基于卷积神经网络模型的图像分类
一.回归任务与分类任务输出的区别
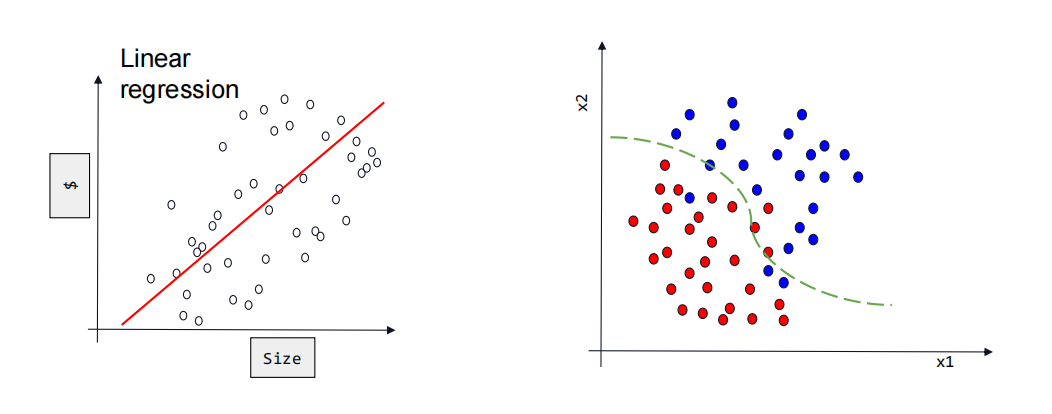
从图像上看,回归是将各个预测点回归拟合一条合适的,loss最小的直线或者曲线;
分类是将各个不同种类的数据通过一定的分类划分方法,划分为一类或者几类;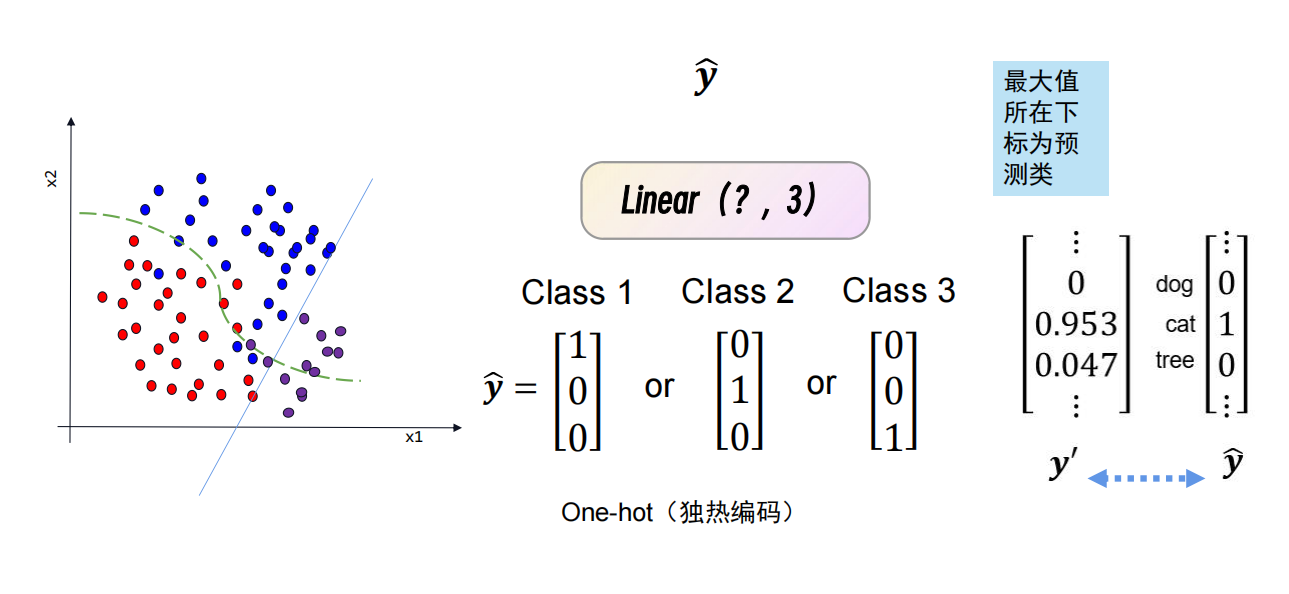
从向量上看,回归的向量里面的值是一个值,表明对应元素成为分类结果的概率大小;
分类的向量是在回归的基础上做归一化softmax的处理,将概率较大的那个类的值设为1,其余设为0. (这样做的主要目的:由于分类任务是独热编码,向量中哪个值是1,就代表对应的哪一类,所以当向量归一化后,就可以直接判断是哪一个种类了)
二.训练的流程(本质与回归类似)
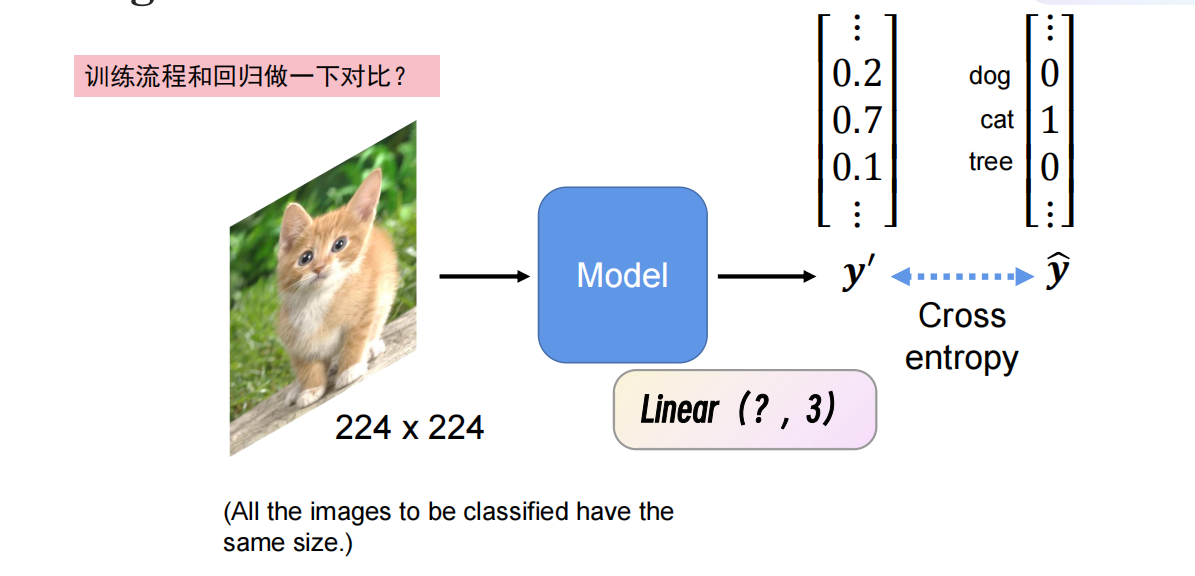
一:本质还是让图片进入模型,然后模型回归拟合出合适的向量,最后对该向量进行归一化。
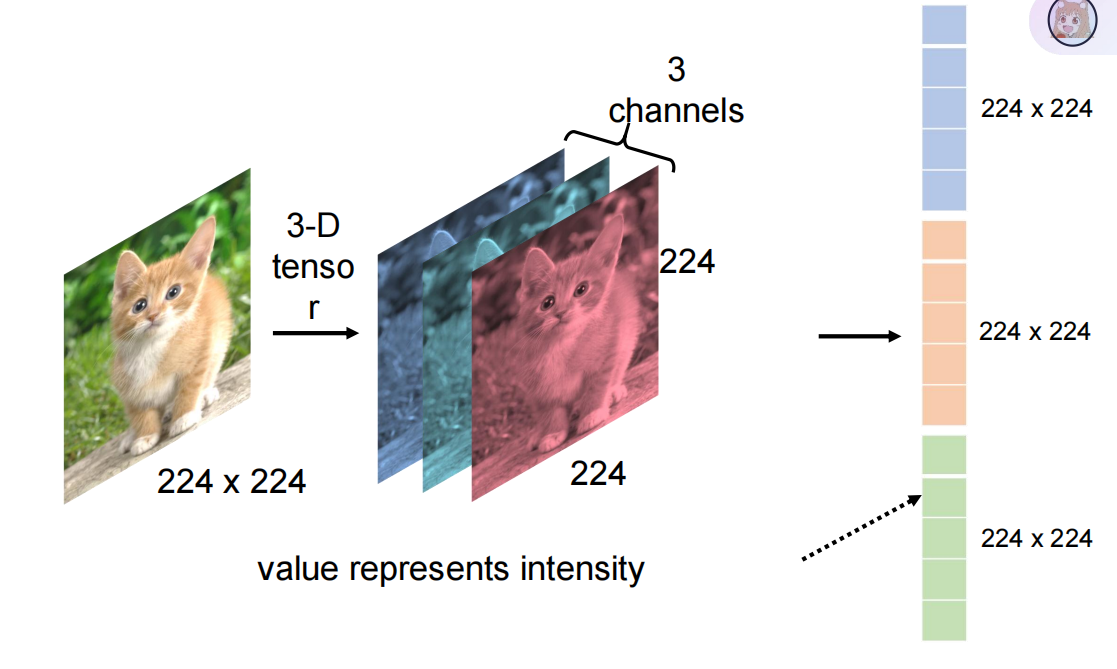
二:主要方式:将图片的所有参数(224*224*3)拉直成150528的参数的向量,然后让它进入模型训练。
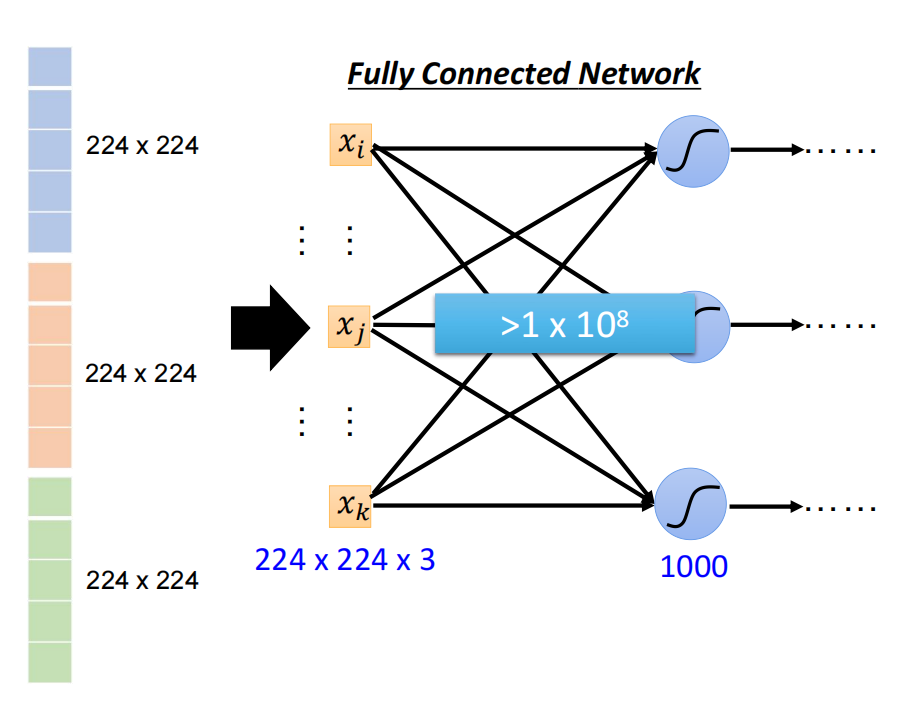
