驶,帮助专业人士提升信息处理效率、减少重复劳动、加快输出速度。
4. 更高的一致性与连续性
很多用户在使用早期模型时会发现一个问题:
同一轮对话聊到后面,模型容易忘记前面说过的话,或者风格变了、要求漏了。
GPT-5.4 的提升之一,就是在处理长任务时尽可能维持:
-
风格一致
-
逻辑一致
-
指令执行一致
-
角色设定一致
-
内容结构一致
这对于以下场景尤其重要:
-
长篇文章写作
-
项目文档连续迭代
-
多轮代码协作
-
品牌统一文案输出
-
多步骤方案设计
5. 更高效率,适合真实生产环境
一个模型是否“先进”,不能只看它会不会回答问题,还要看它是否适合接入真实业务环境。
GPT-5.4 如果被定位为“效率最高的前沿模型之一”,通常意味着它在以下方面更适合生产环境:
-
响应更稳定
-
在复杂任务中减少重复沟通
-
更少偏离要求
-
更适合与工具、系统、API 结合
-
能在高信息密度任务中节省人工时间
这对企业来说很重要,因为真正的商业价值来自:
减少沟通成本、减少重复劳动、缩短交付周期。
三、100 万 Token 超长上下文窗口是什么概念?
这是 GPT-5.4 最引人关注的能力之一。
1. 什么是上下文窗口?
所谓“上下文窗口”,你可以理解为:
模型在一次处理过程中,能够同时“看到”和“记住”的内容范围。
这些内容包括:
-
用户当前输入的文字
-
前面对话内容
-
上传的资料
-
系统提示词
-
历史任务要求
-
文档、代码、表格、说明材料等
上下文窗口越大,模型就越能在一个连续任务中掌握更多信息,而不是只看到局部片段。
2. Token 不是“字数”,但可以近似理解为文本单位
Token 不是严格等于“一个字”或“一个单词”,它是模型处理文本时使用的基本单位。
中文、英文、标点、数字、代码片段,都会被拆成不同数量的 Token。
虽然不能完全等同,但为了方便理解,可以粗略认为:
-
100 万 Token
大致已经是一个极其夸张的文本容量
-
可以装下 大量长篇文档、整本书级别内容、多个项目资料合集
-
对代码、日志、规范、聊天记录、知识库文本等尤其有意义
简单理解:
如果以前的模型像是在桌上摊开几页材料工作,
那么 100 万 Token 更像是可以一次性把 整叠文件、项目归档资料、会议纪要、历史邮件、产品文档、技术规范 全部摆在面前。
3. 100 万 Token 到底有多大?
虽然具体换算会因语言类型和内容结构不同而变化,但可以用几个直观比喻理解:
-
可能相当于 数十万字到上百万字量级 的信息
-
相当于 多本长篇书籍
-
相当于 一个大型项目的完整文档集合
-
相当于 超长代码仓库说明 + 相关文档 + 历史变更记录
-
相当于 大量客服对话、知识库条目、培训资料一次性输入
换句话说,这种容量已经不是“看一篇文章”,而是接近 看一个资料库。
四、100 万 Token 超长上下文窗口意味着什么?
1. 不用频繁切片喂给模型
过去在处理长材料时,常常需要把文档拆成很多段:
-
先发第一章
-
再发第二章
-
再让模型总结
-
再人工拼接总结
-
再继续追问
这种方式效率低,而且容易出现:
-
前后断裂
-
总结重复
-
关键信息遗漏
-
模型忘记前文细节
有了 100 万 Token 的超长上下文窗口后,很多任务可以 一次输入完整资料,让模型在全局范围内理解和分析。
2. 可以做真正意义上的“全局理解”
长文本处理最难的,不是识别每一句话,而是建立 跨章节、跨文档、跨时间线 的联系。
例如:
-
合同 A 与合同 B 哪些条款冲突
-
需求文档与实际实现逻辑是否一致
-
多次会议纪要中哪些决策发生了变化
-
不同版本方案的演进路径是什么
-
整个项目资料中最关键的风险点在哪里
超长上下文意味着模型有机会站在“全局”看问题,而不是只盯着某一页内容。
3. 更适合处理真实工作流中的复杂资料
现实中的业务材料通常不是一篇短文,而是:
-
邮件往来
-
表格说明
-
需求文档
-
项目规范
-
历史记录
-
会议纪要
-
附件摘录
-
FAQ 和知识库条目
100 万 Token 的价值就在于:
它更接近现实办公环境中的“资料总量”,让 AI 真正能介入完整工作流,而不是只做局部问答。
4. 多轮协作更顺畅
上下文越长,多轮对话的连续性通常越好。
这意味着你可以在同一个任务中持续推进,例如:
-
先让它阅读资料
-
再让它总结
-
再生成提纲
-
再细化章节
-
再改写风格
-
再根据补充意见修订
-
最后导出正式版本
在这个过程中,模型不需要不断“重置”,协作体验会更像在与一个真正记得上下文的助手工作。
五、GPT-5.4 适用于什么场景?
