8bert实战
| 维度 | Transformer 编码器 | BERT |
|---|---|---|
| 本质 | 一个模块/组件 | 一个完整的预训练模型 |
| 结构 | 多头自注意力 + FFN + 残差连接 + LN | 完全相同的层结构,堆叠多层 |
| 输入 | token 嵌入 + 位置编码 | token 嵌入 + 段嵌入 + 位置嵌入 |
| 位置编码 | 正弦/余弦固定 | 可学习 |
| 训练方式 | 通常与解码器联合训练(有监督) | 自监督预训练(MLM + NSP)+ 下游微调 |
| 输出用途 | 为解码器提供上下文表示 | 作为通用表示用于下游任务 |
| 双向性 | 是(无掩码) | 是(通过 MLM 强化) |
| 代表作 | Transformer 论文中的编码器部分 | BERT、RoBERTa、ALBERT 等 |
分词器(Tokenizer)
分词器 是自然语言处理(NLP)中将原始文本转换为模型可处理的数值表示的第一步,也是至关重要的一步。它将文本切分成最小的语义单元——token,并将每个 token 映射为词汇表中的整数索引。分词器的设计直接影响模型对语言的理解能力和效率。
神经网络无法直接处理原始字符串,需要将文本转换成数值张量。分词器完成三件事:
-
分词(Tokenization):将文本切分成 token 序列(如单词、子词、字符)。
-
索引化(Indexing):将每个 token 映射到词汇表中的唯一整数 ID。
-
添加特殊标记:如
[CLS]、[SEP]、[PAD]等,以适应模型输入格式。



序列长度限制:大多数 Transformer 模型有最大长度限制(如 BERT 为 512),需对超长文本进行截断或分段。
Bert输入
Token 嵌入(Token Embeddings)
-
将输入文本切分为 WordPiece 子词单元,每个 token 对应词汇表中的一个 ID。
-
通过一个可训练的嵌入矩阵将每个 ID 映射为向量。
-
词汇表大小约 3 万。
段嵌入(Segment Embeddings)
-
用于区分输入中的两个句子(当输入为句子对时)。
-
只有两种向量:EAEA 表示第一个句子,EBEB 表示第二个句子。
-
如果输入是单个句子,则全部使用 EAEA。
位置嵌入(Position Embeddings)
-
与原始 Transformer 的正余弦固定位置编码不同,BERT 使用可学习的位置嵌入。
-
最大位置长度通常设为 512,即最多支持 512 个 token 的序列。
特殊标记
-
[CLS]:放在序列开头,其对应的输出向量用于分类任务。 -
[SEP]:用于分隔句子(放在句子末尾)或表示序列结束。
计算bert参数量
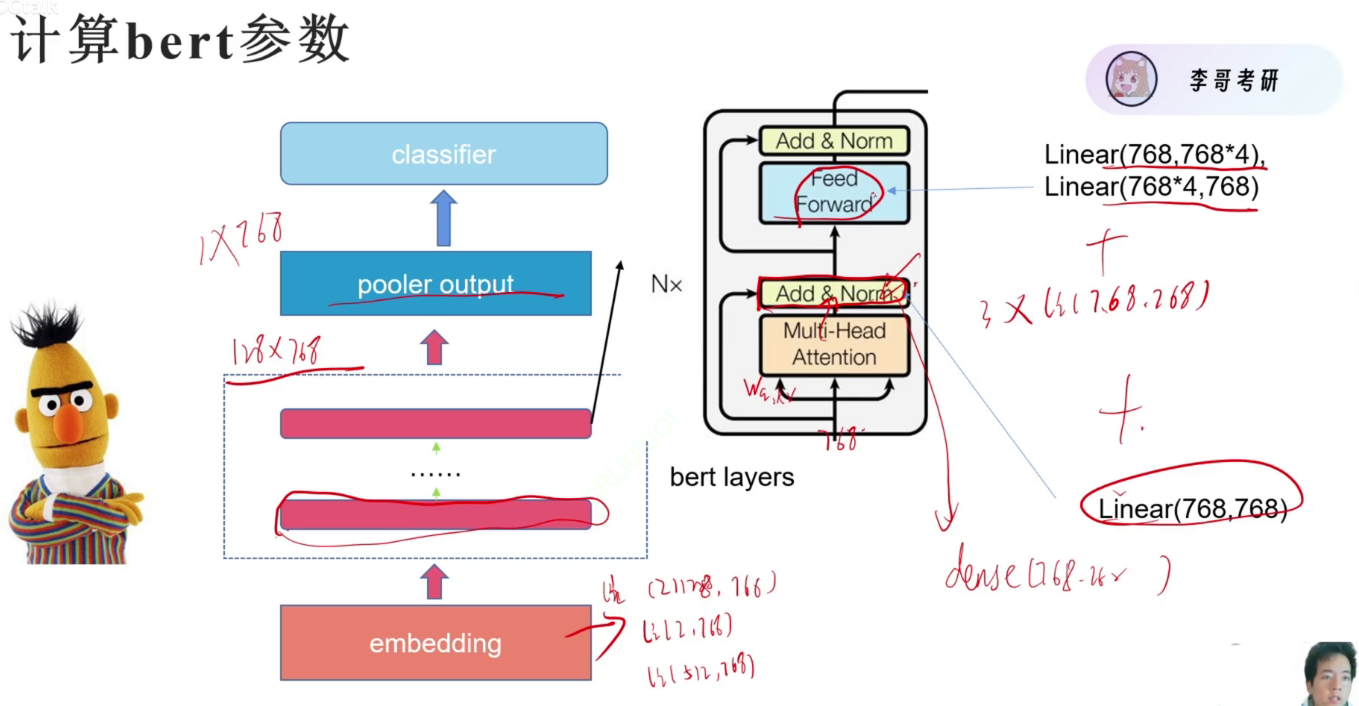
- Token嵌入 21128->768
- 位置嵌入2->768
- 段嵌入512->768

# 从 transformers 库导入 BERT 模型和分词器
from transformers import BertModel, BertTokenizer
# 定义一个函数,用于统计模型的参数量
def get_parameter_number(model):
# 计算模型所有参数的总元素个数(即总参数量)
total_num = sum(p.numel() for p in model.parameters())
# 计算需要梯度更新的参数个数(即可训练参数量)
trainable_num = sum(p.numel() for p in model.parameters() if p.requires_grad)
# 以字典形式返回结果
return {'Total': total_num, 'Trainable': trainable_num}
# 指定要加载的预训练模型名称(中文 BERT-base)
bert_path = "bert-base-chinese"
# 从 Hugging Face 模型库加载预训练权重,返回 BertModel 实例
model = BertModel.from_pretrained(bert_path)
# 调用统计函数并打印结果
print(get_parameter_number(model))| 字段 | 值 | 说明 |
|---|---|---|
architectures |
["BertForMaskedLM"] |
指定模型架构,这里表示用于掩码语言模型(MLM)预训练的 BERT。 |
attention_probs_dropout_prob |
0.1 |
注意力概率的 dropout 比率,防止过拟合。 |
directionality |
"bidi" |
表示模型是双向的(bidirectional),BERT 的核心特性。 |
hidden_act |
"gelu" |
前馈网络中的激活函数,使用 GELU。 |
hidden_dropout_prob |
0.1 |
隐藏层输出的 dropout 比率。 |
hidden_size |
768 |
隐藏层维度(即 HH),BERT-base 的标准值。 |
initializer_range |
0.02 |
参数初始化时截断正态分布的标准差范围。 |
intermediate_size |
3072 |
前馈网络中间层的维度,通常是 4 * hidden_size。 |
layer_norm_eps |
1e-12 |
层归一化中的 epsilon,防止除零。 |
max_position_embeddings |
512 |
最大位置编码长度,即模型能处理的最大序列长度。 |
model_type |
"bert" |
模型类型标识。 |
num_attention_heads |
12 |
注意力头数(A)。 |
num_hidden_layers |
12 |
Transformer 编码器层数(L)。 |
pad_token_id |
0 |
填充 token 的 ID,通常为 0。 |
pooler_fc_size |
768 |
池化层全连接大小,与 hidden_size 相同。 |
pooler_num_attention_heads |
12 |
池化层中的注意力头数(标准 BERT 中池化层不使用多头注意力,可能是预留字段)。 |
pooler_num_fc_layers |