三:最后经过全连接网络,得到最后的预测值。
三.卷积神经网络
在上述的基本流程中,最大的问题在于参数量过大,从而会导致模型负载过高,所以引入卷积神经网路这一手段。
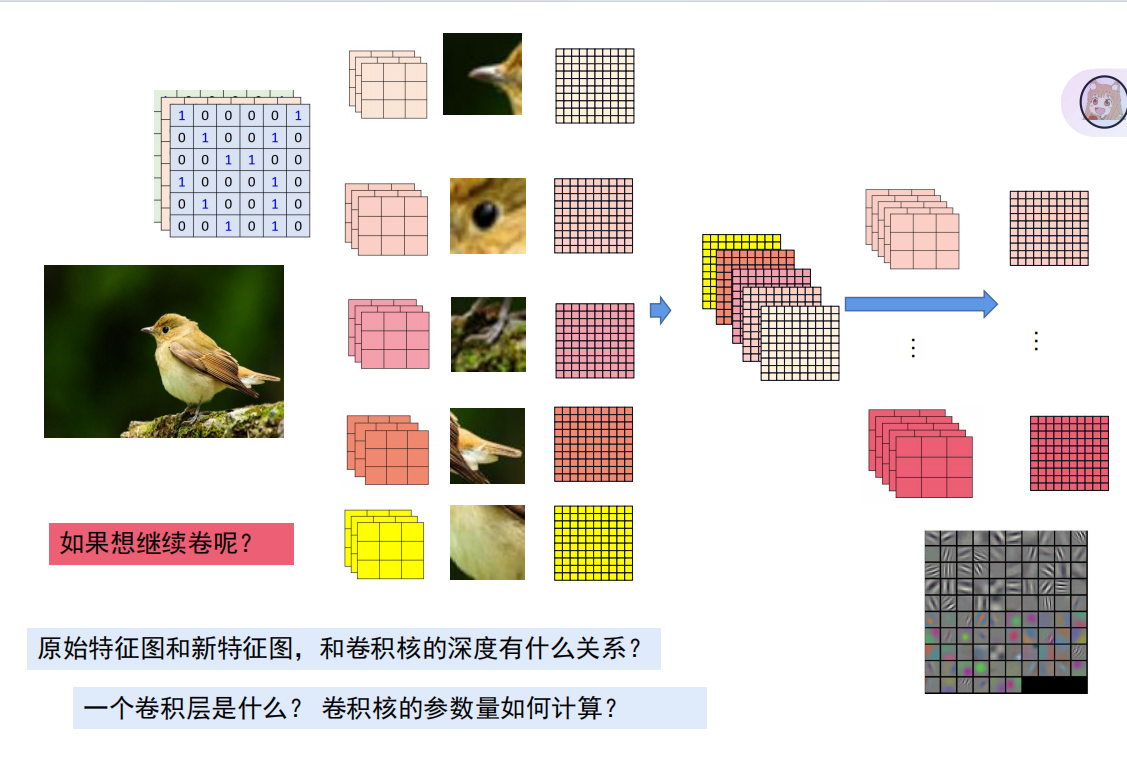
卷积的概念:在大图中找到小图,矩阵点乘的形式,数值越大,说明大图中越可能出现与小图相似的部分。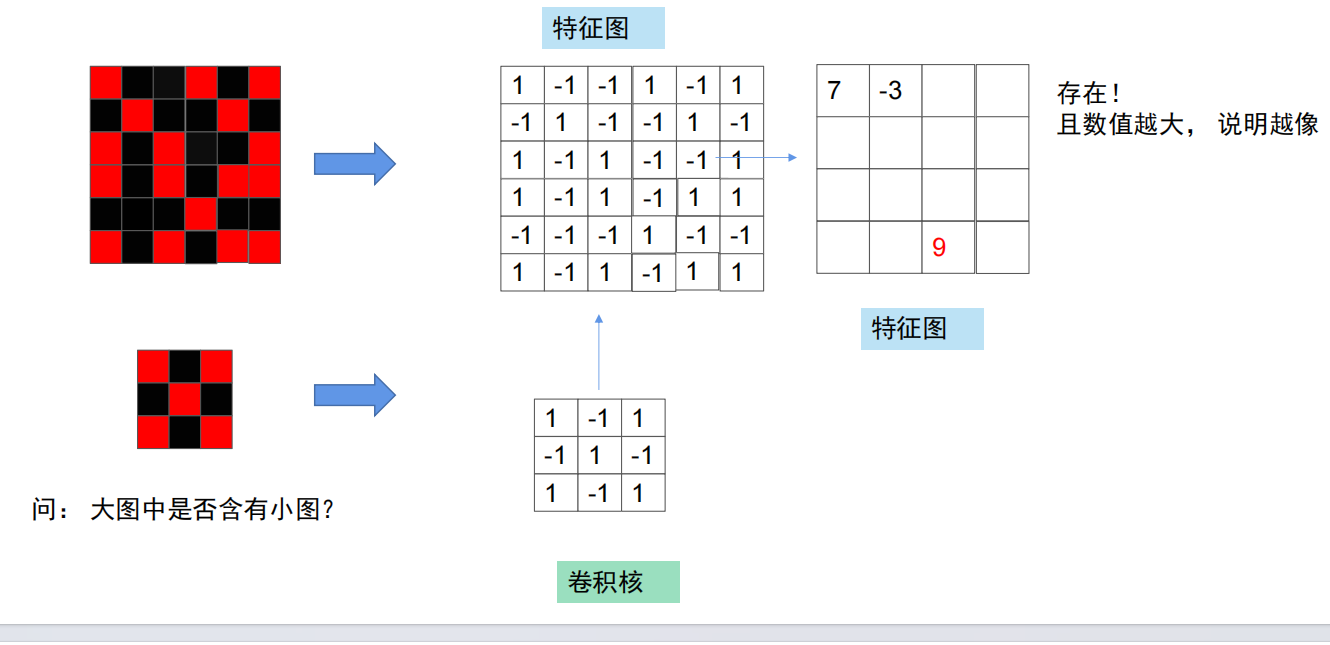
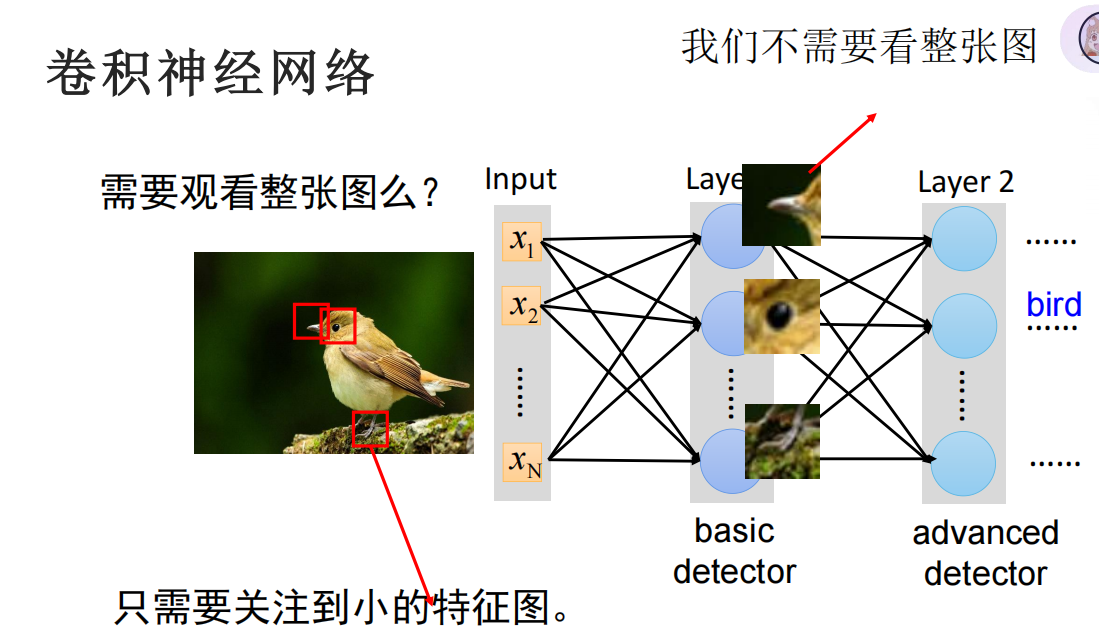
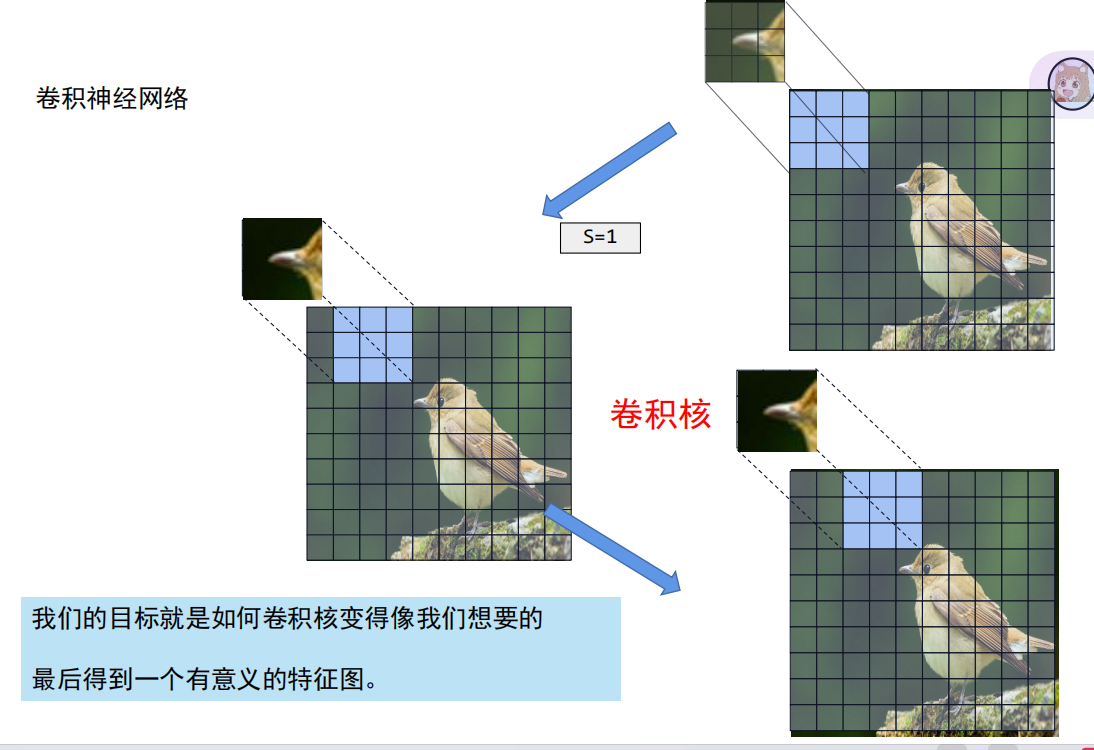
而将其实际应用到分类任务中,我们可以把卷积核看作一个特征,只需要在原图中找到该特征就可以说明此图大概率就是该特征的类别。(比如,分辨一种鸟的种类,可以将其鸟嘴,翅膀,脚等等作为特征,这要原图中有出现此图片,就可以说明它是这一种鸟)
卷积最大的功能:在第一张例图中,我们可以明显的看到,当用3*3的卷积核去与6*6的特征图卷积后,得到的结果是4*4的矩阵(明显参数减少了!),所以运用在卷积神经网络中,可以把多个图片的参数量实现大幅的减少。
