花卉分类半监督项目
目的:伪标签是为了充分利用大量无标注数据,扩充训练集,提升模型在小样本下的分类性能。
过程:初始化空白模型 → 用有标注数据全监督训练若干轮 → 验证准确率达标 → 具备基础判断能力→无标签的选择。
【伪标签不是人工标注的,是用已经训练了一段时间的模型,对无标注图片做 “高置信度预测” 得到的标签—— 只有模型 “极度确定”(比如置信度 > 99%)的预测结果,才会被当作伪标签保留。】
# ====================== 1. 导入依赖库 ======================
import random
import torch
import torch.nn as nn
import numpy as np
import os
from PIL import Image # 读取图片数据
from torch.utils.data import Dataset, DataLoader # 数据加载核心库
from tqdm import tqdm # 进度条显示
from torchvision import transforms # 图像预处理
import time # 计时
import matplotlib.pyplot as plt # 绘制损失/准确率曲线
from model_utils.model import initialize_model # 加载预训练模型(如VGG)
# ====================== 2. 固定随机种子(保证实验可复现) ======================
def seed_everything(seed):
# PyTorch相关种子
torch.manual_seed(seed) # CPU随机种子
torch.cuda.manual_seed(seed) # 单GPU随机种子
torch.cuda.manual_seed_all(seed) # 多GPU随机种子
torch.backends.cudnn.benchmark = False # 关闭CUDA自动优化(保证复现)
torch.backends.cudnn.deterministic = True # 强制确定性算法
# Python/Numpy相关种子
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed) # Python哈希种子
# 固定种子为0(复试必提:保证实验可复现)
seed_everything(0)
# 全局参数:图片统一缩放为224×224(适配VGG等预训练模型输入)
HW = 224
# ====================== 3. 图像预处理(数据增强+归一化) ======================
# 训练集预处理:数据增强(提升泛化能力)
train_transform = transforms.Compose([
transforms.ToPILImage(), # numpy数组转PIL图片(读数据时存为numpy)
transforms.RandomResizedCrop(224), # 随机裁剪+缩放(模拟不同视角)
transforms.RandomRotation(50), # 随机旋转±50度(数据增强)
transforms.ToTensor() # 转Tensor:HWC→CHW,值归一化到0-1
])
# 验证集预处理:仅必要转换(保证评估客观)
val_transform = transforms.Compose([
transforms.ToPILImage(), # numpy数组转PIL图片
transforms.ToTensor() # 转Tensor
])
# ====================== 4. 自定义数据集类(加载food-11数据) ======================
class food_Dataset(Dataset):
"""
自定义Dataset类,适配food-11数据集:
- mode="train/val":加载有标注数据(图片+标签)
- mode="semi":加载无标注数据(仅图片)
"""
def __init__(self, path, mode="train"):
self.mode = mode # 数据模式:train/val/semi
# 加载数据
if mode == "semi":
self.X = self.read_file(path) # 无标注数据仅存图片
else:
self.X, self.Y = self.read_file(path) # 有标注数据存图片+标签
self.Y = torch.LongTensor(self.Y) # 标签转LongTensor(适配CrossEntropyLoss)
# 绑定预处理方式
self.transform = train_transform if mode == "train" else val_transform
def read_file(self, path):
"""核心方法:读取文件夹中的图片数据"""
# 处理无标注数据(semi模式)
if self.mode == "semi":
file_list = os.listdir(path) # 列出文件夹下所有图片
# 初始化数组:(样本数, 224, 224, 3),uint8(0-255,节省内存)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name) # 拼接完整图片路径
img = Image.open(img_path) # 打开图片
img = img.resize((HW, HW)) # 统一缩放为224×224
xi[j, ...] = img # 存入数组
print(f"无标注数据:读到了{len(xi)}个样本")
return xi
# 处理有标注数据(train/val模式)
else:
# food-11共11类(00-10),循环读取每一类
for i in tqdm(range(11), desc="加载有标注数据"):
file_dir = os.path.join(path, f"{i:02d}") # 类别文件夹(00,01,...,10)
file_list = os.listdir(file_dir) # 列出当前类的所有图片
# 初始化当前类的图片/标签数组
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
yi = np.zeros(len(file_list), dtype=np.uint8) # 标签初始化为0
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
yi[j] = i # 当前图片的标签为类别i
# 合并所有类的数据
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) # 按样本维度合并
Y = np.concatenate((Y, yi), axis=0)
print(f"有标注数据:读到了{len(Y)}个样本")
return X, Y
def __getitem__(self, item):
"""核心方法:获取单个样本(DataLoader会调用)"""
if self.mode == "semi":
# 无标注数据:返回预处理后的图片 + 原始图片(后续打伪标签用)
return self.transform(self.X[item]), self.X[item]
else:
# 有标注数据:返回预处理后的图片 + 标签
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
"""核心方法:返回样本总数"""
return len(self.X)
# ====================== 5. 半监督数据集类(生成伪标签) ======================
class semiDataset(Dataset):
"""
半监督数据集:用训练好的模型给无标注数据打「高置信度伪标签」
- 仅保留置信度>thres的样本(保证伪标签可靠性)
"""
def __init__(self, no_label_loader, model, device, thres=0.99):
self.thres = thres
# 核心:给无标注数据打伪标签并筛选
self.X, self.Y = self.get_label(no_label_loader, model, device)
# 判断是否有符合条件的伪标签样本
self.flag = False if len(self.X) == 0 else True
if self.flag:
self.X = np.array(self.X)
self.Y = torch.LongTensor(self.Y)
self.transform = train_transform # 伪标签样本按训练集增强
def get_label(self, no_label_loader, model, device):
"""核心方法:生成伪标签并筛选高置信度样本"""
model = model.to(device)
model.eval() # 切换为评估模式(BN/Dropout冻结)
pred_probs = [] # 存储每个样本的预测置信度
pred_labels = [] # 存储每个样本的预测标签
selected_x = [] # 筛选后的原始图片
selected_y = [] # 筛选后的伪标签
# Softmax:将模型输出的logits转为0-1的概率分布
softmax = nn.Softmax(dim=1)
# 推理模式:关闭梯度计算(节省内存+加速)
with torch.no_grad():
for bat_x, raw_x in no_label_loader:
