五、训练流程
训练流程
大模型的训练是一个复杂而精细的过程,涉及众多超参数的选择与调整、优化策略的运用以及工程实践的考量。本章将按照训练的实际流程,从超参数设定、前向与反向传播、优化器与学习率调度,到梯度裁剪与正则化,逐一详解。
1 超参数设定
超参数是训练前需要手动配置的参数,它们直接影响模型的收敛速度、最终性能和稳定性。
模型参数:模型自己学出来的(权重、偏置)
超参数:训练前人手动设的,控制训练过程
1.1 批次大小(Batch Size)
批次大小指每次参数更新所使用的样本数量。它受限于 GPU 显存,并影响训练动态。
数据集:[样本1, 样本2, 样本3, 样本4, 样本5, 样本6, 样本7, 样本8]
Batch Size = 2
一次只喂 2 个样本 → 算一次梯度 → 更新一次参数
第1步:[1,2] → 梯度 → 更新
第2步:[3,4] → 梯度 → 更新
第3步:[5,6] → 梯度 → 更新
第4步:[7,8] → 梯度 → 更新
===================================================================
Batch Size = 4
一次喂 4 个样本
第1步:[1,2,3,4] → 梯度 → 更新
第2步:[5,6,7,8] → 梯度 → 更新
显存限制与梯度累积:单卡显存无法容纳大批次时,可采用梯度累积(Gradient Accumulation)。即多次前向-反向传播计算梯度,将梯度累加,达到累积步数后再统一更新参数。这样,有效批次大小 = 单卡批次 × 卡数 × 累积步数。
单卡 Batch = 2
累积步数 = 3
第1次前向反向:梯度1
第2次前向反向:梯度2
第3次前向反向:梯度3
→ 把梯度1+2+3 累加
→ 一次性更新参数
单卡 + 梯度累积
单卡批次:2
显卡数量:1
累积步数:4
有效批次 = 2 × 1 × 4 = 8
分布式训练(多卡)
单卡批次:8
显卡:4 张
累积步数:2
有效批次 = 8 × 4 × 2 = 64
影响:大批次可提高训练稳定性,加速收敛(因梯度估计更准确),但可能降低泛化能力(尤其是超过某个阈值时)。对于大模型,常用有效批次大小为 0.5M~4M tokens(如 GPT-3 使用 3.2M tokens 的批次)。
大批次
梯度更准
训练更稳
收敛更快
太大 → 泛化变差
小批次
噪声大
震荡多
泛化通常更好
太小 → 难收敛
实践建议:在分布式训练中,常通过调整梯度累积步数来灵活控制有效批次,同时保持单卡批次较小(如 1~8 个序列)以降低显存压力。
大模型常用有效批次:0.5M~4M tokens
如 GPT-3:3.2M tokens
单卡批次设小:1~8 条序列
用梯度累积把有效批次拉大
小结
Batch Size:一次更新用多少样本
显存不够 → 梯度累积
有效批次 = 单卡批次 × 卡数 × 累积步数
大模型:小单卡批次 + 大累积步数
2 序列长度(Sequence Length)
序列长度指每个训练样本的 token 数量。它影响模型能处理的上下文窗口和计算复杂度。
我 喜欢 用 AI 学习 大模型
↓
token: [我, 喜欢, 用, AI, 学习, 大模型]
序列长度 n = 6
==============================================
模型一次只吃一整段固定长度的 token 串
[token1, token2, ..., token_n]
↑
序列长度 n
典型范围:512~2048,但近期模型如 GPT-4、Claude 支持更长(如 32k、128k),这需要通过序列并行、稀疏注意力等技术实现。
序列长度决定:上下文窗口
序列长度 = 模型能 “记住” 的最大上下文长度。
动态调整:为高效训练,可采用两阶段策略:前期使用较短序列(如 512)加速收敛,后期逐渐增加长度(如 2048)以适应长上下文。例如,LLaMA 训练时逐步将序列长度从 512 增加到 2048。
上下文窗口 = 序列长度 n
用户输入 + 模型输出 总共不能超过 n 个 token
eg:
Sequence Length = 2048→ 最多只能处理 2048 个 token 的对话 / 文章
计算复杂度:Transformer 的自注意力复杂度是 O(n²),因此长序列会显著增加计算和显存开销、训练 / 推理变慢、成本大幅增加;
n=2 → 2×2=4 次计算
n=4 → 4×4=16 次计算
n=8 → 8×8=64 次计算
...
