DDPM详细解析&直观理解
一、DDPM直觉理解
我们今天要深入探讨的DDPM去噪扩散概率模型,DDPM是当今生成式AI浪潮中当之无愧的引擎。它生成的图片在真实感、细腻度和多样性上都达到了前所未有的高度,彻底碾压了过去的传统方法。
我将分两部分来介绍,首先讲解DDPM算法的原理,让大家建立对DDPM算法的直觉印象。后面我将带大家进行严谨的逐步数学推导,让你了解所有的技术细节。了解生成模型的数学基础和VAE模型,这对你理解DDPM是非常有帮助的。
生成算法的目的是无中生有,这是非常困难的。就像让我们直接去画一幅画是很困难的。但是在一幅画上进行随机的涂抹,直到看不出来原来画的是什么,这是容易的。如果我们在随机涂抹的其中一步停下来,想让把这幅画恢复到上一步的状态,这也是比直接让你画出这幅画要容易得多。
让我们来看一下DDPM是怎么做到的。首先我们拿一张原始的图片x_0,后面我们都用x_0来表示原始清晰的图片,然后逐步给它添加随机噪声。比如经过1000步,最后图片完全变为噪声数据x_T,我们用x_T表示最后完全为噪声的图片。我们希望能够通过一个神经网络来学习逐步加噪的逆过程,也就是逐步去噪,一步步把随机噪声还原为原始的清晰的图像。当我们训练好这个逆向去噪的模型后,就可以随机生成一个噪声数据,然后让逆向去噪的模型来逐步去噪,生成一个清晰的图片了。
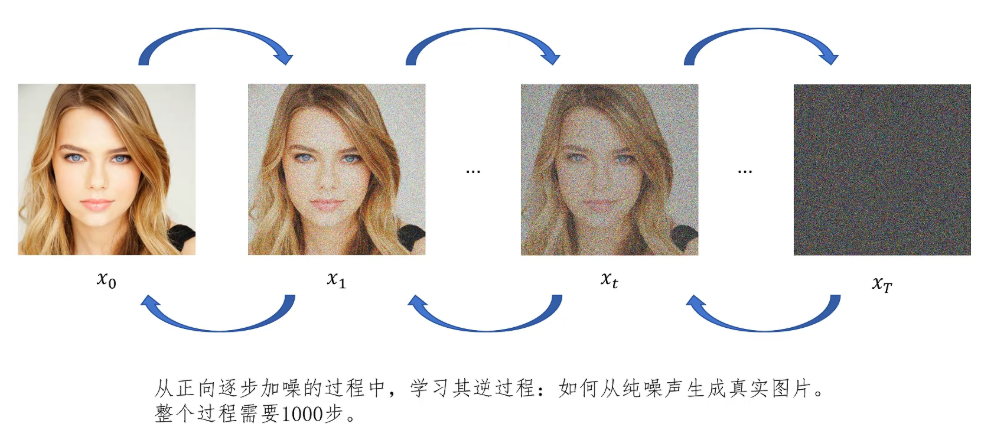
首先我们看正向加噪的过程,它就是一步步往图片里添加噪声,直到图片变得完全随机。每个像素的值看起来就像是从标准正态分布里随机采样出来的一样。那我们怎么给图片里增加噪声呢?在原始图片X0的基础上,我们首先从标准正态分布里采样一个ε,然后让它乘以一个噪声强度系数β。这实际上就相当于以X0为均值,标准差为β的正态分布里进行采样,这样就完成了从X0到X1的加噪过程。类似的对于X1继续增加噪声,从以X1为均值,标准差为β的分布里采样得到Xi加噪过程中每个像素值都是独立的,生成的噪声是一个多维度的噪声,它的形状和图片的形状是一致的。
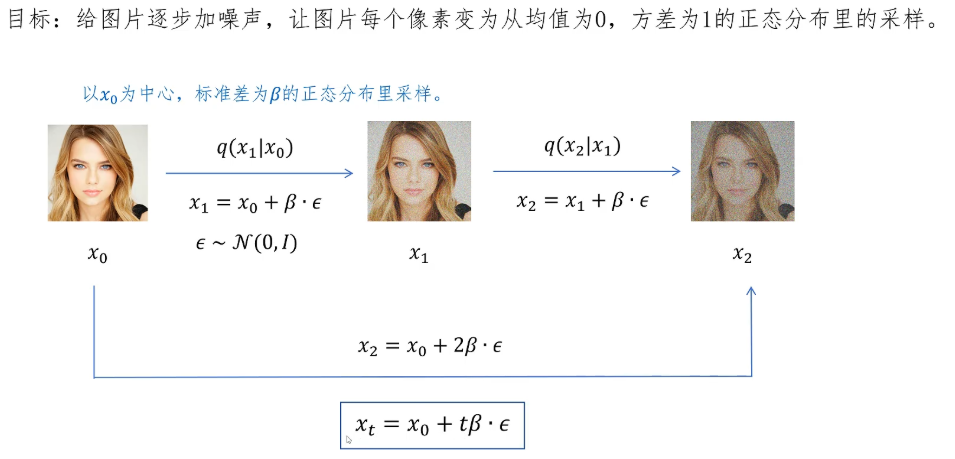
通过观察不难发现,我们实际上可以一次性给 x0x0 增加两倍的噪声,直接从 x0 到达 x2,即 x2=x0+2β⋅ϵ,不用通过中间步骤 x1。同理,对于任意一步的加噪结果,我们可以直接从 x0 增加 t 倍的噪声直接到达 xt,即 xt=x0+tβ⋅ϵ。但实际上这样给原始图片增加噪声有两个问题。第一,随着时间步 t 的增加,均值一直为 x0 保持不变,而方差在一直增大。而我们的目标是让图片最终变为均值为0、方差为1的纯噪声。第二点是在加噪过程中,每一步加入的噪声强度 β 是固定的。可以想象,随着图像逐渐变得杂乱,想要在后期达到与前期同样的破坏效果,实际上需要增加更大的噪声强度。