当然,最后如果需要将output的特征图输出大小要与原图一样的大小时,可以通过zero padding的方式(在在特征图的边缘补充像素(通常补 0),抵消卷积核滑动带来的尺寸收缩。)
卷积核的不同分类:

四.进一步理解如何让特征图变小
1.扩大步长:
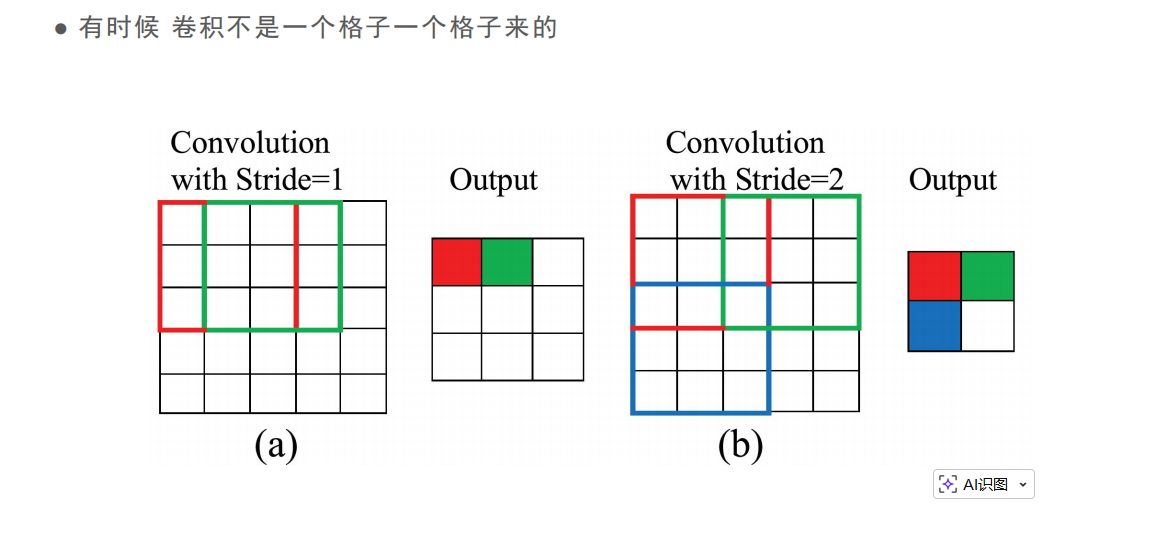
原来的卷积是每卷一次就只会让卷积核向后走一格,而扩大步长就是每卷一次后卷积核走多步,这样最后卷出来的特征图就会小很多。

2.池化pooling
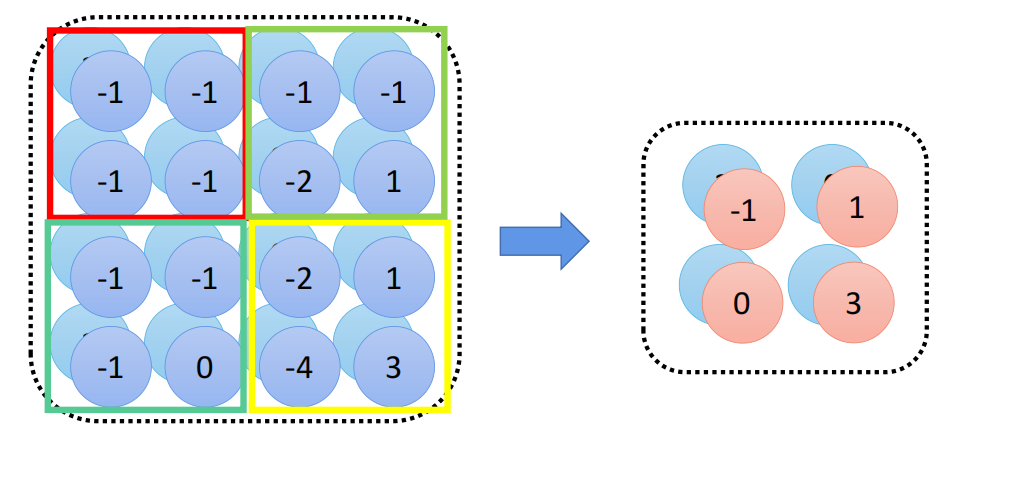
池化的本质在于用一个参数来代表一个范围内的参数,这样也一定程度上减少了参数量的计算。
常见的池化有两种:
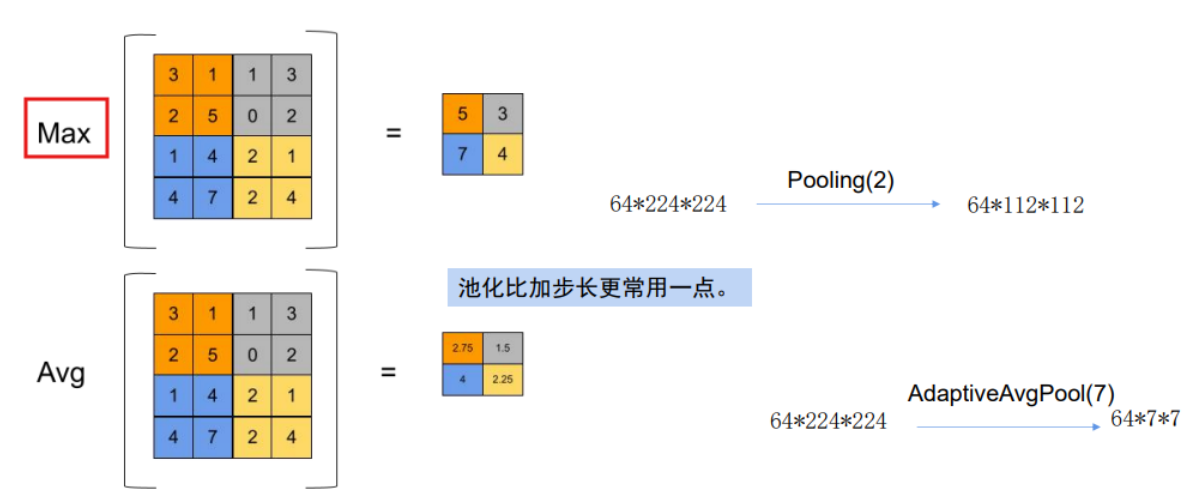
- 最大池化(Max Pooling):取局部区域的最大值,能更好保留边缘、纹理等强特征,是图像任务的首选;
- 平均池化(Average Pooling):取局部区域的平均值,能保留更平滑的全局特征,多用于分类层前的特征整合。
在本项目中,也是使用最大池化作为池化方式,这样主要是可以减少模型的运算负担。
五.卷积神经网络的参数
CNN的主要结构是卷积层,全连接层,池化层和BN层(归一化)等,而90%的参数都在卷积层和全连接层上面。
卷积层(nn.Conv2d):