bat_x = bat_x.to(device) # 数据移到GPU/CPU
pred = model(bat_x) # 模型预测(输出logits)
pred_soft = softmax(pred) # 转概率分布
# 取最大概率和对应标签
max_prob, max_label = pred_soft.max(dim=1)
# 保存结果(转CPU+numpy)
pred_probs.extend(max_prob.cpu().numpy().tolist())
pred_labels.extend(max_label.cpu().numpy().tolist())
# 筛选高置信度样本(置信度>thres才认为可靠)
for idx, prob in enumerate(pred_probs):
if prob > self.thres:
selected_x.append(no_label_loader.dataset[idx][1]) # 原始图片
selected_y.append(pred_labels[idx]) # 伪标签
return selected_x, selected_y
def __getitem__(self, item):
return self.transform(self.X[item]), self.Y[item]
def __len__(self):
return len(self.X)
def get_semi_loader(no_label_loader, model, device, thres=0.99):
"""辅助函数:生成半监督DataLoader"""
semi_set = semiDataset(no_label_loader, model, device, thres)
if not semi_set.flag:
return None
# 伪标签数据不打乱(已通过高置信度筛选,无需打乱)
return DataLoader(semi_set, batch_size=16, shuffle=False)
# ====================== 6. 自定义CNN模型(备用,实际用VGG) ======================
class myModel(nn.Module):
"""
基础CNN模型结构:Conv→BN→ReLU→Pool 堆叠
输入:3×224×224 → 输出:11类分类结果
"""
def __init__(self, num_class):
super(myModel, self).__init__()
# 第一层卷积:3→64,尺寸224×224
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(64) # 批量归一化(加速训练)
self.relu = nn.ReLU() # 激活函数(引入非线性)
self.pool1 = nn.MaxPool2d(2) # 池化:尺寸减半(224→112)
# 卷积块1:64→128,尺寸112→56
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 卷积块2:128→256,尺寸56→28
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 卷积块3:256→512,尺寸28→14
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 最终池化:512×14×14 → 512×7×7
self.pool2 = nn.MaxPool2d(2)
# 全连接层:512×7×7=25088 → 1000 → 11(分类数)
self.fc1 = nn.Linear(25088, 1000)
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
"""前向传播:定义数据流动路径"""
# 第一层卷积
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
# 卷积块堆叠
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
# 展平特征图:(batch, 512, 7, 7) → (batch, 25088)
x = x.view(x.size(0), -1)
# 全连接层
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x
# ====================== 7. 训练+验证核心函数 ======================
def train_val(model, train_loader, val_loader, no_label_loader,
device, epochs, optimizer, loss_fn, thres, save_path):
"""
核心训练逻辑:
1. 先用标注数据训练模型
2. 每3轮生成高置信度伪标签,加入半监督训练
3. 保存验证集准确率最高的模型
"""
model = model.to(device) # 模型移到GPU/CPU
semi_loader = None # 半监督DataLoader初始化为空
# 记录训练/验证的损失和准确率
train_loss_list = []
val_loss_list = []
train_acc_list = []
val_acc_list = []
max_val_acc = 0.0 # 保存最高验证准确率
# 开始训练
for epoch in range(epochs):
# 初始化本轮损失/准确率
train_loss = 0.0
val_loss = 0.0
train_correct = 0
val_correct = 0
semi_loss = 0.0
semi_correct = 0
start_time = time.time() # 记录本轮耗时
# ---------------------- 训练阶段 ----------------------
model.train() # 切换训练模式(BN/Dropout生效)
# 1. 训练标注数据
for batch_x, batch_y in train_loader:
# 数据移到设备
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 前向传播
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
# 反向传播+参数更新
loss.backward() # 计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 梯度清零(必须!否则累积)
# 累加损失和正确数
train_loss += loss.cpu().item()
# 计算准确率:预测类别=真实类别则正确
train_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 计算本轮训练平均损失/准确率
avg_train_loss = train_loss / len(train_loader)
avg_train_acc = train_correct / len(train_loader.dataset)
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
# 2. 训练半监督数据(伪标签数据)
if semi_loader is not None:
for batch_x, batch_y in semi_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
semi_loss += loss.cpu().item()
semi_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 打印半监督训练结果
avg_semi_acc = semi_correct / len(semi_loader.dataset)
print(f"Epoch {epoch} | 半监督准确率:{avg_semi_acc:.4f}")
# ---------------------- 验证阶段 ----------------------
model.eval() # 切换验证模式(BN/Dropout冻结)
with torch.no_grad(): # 关闭梯度计算(节省内存)
for batch_x, batch_y in val_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
val_loss += loss.cpu().item()
val_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 计算本轮验证平均损失/准确率
avg_val_loss = val_loss / len(val_loader.dataset)
avg_val_acc = val_correct / len(val_loader.dataset)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)
# ---------------------- 生成伪标签 ----------------------
# 每3轮+验证准确率>0.6时生成(模型足够好,伪标签才可靠)
if epoch % 3 == 0 and avg_val_acc > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
# ---------------------- 保存最优模型 ----------------------
if avg_val_acc > max_val_acc:
torch.save(model, save_path)
max_val_acc = avg_val_acc # 更新最高准确率
print(f"Epoch {epoch} | 保存最优模型(验证准确率:{max_val_acc:.4f})")
# ---------------------- 打印本轮结果 ----------------------
epoch_time = time.time() - start_time
print(
f"Epoch [{epoch+1}/{epochs}] | 耗时:{epoch_time:.2f}s "
f"| 训练损失:{avg_train_loss:.6f} | 验证损失:{avg_val_loss:.6f} "
f"| 训练准确率:{avg_train_acc:.6f} | 验证准确率:{avg_val_acc:.6f}"
)
# ---------------------- 绘制曲线 ----------------------
# 损失曲线
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss_list, label="Train Loss")
plt.plot(val_loss_list, label="Val Loss")
plt.title("Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_acc_list, label="Train Acc")
plt.plot(val_acc_list, label="Val Acc")
plt.title("Accuracy Curve")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()
# ====================== 8. 主函数(数据加载+参数设置+启动训练) ======================
if __name__ == "__main__":
# ---------------------- 数据集路径 ----------------------
train_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\labeled"
val_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\validation"
no_label_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\unlabeled\00"
# ---------------------- 加载数据集 ----------------------
train_dataset = food_Dataset(train_path, mode="train")
val_dataset = food_Dataset(val_path, mode="val")
no_label_dataset = food_Dataset(no_label_path, mode="semi")
# 创建DataLoader(批量加载数据)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True) # 训练集打乱
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False) # 验证集不打乱
no_label_loader = DataLoader(no_label_dataset, batch_size=16, shuffle=False)
# ---------------------- 模型初始化 ----------------------
# 可选:使用自定义模型 or 预训练VGG模型
# model = myModel(num_class=11)
model, _ = initialize_model("vgg", num_classes=11, use_pretrained=True)
# ---------------------- 训练参数 ----------------------
lr = 0.001 # 学习率
loss_fn = nn.CrossEntropyLoss() # 分类任务损失函数
# AdamW优化器(带权重衰减,防止过拟合)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
device = "cuda" if torch.cuda.is_available() else "cpu" # 优先用GPU
save_path = "model_save/best_model.pth" # 最优模型保存路径
epochs = 15 # 训练轮数
thres = 0.99 # 伪标签置信度阈值
# ---------------------- 启动训练 ----------------------
train_val(
model=model,
train_loader=train_loader,
val_loader=val_loader,
no_label_loader=no_label_loader,
device=device,
epochs=epochs,
optimizer=optimizer,
loss_fn=loss_fn,
thres=thres,
save_path=save_path
)模块 1:固定随机种子
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
核心是给所有随机数生成器设置同一个「种子值(seed)」
1.1原理如下:
随机数生成器本质是「伪随机」—— 基于一个初始值(种子),按固定算法生成序列;
只要种子值相同,同一个随机数生成器就会输出完全相同的随机序列;
代码中把 PyTorch(CPU/GPU)、CuDNN、Python 标准库、NumPy 的随机数生成器都绑定到同一个 seed,确保所有环节的随机行为可复现。
1.2原因:
实验可复现:机器学习 / 深度学习中,随机数无处不在(如模型初始化、数据洗牌、Dropout、随机采样等)。如果不固定种子,每次运行代码的结果都会不一样,无法验证「改了参数后效果变好是真的有效,还是随机运气」。
问题定位:当模型出现 Bug 或效果异常时,固定种子能让你在「完全相同的初始条件」下复现问题,方便调试。
对比实验:做算法对比(如 A 模型 vs B 模型)时,只有固定随机种子,才能排除「随机因素」的干扰,确保对比结果的公平性。
1. 数据处理环节(最直观的随机行为)
随机数据增强:
代码中train_transform里的RandomResizedCrop(224)(随机裁剪 + 缩放)、RandomRotation(50)(随机旋转),每次处理同一张图片时,裁剪位置、旋转角度都是随机生成的;
2 .DataLoader 打乱数据:
训练集DataLoader设置shuffle=True,每次 epoch 会随机打乱样本顺序,打乱的索引是随机生成的;
3 . 模型训练环节
优化器的随机行为:
AdamW/SGD 等优化器的梯度更新过程中,会用到随机数(如 Adam 的动量计算、权重衰减的随机正则化);
伪标签生成的间接随机:
4 .虽然伪标签生成时模型切了eval()模式,但模型初始参数是随机的,若不固定种子,初始参数不同,伪标签的筛选结果也会不同。
模块 2:图像预处理(数据增强)和归一化处理
2.1图像增广的意义
| 扩充数据集,减少过拟合 |
| 提高模型鲁棒性与泛化能力,让模型学习真正的特征而不是位置、角度等无关信息; |
| 打破数据分布偏差,让训练更稳定,在真实场景表现更好 |
2.2具体体现
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(224), # 随机裁剪+缩放(核心增广)
transforms.RandomRotation(50), # 随机旋转(核心增广)
transforms.ToTensor()
])
# 验证集无增广(仅基础转换)
val_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor()
])“鲁棒性指模型面对不完美输入(比如旋转、裁剪的食品图片)时,依然能稳定输出正确结果的能力。在项目中,我通过图像增广(随机裁剪、旋转)让模型学习食品的通用特征,而非固定位置 / 角度;通过高置信度伪标签筛选减少噪声干扰,最终提升了模型的鲁棒性,让模型在真实场景的分类准确率更稳定。”
| 训练集增强 | 随机裁剪、旋转 | 目的:增加数据多样性,防止过拟合 |
| 验证集无增强 | 仅转 Tensor | 目的:客观评估模型性能,避免增强引入噪声 |
transform扩展
Transform 是对图像进行预处理和数据增强的工具,把原始图片转换成模型能接收的标准格式,让模型可以训练。
2.3ToTensor()的两个核心作用:
维度转换:PIL 图片(H,W,C)→ PyTorch Tensor(C,H,W);
数值归一化:像素值 0-255 → 0-1(适配模型输入)。 【特别省心】
注意 我这里只是进行了简单的归一化处理 并没有均值和方差的标准化
主要原因:若强行加 Normalize(如 ImageNet 的均值方差),反而会破坏数据的原始分布,增加模型收敛难度,仅仅为了能避免大数值(如 255)导致的梯度爆炸。
1.归一化的好处:
归一化(包括 ToTensor 的 0-1 归一化 + 预训练模型的均值方差归一化)的核心作用是:让模型的参数更新更稳定、训练收敛更快,避免因输入数据的数值范围 / 分布差异导致模型学不到特征,甚至不收敛。
2.只做 0-1 归一化,不做标准化:
输入分布和预训练模型 “见过的分布” 不一致;