针对以上两点,DDPM算法做了如下的改进。首先人为定义了不同的噪声强度β_t,从β_1到β_T单调递增,通常取值范围为0.0001到0.02,即0 < β_1 < β_2 < ... < β_T < 1。然后对加噪公式也做了改进:从x_{t-1}到x_t的加噪过程不再是简单的累加,而是先通过系数√(1-β_t)对x_{t-1}进行缩放,这样经过多次迭代后能使均值逐渐趋向于零;后面的噪声项则乘以√(β_t)。这实际上就是从以√(1-β_t) * x_{t-1}为均值、β_t I为方差的正态分布中采样,即q(x_t | x_{t-1}) = √(1-β_t) * x_{t-1} + √(β_t) * ε_t,其中ε_t ~ N(0, I)。

为了让后面的公式形式更简洁,这里定义一个新的变量α_t = 1 - β_t。代入上式,加噪过程可写为q(x_t | x_{t-1}) = √(α_t) * x_{t-1} + √(1-α_t) * ε_t,相当于从均值为√(α_t) * x_{t-1}、方差为(1-α_t)I的正态分布中采样得到加噪结果。你可能疑惑这里为什么加噪系数要设置为√(1-β_t)和√(β_t)。实际上加噪系数的设置可以有不同方式,唯一的要求是当t趋于无穷大时,让x_T服从均值为零、方差为单位阵的标准正态分布。而这里这样设置还有一个好处,就是在后面的推导中可以让x_t相对于x_0有一个非常简洁的表达式。

我们接下来就来推导在这样的加噪系数的设置下,x_T的表达式到底是怎样的。这里的两行是我们之前的定义,然后我们写出x_1的表达式,它就等于√(α_1) * x_0 + √(1-α_1) * ε_1。同样我们也可以写出x_2的表达式,可以发现x_2的表达式里有x_1。我们把x_1的表达式代入整理后,就有了这样的表达式。可以看到表达式后边有两个服从高斯分布的随机变量,它们互相独立,并且方差分别为这里的系数。而且我们知道两个独立正态分布的随机变量之和仍然服从正态分布,均值和方差等于原来两个正态分布的均值与方差之和。所以x_2就服从以均值为√(α_1 α_2) * x_0,方差为α_2(1-α_1) + (1-α_2)的正态分布,所以写成表达式就是这样,它的表达式里只有x_0没有x_1。
接下来我们把ε前面的系数进行化简,可以得到一个简洁的表达式:α_2(1-α_1) + (1-α_2) = 1 - α_1 α_2。可以看到x_2就服从均值为√(α_1 α_2) * x_0,方差为1 - α_1 α_2的正态分布。如果你按照上面的方法继续推导,你会得到x_3服从均值为√(α_1 α_2 α_3) * x_0,方差为1 - α_1 α_2 α_3的正态分布。可以发现这里的均值和方差都有一个很简洁的表达式。这正是为什么前面要设置加噪的系数为√(1-β_t)和√(β_t)的原因。
