深度学习周报(3.9~3.15)
目录
摘要
本周首先对克里金方程组的构建求解部分进行了学习,随后尝试用代码进行了不同经验变异模型的克里金插值对比,了解了实践中用到的具体参数;其次阅读了《Deep learning and process understanding for data-driven Earth system science》,了解了其背景与方法论等,为后续学习打下基础。
Abstract
This week, I first studied the construction and solution of kriging equation systems, then attempted to use code to compare kriging interpolation with different empirical variogram models, gaining an understanding of the specific parameters used in practice. Subsequently, I read the paper "Deep learning and process understanding for data-driven Earth system science," learning about its background and methodology, which lays the foundation for subsequent study.
1 克里金法(续)
1.1 预测与评估
在利用合适的模型对离散的变异函数经验点进行拟合,得到光滑的变异函数曲线后,克里金插值就进入了核心的预测阶段,这个阶段主要做的就是构建、求解克里金方程组得到最优权重,进而预测未知点的值并进行误差评估。
显而易见,构建并求解克里金方程组的目标就是为未知点 计算出各已知点
的最优权重
,这也是克里金与其他插值方法的核心区别,即这些权重并非单纯基于距离,而是通过求解一个保证无偏估计(权重之和为1)且估计方差最小(预测值与真实值方差最小)、同时还引入了变异函数的方程组得出的。方程组的标准矩阵形式如下:
