大模型分布式训练:DP、TP、PP 三大并行策略通俗讲解
多张 GPU 分工协作。本文用类比的方式,把三种最核心的并行策略讲清楚。
先搞清楚:GPU 显存里到底存了什么?
很多人以为训练模型只需要存「模型参数」,其实不止。训练时显存里住着三类居民:
| 居民 | 说明 | 占用大小 |
|---|---|---|
| 参数(Parameters) | 模型的权重矩阵 | 1x |
| 梯度(Gradients) | 反向传播算出来的更新量 | 1x |
| 优化器状态(Optimizer States) | 以 Adam 为例,每个参数还要存两个历史统计量(一阶矩 + 二阶矩) | 2x |

💡 还有一类容易被忽视的:激活值(Activations)
前向传播时每一层的中间计算结果,反向传播求梯度时要用到,所以必须暂存。
激活内存的大小跟 batch size 和序列长度成正比——序列一>长、batch 一>大,激活内存甚至比参数本身还大。

策略一:数据并行(Data Parallelism, DP)
核心思路
“模型复制,数据分片”——每张 GPU 上都放一份完整的模型,但每张卡只处理一部分训练数据。
用工厂流水线打比方:
🏭 你有 4 条一模一样的生产线(4 张 GPU),每条线上有完整的生产设备(完整模型)。
今天有 1000 个订单(训练数据),每条线负责处理 250 个。
下班前(每个 step 结束)4 条线开个会,把各自的改进经验(梯度)汇总平均,统一更新设备。
这个"汇总梯度"的步骤叫做 All-Reduce 操作:每张卡把自己算出的梯度发给其他所有卡,所有卡对梯度求平均,保证 4 张卡上的模型副本始终保持一致。
优缺点
✅ 实现简单,几乎所有框架都原生支持
✅ 适用于各种模型架构
❌ 每张卡都要存完整模型——模型太大、单卡放不下时直接失效
❌ GPU 数量增多后,通信开销会成为瓶颈
ZeRO 优化
为了解决"每卡都存完整模型太浪费"的问题,微软提出了 ZeRO(Zero Redundancy Optimizer)。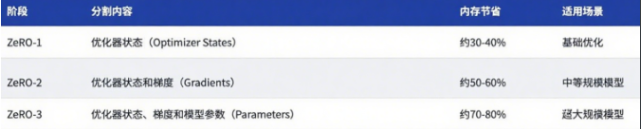
ZeRO 的思路是:把参数、梯度、优化器状态切碎,分散存到各卡上,需要用哪张卡的参数时,临时通过 All-Gather 广播过来,用完立刻丢掉。
普通 DP(8 张卡):
每张卡存完整的 112GB → 显存爆炸 💥
ZeRO-3(8 张卡):
每张卡只存 112GB ÷ 8 = 14GB → 轻松装下 ✅
代价:需要频繁的卡间通信来临时凑齐参数
📚 ZeRO 像图书馆借书——书分散在各分馆,你需要哪本就借来用完还回去。
策略二:张量并行(Tensor Parallelism, TP)
核心思路
数据并行解决了"数据太多"的问题,但解决不了"激活内存太大"的问题。张量并行的思路是:把模型内部的矩阵运算本身切开,分给多张卡并行计算。一个矩阵乘法A×B可以通过分别计算B的每一列或A的每一行,然后组合结果来完成。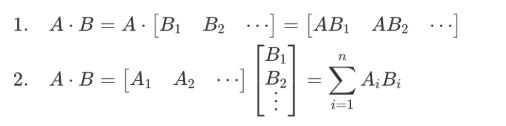
数学依据是矩阵乘法的可切分性:
Y = X · W
可以切成:
GPU0:Y₀ = X · W₀ (W 的前半部分列)
GPU1:Y₁ = X · W₁ (W 的后半部分列)
最后:Y = [Y₀, Y₁] 拼起来就是完整结果
以 Transformer 的 MLP 层为例:
- 第一个线性层:按列切分,每张卡负责计算输出的一部分
- 第二个线性层:按行切分,每张卡拿到上一步的部分结果直接算
- 算完之后做一次 All-Reduce,把各卡的结果加在一起
为什么张量并行不能跨节点用?
每算完一层就必须做一次同步通信,这个通信是阻塞式的——所有卡必须等通信完才能继续算。
节点内(NVLink): 带宽 ≈ 600 GB/s → 每次通信约 3ms,感觉不到
跨节点(网络): 带宽 ≈ 25 GB/s → 每次通信约 80ms,GPU 全在等!
三种关键通信原语
理解张量并行绕不开这三个概念:
| 通信原语 | 描述 | 类比 |
|---|---|---|
| Broadcast(广播) | 一张卡的数据发给所有卡 | 老师把答案念给全班同学 |
| All-Gather(全聚合) | 每张卡把自己那份发给所有人,最终每卡都有完整数据 | 全班同学互相抄笔记,最后每人都有完整答案 |
| Reduce-Scatter(散播归约) | 先对所有卡的数据求和,再把结果切分散发,每卡只拿到一段 | 全班成绩加总后,班长只负责记前10名,副班长记后10名 |
Broadcast(广播)
一张卡 → 所有卡,其他卡被动接收。
操作前:
GPU0: [A] GPU1: [?] GPU2: [?] GPU3: [?]