n=2048 → 2048×2048 ≈ 400万 次计算
2.1 怎么支撑长序列训练:
序列并行(Sequence Parallel)、稀疏注意力(Sparse Attention)、滑动窗口注意力、分页注意力(Paged Attention)
2.2 动态调整策略
前期短序列 → 后期长序列
1)前期训练
序列长度:512
速度快,收敛快
先让模型学会语言规律
2)后期训练
慢慢拉长到:1024 → 2048
让模型适应长上下文
eg:llama
开始:Sequence Length = 512
中期:慢慢升到 1024
结束:固定在 2048
小结
Sequence Length = 一个样本的 token 数量
决定上下文窗口大小
Transformer 复杂度 O(n²),越长越贵
大模型常用:512~2048,高级可达 32k~128k
训练技巧:先短后长,动态调整
3 学习率(Learning Rate)
学习率控制参数更新的步长,是关键的优化超参数之一;
学习率 = 模型更新参数时的 “步子大小”,学习率决定每次更新,权重改多少。
学习率小:步子小,走得慢,稳,但容易卡在局部最优。
学习率大:步子大,走得快,但容易震荡、不收敛、直接炸掉。
学习率怎么起作用
参数更新公式:新权重 = 旧权重 - 学习率 * 梯度
例子 1:学习率太小
学习率 = 0.00001
梯度 = 100更新量 = 0.00001 × 100 = 0.001→ 几乎不动,训练极慢。
例子 2:学习率太大
学习率 = 10
梯度 = 100更新量 = 10 × 100 = 1000→ 权重跳变巨大,直接训崩(loss 飙升、NaN)。
例子 3:学习率合适
学习率 = 0.0001
梯度 = 100更新量 = 0.0001 × 100 = 0.01→ 稳步下降,收敛又稳又快。
典型值:大模型训练通常使用较小学习率,如 1e-4 到 1e-5。例如,GPT-3 使用 6e-5,LLaMA 使用 1.5e-4(经过预热后)。
学习率调度:单纯固定学习率难以达到最佳效果,需配合调度策略。
缩放规律:学习率与批次大小通常遵循线性缩放法则:当批次大小增大 k 倍时,学习率也应大致增大 √k 倍或线性增大(具体取决于优化器)。但过大学习率易导致训练不稳定。
两种常用缩放:
线性缩放 : 批次 ×k → 学习率 ×k
平方根缩放 : 批次 ×k → 学习率 ×√k
eg:
Batch Size = 1024 、 LR = 1e-4
现在把批次扩大 4 倍:Batch Size = 4096
线性缩放:LR = 1e-4 × 4 = 4e-4
平方根缩放:LR = 1e-4 × 2 = 2e-4
批次越大,学习率可以同比例或开比例放大。
小结
学习率 = 参数更新的步长
太大 → 震荡、不收敛、崩