其中 代表各已知点(例如
和
)之间的关系,
则代表已知点与未知点之间的关系,两者都是计算出两点距离,然后代入拟合好的变异函数模型计算得出。
在实际运用中,上述方程组可以直接调用相关函数进行求解,将得到的权重与已知点的观测值进行加权求和就能计算出未知点的克里金估计值。
克里金不仅能给出预测值,还能量化预测的不确定性,即克里金方差,其值越小,对该点的预测越可靠,公式如下所示:
1.2 代码
使用的数据集链接为:中国长、短历时暴雨雨量特征数据集(1961-2015) - Heywhale.com,其中包括中国 659 个站点的站点名称、经纬度以及从1961年至2015年各站点雨量变化趋势数据(包括年总降雨量、年总暴雨雨量、年短历时暴雨雨量和年长历时暴雨雨量)等数据,本次主要用到各站点经纬度与年总降雨量变化趋势进行克里金插值训练。
1.2.1 数据处理
首先,从下载的数据集中提取需要的数据,并生成插值网格。
filepath = r'...' # 自定义
df_data = pd.read_excel(
filepath,
sheet_name=0, # 默认读取第一个工作表
header=None,
skiprows=5, # 跳过前5行,从第6行开始读取
usecols=[1, 2, 3] # 读取B, C, D列
)
# 提取 X, Y, Z 数据
lat = df_data.iloc[:, 0].values # 第2列 (X 坐标)
lon = df_data.iloc[:, 1].values # 第3列 (Y 坐标)
z = df_data.iloc[:, 2].values # 第4列 (Z 值,降雨量)
# 定义插值网格,根据读取到的数据的经纬度范围生成 50x50 的网格点
min_lon, max_lon = lon.min() - 0.5, lon.max() + 0.5
min_lat, max_lat = lat.min() - 0.5, lat.max() + 0.5
grid_lon = np.linspace(min_lon, max_lon, 50)