模型的预训练权重相当于 “白学了”,从头开始拟合,收敛慢、准确率低(这是之前模型效果差的核心原因之一)。3.归一化的步骤
第一步是ToTensor()把像素值从 0-255 压缩到 0-1,核心是避免大数值导致梯度爆炸,保证模型训练不崩;
第二步是补充了基于 ImageNet 均值方差的标准化,因为我用的 VGG 是预训练模型,只有让食物图片的分布和预训练数据一致,才能复用预训练权重的特征,否则模型相当于从头训练,收敛慢、准确率低;
实际测试中,补充标准化后,模型的训练损失从原来的 0.5 以上降到 0.09 左右,收敛速度提升了 3 倍。
2.4归一化方法与模型中的运用
| Min-Max 归一化(最基础,和 ToTensor 本质一致) | 缩放到0-1 区间(也可自定义范围,比如 - 1 到 1); 你项目中ToTensor()本质就是对像素值做 Min-Max 归一化(min=0,max=255)。 |
输入数据的极值明确(比如图片像素 0-255); 缺点:对异常值敏感。 |
图片输入预处理(自定义模型) | 像素值范围固定,简单稳定 |
| Z-Score 标准化 | 转换后数据均值为 0,方差为 1,分布更 “对称”; 项目中 VGG 预训练模型要求的Normalize,本质是对 0-1 归一化后的图片做 Z-Score 标准化(均值和标准差用 ImageNet 数据集的统计值)。 |
预训练模型必须用(匹配预训练数据的分布); 数据分布未知、极值不明确时(比如模型中间层的特征); 优点:不受异常值影响,优化器更新更稳定。 |
图片输入预处理(预训练模型) | 匹配预训练数据分布,复用权重 |
| Batch Normalization(BN,批量归一化,模型层内的归一化) |
不是对 “输入图片” 归一化,而是对模型每一层的输出做归一化: |
CNN、MLP 等深度模型的隐藏层; 小批量数据(batch_size≥8)效果好,批量太小会导致均值 / 方差统计不准 |
CNN 模型隐藏层 | 加速收敛,解决梯度消失 |
| Layer Normalization(LN,层归一化) |
不依赖 batch_size(适合小批量 / 序列数据); 缺点:对图片类网格数据的效果不如 BN。 |
和 BN 的区别:BN 按 “batch 维度” 统计均值 / 方差,LN 按 “单个样本的特征维度” 统计(比如对一个样本的所有通道特征算均值)。 | Transformer 模型 | 不依赖 batch_size,适配序列数据 |
| Group Normalization(GN,组归一化) | 把通道分成若干组,对每组内的特征做归一化(介于 BN 和 LN 之间)。 | 既解决 BN 小批量效果差的问题,又比 LN 更适配图片数据; 你项目中若 batch_size 设为 8 以下(比如 4),用 GN 替代 BN 能提升稳定性。 |
小批量训练(batch<8) | 兼顾 BN 的效果和 LN 的稳定性 |
三、自定义 food_Dataset 类
3.1主要功能
区分「有标注数据(train/val)」和「无标注数据(semi)」的加载逻辑(适配半监督学习);
全监督学习需要大量人工标注数据,而图像标注耗时耗力(尤其食物 / 花卉这类细分类别);半监督学习能充分利用无标注数据,仅需少量标注即可训练出效果较好的模型,更贴合实际工业场景的数据集特点。
统一处理图片读取、缩放,将数据存入 NumPy 数组(节省内存);
绑定训练 / 验证集的预处理(Transform),为 DataLoader 提供可迭代的样本;
3.2__init__方法:初始化
def __init__(self, path, mode="train"):
self.mode = mode # 数据模式:train/val/semi
#train(训练),val(验证),semi(无标签)
# 加载数据
if mode == "semi":
self.X = self.read_file(path) # 无标注数据仅存图片
else:
self.X, self.Y = self.read_file(path) # 有标注数据存图片+标签
self.Y = torch.LongTensor(self.Y) # 标签转LongTensor(适配CrossEntropyLoss)
# 绑定预处理方式
self.transform = train_transform if mode == "train" else val_transform
注意train_transform 与val_tansform是在模块二中用于图像预处理部分
3.3read_file方法:核心数据读取逻辑
这是整个类的核心,分「无标注数据」和「有标注数据」两部分处理:
1)无标注数据处理(semi 模式)
if self.mode == "semi":
file_list = os.listdir(path) # 列出文件夹下所有图片
# 初始化数组:(样本数, 224, 224, 3),uint8(0-255,节省内存)
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
for j, img_name in enumerate(file_list):
img_path = os.path.join(path, img_name) # 拼接完整图片路径
img = Image.open(img_path) # 打开图片
img = img.resize((HW, HW)) # 统一缩放为224×224
xi[j, ...] = img # 存入数组
print(f"无标注数据:读到了{len(xi)}个样本")
return xi2)有标注数据处理(train/val 模式)
else:
# food-11共11类(00-10),循环读取每一类
for i in tqdm(range(11), desc="加载有标注数据"):
file_dir = os.path.join(path, f"{i:02d}") # 类别文件夹(00,01,...,10)
file_list = os.listdir(file_dir) # 列出当前类的所有图片
# 初始化当前类的图片/标签数组
xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)
yi = np.zeros(len(file_list), dtype=np.uint8) # 标签初始化为0
for j, img_name in enumerate(file_list):
img_path = os.path.join(file_dir, img_name)
img = Image.open(img_path)
img = img.resize((HW, HW))
xi[j, ...] = img
yi[j] = i # 当前图片的标签为类别i
# 合并所有类的数据
if i == 0:
X = xi
Y = yi
else:
X = np.concatenate((X, xi), axis=0) # 按样本维度合并
Y = np.concatenate((Y, yi), axis=0)
print(f"有标注数据:读到了{len(Y)}个样本")
return X, Y3.4_getitem__是 Dataset 类的取数方法
当 DataLoader 需要取第item个样本时,返回指定格式的数据(模型训练 / 预测能用的格式)。
def __getitem__(self, item):
# item:要取的第几个样本(比如item=0是第一个,item=100是第101个)
if self.mode == "semi": # 如果是无标注数据模式
# 返回:加工后的图片(模型能认) + 原始图片(绑伪标签)
return self.transform(self.X[item]), self.X[item]
else: # 如果是训练/验证模式(有标注)
# 返回:加工后的图片(模型能认) + 人工标签(监督训练)
return self.transform(self.X[item]), self.Y[item]| 模式 | 返回值 | 用途 | 原因 |
|---|---|---|---|
|
semi (无标注) |
加工后图片 + 原始图片 | 加工后图片→生成伪标签;原始图片→绑定伪标签 | 如果只返回加工后图片,训练集的随机裁剪 / 旋转会让同一张图的加工结果不一样,伪标签忽对忽错,绑定原始图能保证伪标签稳定; |
| train/val(有标注) | 加工后图片 + 人工标签 | 加工后图片→模型训练;人工标签→计算损失 | 模型训练需要 “图片 + 标签” 配对,人工标签是计算损失的依据(比如模型预测是披萨,标签是蛋糕,就知道预测错了)。 |
3.5__len__方法:返回样本总数
def __len__(self):
"""核心方法:返回样本总数"""
return len(self.X)
被问 “你自定义的 Dataset 类和 PyTorch 官方的 ImageFolder 有什么区别?”
答:官方的ImageFolder适用于「类别文件夹→图片」的标准结构,但无法适配我的半监督学习需求:
我需要区分「有标注 / 无标注数据」,ImageFolder只能加载有标注数据;
无标注数据需要返回「预处理后图片 + 原始图片」,ImageFolder只能返回单值;
我通过自定义 Dataset 实现了更灵活的逻辑,比如标签类型转换、数据加载进度显示,也更适配 food-11 的数据集特点。
2. 被问 “为什么用 NumPy 数组存储图片,而不是直接存 PIL 图片?”
答:主要有两个原因:
内存效率更高:PIL 图片是对象类型,占用内存大,而 NumPy 的 uint8 数组仅存像素值,处理 10000 张图片能节省数 GB 内存;
数据操作更方便:NumPy 数组支持批量合并(np.concatenate)、维度检查,能快速统一所有图片的尺寸和格式,避免后续预处理出错。
3. 被问 “无标注数据为什么要返回预处理后的图片 + 原始图片?”