3 |
池化层中全连接层数(标准 BERT 中池化层只有一层,此处可能是预留)。 |
pooler_size_per_head |
128 |
每个注意力头的维度(标准多头注意力的头维度为 hidden_size/num_attention_heads = 64,这里 128 可能表示池化层内部的投影)。 |
pooler_type |
"first_token_transform" |
池化方式,取 [CLS] 位置的输出并通过全连接层变换。 |
type_vocab_size |
2 |
段嵌入的词汇表大小,用于区分两个句子(A/B)。 |
vocab_size |
21128 |
词汇表大小(V),这是中文 BERT 的标准值。 |
dim = 768 # 隐藏层维度 H
vocab = 21128 # 词汇表大小 V
# 嵌入层参数量:词嵌入 + 段嵌入(2类) + 位置嵌入(512)
emb_para = vocab * dim + 2 * 768 + 512 * 768
# 单层 Transformer 参数量(仅权重矩阵)
self_attention_para = 768 * 768 * 3 + 768 * 768 + 768 * 3072 + 3072 * 768
# 768*768*3: Q、K、V 三个权重矩阵(各 H×H)
# 768*768: 输出投影权重矩阵(H×H)
# 768*3072: 前馈网络第一层权重(H×4H)
# 3072*768: 前馈网络第二层权重(4H×H)
# 总和 = 4H² + 8H² = 12H²
print(emb_para + 12 * self_attention_para) # 输出嵌入层 + 12层编码器(仅权重)的总参数
# 遍历模型所有参数,打印名称和形状
for name, para in model.named_parameters():
print(name, para.shape)
# 池化层权重矩阵参数量(H×H)
pool_num = 768 * 768
print(emb_para + 12 * self_attention_para + pool_num) # 加上池化层权重后的总参数# 遍历模型的所有参数(包括可训练和不可训练)
# named_parameters() 返回一个生成器,产生 (参数名, 参数张量) 对
for name, param in model.named_parameters():
# 打印参数名和对应的张量形状
print(name, param.shape)embeddings.word_embeddings.weight torch.Size([21128, 768])
embeddings.position_embeddings.weight torch.Size([512, 768])
embeddings.token_type_embeddings.weight torch.Size([2, 768])
embeddings.LayerNorm.weight torch.Size([768])
embeddings.LayerNorm.bias torch.Size([768])
encoder.layer.0.attention.self.query.weight torch.Size([768, 768])
encoder.layer.0.attention.self.query.bias torch.Size([768])
encoder.layer.0.attention.self.key.weight torch.Size([768, 768])
encoder.layer.0.attention.self.key.bias torch.Size([768])
encoder.layer.0.attention.self.value.weight torch.Size([768, 768])
encoder.layer.0.attention.self.value.bias torch.Size([768])
encoder.layer.0.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.0.attention.output.dense.bias torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.0.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.0.intermediate.dense.bias torch.Size([3072])
encoder.layer.0.output.dense.weight torch.Size([768, 3072])
encoder.layer.0.output.dense.bias torch.Size([768])
encoder.layer.0.output.LayerNorm.weight torch.Size([768])
encoder.layer.0.output.LayerNorm.bias torch.Size([768])
encoder.layer.1.attention.self.query.weight torch.Size([768, 768])
encoder.layer.1.attention.self.query.bias torch.Size([768])
encoder.layer.1.attention.self.key.weight torch.Size([768, 768])
encoder.layer.1.attention.self.key.bias torch.Size([768])
encoder.layer.1.attention.self.value.weight torch.Size([768, 768])
encoder.layer.1.attention.self.value.bias torch.Size([768])
encoder.layer.1.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.1.attention.output.dense.bias torch.Size([768])