1. 长文档分析与总结
适用于:
-
法律合同
-
政策文件
-
企业制度
-
投研报告
-
技术白皮书
-
学术论文
-
培训手册
典型用途:
-
自动摘要
-
提炼核心观点
-
标注关键条款
-
比较文档差异
-
生成简版说明
-
输出汇报材料
2. 企业知识库与内部助手
对于企业来说,很多知识分散在不同系统中:
-
SOP 文档
-
产品资料
-
售后手册
-
培训内容
-
FAQ
-
历史案例
-
运营规范
GPT-5.4 适合作为企业内部智能助手的核心模型,用来实现:
-
知识库问答
-
业务流程解释
-
新员工培训辅助
-
客服支持
-
内部资料检索与总结
它的长上下文能力,特别适合把 大量内部知识一次性纳入处理范围。
3. 软件开发与代码协作
在开发场景中,超长上下文能力非常实用,因为开发工作不只是写一个函数,而是要理解:
-
项目结构
-
接口定义
-
依赖关系
-
历史逻辑
-
配置文件
-
报错日志
-
测试要求
-
部署说明
GPT-5.4 可用于:
-
阅读整个项目文档后给出实现建议
-
分析代码问题
-
生成接口文档
-
编写测试用例
-
解释遗留代码
-
辅助重构
-
根据需求文档生成模块代码
对大型项目来说,这种“能看全局”的能力比单纯会写代码更重要。
4. 内容创作与编辑生产
内容行业同样非常受益于长上下文:
-
长篇专栏写作
-
课程脚本设计
-
图书大纲扩写
-
系列文章风格统一
-
品牌内容规范保持一致
-
多篇资料整合成专题文章
比如,一个编辑团队可以把:
-
品牌手册
-
往期内容
-
风格要求
-
竞品分析
-
采访资料
-
结构提纲
一起交给模型,再让它生成符合要求的长内容。
这样得到的结果通常会更统一,也更符合真实业务需求。
5. 教育与培训场景
在教育领域,GPT-5.4 可用于:
-
课程内容整合
-
教案设计
-
试题讲解
-
知识点拆解
-
学习资料摘要
-
多学科内容串联
-
长篇教材辅助理解
如果要处理整本教材、整套讲义、完整考试大纲,这种超长上下文能力会非常实用。
6. 客服、咨询与复杂问答系统
很多客服问题其实不是简单 FAQ,而是涉及:
-
用户历史记录
-
产品说明
-
规则条款
-
退款政策
-
订单状态
-
多轮沟通内容
GPT-5.4 适合做更高级的客服与咨询支持,尤其适用于:
-
高复杂度售前咨询
-
技术支持
-
知识型客服
-
工单总结
-
客诉归因分析
它可以在更长的对话链中保持理解连续性,减少反复追问。
六、普通用户如何理解 GPT-5.4 的价值?