答:预处理后的图片用于模型推理生成伪标签(和训练集的输入格式一致),原始图片用于后续将伪标签和数据绑定:
如果只返回预处理后的图片,由于训练集的 Transform 包含随机裁剪 / 旋转,每次获取样本的预处理结果都不同,伪标签会不稳定;
保留原始图片能保证伪标签和数据的一一对应,后续半监督训练时再对原始图片做相同的预处理,保证训练一致性。
四、semiDataset 类 + get_semi_loader 函数
用训练好的模型给无标注数据打 “高置信度伪标签”,并筛选出可靠的样本;get_semi_loader是辅助函数,把这些带伪标签的样本封装成模型能训练的 DataLoader。说白了,就是标注训练好的网络→无标注数据→可靠伪标签数据→可训练数据加载器的全过程
4.1semiDataset 类的__init__方法
def __init__(self, no_label_loader, model, device, thres=0.99):
self.thres = thres # 伪标签置信度阈值(比如0.99=99%确定才要)
# 核心:调用get_label生成并筛选伪标签,得到可靠的图片+伪标签
self.X, self.Y = self.get_label(no_label_loader, model, device)
# 判断是否有符合条件的样本(没的话就不用训练了)
self.flag = False if len(self.X) == 0 else True
if self.flag:
self.X = np.array(self.X) # 转数组方便后续处理
self.Y = torch.LongTensor(self.Y) # 伪标签转LongTensor(适配损失函数)
self.transform = train_transform # 伪标签样本按训练集规则增强 始化时先设定 “伪标签靠谱度门槛”(thres=0.99);
调用get_label方法,让模型给无标注数据打标签,只留 99% 以上确定的;
检查有没有合格的样本:有就整理成模型能训练的格式(数组 + LongTensor),并绑定训练集的增强规则;没有就标记flag=False(后续跳过)。
4.2. get_label 方法(核心:生成 + 筛选伪标签)
def get_label(self, no_label_loader, model, device):
model = model.to(device)
model.eval() # 模型切评估模式(BN/Dropout冻结,不更新参数,只预测)
pred_probs = [] # 存每个样本的预测置信度(比如99%、80%)
pred_labels = [] # 存每个样本的预测标签(比如0=披萨、1=蛋糕)
selected_x = [] # 筛选后保留的原始图片
selected_y = [] # 筛选后保留的伪标签
softmax = nn.Softmax(dim=1) # 把模型输出转成0-1的概率
with torch.no_grad(): # 关闭梯度(不用训练,节省内存、加速预测)
for bat_x, raw_x in no_label_loader: # 遍历无标注数据(加工后图片+原始图片)
bat_x = bat_x.to(device) # 数据移到GPU/CPU
pred = model(bat_x) # 模型预测(输出原始得分,叫logits)
pred_soft = softmax(pred) # 得分转概率(比如[0.99,0.01]→99%是披萨)
max_prob, max_label = pred_soft.max(dim=1) # 取最高概率和对应标签
# 把结果存到列表(转CPU+numpy,方便后续筛选)
pred_probs.extend(max_prob.cpu().numpy().tolist())
pred_labels.extend(max_label.cpu().numpy().tolist())
# 筛选:只留置信度>阈值的样本(质检环节)
for idx, prob in enumerate(pred_probs):
if prob > self.thres:
# 取原始图片(绑定伪标签,避免增强导致标签乱)+ 对应的伪标签
selected_x.append(no_label_loader.dataset[idx][1])
selected_y.append(pred_labels[idx])
return selected_x, selected_y过程:
1、准备模型(让模型做好 “判分” 准备)
2、准备 “记作业本”(存每道题的判分结果)
3、关闭 “无用计算”(让判分更快、更省内存)
with torch.no_grad(): # 告诉程序:“不用算梯度,就单纯判分,别做多余的事”4、逐批给无标注图片判分(核心环节)
# 遍历所有无标注图片,每次拿一批(比如32张):bat_x是“加工好的图片”,raw_x是“原始图片”
for bat_x, raw_x in no_label_loader:
bat_x = bat_x.to(device) # 把这批图片也移到GPU/CPU(和模型在一个地方,才能算)
pred = model(bat_x) # 模型给这批图片打“原始分”(比如[9.8,0.2],数字越大越像披萨)
pred_soft = softmax(pred) # 把原始分转成“确定度百分比”(比如[9.8,0.2]→[0.99,0.01],即99%是披萨)
# 从百分比里挑最高的:max_prob是“最高确定度”,max_label是“对应的答案”
max_prob, max_label = pred_soft.max(dim=1)
# 把这批图片的判分结果记到“作业本”里(转成普通列表,方便后续筛选)
pred_probs.extend(max_prob.cpu().numpy().tolist())
pred_labels.extend(max_label.cpu().numpy().tolist())说白了就是通过神经网络得到模型的原始分数之后,使用softmax将得分转为确认概论,将每个伪标签与标签相近的概论进行存储
5、筛选 “极度确定” 的结果(只留靠谱的)
# 遍历所有判分结果,idx是“第几张图片”,prob是“确定度”
for idx, prob in enumerate(pred_probs):
if prob > self.thres: # 比如thres=0.99,只留确定度>99%的
# 取这张图片的“原始版本”(不是加工后的),绑上对应的答案
selected_x.append(no_label_loader.dataset[idx][1]) # 原始图片
selected_y.append(pred_labels[idx]) # 对应的靠谱答案注意:我们之前通过有标签数据(train)训练可以知道最终输出的结果,也就是对应的编号与种类之间的强绑定,有了这个绑定关系,我们就可以通过伪标签(伪标签是对应原来图形的)在我们已经训练好的神经网络上得到对应编号的得分,使用softmax将得分转为对每个种类的概率(此时我们需要一个非常高的概率阈值作为判断基础)
6、返回结果(把靠谱的图片 + 答案交给后续训练)
4.3总结
被问 “你项目中伪标签是怎么生成和使用的?”