卷积层主要参数为权重参数和偏置参数:
权重的参数主要来自图片的形状(输入的通道数,输出的通道数,卷积核高,卷积核宽)eg nn.Conv2d(输入通道数,输出通道数,卷积核大小),参数量=输入通道数*输出通道数*卷积核大小的平方。
偏置的参数主要数如的通道数量。eg64个通道数,偏置的参数就有64个。
全连接层(nn.Linear)
全连接层层的主要参数也是权重和偏置参数:
权重的主要参数nn.Linear(输入维度,输出维度),总的参数量是输入维度*输出维度
偏置的主要参数是输出维度,有多大的输出维度就有多少和偏置参数。
六.通过卷积卷出一个类别
卷积的基本流程:卷积提取特征->fallten拉直->类别输出->loss计算->参数更新
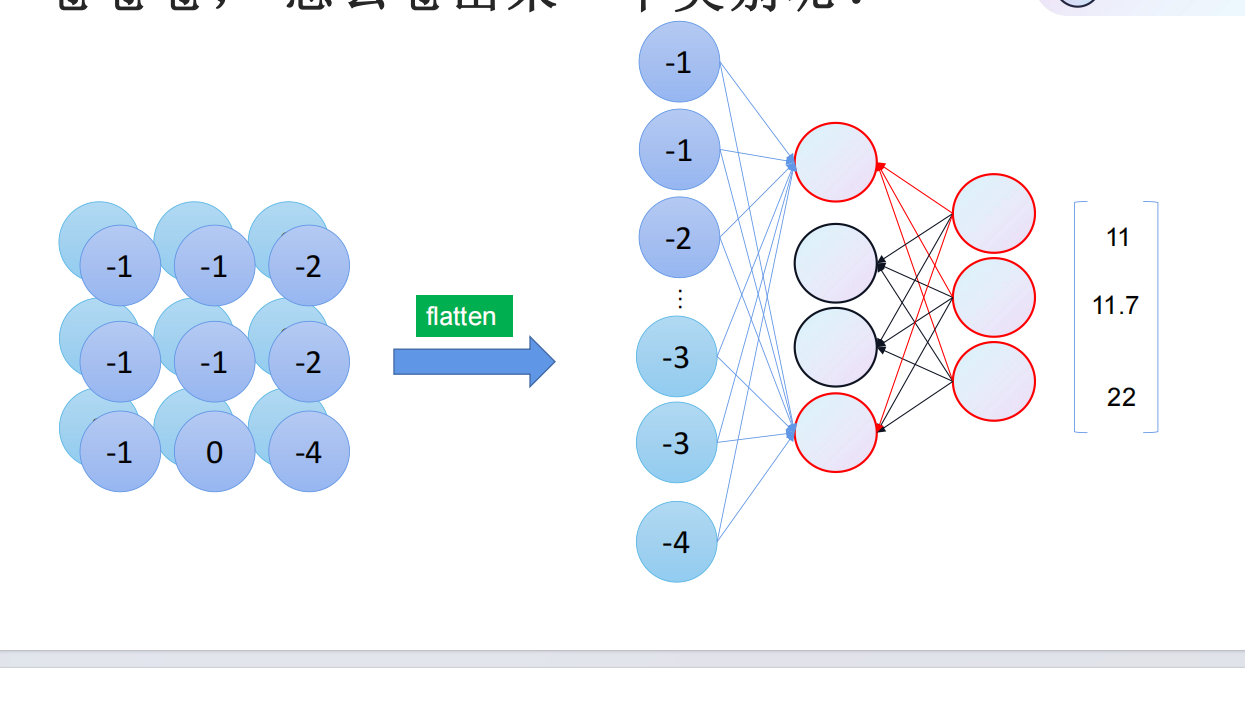
将特征图通过卷积核卷出来的心特征图通过flatten函数,将参数拉直,然后就可以通过全连接来预测loss,并梯度回传到model中,更新参数。

分类任务的loss与回归任务的loss有所不同,回归任务直接Linear后的张量值就可以当作参数来计算Loss,但是分类任务主要是对错的问题,所以要先通过softmax来将张量值转化为归一化后的独热编码类型的张量。
七.计算Loss
多分类任务主要使用交叉熵损失