对于普通用户来说,不必被“100 万 Token”“前沿模型”这些术语吓到。
你可以简单理解为:
它更像一个:
-
读得更多的助手
-
记得更久的助手
-
更懂复杂任务的助手
-
更适合做正式工作的助手
以前你可能只能让 AI 帮你写一段文案;
现在你更可能让它:
-
看完整份资料后帮你总结
-
根据一堆需求生成方案
-
连续帮你修改一篇长文
-
在多轮讨论后保持同一思路
-
协助处理更接近真实工作的任务
这就是 GPT-5.4 对普通用户最直接的意义:
AI 不再只是“偶尔帮点小忙”,而是更接近长期协作工具。
七、GPT-5.4 的意义不只是“更大”,而是更接近真实生产力
从行业角度看,GPT-5.4 的价值并不只是参数更先进、上下文更长,而是它反映出一个趋势:
AI 正在从“单次生成工具”,走向“可持续协作的生产力系统”。
过去大家用 AI 更多是零散使用:
-
写个标题
-
改个段落
-
回答个问题
-
生成个小脚本
而现在,随着超长上下文和专业任务能力提升,AI 更有可能进入核心工作链条,比如:
-
项目分析
-
文档管理
-
决策辅助
-
流程自动化
-
软件研发协作
-
企业知识管理
这意味着 GPT-5.4 的真正价值,不只是“会说得更像人”,而是 更能参与复杂工作本身。
八、结语
GPT-5.4 作为 OpenAI 于 2026 年 3 月 5 日推出的新一代通用人工智能模型,其重要意义体现在三个关键词上:
-
更强
-
更长
-
更专业
其中,100 万 Token 超长上下文窗口 是一个非常关键的能力升级。
它让模型不再局限于短文本对话,而是可以面对 整套资料、完整项目、多轮任务链 进行处理和协作。
对于个人用户来说,它意味着 AI 更好用、更省事;
对于企业和专业团队来说,它意味着 AI 有机会真正进入实际业务流程,成为高效的智能助手。
可以预见,未来衡量一个 AI 模型是否先进,已经不只是看它会不会生成内容,而是看它是否能够:
-
理解复杂问题
-
处理海量上下文
-
在长任务中保持稳定
-
真正服务于专业工作
而 GPT-5.4,正是在这个方向上迈出的重要一步。
大家最关心的还是如何能使用该模型,数字先锋API已经聚合了全球顶尖大模型,让开发者实现 Token 自由,包括 OpenAI、Claude、Gemini、DeepSeek、Grok、Qwen 等主流模型,覆盖文本、图像、语音、视频等多场景能力,为开发者提供更快、更稳、更省的 API 服务。如何使用GPT-5.4模型?
注册-用户-新建令牌-开箱即用
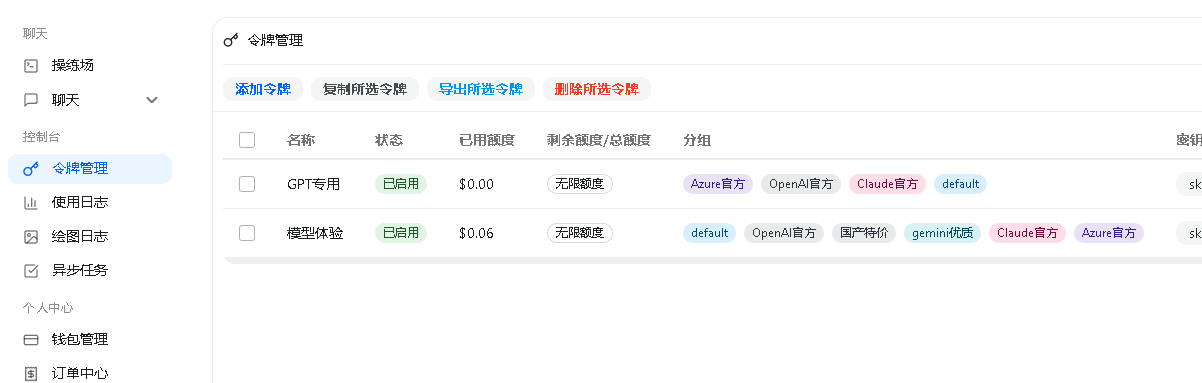