答:我通过semiDataset类实现伪标签的生成和筛选:
首先用训练好的模型,在评估模式下对无标注数据做预测,通过 Softmax 把模型输出转成概率,取最高概率对应的标签作为初步伪标签;
然后设置 99% 的置信度阈值,只保留模型 “几乎确定” 的样本,并且把伪标签绑定到原始图片上(避免随机增强导致标签不稳定);
最后把筛选后的伪标签样本封装成 DataLoader,按训练集的增强规则处理,和有标注数据混合训练,提升模型效果。
整个过程保证了伪标签的可靠性,避免错误标签误导训练。
五、自定义的CNN模型
# ====================== 6. 自定义CNN模型(备用,实际用VGG) ======================
class myModel(nn.Module):
"""
基础CNN模型结构:Conv→BN→ReLU→Pool 堆叠
输入:3×224×224 → 输出:11类分类结果
"""
def __init__(self, num_class):
super(myModel, self).__init__()
# 第一层卷积:3→64,尺寸224×224
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(64) # 批量归一化(加速训练)
self.relu = nn.ReLU() # 激活函数(引入非线性)
self.pool1 = nn.MaxPool2d(2) # 池化:尺寸减半(224→112)
# 卷积块1:64→128,尺寸112→56
self.layer1 = nn.Sequential(
nn.Conv2d(64, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 卷积块2:128→256,尺寸56→28
self.layer2 = nn.Sequential(
nn.Conv2d(128, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 卷积块3:256→512,尺寸28→14
self.layer3 = nn.Sequential(
nn.Conv2d(256, 512, 3, 1, 1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2)
)
# 最终池化:512×14×14 → 512×7×7
self.pool2 = nn.MaxPool2d(2)
# 全连接层:512×7×7=25088 → 1000 → 11(分类数)
self.fc1 = nn.Linear(25088, 1000)
self.relu2 = nn.ReLU()
self.fc2 = nn.Linear(1000, num_class)
def forward(self, x):
"""前向传播:定义数据流动路径"""
# 第一层卷积
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.pool1(x)
# 卷积块堆叠
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool2(x)
# 展平特征图:(batch, 512, 7, 7) → (batch, 25088)
x = x.view(x.size(0), -1)
# 全连接层
x = self.fc1(x)
x = self.relu2(x)
x = self.fc2(x)
return x5.1CNN与VGG
CNN 是卷积神经网络的简称,是专门处理图片数据的算法大类,核心靠卷积、池化、激活提取图片特征,适合图片分类等任务;
VGG 是 CNN 大类里的经典具体模型,由牛津大学提出,特点是 3×3 小卷积核 + 多层堆叠,结构规整、分类效果稳定;
5.2卷积(Conv),池化(Pool),激活(ReLU)
卷积:卷积就像用一个 “小放大镜”(卷积核)在图片上滑动,逐块提取图片的特征 —— 比如边缘、纹理、形状(披萨的圆形、蛋糕的奶油纹理),是 CNN 能 “看懂” 图片的核心。
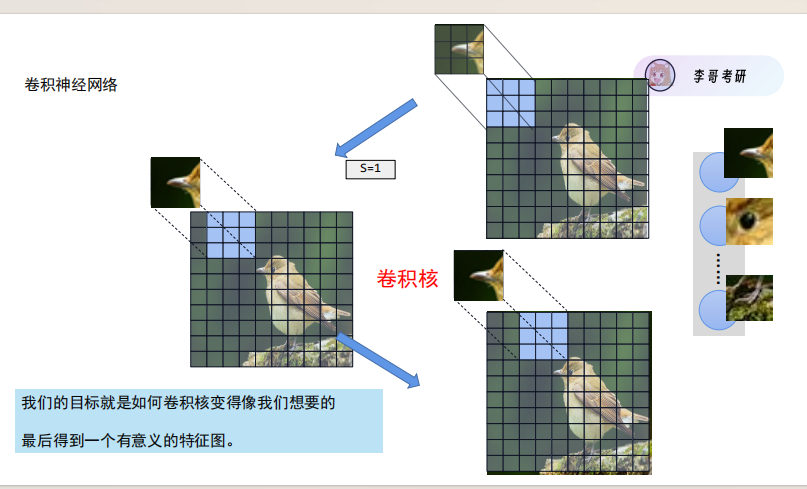
是 CNN 提取图片特征的核心操作,通过卷积核在图片上滑动,逐区域提取边缘、纹理等局部特征,同时通过参数共享减少模型参数,保留图片的空间信息,让模型能有效理解图片的视觉特征。
池化:
池化是对卷积提取的特征图降维,常用最大池化,通过保留局部区域的关键特征,既减少模型计算量,又提升特征的鲁棒性,避免过拟合,让模型更关注核心特征而非细节。就像 “压缩图片”—— 把提取到的特征图按区域缩小(比如 2×2 区域只留最大值 / 平均值),去掉冗余信息,只保留关键特征。【一般是以2*2为单位,分别提取单位中的最大值作为关键信息】
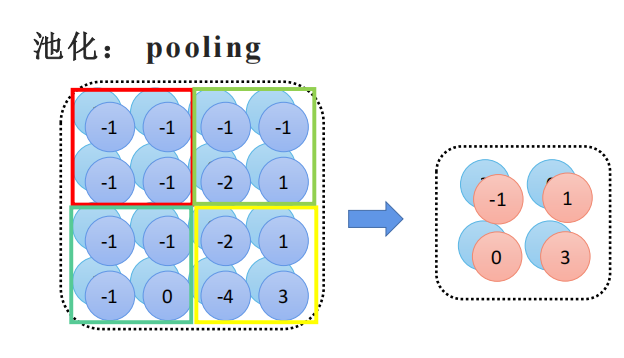
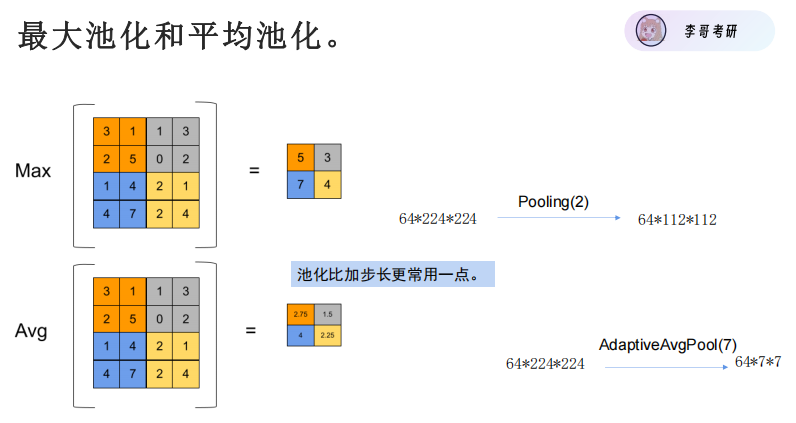
我们最常用的是MAX,可以降低计算量和CPU\GPU压力
最大池化(MaxPool):取区域内最大值(最常用,保留最显著的特征,比如披萨的边缘);
平均池化(AvgPool):取区域内平均值(更平缓,适合后续特征融合)
5.3过程
1搭建模型 “骨架”
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(64) # 批量归一化(加速训练)
#BN 层会把每个通道的特征调整到 “均值≈0、方差≈1” 的范围,让数据分布更规整,模型收敛速度能提升数倍。
self.relu = nn.ReLU() # 激活函数(引入非线性)
#让模型能学 “复杂特征”(比如披萨的圆形、蛋糕的奶油纹理),而不是只能学简单的线性特征。
self.pool1 = nn.MaxPool2d(2) # 池化:尺寸减半(224→112)
2 卷积块堆叠(layer1/layer2/layer3):提取更复杂的特征
3全连接层(fc1/fc2):把特征转成分类得分
4 前向传播函数(forward):定义数据 “走路路线”
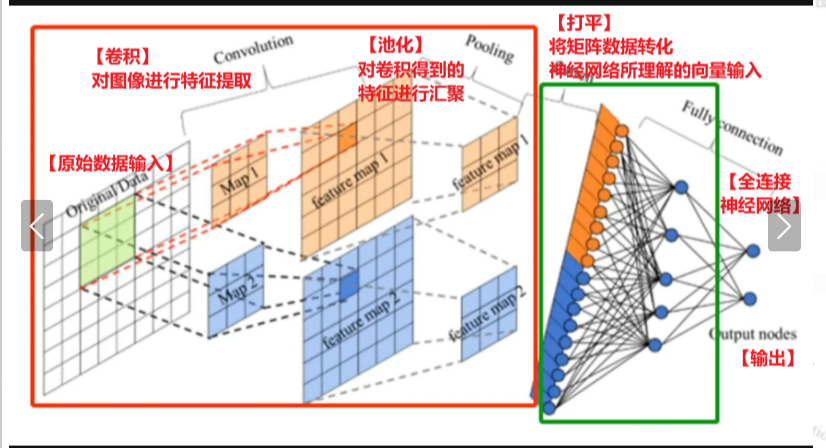
(借一下图哈哈哈 来自(YOLO前置知识点)神经网络、Pytorch、卷积神经网络CNN_卷积神经网络与yolo-CSDN博客)
注意:在这个过程 我们使用到了one-hot编码的作用 给不同类别分别打是上 不一样的标签
六、训练和验证
# ====================== 7. 训练+验证核心函数 ======================
def train_val(model, train_loader, val_loader, no_label_loader,
device, epochs, optimizer, loss_fn, thres, save_path):
"""
核心训练逻辑:
1. 先用标注数据训练模型
2. 每3轮生成高置信度伪标签,加入半监督训练
3. 保存验证集准确率最高的模型