encoder.layer.1.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.1.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.1.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.1.intermediate.dense.bias torch.Size([3072])
encoder.layer.1.output.dense.weight torch.Size([768, 3072])
encoder.layer.1.output.dense.bias torch.Size([768])
encoder.layer.1.output.LayerNorm.weight torch.Size([768])
encoder.layer.1.output.LayerNorm.bias torch.Size([768])
encoder.layer.2.attention.self.query.weight torch.Size([768, 768])
encoder.layer.2.attention.self.query.bias torch.Size([768])
encoder.layer.2.attention.self.key.weight torch.Size([768, 768])
encoder.layer.2.attention.self.key.bias torch.Size([768])
encoder.layer.2.attention.self.value.weight torch.Size([768, 768])
encoder.layer.2.attention.self.value.bias torch.Size([768])
encoder.layer.2.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.2.attention.output.dense.bias torch.Size([768])
encoder.layer.2.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.2.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.2.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.2.intermediate.dense.bias torch.Size([3072])
encoder.layer.2.output.dense.weight torch.Size([768, 3072])
encoder.layer.2.output.dense.bias torch.Size([768])
encoder.layer.2.output.LayerNorm.weight torch.Size([768])
encoder.layer.2.output.LayerNorm.bias torch.Size([768])
encoder.layer.3.attention.self.query.weight torch.Size([768, 768])
encoder.layer.3.attention.self.query.bias torch.Size([768])
encoder.layer.3.attention.self.key.weight torch.Size([768, 768])
encoder.layer.3.attention.self.key.bias torch.Size([768])
encoder.layer.3.attention.self.value.weight torch.Size([768, 768])
encoder.layer.3.attention.self.value.bias torch.Size([768])
encoder.layer.3.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.3.attention.output.dense.bias torch.Size([768])
encoder.layer.3.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.3.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.3.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.3.intermediate.dense.bias torch.Size([3072])
encoder.layer.3.output.dense.weight torch.Size([768, 3072])
encoder.layer.3.output.dense.bias torch.Size([768])
encoder.layer.3.output.LayerNorm.weight torch.Size([768])
encoder.layer.3.output.LayerNorm.bias torch.Size([768])
encoder.layer.4.attention.self.query.weight torch.Size([768, 768])
encoder.layer.4.attention.self.query.bias torch.Size([768])
encoder.layer.4.attention.self.key.weight torch.Size([768, 768])
encoder.layer.4.attention.self.key.bias torch.Size([768])
encoder.layer.4.attention.self.value.weight torch.Size([768, 768])
encoder.layer.4.attention.self.value.bias torch.Size([768])
