【瑞萨AI挑战赛】数据采集,模型训练以及部署
这是我使用RA0E1芯片构建的采集节点,多节点挂载在485总线,采集板载传感器数据,用来监测每个节点的压力。目前的问题在于传感误差以及功耗问题。考虑如果训练模型判断整体结构变化趋势,对轮询间隔,以及轮询数量进行调度,可以显著降低整体功耗。

Reality AI提供的数据采集工具Data Storage Tool可以有效助理传感器数据集的采集,方便后续进行模型训练。首先来调通这个工具。
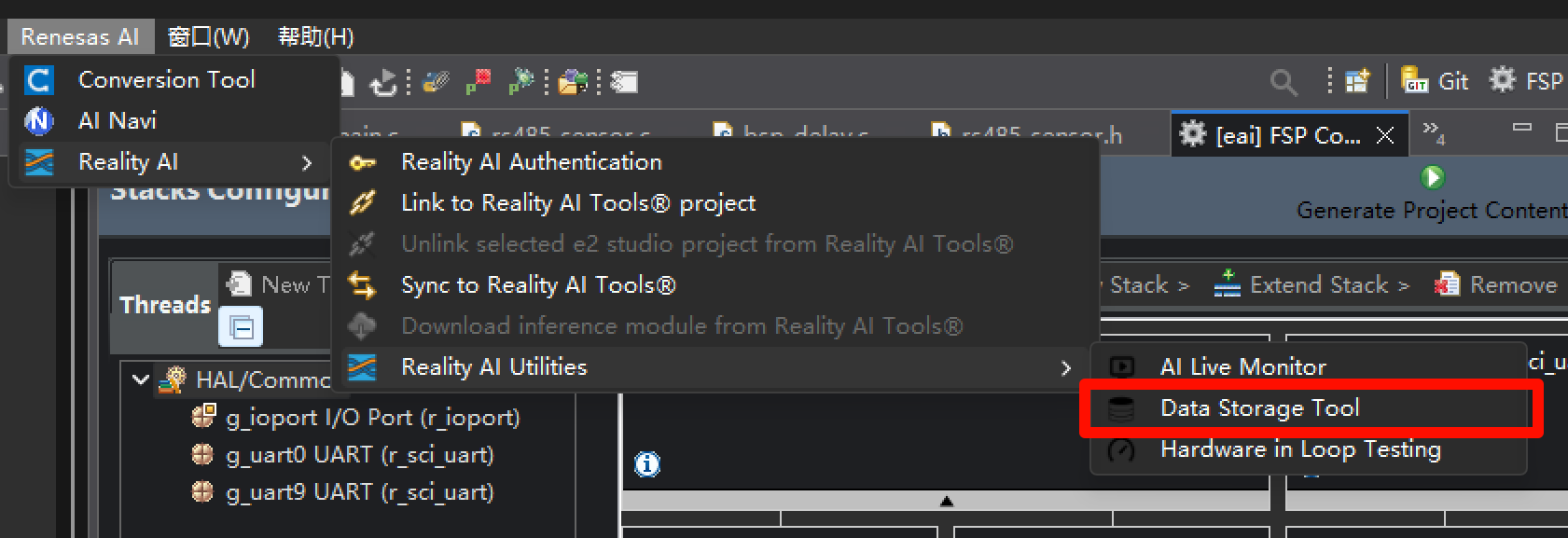
打开工具,自动映射到了当前连接的串口通道,这就是我们之前配置的通过jlink转发的串口。点击connect即可链接。
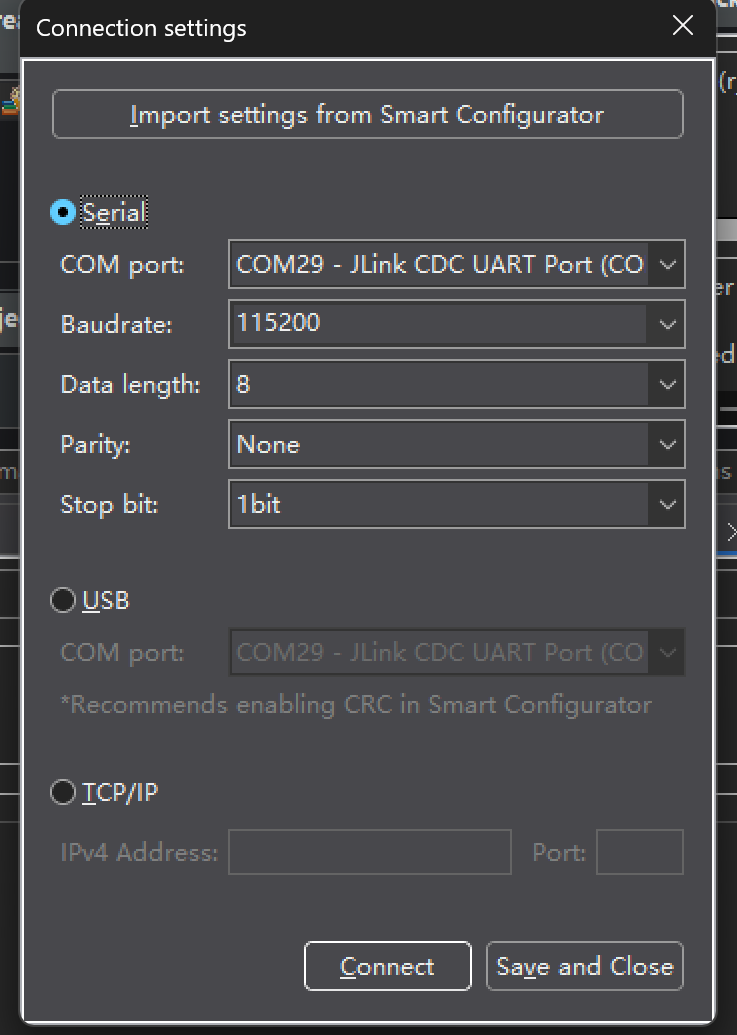
配置好后,问题就来了,应该采集什么样的数据呢?
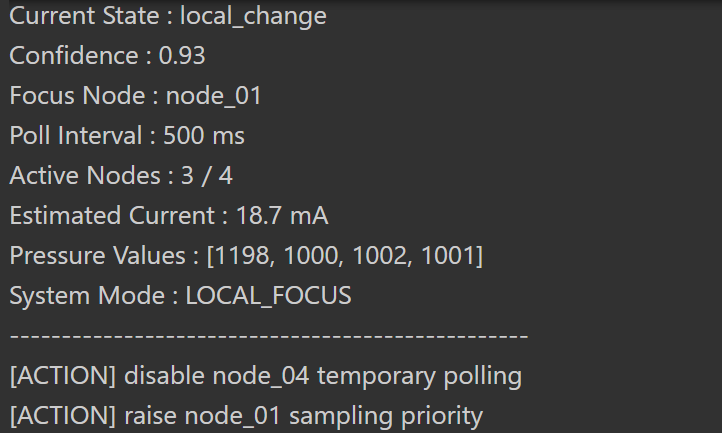
给这个多节点压力监测系统定了 5 个状态:
stable_pressureslow_driftlocal_changeglobal_changesuspected_abnormal
对应了五个状态:内容是系统后面该怎么调度。
第一种状态:stable_pressure
这个状态最好理解。
它表示当前压力整体稳定,节点数据虽然会有细微波动,但这些波动基本都还停留在噪声范围内,空间分布关系也没有明显变化。
换句话说,就是系统处在一种“没什么事发生”的状态。
在这个状态下,典型现象通常是:
- 单节点压力值围绕某个稳定值轻微波动
- 短时均值基本不变
- 方差较低
- 相邻采样点差分不大
- 多节点之间的压力分布关系保持稳定
这类状态最适合做的事情,其实不是继续拼命采,而是放心大胆地省电。
如果模型判断当前是 stable_pressure,那么系统完全可以:
- 拉长轮询间隔
- 减少参与轮询的节点数量
- 只保留少量哨兵节点继续在线
- 让其他节点尽量停在低功耗等待状态
第二种状态:slow_drift
它表示压力值不是完全不动,而是在一个较长时间尺度上缓慢变化。这个变化通常不是突发的,也不是剧烈的,而是一种“慢慢偏”的状态。
- 载荷在缓慢增加
- 载荷在缓慢释放
- 接触面在慢慢滑移
- 环境因素引起的基线缓慢漂移
从数据上看,它的特点一般是:
- 短时波动不大
- 但长窗口上有明显斜率
- 均值在持续单向变化
- 节点间相对关系变化缓慢
这个状态最容易和 stable_pressure 打架。因为如果窗口太短,看起来它像稳定;如果窗口拉长,又会发现它其实在慢慢漂。
如果写代码来实现的话,和上一个状态相比,要设计窗口以及阈值。但是或许使用ai可以简化这个流程。
如果系统判断当前处于 slow_drift,就没必要像异常一样全网提频,但也不应该继续像纯稳定态那样懒着。更合理的策略通常是:
- 保持中低频轮询
- 继续跟踪趋势
- 适当保留更多节点在线
- 为后续可能进入变化态做准备
第三种状态:local_change
表示变化发生了,但还只是局部发生。也就是说,某几个节点、某一个小区域的压力已经明显变化,但整个系统还没有一起动起来。
比如:
- 某个局部点被按压了
- 某一片区域载荷增加
- 某个节点周围接触关系发生变化
- 局部受力开始异常,但还没扩散成整体变化