为了更加简洁地表示,我们定义α拔_t = α_1 * α_2 * ... * α_t,即从1到t的连乘。这样我们就可以直接给出x_t的分布,不用一步步地采样。x_t就等于从均值为√(α拔_t) * x_0,方差为1 - α拔_t的正态分布里采样,写成表达式就是x_t = √(α拔_t) * x_0 + √(1 - α拔_t) * ε。当t趋于无穷大时,因为α拔_t是无穷多个小于1的数连乘,所以它趋于0,因此均值就趋于0,方差就趋于1。这样就达到了我们的目的:让经过T次的正向加噪过程,每个像素最终成为从均值为0、方差为1的标准正态分布里采样得到的噪声。
最后我们再回过头来完整看一下正向加噪过程的公式表达。首先定义一组β_t,它们随着时间步的推移越来越大。然后定义α_t = 1 - β_t,α拔_t = α_1 * α_2 * ... * α_t(即从1到t的连乘)。然后我们定义从t-1步到t步的加噪过程,它可以用表达式写作√(α_t) * x_{t-1} + √(1-α_t) * ε_t,也可以看作是从均值为√(α_t) * x_{t-1}、方差为(1-α_t)的正态分布里采样,来完成从x_{t-1}到x_t的加噪过程。

同样,我们通过推导得到了不用直接一步步加噪,而是直接得到经过t步加噪后的x_t的表达式。它等于√(α拔_t) * x_0 + √(1-α拔_t) * ε,也就是从均值为√(α拔_t) * x_0、方差为(1-α拔_t)I的正态分布里采样,直接得到经过t步加噪后的x_t。这时候我们需要停下来想一想,我们加噪的目的是什么呢?我们一步步的加噪是想让模型学会去噪。前向加噪过程完全通过计算和随机采样就可以完成,过程是确定的,不需要模型参与。后边的去噪过程,我们可以定义一个神经网络来学习。
这里需要特别注意的是,DDPM不论前向加噪过程还是后向去噪过程,都是一个概率采样。前向加噪过程我们刚才推导过,就是从一个正态分布里进行采样的过程。每一步给当前图像所加的噪声都有很多种可能性,不同噪声的概率不同,我们只是随机选择一种噪声。同样,反向去噪也是一个正态分布,反向去噪的每一步就是从这个正态分布里采样一个更清晰的去噪后的图片。这里可以理解为,对一张模糊的图片,在这一步可以去掉的噪声有很多种可能,不同噪声的概率不同,我们从中随机选取一个噪声进行去除。也正是这种去噪的随机性,让DDPM生成的图片比其他算法有更多的多样性。
我们现在有前向过程从x_{t-1}到x_t的概率密度函数q(x_t|x_{t-1}),我们前边已经推导出来它的表达式。如果我们可以通过计算得到从x_t到x_{t-1}的去噪正态分布的概率密度函数,那我们就可以从这个概率密度函数里采样,得到前一步去噪后更清晰的图片。所以我们现在是已知q(x_t|x_{t-1}),想要去求解q(x_{t-1}|x_t)。看到这个条件概率的样式,我们首先想到的是用贝叶斯公式去试着求解一下。这里我们把去噪的概率密度函数q(x_{t-1}|x_t)写成贝叶斯公式的形式,它就转化为三个概率密度函数的乘除运算:q(x_t|x_{t-1}) * q(x_{t-1}) / q(x_t)。
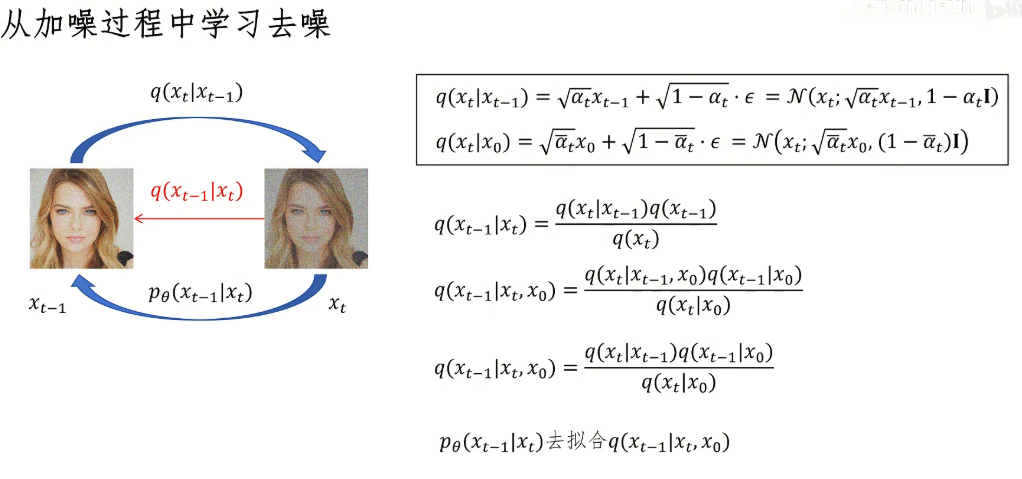