encoder.layer.4.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.4.attention.output.dense.bias torch.Size([768])
encoder.layer.4.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.4.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.4.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.4.intermediate.dense.bias torch.Size([3072])
encoder.layer.4.output.dense.weight torch.Size([768, 3072])
encoder.layer.4.output.dense.bias torch.Size([768])
encoder.layer.4.output.LayerNorm.weight torch.Size([768])
encoder.layer.4.output.LayerNorm.bias torch.Size([768])
encoder.layer.5.attention.self.query.weight torch.Size([768, 768])
encoder.layer.5.attention.self.query.bias torch.Size([768])
encoder.layer.5.attention.self.key.weight torch.Size([768, 768])
encoder.layer.5.attention.self.key.bias torch.Size([768])
encoder.layer.5.attention.self.value.weight torch.Size([768, 768])
encoder.layer.5.attention.self.value.bias torch.Size([768])
encoder.layer.5.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.5.attention.output.dense.bias torch.Size([768])
encoder.layer.5.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.5.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.5.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.5.intermediate.dense.bias torch.Size([3072])
encoder.layer.5.output.dense.weight torch.Size([768, 3072])
encoder.layer.5.output.dense.bias torch.Size([768])
encoder.layer.5.output.LayerNorm.weight torch.Size([768])
encoder.layer.5.output.LayerNorm.bias torch.Size([768])
encoder.layer.6.attention.self.query.weight torch.Size([768, 768])
encoder.layer.6.attention.self.query.bias torch.Size([768])
encoder.layer.6.attention.self.key.weight torch.Size([768, 768])
encoder.layer.6.attention.self.key.bias torch.Size([768])
encoder.layer.6.attention.self.value.weight torch.Size([768, 768])
encoder.layer.6.attention.self.value.bias torch.Size([768])
encoder.layer.6.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.6.attention.output.dense.bias torch.Size([768])
encoder.layer.6.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.6.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.6.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.6.intermediate.dense.bias torch.Size([3072])
encoder.layer.6.output.dense.weight torch.Size([768, 3072])
encoder.layer.6.output.dense.bias torch.Size([768])
encoder.layer.6.output.LayerNorm.weight torch.Size([768])
encoder.layer.6.output.LayerNorm.bias torch.Size([768])
encoder.layer.7.attention.self.query.weight torch.Size([768, 768])
encoder.layer.7.attention.self.query.bias torch.Size([768])
encoder.layer.7.attention.self.key.weight torch.Size([768, 768])
encoder.layer.7.attention.self.key.bias torch.Size([768])
encoder.layer.7.attention.self.value.weight torch.Size([768, 768])