这类状态的数据特征通常会表现为:
- 某几个节点均值突变或方差明显上升
- 局部节点差分增大
- 其余节点仍然相对稳定
- 空间分布开始局部失衡
如果模型给出 local_change,那最合理的调度方式通常不是全网一起提频,而是:
- 保持全局中频轮询
- 对热点区域节点提高轮询密度
- 提高相关节点上报频率
- 让调度策略优先关注发生变化的那一小片区域
这一步如果做得好,系统既不会因为一点局部变化就全网过载,也不会因为偷懒而漏掉真正开始变化的区域。
第四种状态:global_change
和 local_change 相对应,global_change 表示变化已经不是局部的了,而是多个节点同时发生明显变化,说明整体工况、整体受力或者整体接触状态正在变化。
这类状态通常意味着系统不能再慢吞吞地按老节奏工作了。
典型场景可能包括:
- 整体载荷明显上升或下降
- 多点同时受力变化
- 压力中心发生明显迁移
- 多节点共同表现出趋势切换
它的典型数据表现一般是:
- 多个节点同步上升或下降
- 全局均值、极差都在明显变化
- 空间分布整体重排
- 节点间关系不再只是某一小块偏移,而是出现系统级变化
这个状态一旦出现,系统调度就要更积极:
- 缩短全局轮询周期
- 增加参与轮询的节点数量
- 提高整体采样和上报频率
- 必要时进入高关注模式
如果说 stable_pressure 是“别忙了”,那 global_change 基本就是“全体起来,别装死”。
第五种状态:suspected_abnormal
最后一个状态,是 suspected_abnormal。
它可能对应的场景包括:
- 单点异常尖峰
- 高频抖动异常
- 节点接触不良
- 虚接、跳变、漂移失控
- 某个节点输出突然脱离整体模式
- 超出历史统计边界的异常受力行为
从数据上看,这类状态往往表现得比较难看:
- 突发峰值很高
- 波动极不连续
- 节点间一致性突然崩掉
- 跟以往任何正常模式都不太像
这个标签的意义非常直接:它不是让系统优雅分析,而是让系统赶紧提高警惕。
如果模型判断当前是 suspected_abnormal,调度上一般就不能再省着来了,而是应该:
- 提高采样频率
- 增加关键节点参与度
