BERT句子向量效果差?别急,用对比学习把它“掰正”!
大家好,今天我们来聊一个非常接地气、但在实际应用中又特别让人头疼的问题——如何用BERT构建真正好用的句子向量。
你可能已经听说过BERT,甚至用过它。它在文本分类、机器阅读理解、序列标注这些任务上确实很强。但如果你试着直接拿BERT的输出去做“语义相似度计算”或者“语义检索”,大概率会碰一鼻子灰——效果往往不尽如人意,甚至不如一些轻量级的词向量平均。
为什么?因为BERT天生就不是干这个的。
今天这篇文章,我们就来深挖一下:为什么原始BERT做不好句子向量?什么样的句子向量才是好向量?怎么把BERT“调教”成一个句子向量神器?
一、什么样的句子向量是“好”的?
在动手改模型之前,我们得先搞清楚目标。
一个好的句子向量,应该具备两个关键性质:对齐性 和 均匀性。
-
对齐性:意思相近的句子,它们的向量应该挨得近。
-
均匀性:意思不同的句子,它们的向量应该在整个向量空间里均匀分布,而不是挤在一个小角落里。
你可以把向量空间想象成一个房间。好句子向量的样子是:同类句子聚成一个个小圈子,不同类别的圈子分散在房间各个角落。
如果所有句子都挤在墙角,那你的检索系统就废了——随便拿个句子进去,出来的全是邻居。
二、原始BERT的句子向量为啥不行?
这就得从BERT是怎么训练的说起了。
BERT有两个预训练任务:掩码语言模型 和 下一个句子预测。
-
MLM的任务是猜词,它的关注点在词级别。
-
NSP的任务是判断两句话是不是前后关系,用的是[CLS]这个特殊token的输出。
问题就出在这儿:这些任务的损失函数从来没要求过“不同句子的向量要分散开”。
结果就是,BERT把所有句子的向量都塞到了一个非常狭窄的锥形空间里。这种现象在学术上叫各向异性。简单说就是:不管你说什么,BERT都觉得你们差不多,向量都挤在一起。
你用余弦相似度去算,随便两个句子都是0.8、0.9的高分,根本没法区分。
三、怎么解决?引入对比学习
想让句子向量既有对齐性又有均匀性,就得改训练方式。核心思路是:拉近语义相近的句子,推开语义不同的句子。
这就是对比学习的思想。
目前最成熟、最好用的工具是sentence_transformers这个库,它封装了很多基于对比学习的句子向量模型。我们挑两个最有代表性的来拆解:Sentence-BERT 和 SimCSE。
四、Sentence-BERT:给BERT加上“距离感”
Sentence-BERT的思路非常直接:在训练的时候,把两个句子之间的距离也作为学习目标。
它的架构如下图所示(这里我们脑补一下)。两个BERT模型共享参数,分别编码句子A和句子B,得到向量u和v。然后把这俩向量拼接起来,再拼上它们的差向量|u-v|,最后喂给一个分类器,判断它们是不是语义相近。
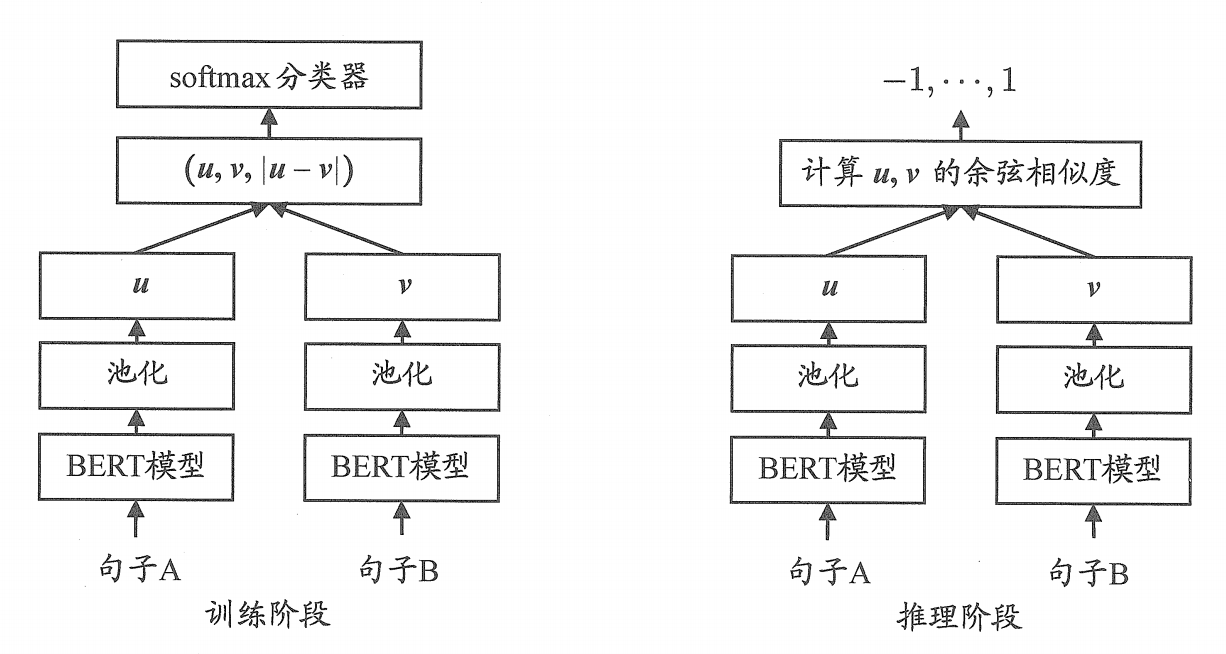
SBERT支持三种训练任务:
-
分类任务:用(u, v, |u-v|)做分类。
-
回归任务:直接优化u和v的余弦相似度。
-
三元组损失:用一个锚点句子a,一个正例p,一个负例n,目标是让a和p的距离比a和n的距离近至少一个阈值。
这个三元组损失可以用一个公式表达:
max(∥sa−sp∥−∥sa−sn∥+ϵ,0)max(∥sa−sp∥−∥sa−sn∥+ϵ,0)
它的意思是:如果负例比正例离锚点还近,就惩罚模型,直到它们被推开。