encoder.layer.7.attention.self.value.bias torch.Size([768])
encoder.layer.7.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.7.attention.output.dense.bias torch.Size([768])
encoder.layer.7.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.7.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.7.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.7.intermediate.dense.bias torch.Size([3072])
encoder.layer.7.output.dense.weight torch.Size([768, 3072])
encoder.layer.7.output.dense.bias torch.Size([768])
encoder.layer.7.output.LayerNorm.weight torch.Size([768])
encoder.layer.7.output.LayerNorm.bias torch.Size([768])
encoder.layer.8.attention.self.query.weight torch.Size([768, 768])
encoder.layer.8.attention.self.query.bias torch.Size([768])
encoder.layer.8.attention.self.key.weight torch.Size([768, 768])
encoder.layer.8.attention.self.key.bias torch.Size([768])
encoder.layer.8.attention.self.value.weight torch.Size([768, 768])
encoder.layer.8.attention.self.value.bias torch.Size([768])
encoder.layer.8.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.8.attention.output.dense.bias torch.Size([768])
encoder.layer.8.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.8.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.8.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.8.intermediate.dense.bias torch.Size([3072])
encoder.layer.8.output.dense.weight torch.Size([768, 3072])
encoder.layer.8.output.dense.bias torch.Size([768])
encoder.layer.8.output.LayerNorm.weight torch.Size([768])
encoder.layer.8.output.LayerNorm.bias torch.Size([768])
encoder.layer.9.attention.self.query.weight torch.Size([768, 768])
encoder.layer.9.attention.self.query.bias torch.Size([768])
encoder.layer.9.attention.self.key.weight torch.Size([768, 768])
encoder.layer.9.attention.self.key.bias torch.Size([768])
encoder.layer.9.attention.self.value.weight torch.Size([768, 768])
encoder.layer.9.attention.self.value.bias torch.Size([768])
encoder.layer.9.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.9.attention.output.dense.bias torch.Size([768])
encoder.layer.9.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.9.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.9.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.9.intermediate.dense.bias torch.Size([3072])
encoder.layer.9.output.dense.weight torch.Size([768, 3072])
encoder.layer.9.output.dense.bias torch.Size([768])
encoder.layer.9.output.LayerNorm.weight torch.Size([768])
encoder.layer.9.output.LayerNorm.bias torch.Size([768])
encoder.layer.10.attention.self.query.weight torch.Size([768, 768])
encoder.layer.10.attention.self.query.bias torch.Size([768])
encoder.layer.10.attention.self.key.weight torch.Size([768, 768])
encoder.layer.10.attention.self.key.bias torch.Size([768])