- 进入告警或诊断模式
- 必要时恢复更高密度的全节点监测
这类状态在后期非常值钱,因为它决定了这套系统能不能不仅省电,还具备一点真正的“异常感知能力”。
除此之外,这些状态不应该通过轮询所有的传感器判断出,而是取部分节点进行分析
所以在样本中,每个样本窗口里,可以包含:多节点压力序列、时间戳、对应标签、当前状态、可选的采样频率和批次编号。
我们根据这个来设计单片机程序,样本数据示意如下:
{
"timestamp": "2026-03-15T21:05:10.120+08:00",
"bus_id": "rs485_01",
"round_id": 1286,
"sample_rate_hz": 50,
"nodes": [
{"id": "node_01", "pressure": 1023},
{"id": "node_02", "pressure": 1018},
{"id": "node_03", "pressure": 1021},
{"id": "node_04", "pressure": 1020}
]
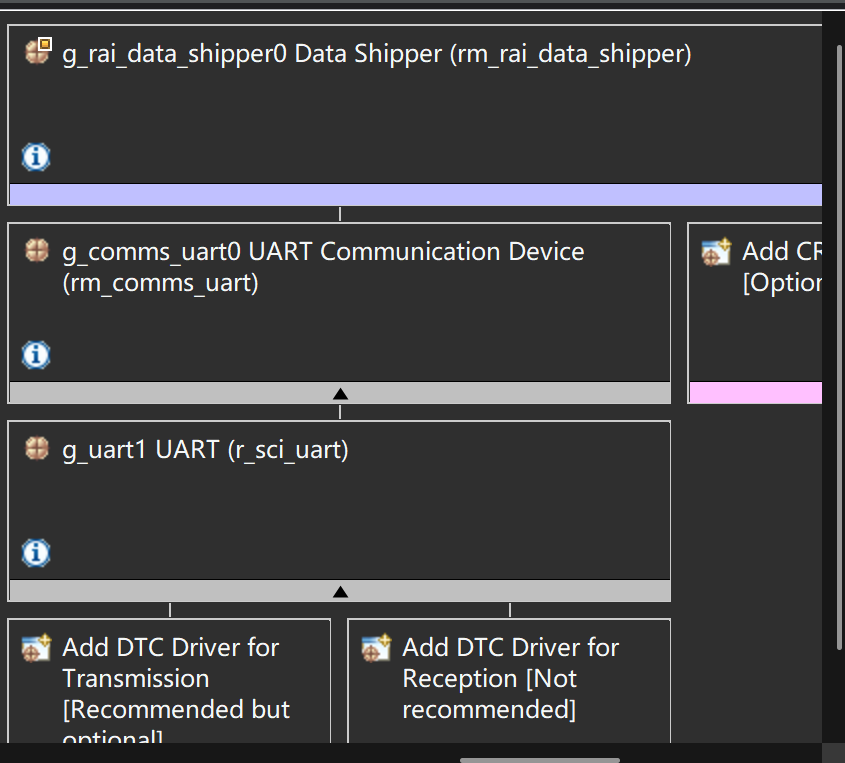
}需要配置一个data shipper,如图,并将串口以及data collector直接介入这个stack。
新建一个stack,配置一下data collector,如图。
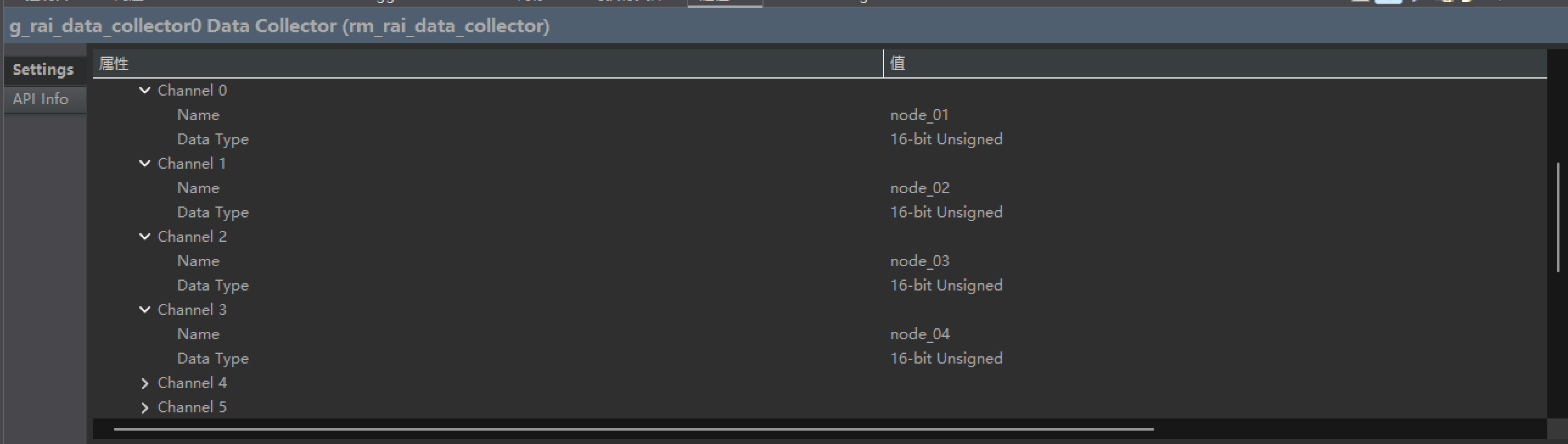
从这里一键导入我们配置好的通道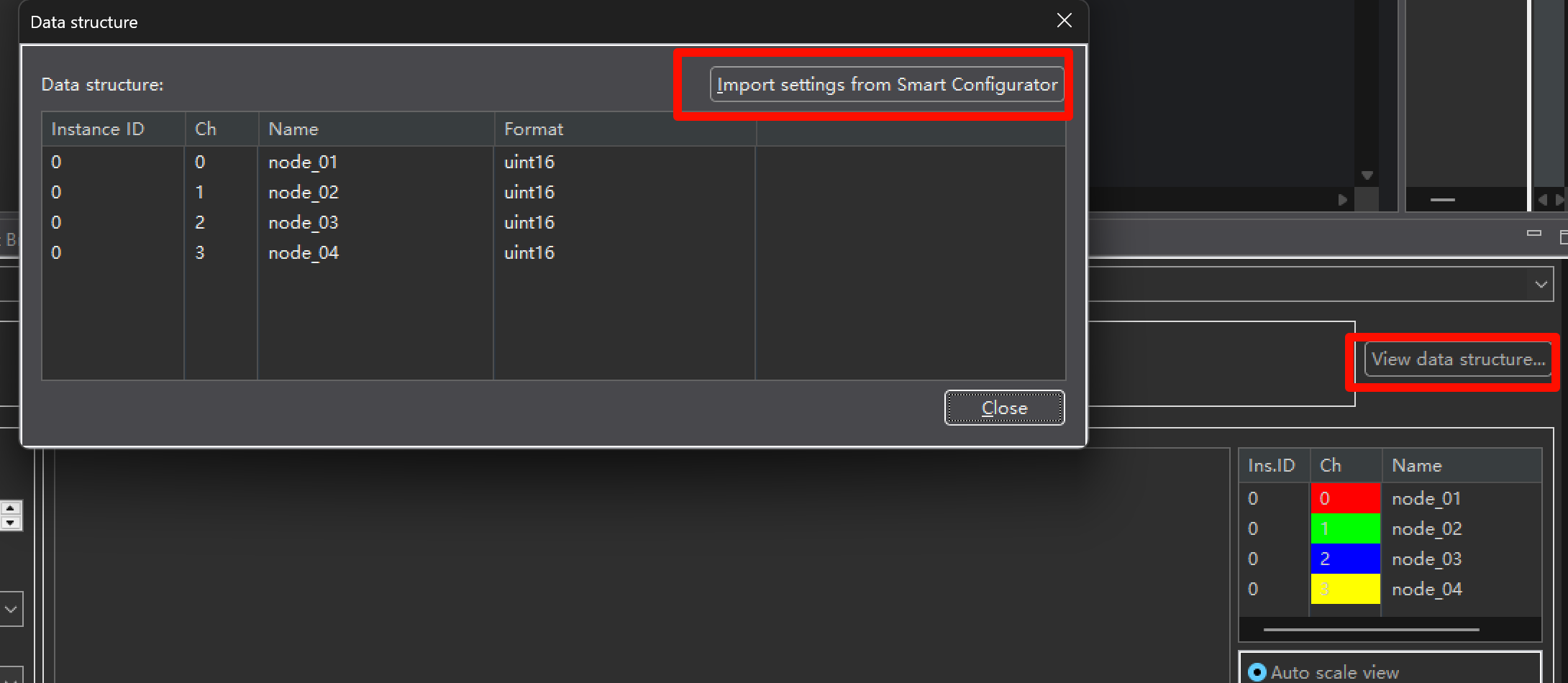
最后数据集以csv格式导出,存储在本地。可以直接拖入Reality AI 网站。进行数据处理之后,最终形成数据集。
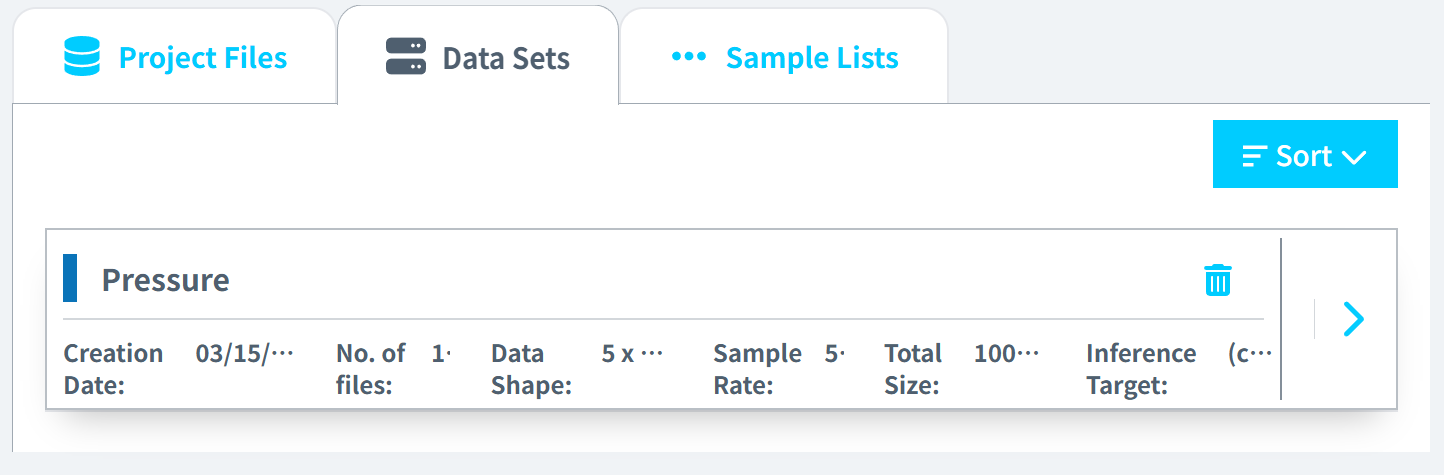
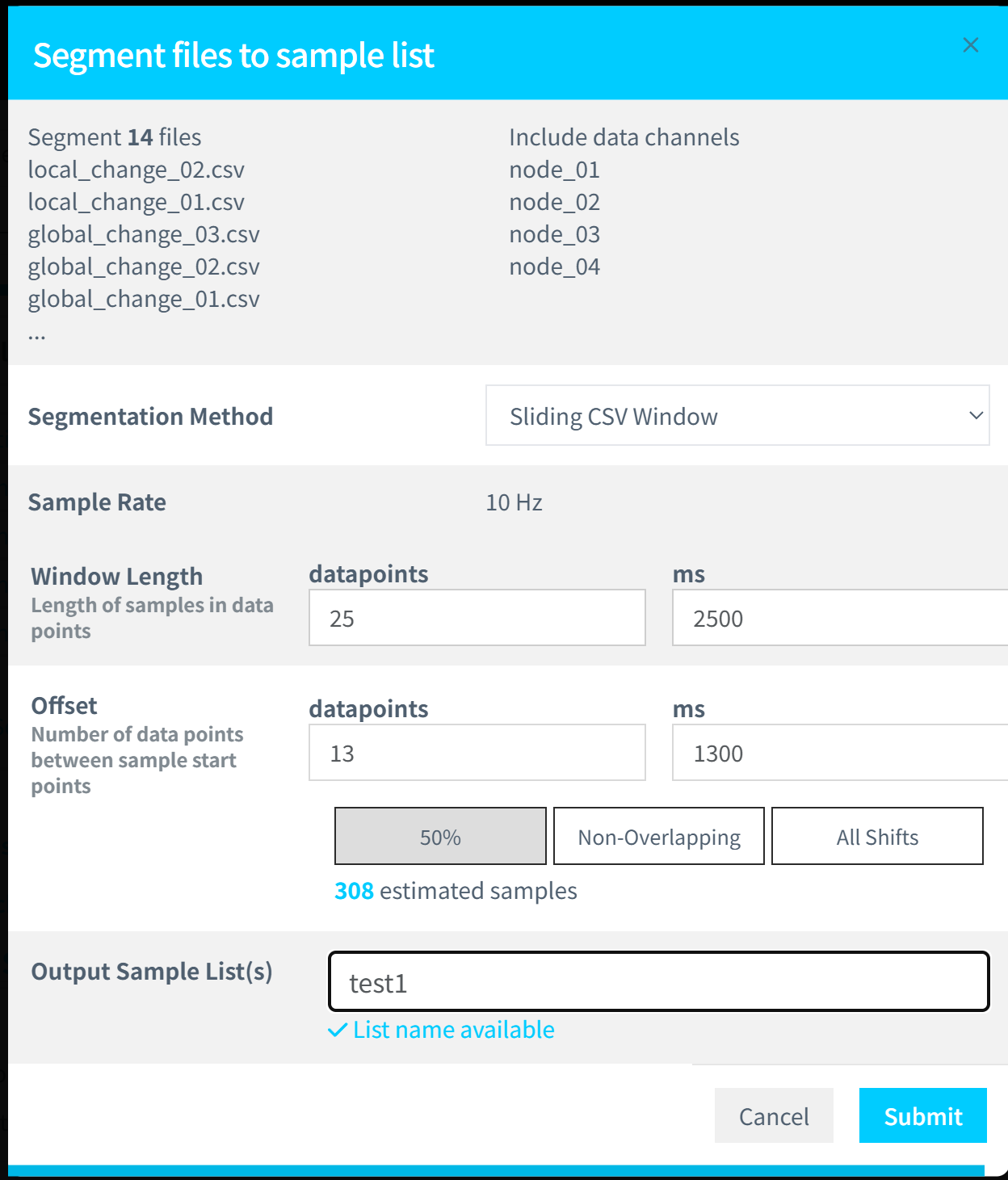
在之前dataset的基础上,创建一个sample list
分类list完成后,在classes中点击start exploring开始生成模型。
在 Reality AI 训练完成以后,平台通常会给出几组候选模型。