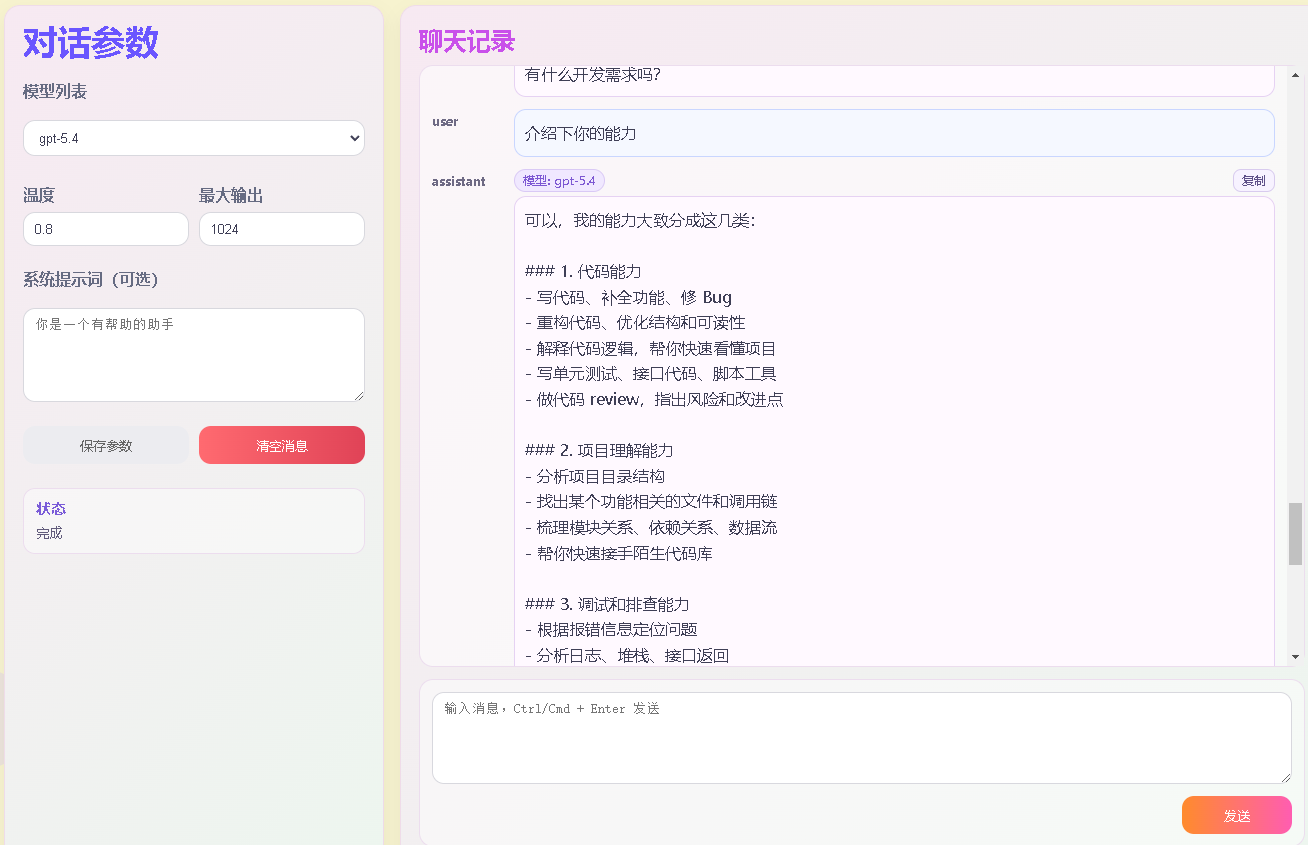
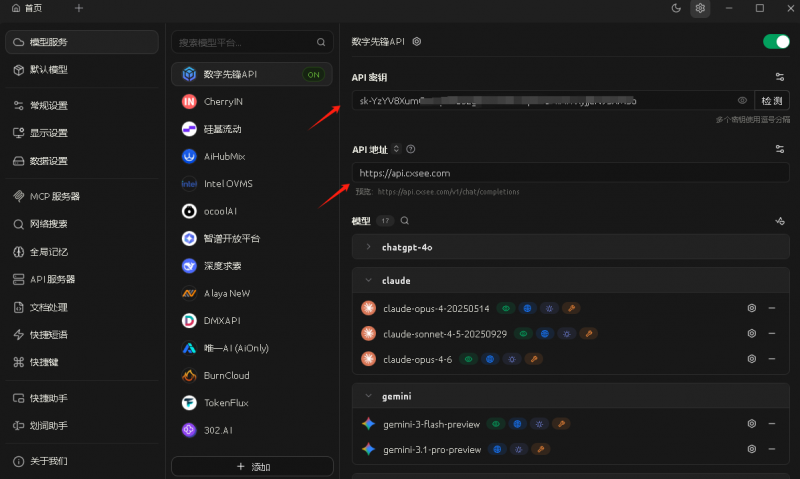
对接工具使用,客户端工具Cherry Studio使用示例:Base URL+Api Key
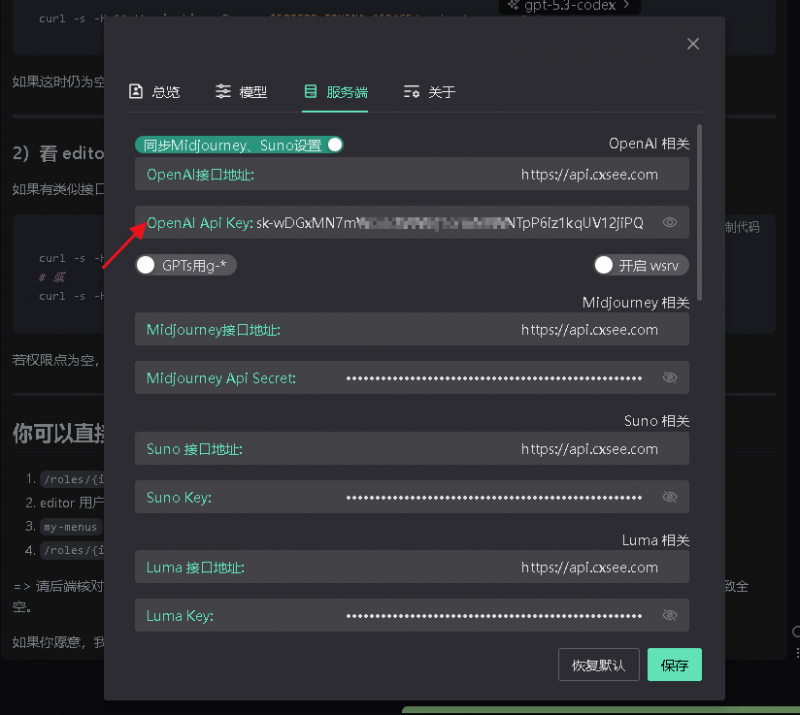
开源工具示例:Base URL+Api Key
开箱即用令牌KEY也可以到“数字先锋小程序”购买体验
请求示例(非流式)
curl -X POST "https://cxsee.cxsee.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4",
"messages": [
{
"role": "user",
"content": "你好,请用一句话介绍你自己"
}
],
"temperature": 0.7,
"stream": false
}'返回示例(成功)
{
"id": "chatcmpl-5fceea0d-305e-4517-85d2-efb3105a8876",
"object": "chat.completion",
"created": 1773596471,
"model": "gpt-5.4",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "你好,我是一个由 OpenAI 提供的 AI 助手,可以帮你解答问题、写作、翻译、编程和整理思路。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 14,
"completion_tokens": 38,
"total_tokens": 52
}
}流式回复请求示例(stream=true)
curl -N -X POST "https://cxsee.cxsee.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-5.4",
"messages": [
{
"role": "user",
"content": "请用3句话介绍一下人工智能的发展"
}
],
"temperature": 0.7,
"stream": true
}'流式返回示例(SSE)
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"role":"assistant"},"finish_reason":null}]}