encoder.layer.10.attention.self.value.weight torch.Size([768, 768])
encoder.layer.10.attention.self.value.bias torch.Size([768])
encoder.layer.10.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.10.attention.output.dense.bias torch.Size([768])
encoder.layer.10.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.10.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.10.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.10.intermediate.dense.bias torch.Size([3072])
encoder.layer.10.output.dense.weight torch.Size([768, 3072])
encoder.layer.10.output.dense.bias torch.Size([768])
encoder.layer.10.output.LayerNorm.weight torch.Size([768])
encoder.layer.10.output.LayerNorm.bias torch.Size([768])
encoder.layer.11.attention.self.query.weight torch.Size([768, 768])
encoder.layer.11.attention.self.query.bias torch.Size([768])
encoder.layer.11.attention.self.key.weight torch.Size([768, 768])
encoder.layer.11.attention.self.key.bias torch.Size([768])
encoder.layer.11.attention.self.value.weight torch.Size([768, 768])
encoder.layer.11.attention.self.value.bias torch.Size([768])
encoder.layer.11.attention.output.dense.weight torch.Size([768, 768])
encoder.layer.11.attention.output.dense.bias torch.Size([768])
encoder.layer.11.attention.output.LayerNorm.weight torch.Size([768])
encoder.layer.11.attention.output.LayerNorm.bias torch.Size([768])
encoder.layer.11.intermediate.dense.weight torch.Size([3072, 768])
encoder.layer.11.intermediate.dense.bias torch.Size([3072])
encoder.layer.11.output.dense.weight torch.Size([768, 3072])
encoder.layer.11.output.dense.bias torch.Size([768])
encoder.layer.11.output.LayerNorm.weight torch.Size([768])
encoder.layer.11.output.LayerNorm.bias torch.Size([768])
pooler.dense.weight torch.Size([768, 768])
pooler.dense.bias torch.Size([768])分词器代码
# 从预训练路径加载中文 BERT 的分词器
mytokenizer = BertTokenizer.from_pretrained(bert_path)
# 待编码的文本
text = "我爱你"
# 调用分词器对文本进行处理
out = mytokenizer(
text,
padding="max_length", # 填充到最大长度(max_length)
truncation=True, # 超过 max_length 时截断
max_length=128 # 指定最大长度为 128
)
# 打印输出字典
print(out)酒店评价数
train_test_split
# 使用 train_test_split 将数据划分为训练集和验证集
# data: 特征数据列表,label: 对应的标签列表
# test_size=val_size: 验证集所占比例(如 0.2 表示 20%)
# shuffle=True: 划分前随机打乱数据
# stratify=label: 按标签比例分层采样,确保训练/验证集中各类别比例与原始数据一致
train_x, val_x, train_y, val_y = train_test_split(
data, label,
test_size=val_size,
shuffle=True,
stratify=label
)data.py
# data 模块:负责读取数据、划分数据集、创建 DataLoader
import torch
from torch.utils.data import DataLoader, Dataset
from sklearn.model_selection import train_test_split # 用于数据分割
def read_file(path):
"""
读取 CSV 格式的文本文件,提取标签和文本内容。
文件格式:第一行为标题,之后每行为 "标签,文本内容"(逗号分隔,仅分割一次)。
:param path: 文件路径
:return: (文本列表, 标签列表)
"""
data = [] # 存储文本
label = [] # 存储标签
