AI编程2:LangGraph 实战:打造 AI 智能路由工作流,让 LLM 自动 “分流干活“
本文手把手教你用 LangGraph 搭建智能路由工作流,实现 AI 自动分析用户意图、动态分支执行任务,附完整可运行代码!
作者:WangQiaomei版本:1.0(2026/3/16)
前言
在 AI 应用开发中,我们经常需要让大模型根据用户输入的不同意图,自动选择对应的处理逻辑 —— 比如用户要讲笑话就调用笑话生成逻辑,要写故事就调用故事生成逻辑。今天就带大家基于 LangGraph 实现一套智能路由工作流,让 AI 像餐厅服务员一样,精准把用户需求分配到对应 "窗口" 处理!
一、核心场景:AI 自动识别意图并执行
先看一个完整的执行流程,直观感受智能路由的作用:
- 输入:
"Write me a joke about cats"(给我写一个关于猫的笑话) - 路由判断:LLM 分析用户意图,返回
decision = "joke"(判断用户想要笑话) - 条件分支:路由函数根据
decision,指定下一步执行llm_call_2(笑话生成节点) - 执行:
llm_call_2调用 LLM 生成关于猫的笑话 - 输出:打印最终生成的笑话内容
工作流程图

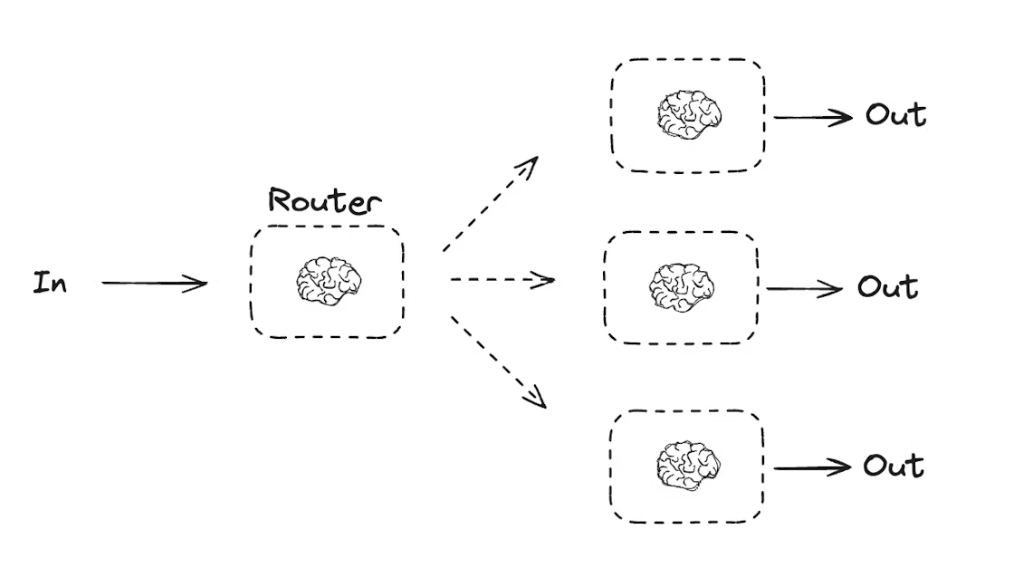
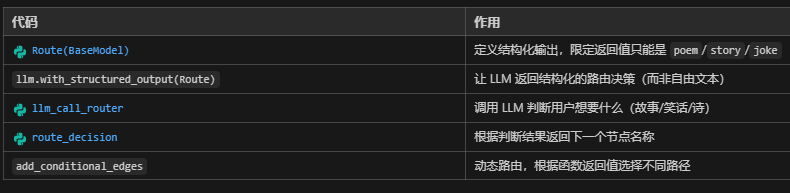
核心组件解释
🌰 生活类比:餐厅点餐系统
为了让新手快速理解,我们用餐厅场景做类比:
表格
| 生活中的概念 | 代码中的对应 |
|---|---|
| 顾客说的话 | state["input"] = "Write me a joke about cats" |
| 服务员判断需求类型 | llm_call_router → 判断出是 "joke" |
| 分配到对应窗口 | route_decision → 返回 "llm_call_2" |
| 面食 / 饮料 / 甜点窗口 | llm_call_1 (故事) /llm_call_2 (笑话) /llm_call_3 (诗) |
| 做好的菜 | state["output"] = 生成的笑话内容 |
简单来说:这是一套 "智能分流" 系统,AI 自动分析用户需求,然后路由到对应的处理函数执行。
二、核心概念:LangGraph 的 "边" 与 "节点"
LangGraph 的核心是节点(Node) 和边(Edge),节点是执行具体任务的函数,边是节点之间的执行路径。我们重点讲两种边:普通边和条件边(智能路由的核心)。
2.1 普通边:固定执行路径
普通边是 "单向固定" 的,从 A 节点执行完,必然走到 B 节点。
python
运行
# 示例:开始节点执行完,必然走到路由节点(服务员)
router_builder.add_edge(START, "llm_call_router")
# 示例:任何生成节点执行完,必然走到结束节点
router_builder.add_edge("llm_call_1", END) # 写故事 → 结束
router_builder.add_edge("llm_call_2", END) # 写笑话 → 结束
router_builder.add_edge("llm_call_3", END) # 写诗 → 结束
2.2 条件边:动态智能路由(核心)
条件边是 "动态可变" 的,根据判断结果决定下一步走哪个节点,这也是智能路由的核心。
2.2.1 条件边语法
python
运行
router_builder.add_conditional_edges(
"起始节点", # 从哪个节点出发(比如:服务员节点)
"判断函数", # 根据什么规则判断(比如:分析decision值)
{
"判断结果1": "目标节点1",
"判断结果2": "目标节点2",
...