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"content":"人工智能起源于"},"finish_reason":null}]}
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"content":"20世纪中期,"},"finish_reason":null}]}
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"content":"经历了符号主义、机器学习和深度学习等阶段。"},"finish_reason":null}]}
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"content":"近年来,大模型推动了自然语言、视觉与多模态能力的快速突破。"},"finish_reason":null}]}
data: {"id":"chatcmpl-xxx","object":"chat.completion.chunk","created":1773599999,"model":"gpt-5.4","choices":[{"index":0,"delta":{"content":"未来人工智能将更深入地重塑教育、医疗、制造与办公协作。"},"finish_reason":"stop"}]}
data: [DONE]| 字段 | 说明 |
|---|---|
| id | 本次请求唯一 ID(可用于排障与日志追踪) |
| object | 对象类型,通常为 chat.completion |
| created | 响应创建时间(Unix 时间戳) |
| model | 实际使用的模型 ID |
| choices | 生成结果数组(通常取 choices[0]) |
| choices[].message.role | 返回角色,通常为 assistant |
| choices[].message.content | 模型生成内容 |
| finish_reason | 结束原因:stop 表示正常结束 |
| usage.prompt_tokens | 输入消耗 tokens |
| usage.completion_tokens | 输出消耗 tokens |
| usage.total_tokens | 总消耗 tokens |

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)