太小 → 训练极慢
大模型常用:1e-5 ~ 1e-4
必须配合学习率调度
批次变大 → 学习率可同比例 / 平方根放大
4 初始化(Initialization)
参数初始化影响模型训练的起点,好的初始化能加速收敛并避免梯度消失/爆炸,初始化决定模型从哪里起步。
4.1 Xavier 初始化(Glorot 初始化)
适用:sigmoid、tanh 这类饱和激活函数;
目标:让每层输出的方差差不多;
nin:输入维度
nout:输出维度
eg:
全连接层:输入 256 维,输出 256 维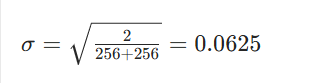
权重从 N(0,0.0625) 采样。
4.2 Kaiming 初始化(He 初始化)
适用:专为 ReLU、LeakyReLU 设计;
目标:解决 ReLU 导致一半神经元为 0,方差变小的问题;
eg:
输入维度 nin=512
权重从 N(0,0.0625) 采样。
4.3 大模型实践
大模型不用复杂公式,直接用固定小标准差。
eg:
GPT 系常用: N(0,0.02)
所有权重基本都用这个,梯度稳、不容易炸。GPT-2、早期 GPT-3 都用 0.02
4.4 嵌入层初始化
词嵌入层(Embedding)
N(0,0.02)和上面一样,简单统一。
语言模型输出层(LM head)
常用:权重初始化为 0 或极小值
目的:让一开始的预测分布比较均匀,初始 loss 不会爆炸
4.5 残差连接的影响
残差连接的初始化技巧(Post-LN 常用)
Transformer 有残差:输出 = 主干输出 + 输入
技巧:
把残差分支最后一层权重初始化为 0
效果:
一开始模型 ≈ 恒等映射
梯度不会在深层消失 / 爆炸
深层大模型训练更稳
小结
初始化 = 模型权重的起点
Xavier:适合 sigmoid/tanh
Kaiming:适合 ReLU
大模型通用:正态分布 N(0,0.02)
嵌入层:同 N(0,0.02)
输出层:0 或极小值,防止初始 loss 爆炸
残差网络:残差分支最后一层权重 = 0,让模型一开始近似恒等映射
5 前向传播与损失
5.1 前向传播计算 Logits
输入序列经过嵌入层得到向量表示,然后通过多层 Transformer 块,最终由输出层(通常为线性变换 + LayerNorm)映射到词表大小的 logits 向量,表示每个 token 的未归一化分数。
输入token序列:x₁ x₂ x₃ … x_T
↓
嵌入层(Embedding):变成向量
↓
多层TransformerEncoder/Decoder
↓
输出层(Linear + LayerNorm)
↓
【Logits】:长度 = 词表大小 |V|
5.2 自回归模型的 Logits 规则(重点)