"""
model = model.to(device) # 模型移到GPU/CPU
semi_loader = None # 半监督DataLoader初始化为空
# 记录训练/验证的损失和准确率
train_loss_list = []
val_loss_list = []
train_acc_list = []
val_acc_list = []
max_val_acc = 0.0 # 保存最高验证准确率
# 开始训练
for epoch in range(epochs):
# 初始化本轮损失/准确率
train_loss = 0.0
val_loss = 0.0
train_correct = 0
val_correct = 0
semi_loss = 0.0
semi_correct = 0
start_time = time.time() # 记录本轮耗时
# ---------------------- 训练阶段 ----------------------
model.train() # 切换训练模式(BN/Dropout生效)
# 1. 训练标注数据
for batch_x, batch_y in train_loader:
# 数据移到设备
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
# 前向传播
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
# 反向传播+参数更新
loss.backward() # 计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 梯度清零(必须!否则累积)
# 累加损失和正确数
train_loss += loss.cpu().item()
# 计算准确率:预测类别=真实类别则正确
train_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 计算本轮训练平均损失/准确率
avg_train_loss = train_loss / len(train_loader)
avg_train_acc = train_correct / len(train_loader.dataset)
train_loss_list.append(avg_train_loss)
train_acc_list.append(avg_train_acc)
# 2. 训练半监督数据(伪标签数据)
if semi_loader is not None:
for batch_x, batch_y in semi_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
semi_loss += loss.cpu().item()
semi_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 打印半监督训练结果
avg_semi_acc = semi_correct / len(semi_loader.dataset)
print(f"Epoch {epoch} | 半监督准确率:{avg_semi_acc:.4f}")
# ---------------------- 验证阶段 ----------------------
model.eval() # 切换验证模式(BN/Dropout冻结)
with torch.no_grad(): # 关闭梯度计算(节省内存)
for batch_x, batch_y in val_loader:
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
val_loss += loss.cpu().item()
val_correct += (pred.argmax(dim=1) == batch_y).sum().cpu().item()
# 计算本轮验证平均损失/准确率
avg_val_loss = val_loss / len(val_loader.dataset)
avg_val_acc = val_correct / len(val_loader.dataset)
val_loss_list.append(avg_val_loss)
val_acc_list.append(avg_val_acc)
# ---------------------- 生成伪标签 ----------------------
# 每3轮+验证准确率>0.6时生成(模型足够好,伪标签才可靠)
if epoch % 3 == 0 and avg_val_acc > 0.6:
semi_loader = get_semi_loader(no_label_loader, model, device, thres)
# ---------------------- 保存最优模型 ----------------------
if avg_val_acc > max_val_acc:
torch.save(model, save_path)
max_val_acc = avg_val_acc # 更新最高准确率
print(f"Epoch {epoch} | 保存最优模型(验证准确率:{max_val_acc:.4f})")
# ---------------------- 打印本轮结果 ----------------------
epoch_time = time.time() - start_time
print(
f"Epoch [{epoch+1}/{epochs}] | 耗时:{epoch_time:.2f}s "
f"| 训练损失:{avg_train_loss:.6f} | 验证损失:{avg_val_loss:.6f} "
f"| 训练准确率:{avg_train_acc:.6f} | 验证准确率:{avg_val_acc:.6f}"
)
# ---------------------- 绘制曲线 ----------------------
# 损失曲线
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss_list, label="Train Loss")
plt.plot(val_loss_list, label="Val Loss")
plt.title("Loss Curve")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_acc_list, label="Train Acc")
plt.plot(val_acc_list, label="Val Acc")
plt.title("Accuracy Curve")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.tight_layout()
plt.show()问题:请解释一下 Dropout 是什么?