我们首先看分子的第一部分,q(x_t|x_{t-1}),这个没有问题,是我们已知的;另外两项q(x_{t-1})和q(x_t),我们都不知道它的概率密度函数。q(x_{t-1})代表着在考虑所有可能的原始图片下,经过加噪到达x_{t-1}这一步的、带着噪声的图片的概率密度分布,这个是很难计算的,因为它包含了对所有原始图片的可能性。我们之前推导的公式里只能计算出在给定一个确定的x_0的情况下,到达某一时间步时图片可能的概率密度分布函数。所以这里没有办法,我们只能增加对x_0的依赖,把x_0放到条件里,这样我们就可以计算出在给定一个确定的图片x_0的情况下,反向去噪过程的概率密度函数q(x_{t-1}|x_t, x_0)。
这里q(x_t|x_{t-1}, x_0),实际上我们可以去掉对x_0的依赖,因为从x_{t-1}到x_t的加噪过程只依赖于x_{t-1},我们直接在x_{t-1}上进行加噪,这和x_0是没有什么关系的。可以看到,我们得到了一个反向去噪的概率密度函数,但是我们没有办法直接用这个概率分布来进行图像生成,因为它是依赖于x_0的,也就是它必须知道答案才能生成。所以这里我们就定义一个神经网络p_θ来拟合从x_t降噪到x_{t-1}的正态分布,也就是说拟合它的均值和方差。而拟合的目标就是通过贝叶斯公式计算的、在给定不同的x_0的情况下,从x_t降噪到x_{t-1}的正态分布的均值和方差。这里你可以这样理解,我们要学习的p_θ要拟合不同的原始图片x_0下,从x_t降噪到x_{t-1}的均值和方差,这让DDPM的生成就有了多样性。
用p_θ去拟合的概率分布是必须在已知x_0时才可以计算出的概率分布。这里打个不太合适的比方:比如去噪的某一步,我们是要给图片增加眼睛的信息,但是我们拟合的概率分布是知道x_0原始图片的,也就是知道原本这个图片里的眼睛是什么,然后再让你去画上眼睛,这是相对容易的。并且通过不同的图片可以学会泛化,然后再用p_θ这个神经网络进行生成时没有了答案,但是模型已经学会了如何画人的眼睛,就会自动补上人的眼睛。所以到这里我们就对DDPM算法有了一个直观的认识。

二、DDPM数学推导
下面我们就按照原始论文的方式进行数学推导。前向加噪的正态分布采样,我们用 q 来表示,从 x_{t-1} 到 x_t 的加噪,就是从 q(x_t|x_{t-1}) 中进行采样。反向降噪的神经网络我们用 p_θ 来表示,比如 p_θ(x_{t-1}|x_t) 表示神经网络 p_θ 以 x_t 为输入,输出一个均值和方差,然后从以这个均值和方差构成的正态分布里采样得到 x_{t-1}。
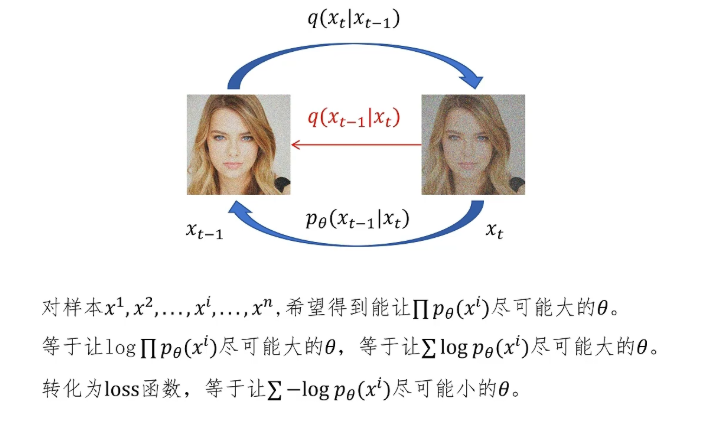