grid_lat = np.linspace(min_lat, max_lat, 50)1.2.2 克里金插值
其次,定义克里金插值所用的变异函数与参数,并执行得到预测值与方差。
# 普通克里金插值()
OK = OrdinaryKriging(
lon, lat, z, # 位置参数
variogram_model='spherical', # 变异函数-球形 可选指数或高斯
verbose=False, # 是否在控制台打印拟合过程的详细信息
enable_plotting=False, # 是否自动弹出变异函数拟合图
nlags=20, # 计算实验变异函数时的滞后距离分组数
weight=True # 拟合函数时是否对滞后距离加权,是则能减少远距离噪声的干扰
)
z_interp, z_variance = OK.execute('grid', grid_lon, grid_lat) # 预测值与方差
# 对插值结果做轻度高斯平滑
z_smooth = gaussian_filter(z_interp.data, sigma=1.0)nlags 决定了实验变异函数被分成多少个距离区间,如果值太小,可能无法捕捉到精细的空间结构;反之,如果太大,每个区间可能数据点太少,会不稳定。
1.2.3 可视化与统计
最后,进行可视化,所得结果如下,包括选用球状模型、高斯模型与指数模型三种情况。
球状:
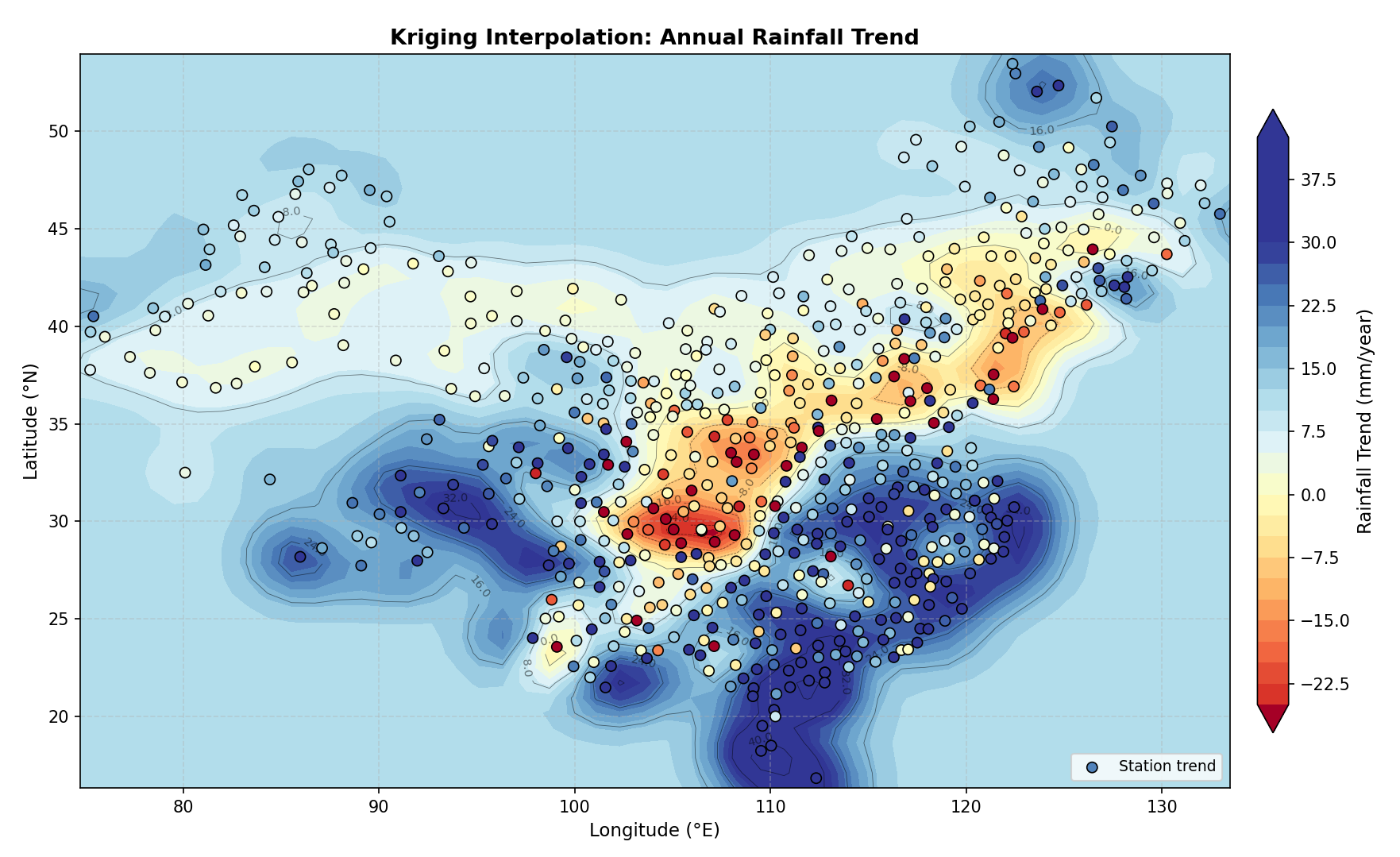
其克里金方差均值为 465.2404,最小值为 103.0230,最大值为 552.4022。
高斯:
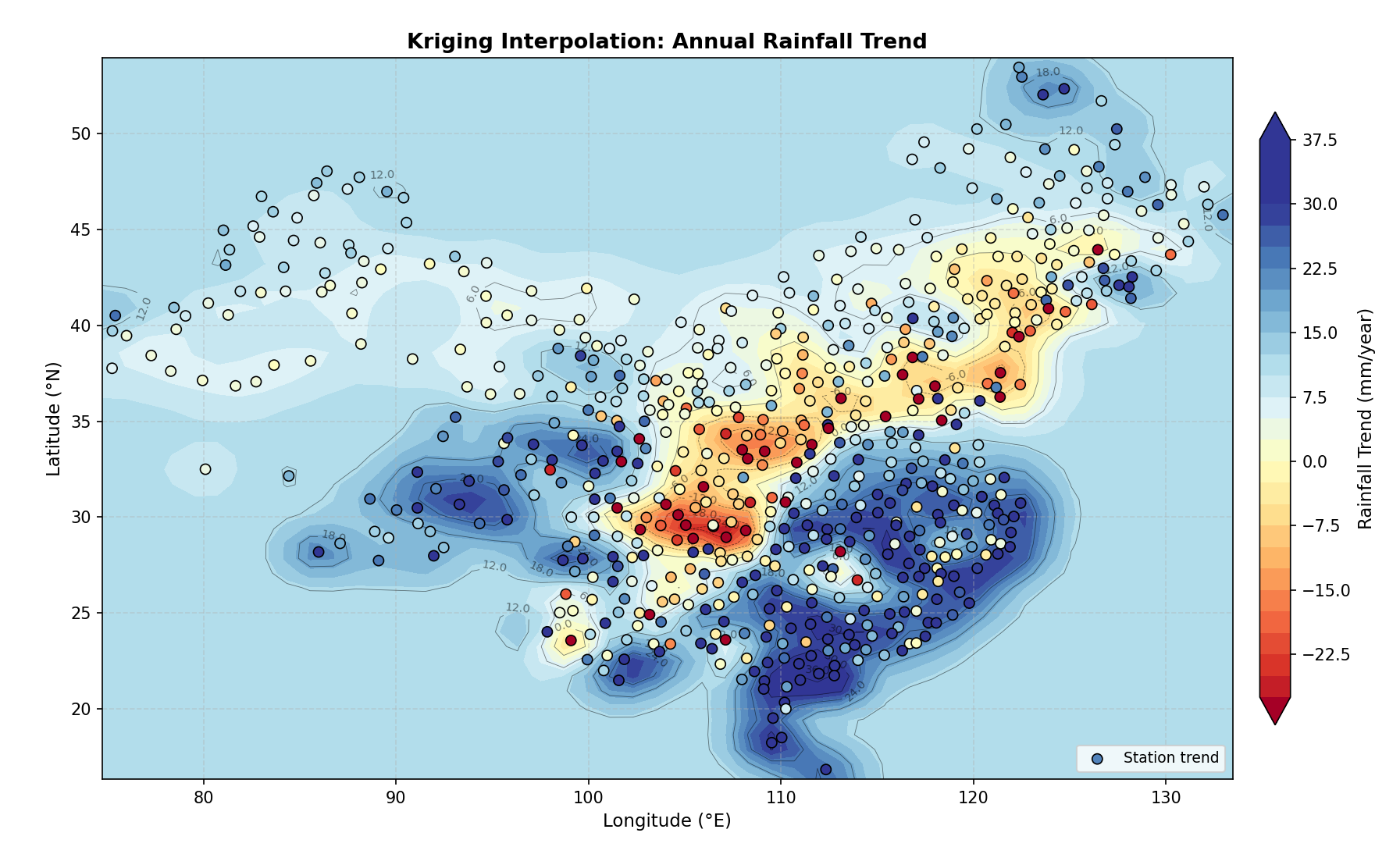
其克里金方差均值为 443.3411,最小值为 69.5684,最大值为 560.9453。
指数:
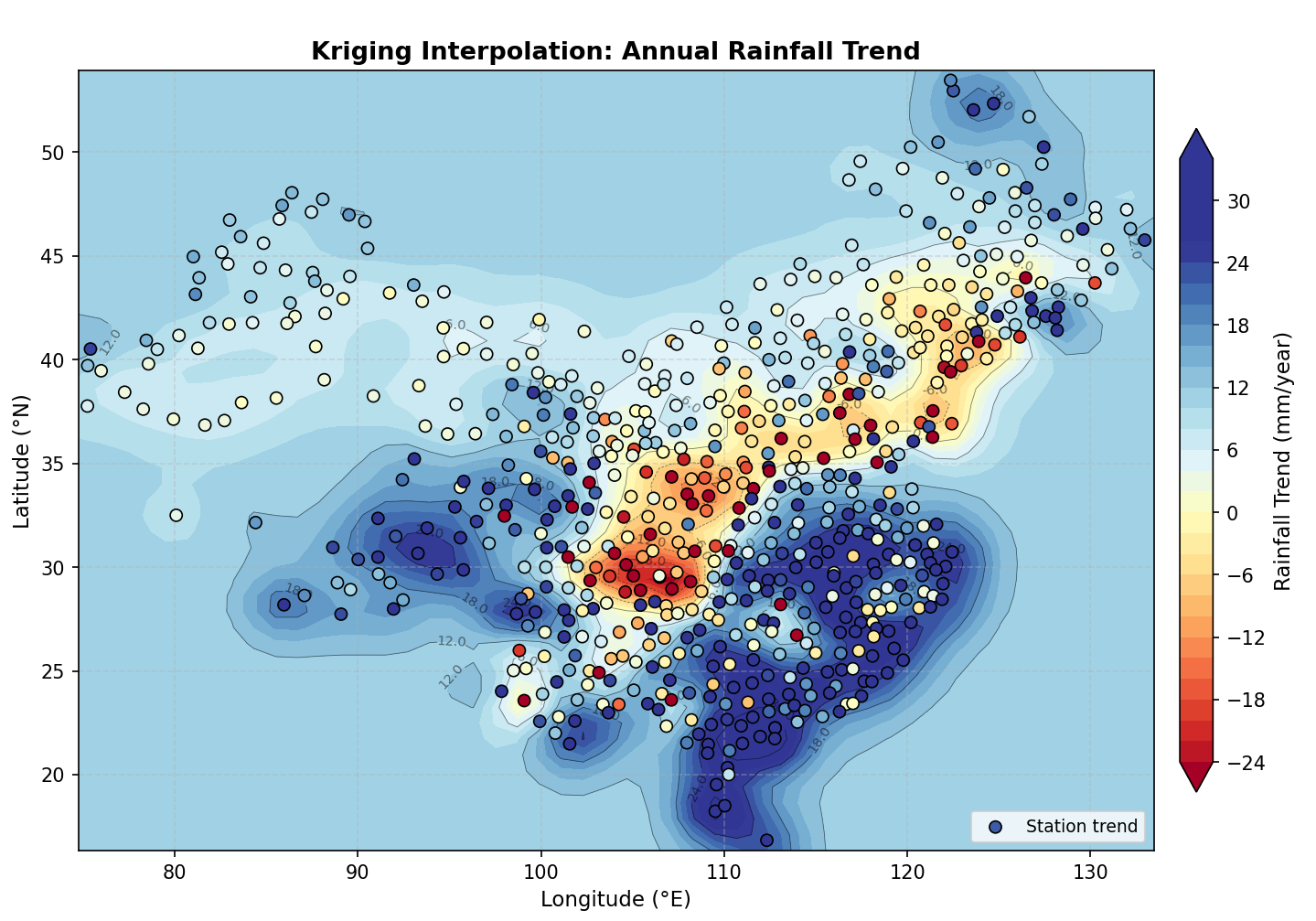
其克里金方差均值为 489.7661,最小值为 15.3661,最大值为 559.6664。