对于自回归语言模型,输入序列 x1,x2,x3…xT,模型输出每个位置对应的下一个 token 的 logits;
Logits = 模型对每个 token 的 “原始打分”,未归一化。
输入:x1,x2,x3,…,xT
模型做的事:
用 x1 预测 x2
用 x1,x2 预测 x3
…
用 x1∼xT−1 预测 xT
所以:
输出 logits₁ → 预测 x₂
输出 logits₂ → 预测 x₃
…
logits_{T-1} → 预测 x_T
最后一个位置 x_T 不预测
============================================
eg
输入: x1 x2 x3 x4
位置: 1 2 3 4
预测:
logits1 → 预测x2
logits2 → 预测x3
logits3 → 预测x4
logits4 → 无(不计算)
5.3 损失函数:交叉熵
语言模型的标准损失是交叉熵损失(Cross-Entropy Loss)。对于每个预测位置,计算预测分布与真实 token 的交叉熵,并求平均。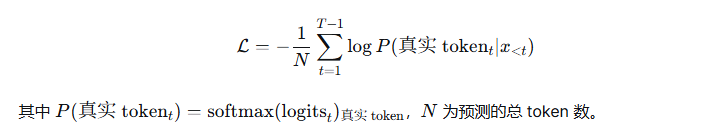
P:softmax 后真实 token 的概率
N:总有效 token 数
eg:
词表大小 = 3
logits₁ = [2, 5, 1]
真实下一个 token = 第 2 个(对应概率最大那个)
步骤:
softmax (logits) → 得到概率
概率 ≈ [0.0466, 0.9362, 0.0171]
取真实 token 概率:0.9362
负对数:-ln (0.9362) ≈ 0.0659
所有位置平均 → 最终损失 L
5.3.1 掩码
在批处理中,序列可能被填充(padding)到相同长度,填充部分的 token 不应参与损失计算,需使用注意力掩码和损失掩码将其忽略。此外,在指令微调中,可能只对输出部分的 token 计算损失,而忽略输入提示部分。
掩码1:Padding 掩码
短序列补 0 到统一长度,补的部分不算损失。
谈吗2:指令微调掩码
只对模型输出部分算损失。
提示:问题问题问题【不计算损失】
回答:答案答案答案【计算损失】
5.4 困惑度(Perplexity)
困惑度是语言模型常用的评估指标,定义为损失指数:
PPL=exp(L)
L:平均交叉熵损失
exp:自然指数
困惑度越低,模型对下一个 token 的预测越准确。
PPL 越低 → 模型越 “不困惑”
PPL = 平均每次要在多少个词里瞎猜
越小越好
eg
损失 L=0.0659 → PPL≈1.07(很准)
损失 L=2 → PPL≈7.39(猜得一般)
6 反向传播与梯度累计
6.1 反向传播