我们训练 p_θ 的最终目标是什么?那就是让神经网络生成我们用来训练的图片的可能性尽可能的大。对于训练样本,我们用 x 的上标数字来表示,x^1, x^2, ..., x^n,我们希望 p_θ 生成它们的联合概率最大,就是对每个概率的连乘。我们最终想要得到的就是通过训练后的神经网络的参数 θ,它可以让这个连乘的值最大。让这个连乘最大的 θ 就等于让 log 连乘最大的 θ,log 内的连乘等于 log 的连加。最后给这个表达式前面增加一个负号,成为 loss 函数。我们就是要找到让这个 loss 函数最小的 θ 的值,所以我们的目标就是最小化这个 loss 函数。
一个完整的正向过程的概率就是在给定x_0的情况下,一步步生成x_1, x_2, …, x_T的过程的概率。它就等于第一步在给定x_0的情况下得到x_1的概率乘以第二步,也就是给定x_0, x_1的情况下生成x_2的概率,一直乘到给定x_0到x_{T-1}得到x_T的概率。又因为我们知道在前向加噪过程中的每一步,它都只和前一步有关,和更前面的步骤是没有关系的。所以可以把公式里面的依赖化简,每一步只依赖于它前一步。最后我们把这个概率公式进行简写,这里用x_{1:T}表示从x_1到x_T的联合概率分布。后面用每一步根据自己前一步加噪的概率连乘来表示。
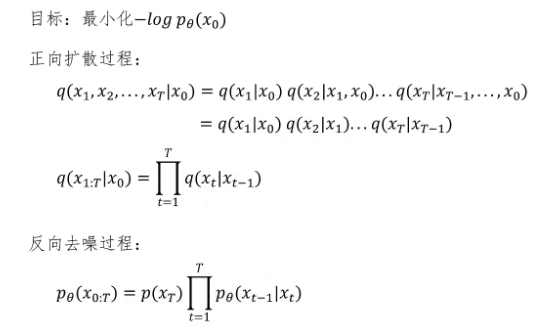
同样我们也可以定义出反向去噪的一个完整过程的概率表达式。可以看到它不依赖于任何值,因为它的初始状态就是p(x_T),它就是从一个标准正态分布产生出来的。后面这个连乘里的每一项都是去噪每一步的概率,这个概率是由神经网络的参数决定的。
我们再来看我们的目标是最小化这个负的log函数。log里面的概率函数表示通过去噪网络p_θ生成原始图像x_0的概率,注意这里的x_0是下标0,表示原始清晰的图片。如何计算这个p_θ(x_0)呢?根据我们上边的定义,我们有去噪整个过程的联合分布p_θ(x_0:T)的表达式。为了得到p_θ(x_0),我们需要对从x_1到x_T进行积分,就代表着考虑各种x_1的可能性,x_2的可能性,一直到x_T的各种可能性。对这些所有路径的可能性的积分就得到了p_θ(x_0)的概率。

这一步我们引入前向加噪过程的概率q(x_1:T|x_0),同时乘以和除以它。然后我们发现这是一个期望的形式。我们把它写成期望的表达式,即E_{q(x_1:T|x_0)}[p_θ(x_0:T)/q(x_1:T|x_0)],然后根据詹森不等式将它写成一个不等式的形式,同时将负log移动到期望内,得到负log p_θ(x_0) ≤ E_{q(x_1:T|x_0)}[-log(p_θ(x_0:T)/q(x_1:T|x_0))]。
好了,我们保持我们的目标不变,要最小化这个loss函数。我们现在有一个不等式,我们继续对这个不等式内的log项进行化简。这一步我们带入正向扩散加噪过程和反向去噪过程的概率公式:p_θ(x_0:T) = p(x_T) * ∏{t=1}^T p_θ(x{t-1}|x_t),q(x_1:T|x_0) = ∏{t=1}^T q(x_t|x{t-1})。这一步把p(x_T)提取出来,这一步根据log内的乘法等于log的连加进行化简。这一步单独把t=1的情况提取出来,剩下的部分就是从2到T的连加。然后注意看蓝色的部分,它表示从x_{t-1}加噪到x_t,因为从x_{t-1}加噪到x_t只和x_{t-1}的状态有关,是否增加x_0都无所谓。所以这里我们增加上x_0概率值不变,然后利用贝叶斯公式可以变化为下面的表达式。我们把蓝色式子变化后的表达式代入,就得到了这样的表达式。