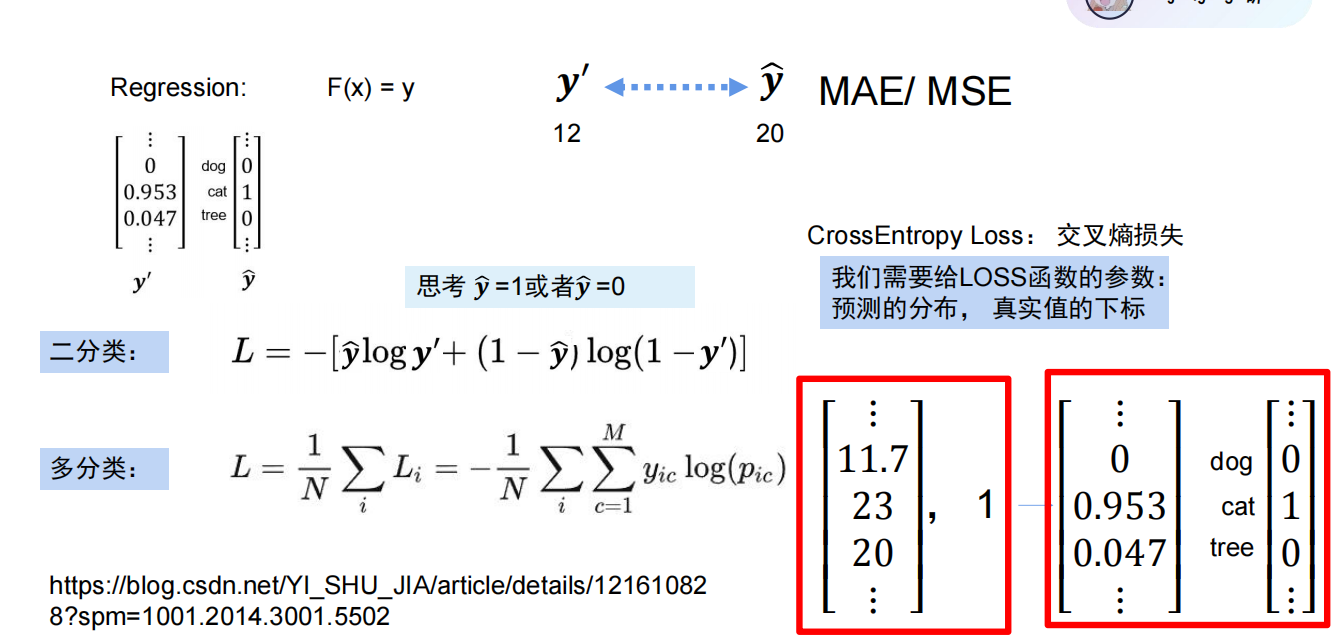
对比均方误差(MSE),交叉熵损失有两个核心优势:
- 梯度更合理:分类任务中,MSE 的梯度会随预测概率接近 0/1 而趋近于 0(梯度消失),交叉熵损失的梯度与预测概率直接相关,训练更高效;
- 贴合分类目标:分类关注的是 “类别概率的相对大小”,而非 “绝对数值”,交叉熵损失直接衡量概率分布的差异,更贴合任务本质。
交叉熵损失的计算例子:

最后,在计算出对应的Loss后,会经过Loss回传。因为Loss的计算本质是为了让模型更好的更新参数权重和偏置,计算梯度,再用优化器更新参数的模型。
优化器的种类
1.SDG: 在每一轮的训练中,在各轮损失函数中通过在某一高位上施加一个动量,让Loss到达Loss最低的点,同时保存该模型的参数。
2.Adam:把L2正则融入梯度里,这样通过在损失函数假L2惩罚项实现对应效果
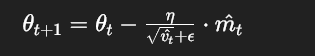
这个损失函数不仅考虑了当下的参数对模型的影响,同时还考虑了以往参数对模型的影响,并针对二者加以一定的权重。
3.AdamW:把L2从梯度中抽离,独立施加
不修改损失函数,先计算纯任务梯度的Adam更新量,再单独减权重衰减项。