反向传播通过自动微分(Autograd)计算损失对每个参数的梯度。现代框架(PyTorch、TensorFlow)自动构建计算图并执行链式法则。在分布式训练中,每个 GPU 计算其本地 batch 的梯度,然后通过 All-Reduce 通信同步梯度(数据并行)。
反向传播 = 从损失往回算,给每个参数找 “该怎么改” 的梯度
前向传播:输入 → logits → 损失 L
↓
反向传播:L → 输出层 → Transformer层 → 嵌入层
↓
得到:每个权重的梯度(∂L/∂w)
自动微分(Autograd):PyTorch/TensorFlow 自动帮你算梯度,不用手动写链式法则
分布式训练梯度同步:
GPU1:算自己batch的梯度
GPU2:算自己batch的梯度
...
All-Reduce通信:把所有GPU的梯度求平均
→ 所有GPU拿到相同的全局梯度
6.2 梯度累积
如前所述,梯度累积用于模拟大批次。流程如下:
1、每个 micro-batch 前向计算损失。
2、调用 loss.backward() 累积梯度(而非立即更新)。
3、重复若干步。
4、达到累积步数后,调用 optimizer.step() 更新参数,并 optimizer.zero_grad() 清零梯度。
eg: 累积步数 = 4,单卡 batch=2
步骤 操作 梯度状态
1 喂 batch1 → 算 loss → loss.backward () 梯度 1(累加中)
2 喂 batch2 → 算 loss → loss.backward () 梯度 1 + 梯度 2
3 喂 batch3 → 算 loss → loss.backward () 梯度 1 + 梯度 2 + 梯度 3
4 喂 batch4 → 算 loss → loss.backward () 梯度 1 + 梯度 2 + 梯度 3 + 梯度 4
5 optimizer.step () → 更新参数 梯度清零前的总梯度
6 optimizer.zero_grad() 梯度清零,准备下一轮
梯度累积的优点
突破显存限制:用小 batch 模拟大 batch,不用换更大显存的 GPU
保持训练稳定:有效批次大,梯度更准,训练更稳
灵活调整:改累积步数就能调整有效批次,不用改其他代码
小结
反向传播:从损失往回算梯度,分布式训练用 All-Reduce 同步梯度
梯度累积:多次 backward 累积梯度 → 一次 step 更新参数 → zero_grad 清零
核心技巧:损失要除以累积步数,保证梯度尺度正确
作用:突破单卡显存限制,模拟大批次训练
7 优化器
优化器根据梯度更新参数,是训练的核心;
优化器 = 根据梯度,决定参数怎么更的 “智能调节器”。
7.1 Adam 与 AdamW