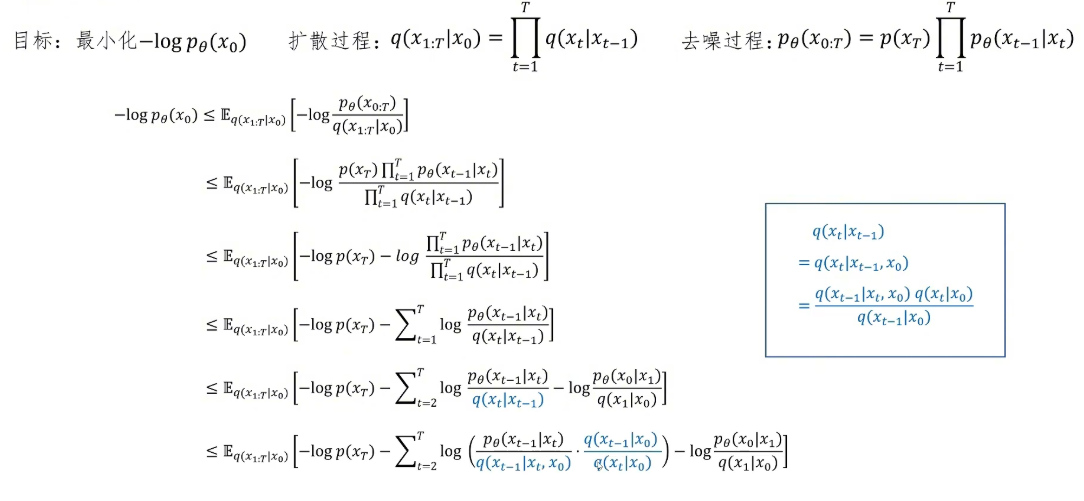
然后我们接着进行推导。这一步我们把log里的乘法变为log的相加,因为前面是负号,所以拆分出来也是减号。我们得到几个单独的log项,其中包括对正向加噪概率的求和。接下来我们对其中从t=2到T的求和项进行变换,利用贝叶斯公式将其改写为三个log项的组合:一个条件概率、一个边缘概率和另一个边缘概率的差。这样改写后,我们发现这些项在求和时会产生连锁抵消的效果——将求和展开,前一项的分母和后一项的分子恰好可以约掉,最终只剩下第一项的分子和最后一项的分母。把这个化简后的结果代入原来的表达式,再与其他log项(如t=1的项和p(x_T)项)进行合并,利用对数的运算法则进一步整理,就得到了一个更加紧凑的表达式。这个表达式将帮助我们最终将目标函数转化为一系列KL散度的和,从而便于神经网络学习。
然后我们把这个期望形式分别带入里面三项的每一项。这里我们通过改变分子和分母的位置,改变了前面两项的符号。我们分别看这三项:第一项我们发现里面不包含可以优化的p_θ,它就是一个常数,不能被优化。最后一项我们优化的是去噪的最后一步,就是从x_1到x_0的去噪过程。我们去噪要经过1000步,最后一步基本上已经是清晰的图片了,这一步我们可以忽略,所以我们的注意力就集中在中间这一部分,这就是我们需要优化的项。
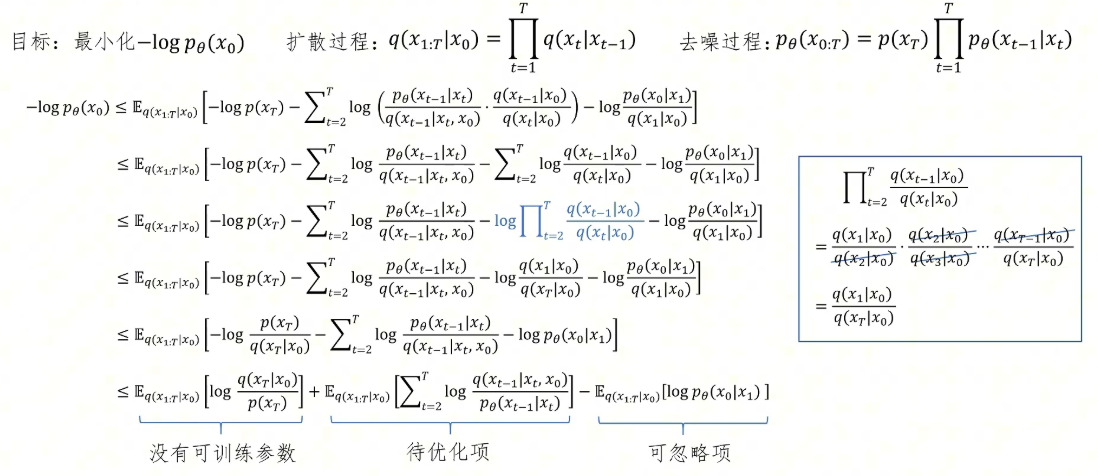
再来回顾一下我们的目标,我们的目标是最小化这个loss函数,就等于最小化我们上一步得到的这个待优化的项。我们看期望里的条件概率,它是给定x_0的情况下,从x_1到x_T的联合概率。因为后边我们表达式里只有x_0、x_{t-1}和x_t三项,所以我们前面这个联合概率可以去掉那些不存在的项,仅保留x_0、x_{t-1}和x_t三项。然后我们把这个期望变成对x_{t-1}、x_t的积分,同时积分里面需要乘以给定x_0时x_t和x_{t-1}的联合概率值。然后我们根据条件概率公式把这个概率变成这两项概率的乘积。第一个概率值和x_{t-1}无关,我们可以把它提到第一重积分的外边,里边对x_{t-1}进行积分,里边是一个KL散度的表达式。然后我们对x_t进行积分,这是一个期望的形式,我们把它写作期望的表达式,最终表达式就为这样,我们的目标就是最小化这个表达式,这个表达式里边有一个KL散度,我们知道KL散度的最小值就是0,表示两个分布完全一致。