} # 结果与节点的映射表
)
2.2.2 实战示例(对应餐厅场景)
python
运行
router_builder.add_conditional_edges(
"llm_call_router", # 服务员节点
route_decision, # 服务员的判断逻辑
{
"llm_call_1": "llm_call_1", # 意图=故事 → 故事窗口
"llm_call_2": "llm_call_2", # 意图=笑话 → 笑话窗口
"llm_call_3": "llm_call_3", # 意图=诗 → 诗歌窗口
},
)
2.2.3 路由判断函数(route_decision)
这个函数是条件边的 "大脑",根据路由节点的判断结果,返回下一步要执行的节点名:
python
运行
def route_decision(state: State):
if state["decision"] == "story":
return "llm_call_1" # 意图=故事 → 执行故事节点
elif state["decision"] == "joke":
return "llm_call_2" # 意图=笑话 → 执行笑话节点
elif state["decision"] == "poem":
return "llm_call_3" # 意图=诗 → 执行诗歌节点
三、关键实现:路由节点如何识别用户意图?
路由节点(llm_call_router)是整个工作流的 "大脑",它通过 LLM 分析用户输入的语义,返回结构化的意图判断结果。
3.1 结构化输出约束
首先定义结构化输出模型,限定 LLM 只能返回poem/story/joke三种结果,避免返回无效值:
python
运行
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
..., description="The next step in the routing process"
)
# 让LLM返回结构化的路由决策(而非自由文本)
router = llm.with_structured_output(Route)
3.2 路由节点函数实现
python
运行
def llm_call_router(state: State):
"""路由节点:分析用户意图,决定走哪个分支"""
# 调用LLM分析用户输入
decision = router.invoke(
[
SystemMessage(
content="Route the input to story, joke, or poem based on the user's request."
),
HumanMessage(content=state["input"]),
]
)
# 返回结构化的判断结果
return {"decision": decision.step}
3.3 为什么比传统关键词匹配更优?
表格
| 方式 | 示例 | 特点 |
|---|---|---|
| 传统算法 | if "joke" in input: return "joke" |
关键词匹配,死板(比如识别不了 "来点好笑的") |
| AI 模型 | 理解 "给我讲个笑话"、"Write me a joke" 等自然语言 | 语义理解,灵活适配各种表达 |
四、完整核心代码(可直接运行)
python
运行
# -*- coding: utf-8 -*-
"""
langchain_test5_routing
~~~~~~~~~~~~
:copyright: (c) 2026
:authors: WangQiaomei
:version: 1.0 of 2026/3/16
用户输入 "Write me a joke about cats"
↓
llm_call_router ← LLM 分析意图,返回 "joke"
↓
route_decision ← 根据 decision 选择分支
/ │ \
↓ ↓ ↓
story joke poem
(llm_1)(llm_2)(llm_3)
\ │ /
↓
END
"""
# 导入必要依赖(新手注意:先安装依赖 pip install langgraph langchain langchain-community pydantic)
from langgraph import StateGraph, START, END
from langgraph.graph import StateGraph
from pydantic import BaseModel, Field
from typing import Literal, TypedDict
from langchain_core.messages import SystemMessage, HumanMessage
from IPython.display import Image, display
# 初始化LLM(以通义千问为例,可替换为OpenAI/Claude等)
# 注意:需提前配置环境变量 ALIBABA_API_KEY
from langchain_community.llms import Tongyi
llm = Tongyi(model_name="qwen-turbo")
# 定义结构化输出,限定返回值只能是 poem/story/joke
class Route(BaseModel):
step: Literal["poem", "story", "joke"] = Field(
..., description="The next step in the routing process"
)
# 让 LLM 返回结构化的路由决策(而非自由文本)
router = llm.with_structured_output(Route)
def safe_print(text):
"""GBK 兼容打印,移除无法编码的字符(如 emoji)"""
print(text.encode('gbk', errors='ignore').decode('gbk'), end="", flush=True)
# 状态定义:工作流中传递的数据结构
class State(TypedDict):
input: str # 用户输入
decision: str # 路由决策结果(poem/story/joke)
output: str # 最终输出
# 节点函数:每个节点负责一种任务
def llm_call_1(state: State):
"""写故事"""
result = llm.invoke(state["input"])
return {"output": result}
def llm_call_2(state: State):
"""写笑话"""
result = llm.invoke(state["input"])
return {"output": result}
def llm_call_3(state: State):
"""写诗"""
result = llm.invoke(state["input"])
return {"output": result}
def llm_call_router(state: State):
"""路由节点:分析用户意图,决定走哪个分支"""
# 使用结构化输出的 LLM 来判断用户想要什么
decision = router.invoke(
[
SystemMessage(
content="Route the input to story, joke, or poem based on the user's request."