loss=loss+w*w ,w*w是为了让梯度衰减更加平滑。
八.经典的神经网络模型
1.Alexnet
AlexNet 是深度学习与计算机视觉的里程碑式卷积神经网络,2012 年由 Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton 提出,在 ImageNet 竞赛中以 15.3% Top-5 错误率碾压传统方法(亚军 26.2%),正式开启深度 CNN 时代。
主要的创新点:
1.激活函数:将原先的sigmod函数换成relu,可以防止梯度消失的现象。
因为梯度的累成的,如果大部分的梯度过小,就会导致梯度消失的现象出现。而sigmod的梯度最大是0.25,是比较容易出现梯度消失的状况的。而relu的梯度最大的1,不容易出现梯度消失的状况。
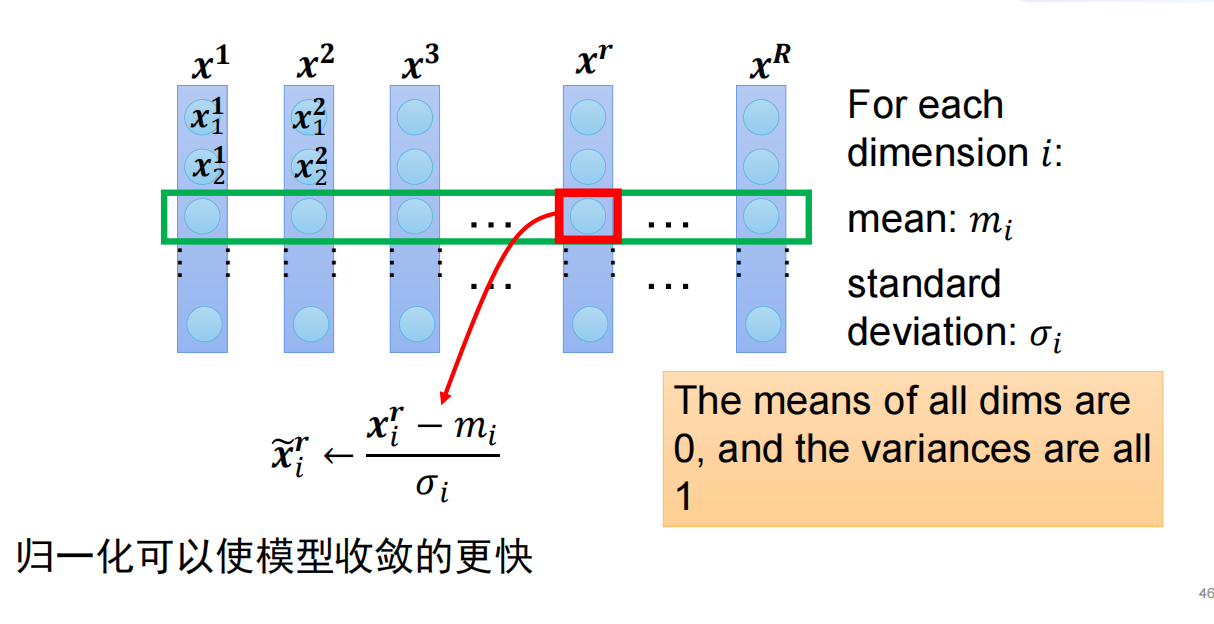
2.归一化
它可以让模型关注数据的分布,而不受数据量纲的影响。 归一化可以 保持学习有效性, 缓解梯度消失和梯度爆炸,提高模型的泛化能力。
3.池化
采用 3×3 窗口、步长 2 的重叠池化(非传统无重叠),减少过拟合,Top-1/Top-5 误差分别降低 0.4%/0.3%,增强特征鲁棒性。
4.dropout