操作后(GPU0 广播):
GPU0: [A] GPU1: [A] GPU2: [A] GPU3: [A]
场景:把某个参数的最新值同步给所有卡。
All-Gather(全聚合)
每张卡都把自己的数据发给所有人,最后每张卡都拼接成完整数据。
操作前(每张卡只有一块):
GPU0: [A] GPU1: [B] GPU2: [C] GPU3: [D]
操作后(每张卡都有完整数据):
GPU0: [A,B,C,D] GPU1: [A,B,C,D] GPU2: [A,B,C,D] GPU3: [A,B,C,D]
场景:ZeRO-3 中,每张卡只存了部分参数,需要某层完整参数时用 All-Gather 临时凑齐。
Reduce-Scatter(散播归约)
先对所有卡的数据求和,再把结果切分散发,每张卡只得到求和结果的一部分。
操作前(每张卡都有完整数据):
GPU0: [A0,B0,C0,D0]
GPU1: [A1,B1,C1,D1]
GPU2: [A2,B2,C2,D2]
GPU3: [A3,B3,C3,D3]
操作后(求和 + 切分):
GPU0: [A0+A1+A2+A3] ← 只拿第一块的和
GPU1: [B0+B1+B2+B3] ← 只拿第二块的和
GPU2: [C0+C1+C2+C3]
GPU3: [D0+D1+D2+D3]
场景:反向传播时每张卡算出了自己的梯度,用 Reduce-Scatter 把梯度加起来,每张卡只负责存自己那份(ZeRO-2 就是这么做的)。
三者关系
All-Gather = Broadcast 的多对多版本(主动的,每人都发)
All-Reduce = Reduce-Scatter + All-Gather(先归约再广播,每人得到完整求和结果)
Transformer 有几十上百层,每层都卡一次,GPU 利用率直接崩掉。
💡 实践建议:TP 度数一般设为 2、4、8;优先在单机 8 卡内使用;配合流水线并行效果更好。
策略三:流水线并行(Pipeline Parallelism, PP)
核心思路
“把模型按层切开,每张卡只负责几层,数据像工厂流水线一样依次流过”。
GPU0:负责 layer 1~8
GPU1:负责 layer 9~16
GPU2:负责 layer 17~24
GPU3:负责 layer 25~32
数据流向:
输入 → GPU0 算完 → 把激活值传给 GPU1 → GPU1 算完 → 传给 GPU2 → ...
🏭 就像汽车装配线:第一组工人装发动机,第二组装车身,第三组装内饰。每组只需要自己那套工具,不需要其他组的设备。
气泡问题
朴素的流水线有个致命缺陷:GPU 空闲等待(气泡)。
时间轴 →
GPU0:[前向传播] [等] [等] [反向传播]
GPU1:[等] [前向] [等] [反向]
GPU2:[等] [等] [前向] [反向]
GPU0 算完前向就要等 GPU1、GPU2 都算完,然后才能开始反向传播,大量时间在空转。
解决方案:微批次(Micro-batch)
把一个大批次切成多个小批次,让 GPU 交错执行,填补空闲时间:
时间轴 →
GPU0:[MB1-前向][MB2-前向][MB3-前向][空闲][MB1-反向][MB2-反向][MB3-反向]
GPU1:[等 ][MB1-前向][MB2-前向][MB3-前向][MB1-反向][MB2-反向][MB3-反向]
GPU2:[等 ][等 ][MB1-前向][MB2-前向][MB3-前向][MB1-反向][MB2-反向]
微批次数越多,气泡占比越小,GPU 利用率越高。
优缺点
✅ 通信开销低(只在相邻层之间传激活值)
✅ 显存占用显著降低(每卡只存几层的参数)
❌ 气泡问题无法完全消除
❌ 存在木桶效应,最慢的那张卡决定整体速度
❌ 需要合理切分层数以保证负载均衡
三种策略对比总结
| DP 数据并行 | TP 张量并行 | PP 流水线并行 | |
|---|---|---|---|
| 切分对象 | 训练数据 | 矩阵运算(层内) | 模型层数(层间) |
| 每卡存什么 | 完整模型 | 部分权重矩阵 | 几层的完整参数 |
| 解决的问题 | 加速训练、扩展数据量 | 激活内存过大 | 模型整体放不下 |
| 通信类型 | All-Reduce(梯度同步) | All-Gather / Reduce-Scatter(频繁) | 点对点传激活值(少) |
| 跨节点效果 | ✅ 较好 | ❌ 很差(带宽瓶颈) | ✅ 较好 |
| 主要副作用 | 每卡存完整模型 | 必须节点内使用 | 流水线气泡 |
实践中怎么选?
一句话原则:按问题选策略,组合使用效果最好。
- 先上数据并行:最简单,先跑起来
- 模型单卡放不下 → 加流水线并行(PP),把层分到多卡
- 激活内存爆显存 → 加张量并行(TP),在单机内切矩阵
- 三者叠加(3D并行)是目前训练超大模型的主流方案
优化是系统工程,没有银弹。理解每种策略的本质,结合自己的硬件条件和模型架构,多测试才能找到最优配置。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)