三者方差都比较高,打印拟合的详细信息发现变程值都较小。造成这种情况出现的一个原因可能是数据量比较少,空间相关性不明显;另一个原因则可能在于 pykrige 默认按欧几里得距离处理,会把经纬度差值直接当成平面距离来算,在大尺度区域,1个经度在赤道附近约111公里,但在高纬度地区则短很多,这样计算的“距离”是不准确的,会影响变异函数的计算和拟合。
2 论文阅读
本周阅读了一篇发表于2019年的综述类论文:《Deep learning and process understanding
for data-driven Earth system science》,其下载链接为:Deep learning and process understanding for data-driven Earth system science | Nature
2.1 背景
一方面,地球系统科学正面临着数据挑战。由于现代科学技术的发展,涵盖遥感、地面观测、模型模拟等多种来源的数据具有体量大、速度快、种类多、真实性不确定的“四V”特征,但在许多应用场景中,尤其是在生物圈动态、火灾、滑坡等复杂系统中,传统物理模型进展十分有限。
另一方面,机器学习虽已在地球科学,如土地覆盖分类、土壤属性预测、碳通量估算等场景中广泛应用,但更强调空间预测,即预测在观测时间段内相对静态的属性,在处理空间和时间上下文时表现有限,往往难以捕捉动态系统中的“记忆效应”和空间依赖性。
2.2 方法论
首先,通过表格对比了几类任务的传统方法与深度学习方法,包括分类与异常检测、回归以及状态预测等,认为深度学习(尤其是 CNN 和 RNN)能自动从数据中提取时空特征,避免手工特征工程的局限,适用于多维、多尺度、多源数据。
其次,虽然物理建模与机器学习经常被视为两个不同的领域,但实际上它们能够互补,并提出了五个潜在的“协同点”,包括参数化学习(用机器学习优化模型参数)、模型替换(用神经网络替代经验性强的生物过程子模型)、模型-观测偏差分析(用机器学习识别物理模型的系统性误差)、子模型约束(用机器学习输出驱动子模型,减少耦合误差)以及替代建模(用机器学习替代计算昂贵的物理模块。
2.3 创新点
本文的创新点主要包括:
第一,强调深度学习在处理时空上下文方面的独特优势,认为应将物理一致性作为模型训练的重要约束,应针对地球系统数据特性(多源、异构、高维、缺失、不确定性)开发定制化网络结构,避免预测结果违反自然规律。