主要功能是让模型在训练的时候少添加部分数据,而在验证的时候多添加上这部分数据。这样可以有效的防止过拟合的现象,还提高了模型的泛化能力。
2.VGG模型
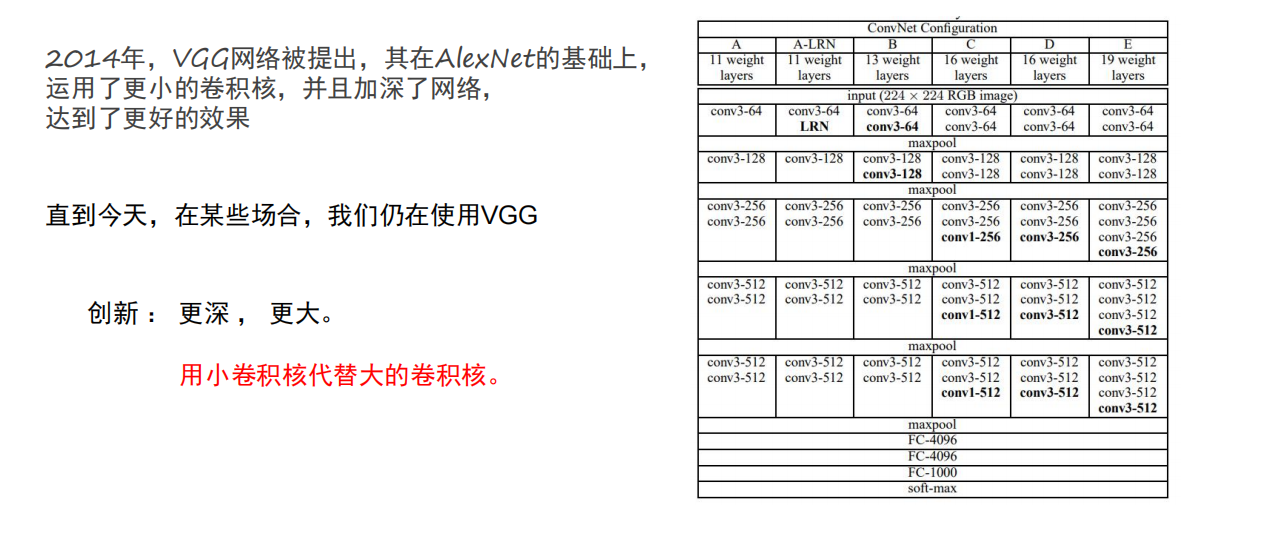
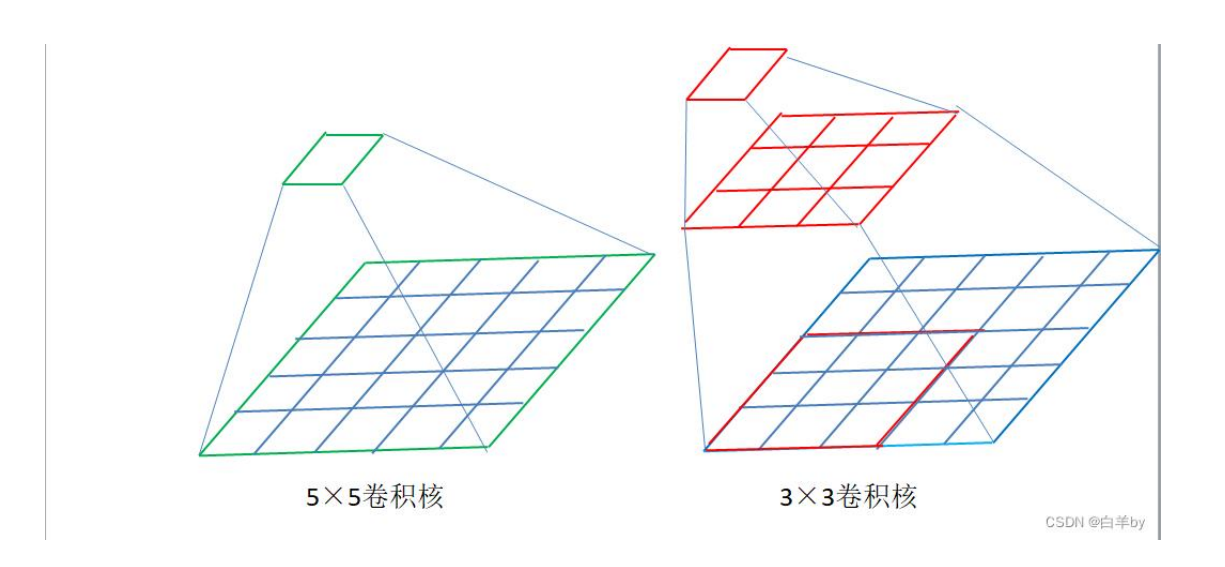
主要的功能是在感受野相同的情况下,堆叠 3×3 小卷积核替代大卷积核(更深,更大)。从而参数量大幅减少,大幅降低模型复杂度,缓解过拟合。
3.resnet18
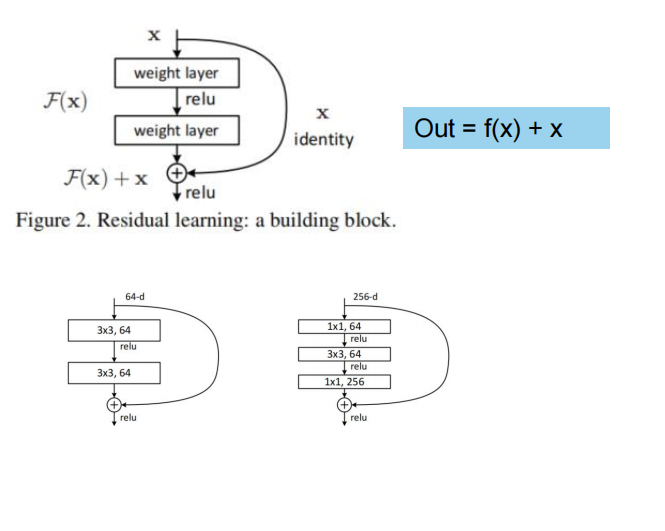
1.ResNet 解决的致命问题:梯度消失 + 网络退化
- 以前大家以为:网络越深,效果越好。
- 实际发现:层数太深 → 准确率不升反降(不是过拟合,是退化)。
- 根本原因:梯度在反向传播时一层层衰减,梯度消失,底层参数根本学不动。
2. ResNet 核心创新:残差块(Residual Block)
公式
y=F(x)+x
- x:输入
- F(x):卷积层学到的特征
- 直接把输入 x 加到输出上(捷径 /skip connection)
直观理解
-
不是让网络去学 “完整输出”,而是让它学残差(差值):F(x)=y−x
-
就算卷积啥也没学到,至少还能恒等映射过去,不会越学越烂。
3. 为什么残差连接能解决梯度消失?