Adam(Adaptive Moment Estimation):自适应学习率(给不同参数配不同步长),Adam = 动量(Momentum) + RMSProp,对每个参数自适应调整学习率。更新规则: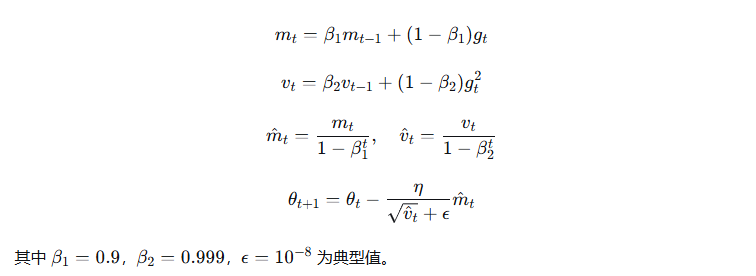
eg
梯度 g_t → 算动量 m_t → 算平方梯度 v_t
↓ ↓
修正 m̂_t 修正 v̂_t
↘ ↙
自适应步长:η/(√v̂_t+ε)
↓
参数更新:θ_t - 步长 × m̂_t
AdamW:Adam 的改进版,将权重衰减(L2 正则)与梯度更新解耦,即权重衰减项不参与自适应学习率计算,而是直接加到参数上。这被证明能更好地泛化。几乎所有大模型(如 GPT、BERT、LLaMA)都使用 AdamW。
Adam:
参数更新 = θ - η×(m̂/(√v̂+ε)) - η×wd×θ
(衰减项参与自适应缩放)
AdamW:
1. 梯度更新:θ_temp = θ - η×(m̂/(√v̂+ε))
2. 权重衰减:θ_new = θ_temp × (1-η×wd)
(衰减项独立,不参与自适应)
超参数
大模型训练常设 β1=0.9,β2=0.95(GPT-3 使用 0.95 以稳定训练),权重衰减 0.1 或 0.01。
小结
Adam:结合动量 + 自适应学习率,β₁=0.9、β₂=0.999 是基础值
AdamW:解耦权重衰减,大模型(GPT/LLaMA)标配
大模型参数:β₁=0.9、β₂=0.95、权重衰减 0.1/0.01
核心区别:AdamW 的权重衰减独立于自适应学习率,效果更好
8 学习率调度(Learning Rate Schedule)
8.1 两个阶段
学习率调度使学习率随时间变化,通常包含两个阶段:
预热(Warmup):训练初期使用较小学习率,逐渐增加到目标值,防止早期梯度不稳定。通常线性预热,步数为总步数的 1%~10%(如 GPT-3 预热 375M tokens,约总数据的 0.2%)。
衰减(Decay):预热后,学习率逐渐下降,使模型在后期精细调整。常用策略:
两大核心阶段:
余弦退火(Cosine Annealing):按余弦函数从峰值降到接近 0。公式: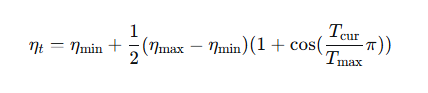
其中 T max 为总步数。
线性衰减:简单线性下降到 0。
策略 曲线形状 核心特点
余弦退火 余弦曲线(先慢降,后快降) 大模型首选,调优更充分
线性衰减 直线下降 简单,但后期下降太快
8.2 实践
LLaMA 使用余弦退火,最低学习率设为峰值的 10%。许多框架(如 HuggingFace Transformers)内置多种调度器。
预热:线性升到峰值学习率(1.5e-4)
衰减:余弦退火,ηmin=1.5e−5(峰值的 10%)
总步数:约 1T tokens
eg