这个KL散度衡量的是哪两个概率分布的相似程度呢?一个是前向加噪过程中,给定x_0和x_t得到x_t加噪前的x_{t-1}的概率分布q(x_{t-1}|x_t, x_0);另一个是我们要训练的p_θ从x_t得到降噪后的x_{t-1}的概率分布p_θ(x_{t-1}|x_t)。也就是说,要让神经网络的去噪过程从前向加噪过程中学习,只不过根据加噪得到的概率分布是参考了正确答案x_0后得到的。我们这一通推导得到的结果和我们最初通过直觉得到的结果是一致的。现在我们知道了去噪网络训练的目的是什么了:那就是每一步去噪网络预测的正态分布的均值和方差,应该等于q(x_{t-1}|x_t, x_0)这个分布的均值和方差。
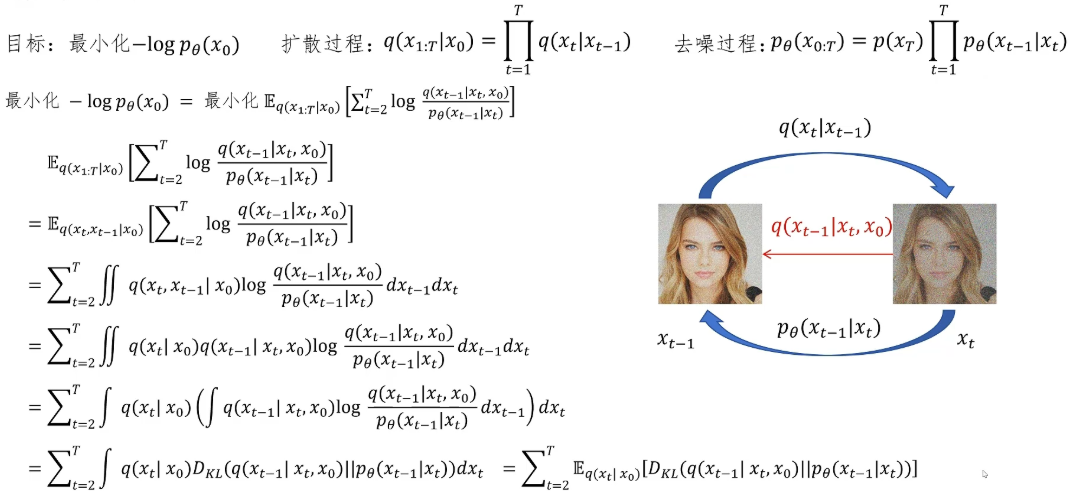
那么q(x_{t-1}|x_t, x_0)具体的均值和方差是多少呢?我们就来计算一下。根据贝叶斯公式,我们可以把它写成q(x_{t-1}|x_t, x_0) = q(x_t|x_{t-1}, x_0) * q(x_{t-1}|x_0) / q(x_t|x_0)。其中分子的第一项里的x_0是可以忽略的,因为q(x_t|x_{t-1})与x_0无关。经过之前的推导,我们知道贝叶斯公式里的这三项都是正态分布,我们之前也给出了它们的均值和方差的公式。另外,在贝叶斯统计中,如果先验分布和似然函数都是高斯的,那么后验分布也一定是高斯的,所以我们知道这个表达式的计算结果一定是一个高斯分布。
接下来我们就把这三项的概率密度函数代入进行计算。直接计算这个式子比较复杂,有没有什么简单点的办法呢?既然我们知道结果一定是个正态分布,那它的表达式一定符合正态分布的标准形式,也就是由常数项1/√(2πσ^2)乘以指数函数构成。我们看这个指数部分,它包含了我们要求的均值和方差,所以我们只要求出这个复杂式子的指数部分就可以了。然后把指数部分写成关于自变量x_{t-1}的表达式,根据系数就可以推断得到我们要求的均值和方差。所以这里我们只整理出指数部分,指数函数相乘等于指数部分相加。因为前面的常数项不影响均值和方差的求解,所以这个指数函数正比于实际的函数值。
然后我们来看这个正态分布的指数部分,把它写成关于自变量x_{t-1}的二次多项式。我们知道正态分布的指数形式通常为exp(-1/2 * ( (x-μ)^2/σ^2 )),展开后得到关于x的二次项系数为-1/(2σ^2),一次项系数为μ/σ^2,以及常数项。所以我们只需要将待求的表达式也整理成关于x_{t-1}的二次多项式,通过对比系数就能得到方差和均值。
根据贝叶斯公式,q(x_{t-1}|x_t, x_0)正比于q(x_t|x_{t-1}) * q(x_{t-1}|x_0),这两个都是高斯分布。我们将它们的指数部分相加,并提取出负二分之一公因子,得到关于x_{t-1}的表达式。注意这里只有两项包含x_{t-1,第三项(与x_{t-1}无关的常数项)可以忽略,因为它不影响均值和方差的求解。

接下来我们把这两项中的平方展开,合并同类项,得到关于x_{t-1}的二次项和一次项。二次项的系数就是1/σ^2,一次项的系数是-2μ/σ^2(注意指数部分前面有负号,整理后得到的关系)。通过联立这两个系数,我们就可以解出方差σ^2和均值μ。这个均值μ就是我们需要神经网络去拟合的目标,它依赖于x_t和x_0。