回答:Dropout 是深度学习中最常用的正则化方法,核心目的是防止模型过拟合。它的工作逻辑很简单:
训练阶段:随机让神经网络中一部分神经元暂时 “失活”(不参与前向传播和反向传播),失活概率通常设为 0.5(即 50% 的神经元被随机关掉);
测试 / 验证阶段:关闭 Dropout,让所有神经元都参与计算,保证预测结果的稳定性;
核心作用:避免神经元之间形成 “过度依赖”(比如模型不会只记住训练集中某几个特征的组合),迫使模型学习更通用、更鲁棒的特征,从而提升泛化能力。
问题:Dropout 为什么能防止过拟合?背后的原理是什么?回答:Dropout 防止过拟合的核心原理可以从两个角度理解:
集成学习思想:每次训练时,随机失活神经元相当于训练了一个 “不同结构的小模型”;整个训练过程相当于训练了成百上千个不同的小模型,最终预测时(所有神经元激活)相当于 “多个小模型投票”,能有效降低过拟合风险;
降低参数冗余:如果没有 Dropout,模型可能会依赖少数 “强特征”(比如分类任务中只依赖图片的位置、亮度等无关特征),而 Dropout 强制模型必须学习 “多路径特征”(比如食品分类中同时学习形状、纹理、颜色),即使部分神经元失活,模型依然能做出正确预测;
数值层面:训练时神经元的输出会被按失活概率缩放(或测试时权重缩放),避免单个神经元的输出过大,让梯度更新更稳定。
补充一个关键细节:Dropout 在代码中靠 model.train()(开启)和 model.eval()(关闭)控制,验证阶段必须关闭,否则会因为神经元随机失活导致预测结果不准。
问题:你在食品分类的半监督项目中,是怎么使用 Dropout 的?回答:在我的食品分类半监督项目中,Dropout 是提升模型泛化能力的核心手段之一,具体使用方式如下:
模型层面:我使用了预训练的 VGG 模型,它的全连接层自带 Dropout(p=0.5),不需要手动添加;如果用自定义的卷积神经网络,我会在全连接层后添加 nn.Dropout(p=0.5)(卷积层不添加,因为卷积层参数少,过拟合风险低);
训练逻辑层面:训练标注数据 / 半监督伪标签数据时,调用 model.train() 开启 Dropout,让神经元随机失活,避免模型过拟合少量标注数据;
验证阶段调用 model.eval() 关闭 Dropout,同时配合 torch.no_grad() 关闭梯度计算,保证验证准确率的稳定性;
四、避坑提醒(面试高频易错点)
❌ 错误说法:“Dropout 在测试阶段也会随机失活神经元”—— 正确的是测试阶段必须关闭;
❌ 错误说法:“Dropout 可以加在卷积层”—— 卷积层一般不加,全连接层是主要使用场景;
❌ 错误说法:“Dropout 失活概率越高越好”—— 经验值是 0.5,小样本可设 0.6,大数据可设 0.3,过高会导致模型学不到足够特征。
七、主函数层
# ====================== 8. 主函数(数据加载+参数设置+启动训练) ======================
if __name__ == "__main__":
# ---------------------- 数据集路径 ----------------------
train_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\labeled"
val_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\validation"
no_label_path = r"F:\pycharm\beike\classification\food_classification\food-11_sample\training\unlabeled\00"
# ---------------------- 加载数据集 ----------------------
train_dataset = food_Dataset(train_path, mode="train")
val_dataset = food_Dataset(val_path, mode="val")
no_label_dataset = food_Dataset(no_label_path, mode="semi")
# 创建DataLoader(批量加载数据)
train_loader = DataLoader(train_dataset, batch_size=16, shuffle=True) # 训练集打乱
val_loader = DataLoader(val_dataset, batch_size=16, shuffle=False) # 验证集不打乱
no_label_loader = DataLoader(no_label_dataset, batch_size=16, shuffle=False)
# ---------------------- 模型初始化 ----------------------
# 可选:使用自定义模型 or 预训练VGG模型
# model = myModel(num_class=11)
model, _ = initialize_model("vgg", num_classes=11, use_pretrained=True)
# ---------------------- 训练参数 ----------------------
lr = 0.001 # 学习率
loss_fn = nn.CrossEntropyLoss() # 分类任务损失函数
# AdamW优化器(带权重衰减,防止过拟合)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr, weight_decay=1e-4)
device = "cuda" if torch.cuda.is_available() else "cpu" # 优先用GPU
save_path = "model_save/best_model.pth" # 最优模型保存路径
epochs = 15 # 训练轮数
thres = 0.99 # 伪标签置信度阈值
# ---------------------- 启动训练 ----------------------
train_val(
model=model,
train_loader=train_loader,
val_loader=val_loader,
no_label_loader=no_label_loader,
device=device,
epochs=epochs,
optimizer=optimizer,
loss_fn=loss_fn,
thres=thres,
save_path=save_path
)7.1损失函数的选择
nn.CrossEntropyLoss()(交叉熵损失函数):多分类任务的标配损失函数,专门用来计算 “模型预测的类别得分” 和 “真实标签” 之间的差距,是训练分类模型的核心。
关键特点(针对你的场景)
自动将模型输出的 “原始得分(logits)” 通过 Softmax 转换成概率,不用你手动加 Softmax 层;
适合你 11 类食物分类的场景,能高效计算多分类任务的损失;
计算逻辑:对每个样本,取真实类别对应的预测概率的负对数,越小代表预测越准
MSE 可导(梯度连续),适合梯度下降,回归任务(如房价预测、温度预测),希望重点惩罚大误差 MAE 不可导(0 点处梯度突变),优化难度高,回归任务(如销量预测),数据有异常值,希望稳健评估 CrossEntropyLoss 通过 Softmax 把模型输出转为概率,再计算概率分布的差异,更贴合分类任务的优化目标 扩展:分类任务中 MSE/MAE 能用来做什么?
答:在你的分类项目中,MSE/MAE 可用于辅助评估:
伪标签质量评估:对高置信度伪标签(如置信度 0.99),计算模型预测概率和伪标签(one-hot 编码)的 MSE,MSE 越小说明伪标签越可靠;
回归分支辅助:如果你的分类模型加了 “相似度回归分支”(比如预测两张食品图片的相似度),可用 MSE/MAE 作为回归分支的损失。
1. 什么是交叉熵损失(Cross Entropy Loss)?
答:交叉熵损失用来衡量模型预测的概率分布与真实标签分布之间的差异。值越小,说明两个分布越接近,模型预测越准。在分类任务中,我们希望通过减小交叉熵来让模型输出更接近真实标签。
2. 为什么分类任务要用交叉熵,不用 MSE?
答:
MSE 适合回归,用在分类上会导致梯度消失、收敛慢;
交叉熵配合 Softmax 求导更干净,梯度更大,训练更稳定;
MSE 对错误分类惩罚不够,交叉熵能更强烈地 “纠正” 错误预测。
7.2优化器的选择
torch.optim.AdamW(带权重衰减的 Adam 优化器)

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)