峰值学习率 ηmax=1e−4
最低学习率 ηmin=1e−5
总步数 Tmax=10000
阶段 步数范围 学习率变化
预热 0~1000 0 → 1e-4(线性上升)
衰减 1000~10000 1e-4 → 1e-5(余弦下降)
小结
学习率调度:分预热 + 衰减两阶段,动态调整学习率
预热:线性上升(1%~10% 总步数),防止初期梯度不稳
衰减:大模型首选余弦退火(LLaMA 用此策略),最低 LR 设为峰值的 10%
工具:HuggingFace Transformers 内置 get_cosine_schedule_with_warmup,直接调用即可
9 梯度裁剪(Gradient Clipping)
梯度裁剪防止梯度爆炸,通过限制梯度的范数来稳定训练。
按范数裁剪:计算所有参数梯度的 L2 范数 ||g|| ,如果超过阈值 c ,则缩放梯度: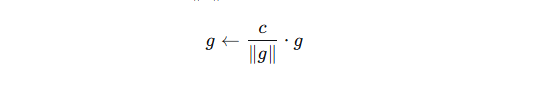
型阈值 c=1.0。也可按最大绝对值裁剪(clip by value),但范数裁剪更常用。
作用:避免梯度值过大导致参数剧变,尤其在使用 FP16 混合精度时,梯度爆炸易引发溢出。
实现:PyTorch 提供 torch.nn.utils.clip_grad_norm_。
典
eg
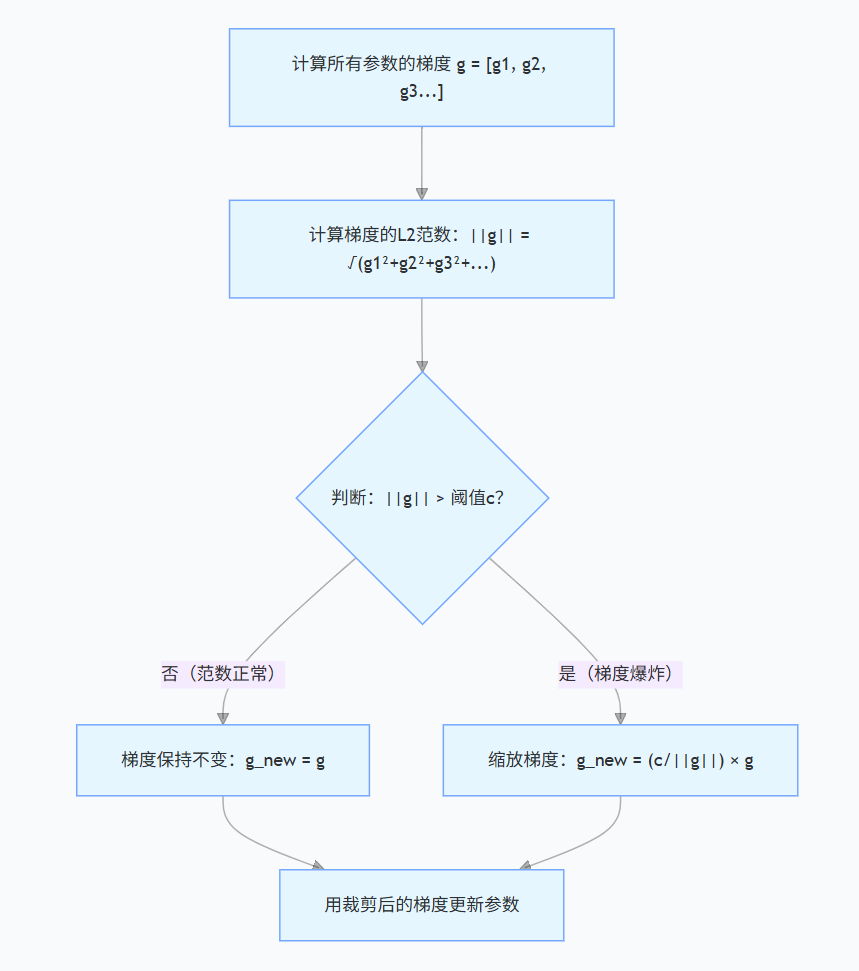
假设模型只有 3 个参数,反向传播后得到梯度:g = [3.0, 4.0, 0.0]
设定裁剪阈值 c = 1.0(行业常用值)
计算步骤
计算梯度的 L2 范数
∣∣g∣∣=3.02+4.02+0.02=9+16=5.0
判断是否需要裁剪
范数 5.0 > 阈值 1.0,需要裁剪。
计算缩放系数
缩放系数 = c/∣∣g∣∣=1.0/5.0=0.2
缩放梯度
g_new=0.2×[3.0,4.0,0.0]=[0.6,0.8,0.0]
验证裁剪后范数
∣∣g_new∣∣=0.62+0.82=1.0(刚好等于阈值)
对此
状态 梯度向量 梯度范数 效果
裁剪前 [3.0, 4.0, 0.0] 5.0 范数过大,参数更新幅度过大
裁剪后 [0.6, 0.8, 0.0] 1.0 范数受控,训练稳定
小结
梯度裁剪的核心逻辑:
计算梯度 L2 范数→判断是否超阈值→超则按比例缩放,最终让梯度范数等于阈值;
数值例子直观验证:
梯度 [3,4,0] 范数为 5,阈值 1 时,缩放后梯度为 [0.6,0.8,0],范数刚好为 1;
PyTorch 实现:
clip_grad_norm_(按范数,更常用)和clip_grad_value_(按绝对值),均在loss.backward()后、optimizer.step()前执行;
10 正则化(Regularization)