第二,将物理模型与机器学习的结合从替代扩展到互补,提出五种协同路径,形成系统化的建模框架,比如在运动场学习中引入物理方程(如热量传输),使模型既具物理可解释性,又具数据适应性。
第三,强调可解释性与不确定性,提出应发展可解释AI,使模型预测准确的同时能够提供因果解释,并鼓励引入贝叶斯/概率编程以处理数据与模型的不确定性,进而提升模型的科学可信度。
2.4 实验结果
虽然论文本身是综述性质的,但引用了大量已有研究成果作为支撑,具体包括:
第一,极端天气识别。Racah (2017) 和 Liu (2016) 使用 CNN 从气候模型输出中自动识别飓风、大气河流等极端天气事件,无需人工设定阈值。
第二,碳通量估算。Jung (2011, 2017) 使用神经网络从 FLUXNET 数据中估算全球陆地光合作用与蒸散发,揭示了气候模型对热带雨林生产力的高估。
第三,降水临近预报。Shi (2015, 2017) 提出 ConvLSTM 模型,结合 CNN 与 LSTM,显著提升了短时降水预报的准确性。
第四,混合建模示例。de Bezenac (2017) 使用深度学习学习海洋运动场,再结合物理模型预测海表温度,体现出“物理+数据”融合的优势;Gentine (2018) 用机器学习替代大气对流参数化方案,改善了气候模型的长期偏差。
3 总结
本周首先对克里金插值的预测与评估,也即克里金方程组的相关部分进行了了解,随后用代码大致尝试了采用不同经验变异模型的克里金插值,文中的是调过 nlags 的结果,可惜方差都比较高,后续有空的话可能会去认真调下其他可以用的参数,比如说看到可以设置用地理坐标系计算距离解决文中提到的第二个可能原因。其次,阅读了一篇综述类的论文,读得比较浅显,感觉综述类的文章在学习某个领域之前和学习一段时间之后再读可能理解会不一样。另外就是,觉得需要找一篇新一点的综述类文章读,这篇时间有点早,涉及到的技术目前不一定还好用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)