),
HumanMessage(content=state["input"]),
]
)
return {"decision": decision.step}
# 条件边函数:根据 decision 返回下一个要执行的节点名称
def route_decision(state: State):
# 返回要访问的下一个节点名称
if state["decision"] == "story":
return "llm_call_1"
elif state["decision"] == "joke":
return "llm_call_2"
elif state["decision"] == "poem":
return "llm_call_3"
# 构建工作流
router_builder = StateGraph(State)
# 第1步:添加所有节点(定义可用的"窗口")
router_builder.add_node("llm_call_1", llm_call_1) # 故事窗口
router_builder.add_node("llm_call_2", llm_call_2) # 笑话窗口
router_builder.add_node("llm_call_3", llm_call_3) # 诗歌窗口
router_builder.add_node("llm_call_router", llm_call_router) # 路由窗口(服务员)
# 第2步:添加起始边(用户先找服务员)
router_builder.add_edge(START, "llm_call_router") # 开始 → 路由节点
# 第3步:添加条件边(服务员分配到对应窗口)
router_builder.add_conditional_edges(
"llm_call_router", # 从路由节点出发
route_decision, # 决策函数
{
"llm_call_1": "llm_call_1", # 分配到故事窗口
"llm_call_2": "llm_call_2", # 分配到笑话窗口
"llm_call_3": "llm_call_3", # 分配到诗歌窗口
},
)
# 第4步:添加结束边(所有窗口执行完都结束)
router_builder.add_edge("llm_call_1", END) # 写故事 → 结束
router_builder.add_edge("llm_call_2", END) # 写笑话 → 结束
router_builder.add_edge("llm_call_3", END) # 写诗 → 结束
# 编译工作流
router_workflow = router_builder.compile()
# 显示工作流图(需安装 graphviz:pip install graphviz)
display(Image(router_workflow.get_graph().draw_mermaid_png()))
# 执行工作流
if __name__ == "__main__":
state = router_workflow.invoke({"input": "Write me a joke about cats"})
safe_print(state["output"])
五、运行效果展示
执行代码后,LLM 会自动识别用户输入的意图是 "joke",并生成对应的笑话:
plaintext
Sure! Here's a purr-fect one for you:
**Why did the cat get kicked out of the library?**
*Because every time someone whispered “shhh,” it immediately interpreted it as an invitation to sit on their laptop… and then loudly demanded treats in full-volume yowls.*
*Bonus fact: Studies show cats understand “shhh” about as well as they understand why curtains exist — which is to be climbed, not ignored.*
Want a pun-based version, a science-y twist, or one starring a specific cat breed?
六、扩展与优化建议
- 增加意图类型:只需扩展
Route类的Literal值,新增对应的节点函数即可(比如添加essay(散文)类型); - 异常处理:给路由函数添加默认分支,避免 LLM 返回非预期值导致工作流中断;
- 多轮对话:扩展
State类,添加history字段,支持多轮上下文感知; - 性能优化:对高频意图添加缓存,避免重复调用 LLM 做路由判断。
📝 核心知识点总结
- LangGraph 核心:节点(Node)是执行具体任务的函数,边(Edge)是节点间的执行路径,条件边是智能路由的核心;
- 结构化输出:通过
with_structured_output约束 LLM 返回固定格式的结果,避免自由文本的不确定性; - 智能路由逻辑:先通过 LLM 分析用户意图(路由节点),再通过条件边动态选择执行节点,实现 "按需执行"。
最后
这套智能路由工作流是 LangGraph 最经典的应用场景之一,掌握它后可以扩展到更复杂的 AI 应用 —— 比如智能客服(分流咨询 / 投诉 / 售后)、智能创作平台(分流小说 / 诗歌 / 剧本)等。如果有任何问题,欢迎在评论区交流~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)