为了在去噪过程中不依赖x_0,我们还可以利用前面推导出的x_t与x_0的关系式x_t = √(α拔_t) x_0 + √(1-α拔_t) ε,将x_0用x_t和噪声ε表示,从而得到只依赖于x_t的均值表达式。这样,神经网络就可以根据当前时刻的x_t来预测均值,实现逐步去噪。

我们仔细看一下最终求得的需要神经网络拟合的这个正态分布。它是在已知x_t的情况下预测x_{t-1}的分布情况。下边的表达式中x_t是已知的,α_t、α拔_t、α拔_{t-1}都是我们已知的,只有这个ε是未知的。这个ε就是对于这个x_t从x_0直接生成时,从标准正态分布里采样出来的噪声。这个噪声在这里是一个抽样出来的确定的值。之前我们说要让神经网络来预测均值和方差,现在我们只需要让神经网络来预测这个噪声值就可以了。然后根据公式我们就可以得到从x_t到x_{t-1}步去噪的正态分布的均值和方差。然后我们从这个正态分布里采样,就可以得到去噪后的x_{t-1}了。
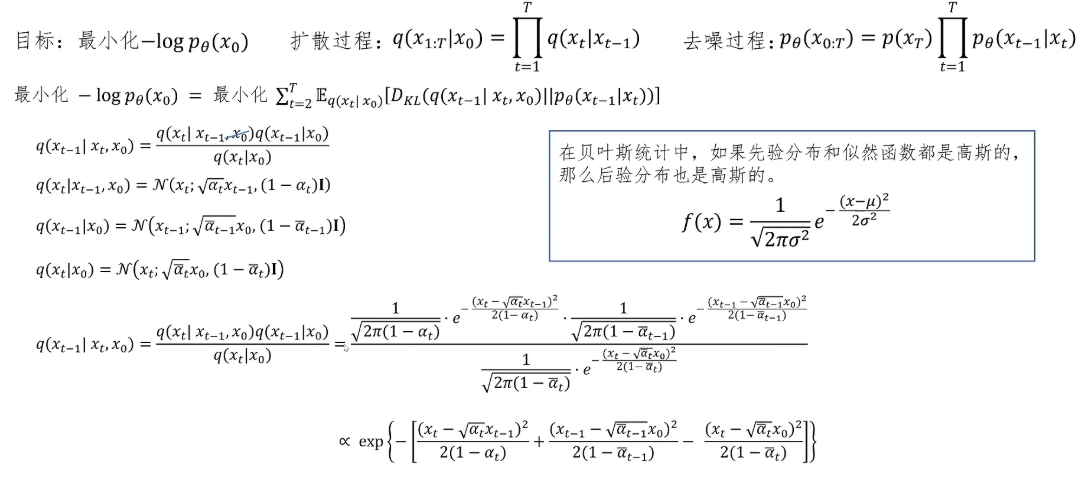
最后我们再来完整地看一下DDPM算法的训练和推理过程。首先需要定义一些训练过程中要用到的常量。DDPM里定义了1000个β_t,最小的值为0.0001,最大的值为0.02。然后定义α_t = 1 - β_t,以及α拔_t = ∏_{i=1}^t α_i。训练时获取一组训练数据,也就是一组原始图片x_0。随机生成一个t,这个t是1到1000之间,然后再从多元标准正态分布里采样一个ε,这个ε的形状和原始图片是一样大小的。然后就可以根据公式x_t = √(α拔_t) * x_0 + √(1-α拔_t) * ε生成一个x_t。因为不同的时间步里x_t包含的噪声是不同的,所以我们同时需要将x_t和时间步t的具体值一起送入去噪网络,让去噪网络去预测这个ε。然后用MSE计算预测的ε和真实的ε之间的loss,反向传播去更新去噪网络。
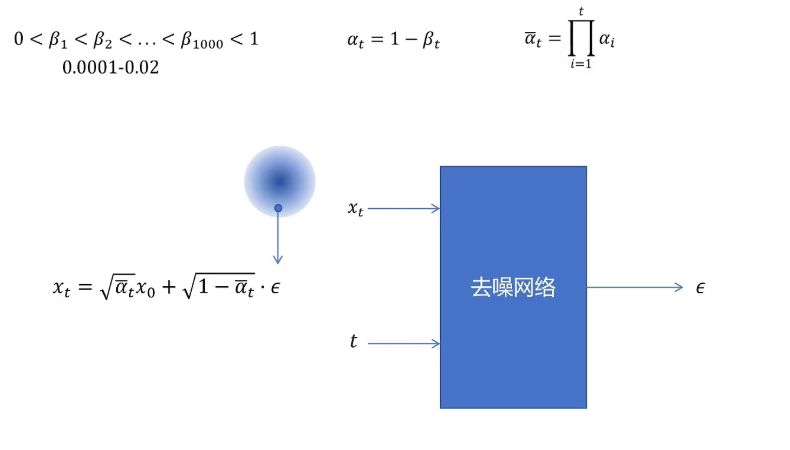
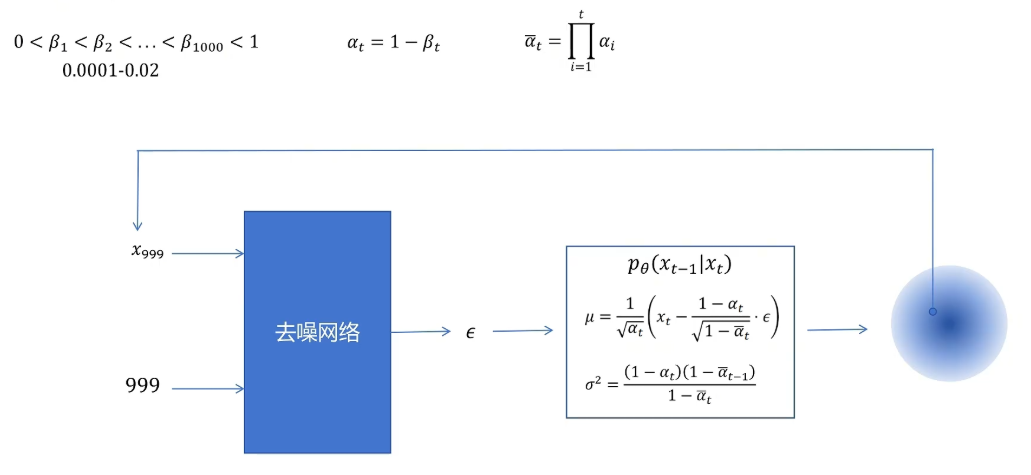
接下来我们看DDPM的推理过程,也就是生成图片的过程。推理时首先从一个标准多元正态分布里采样一个噪声作为x_1000,然后将它和时间步t=1000一起传入去噪网络,网络预测出ε。接着根据均值和方差的公式计算出从1000步到999步采样的正态分布,并从中采样一个值作为x_999。然后再把x_999作为输入,连同时间步999一起送入去噪网络进行下一轮去噪。这样一直重复,直到最后一轮(t=1到0)。最后一轮不需要采样,直接使用该步正态分布的均值作为最终输出的清晰图片x_0。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)