这时候前面已经根据资源占用、整体精度、最差精度和混淆矩阵做过一轮筛选,所以到了这里,就不再是随便选一个,而是挑那个更适合当前板子资源、同时分类结果也比较稳的模型。
模型选定以后,接下来就是生成嵌入式部署包。
之后在deploy中,选择开发板,工具链,生成可部署在MCU中的模型文件,完成后点击下载。
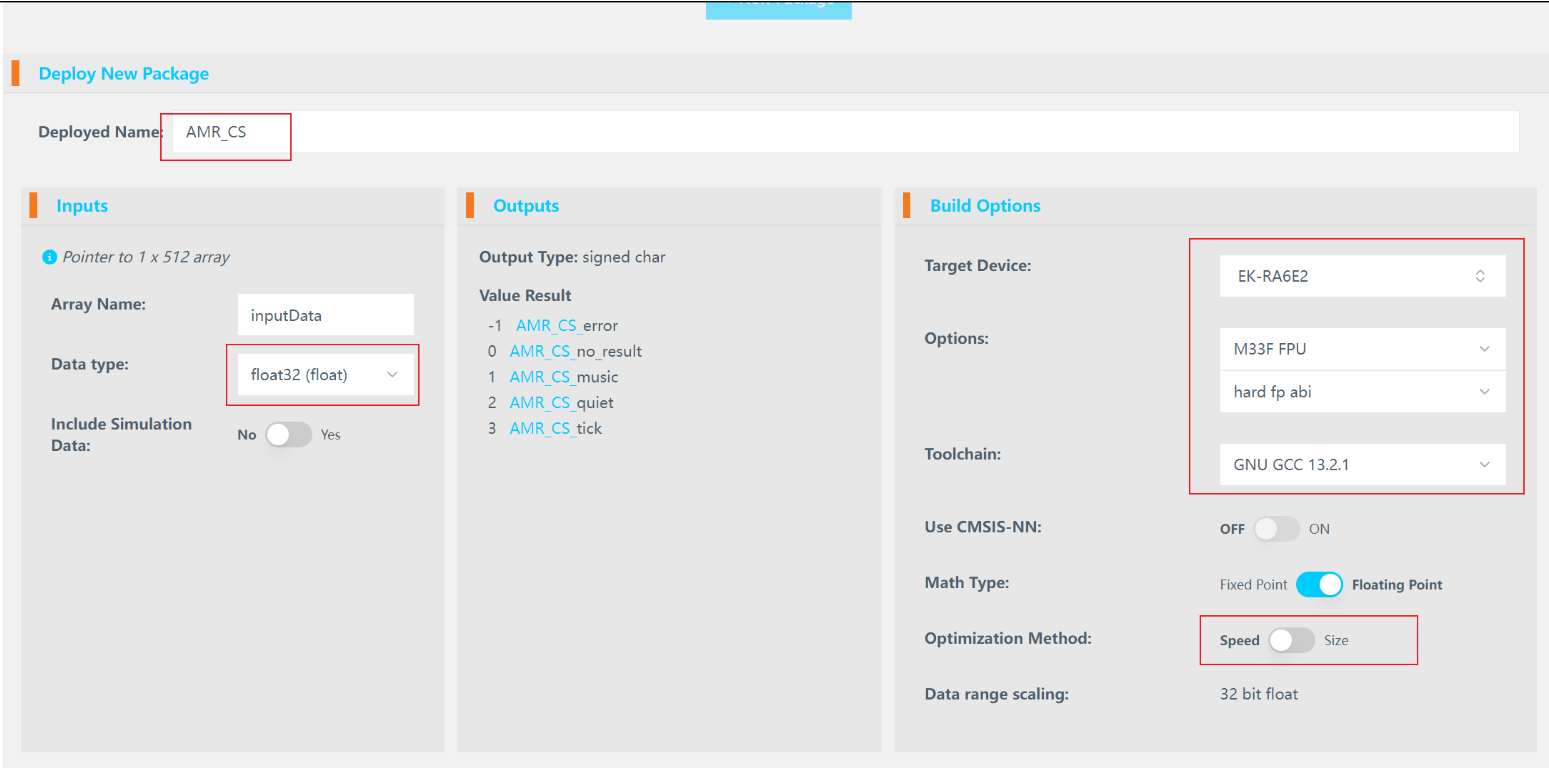
接下来就回到自己的 e2studio 工程里。
将librai_edsp_f32_arm.a,amr_model.c,amr_model.h,RealityAI.h,RealityAI_Config.h,RealityAI_Types.h文件复制到Asset Tracking工程中的src/rai文件夹中。借用生成的example.c调用模型,添加#include "AMR_CS_model.h"头文件。编译通过,无报错。
连接好设备,上电,终端显示如下,调度逻辑成功运行。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)