推理的时候,SBERT直接用余弦相似度来衡量句子之间的语义距离,效果非常好。
一个小细节:SBERT尝试了多种池化方式,最后发现对所有token的输出取平均效果最好,比直接用[CLS]强得多。
五、SimCSE:没有标注数据怎么办?
SBERT需要标注好的句子对,这在很多场景下是奢侈品。那有没有不用标注数据的办法?
有。SimCSE就提供了一个非常巧妙的思路:用Dropout造正例。
我们知道BERT在训练时会随机丢弃一些神经元,这叫Dropout。即使输入同一个句子,两次前向传播的结果也会略有不同。SimCSE就是把这两次结果当作正例,把batch里其他句子当作负例,然后用对比损失去训练。
假设一个batch有N个句子,我们把它复制一遍,变成2N个输入。每个句子经过两次Dropout,得到两个略有不同的向量。损失函数是:
L=−log∑j=1Nsim(hizj,hizj)∑j=1Nsim(hizj,h^izj)L=−log∑j=1Nsim(hizj,h^izj)∑j=1Nsim(hizj,hizj)
这个公式的意思是:对每个句子,最大化它自己和自己的两次Dropout结果之间的相似度,同时最小化它和其他句子之间的相似度。
这就是一个典型的对比学习框架。训练完之后,模型学会了:即使有扰动,同一个句子的语义也应该保持一致;不同句子的语义应该被区分开。
效果出奇地好。SimCSE在无监督情况下就能吊打很多有监督模型。
当然它也有bug。一个常见问题是:模型可能会偷懒,认为长度相近的句子就更相似。因为在一个batch里,长度相近的句子经常被当作负例推开,但长度本身和语义无关。
后来的改进版如ESimCSE,就通过随机增删词、同义词替换等方式,增加了扰动,减少了这种偏差。
六、总结:让BERT学会“分得开、聚得拢”
我们来梳理一下整条技术路线:
-
原始BERT的句子向量不行,是因为预训练任务没要求句子级别的区分度,导致向量空间狭窄、各向异性。
-
好句子向量的标准是对齐性和均匀性:相似的靠拢,不同的分散。
-
对比学习是解决问题的核心手段:通过拉近正例、推开负例,让模型学会语义区分。
-
SBERT用标注数据做有监督对比学习,效果好但依赖数据。
-
SimCSE用Dropout造正例,实现无监督对比学习,让训练不再依赖标注。
-
池化方式很重要,平均池化往往比[CLS]更好。
-
后续优化方向包括减少偏差、增加扰动、提升均匀性。
最终你会发现,句子向量模型的本质,就是在“对齐性”和“均匀性”之间找到平衡。而这个平衡,恰恰是通过对比学习这种“拉近推开”的机制来实现的。
随着模型规模越来越大,像SGPT这样的解码器模型也开始在文档表征上展现出强大能力。这说明:只要训练目标对,大模型也能当个好用的编码器。
如果你正在做语义检索、相似度计算、文本聚类,别再直接拿BERT硬上了。试试SBERT或者SimCSE,你会发现,原来BERT也可以这么听话。
一句话总结:想让BERT听懂“句子之间的远近”,就得用对比学习把它“掰正”。
文章参考书籍:百面大模型
链接: https://pan.baidu.com/s/10mycZxNYbh1w63onscj4qA?pwd=iqni 提取码: iqni

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)