with open(path, "r", encoding="utf-8") as f:
for i, line in enumerate(f):
if i == 0: # 跳过第一行标题
continue
line = line.strip("\n") # 去除换行符
line = line.split(",", 1) # 只分割第一个逗号
data.append(line[1]) # 文本部分
label.append(line[0]) # 标签部分
print("读了%d的数据" % len(data))
return data, label
class jdDataset(Dataset):
"""
自定义数据集类,__getitem__ 返回 (文本字符串, 标签张量)。
注意:返回字符串会导致 DataLoader 在 batch_size > 1 时无法自动堆叠,
因为字符串不能直接转换为张量。通常需要在 Dataset 内部完成文本到数值 ID 的转换。
"""
def __init__(self, data, label):
"""
:param data: 文本列表
:param label: 标签列表(字符串形式)
"""
self.X = data
# 将标签转换为整数,并封装为 LongTensor
self.Y = torch.LongTensor([int(i) for i in label])
def __getitem__(self, item):
"""
返回单个样本: (文本字符串, 标签张量)
"""
return self.X[item], self.Y[item]
def __len__(self):
return len(self.Y)
def get_data_loader(path, batchsize, val_size=0.2):
"""
读取数据,划分训练/验证集,并返回对应的 DataLoader。
:param path: 数据文件路径
:param batchsize: 批次大小
:param val_size: 验证集比例
:return: (train_loader, val_loader)
"""
# 1. 读取原始数据
data, label = read_file(path)
# 2. 划分训练集和验证集(按标签分层抽样,保证分布一致)
train_x, val_x, train_y, val_y = train_test_split(
data, label,
test_size=val_size,
shuffle=True,
stratify=label # 分层抽样,确保训练/验证集中各类别比例与原数据相同
)
# 3. 创建 Dataset 实例
train_set = jdDataset(train_x, train_y)
val_set = jdDataset(val_x, val_y)
# 4. 创建 DataLoader
train_loader = DataLoader(train_set, batchsize, shuffle=True)
val_loader = DataLoader(val_set, batchsize, shuffle=True)
return train_loader, val_loader学习率退火(Learning Rate Annealing)
在深度学习中,“退火”通常指训练过程中动态调整学习率的策略,使模型在初期快速探索,后期精细收敛。常见方法包括:
| 类型 | 描述 |
|---|---|
| Step Decay | 每隔固定轮数将学习率乘以一个衰减因子(如每 30 轮乘以 0.1)。 |
| Exponential Decay | 学习率按指数函数衰减:lr = lr0 * e^(-kt)。 |
| Cosine Annealing | 学习率按余弦函数从初始值下降到最小值(如 eta_min),形状平滑。 |
| Cosine Annealing with Warm Restarts |
余弦退火 + 周期重启(你代码中使用的)。每个周期学习率下降后跳回初始值,重新开始余弦下降,帮助模型跳出局部极值。 |
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer, T_0=20, eta_min=1e-9)-
optimizer:要调整学习率的优化器实例。 -
T_0:第一个重启周期的迭代次数(通常指 epoch 数)。即经过T_0次更新后,学习率将完成第一个余弦下降周期并重启。 -
eta_min:学习率的最小值(衰减下限),默认为 0。这里设为1e-9,表示在每个周期结束时学习率会降到1e-9,然后重启。
其他
超参数(Hyperparameters) 是机器学习模型训练前需要人为设定的参数,它们控制模型的学习过程和结构,而非通过训练数据直接学习得到。与模型参数(如神经网络的权重)不同,超参数的值通常在训练开始前固定,并在整个训练过程中保持不变(或按预设策略调整)。
损失函数(Loss Function) 是机器学习和深度学习中用来衡量模型预测值与真实值之间差异的函数。它的值越小,表示模型的预测越准确。训练模型的过程本质上就是通过优化算法(如梯度下降)不断调整模型参数,以最小化损失函数。
优化器(Optimizer) 是深度学习训练中用于更新模型参数的核心组件。它根据损失函数计算出的梯度,决定参数如何调整,以使损失逐渐减小。优化器的选择直接影响模型的收敛速度、最终性能和训练稳定性。
数据不平衡 是指分类任务中不同类别的样本数量差异巨大的情况。例如,在信用卡欺诈检测中,正常交易可能占 99.9%,而欺诈交易仅占 0.1%;在医疗诊断中,罕见病样本远少于健康样本。这种不平衡会导致模型偏向多数类,忽视少数类,从而影响实际应用效果。
-
模型偏向多数类:模型会倾向于将大多数样本预测为多数类,因为这样整体准确率很高,但少数类几乎无法被正确识别。
-
少数类性能极差:召回率(Recall)可能接近 0,模型对少数类几乎失效。
-
评估指标误导:准确率(Accuracy)不再是可靠指标,一个 99% 准确率的模型可能完全没有识别出任何少数类样本。
-
损失函数被多数类主导:标准损失函数(如交叉熵)对每个样本同等看待,导致梯度更新主要来自多数类。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)