正则化旨在防止过拟合,提升泛化能力。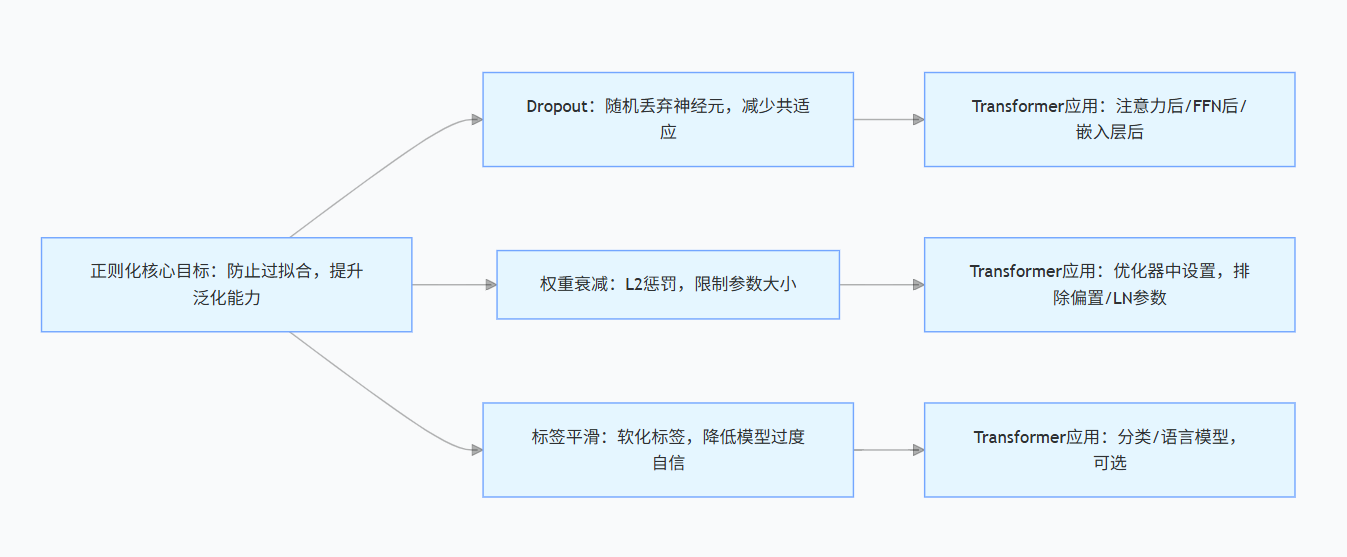
10.1 Dropout
Dropout 在训练时随机丢弃一部分神经元(将其输出置零),相当于训练多个子网络的集成,减少神经元共适应。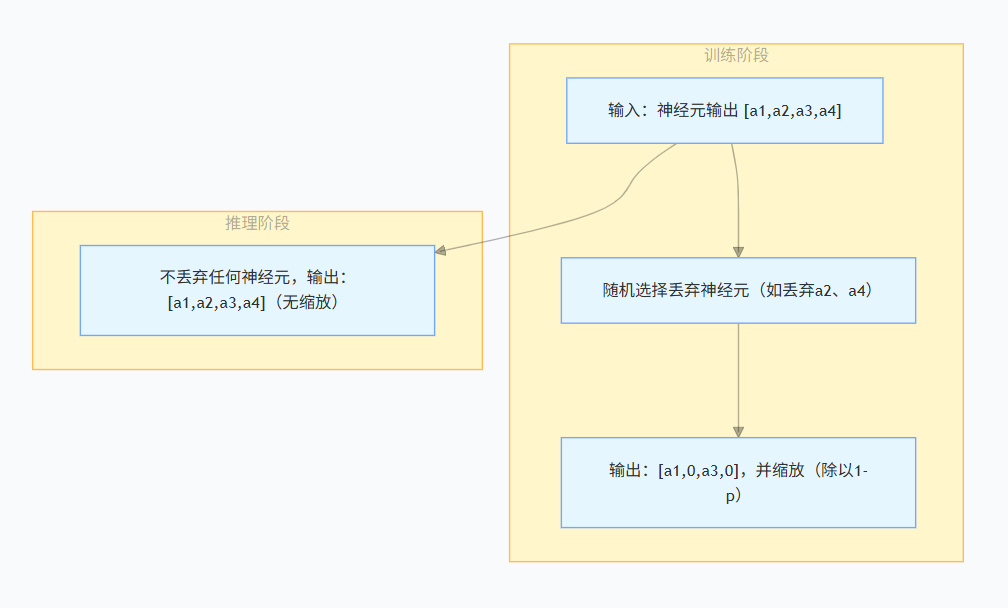
丢弃率 p:训练时神经元被丢弃的概率(大模型常用 0.1/0.2,超大规模模型可设 0);
缩放补偿:训练时输出需除以1-p,保证总输出期望不变;推理时不缩放、不丢弃;
Transformer 应用位置:注意力权重后、FFN 激活后、嵌入层后、残差连接前后;
微调阶段,通常增加 Dropout 防止过拟合。
10.2 权重衰减(Weight Decay)
权重衰减通过在损失函数中添加参数的 L2 范数惩罚项,等价于在更新时对参数进行衰减: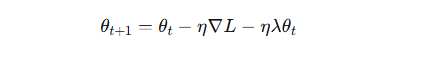
其中 λ 为权重衰减系数。
典型值:0.01~0.1。AdamW 中权重衰减与学习率解耦,常设 0.1。
注意:通常不对偏置项和 LayerNorm 的 scale 参数应用权重衰减,因为它们不参与正则化,且偏置的维度较低。
10.3 标签平滑(Label Smoothing)
原始 one-hot 标签:y=[1,0,0](类别 0 为正)。
平滑后软标签:y_smooth=[1−ϵ,ϵ/(K−1),ϵ/(K−1)](ϵ为平滑系数,通常 0.1;K 为类别数)。
作用:防止模型对预测类别过度自信,提升泛化能力。
小结
Dropout:训练时随机丢弃神经元(Transformer 常用 0.1/0.2),推理时恢复,核心是减少神经元共适应;微调阶段可增大丢弃率防过拟合;
权重衰减:通过 L2 惩罚限制参数大小,AdamW 中解耦权重衰减与学习率(常用 0.1),需排除偏置和 LayerNorm 参数;
标签平滑:将 one-hot 标签转为软标签(ε≈0.1),降低模型过度自信,提升泛化,在分类 / 语言模型中可选使用;
11 训练流程总结
一个典型的大模型训练迭代(iteration)流程如下:
数据加载:从内存映射文件读取一批 token 序列
前向传播:模型计算 logits,并计算损失(考虑掩码)
反向传播:计算梯度,并累积
梯度裁剪:达到累积步数后,对累积梯度进行裁剪
优化器更新:AdamW 更新参数,同时应用学习率调度
梯度清零:准备下一步
日志记录:记录损失、学习率、梯度范数等,用于监控
以上每个环节都有成熟的实践经验和调优技巧。在实际大规模训练中,还需结合混合精度、分布式并行等技术,这将在后续章节展开。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)