反向传播时梯度:∂x∂y=∂x∂F+1
- 梯度 = 卷积层梯度 + 1
- 永远不会变成 0
- 梯度可以直接沿着捷径传回底层
这就是 ResNet 能堆到 101 层、152 层、甚至 1000 层 的原因。
4. 两种经典残差块
① 基本残差块(ResNet18/34)
conv → BN → ReLU → conv → BN → +x → ReLU
② 瓶颈结构(ResNet50/101/152)
1×1 降维 → 3×3 卷积 → 1×1 升维减少计算量,能堆更深
本质上,残差连接的公式告诉我们,output的数据不仅要把模型预测的输出,还要把过去的数据也一并输出。
1*1卷积
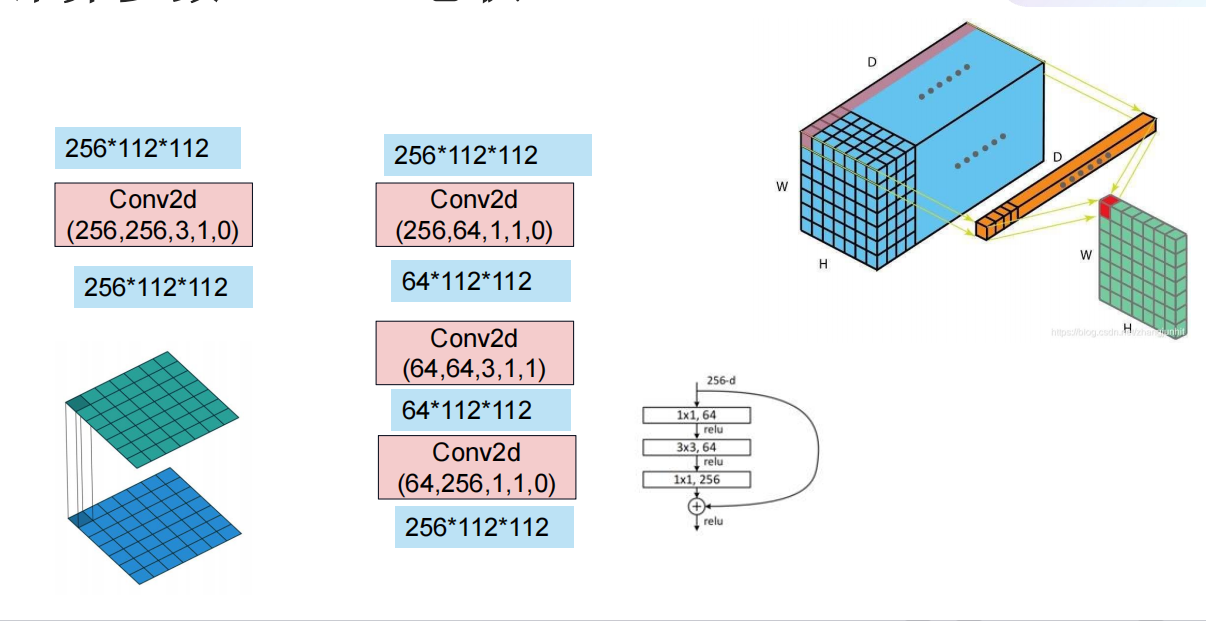
1. 降维 / 升维(通道数调整)
- 把 通道数变少:减少计算量
- 把 通道数变多:增强特征
这是 ResNet 瓶颈结构(bottleneck)的灵魂。
2. 跨通道信息融合(特征交互)
每个像素会对所有通道做加权求和。相当于让不同通道的特征互相交流。
3. 引入非线性,增加模型表达能力
1×1 卷积后面加 ReLU,不改变尺寸,却能加深网络、增强表达。
1*1卷积让模型得到更深更大的扩展,本质是因为减少了参数量。
实战
实战中主要运用到pytorch中的nn库,nn库的主要功能是全连接和卷积,当然还有其他神经网络的工具。

训练模型的总体流程:

主要是三个模块:处理数据集,定义模型,定义超参数。
分类任务的训练和验证的不同流程区别:
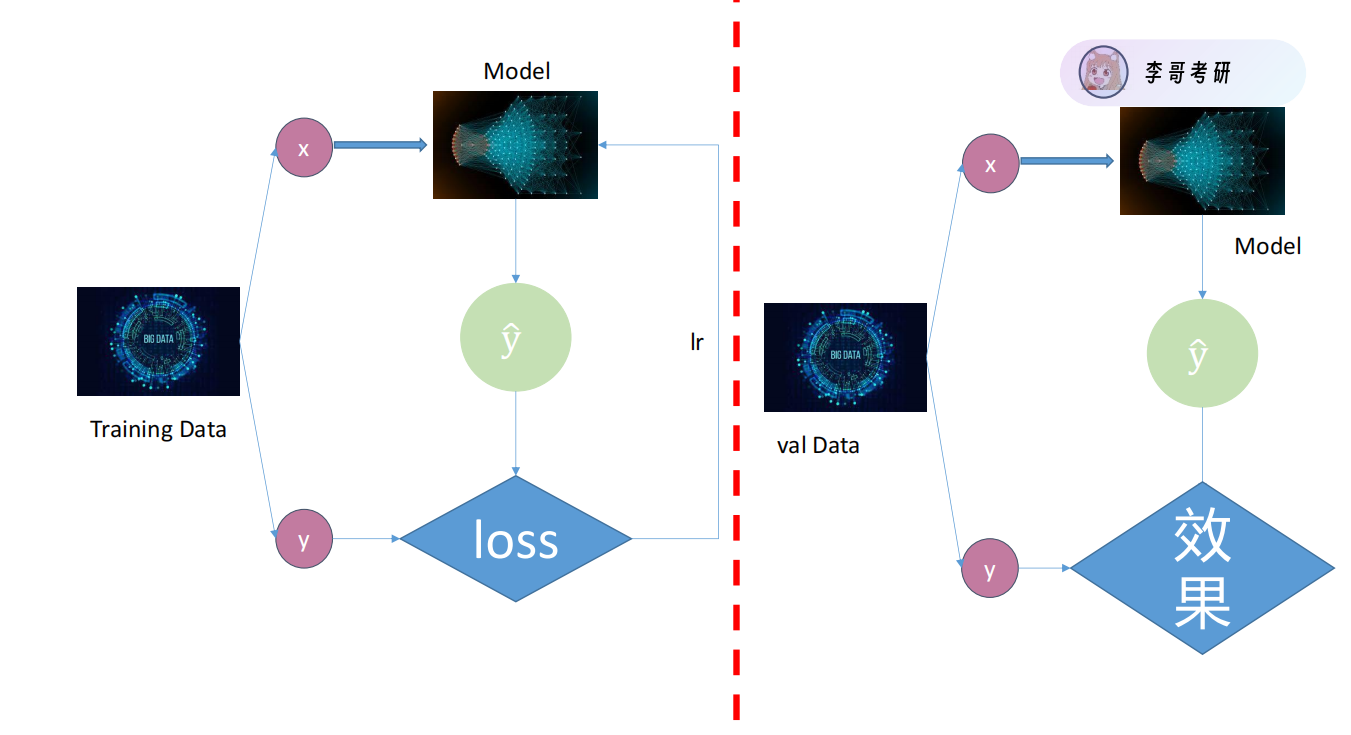
训练的时候,模型会通过y估计与真实值的差距(loss),来做梯度回传,让模型的权重和偏置参数做一定的优化。
测试的时候,模型就不用求loss了(因为没有真实值),预测值就是y估计。
导入所需要的库函数
对数据进行数据增广

数据增广就是对训练图像做合理的随机变换(翻转、裁剪、颜色抖动等),扩充数据多样性,减少过拟合,提高模型泛化能力。训练用,测试不用(因为数据增广的目的的让模型有更多的数据得到训练,而不是让模型在测试时增加负担)。

测试时,就不需要数据增广,直接做合适的全连接让图片顺利进入模型即可。

区分模式(分为测试下、训练下和半监督下),不同模式所要针对的运行方式不同。
要注意梯度计算时的三个重要步骤:

分别是梯度回传,更新优化器,梯度清零
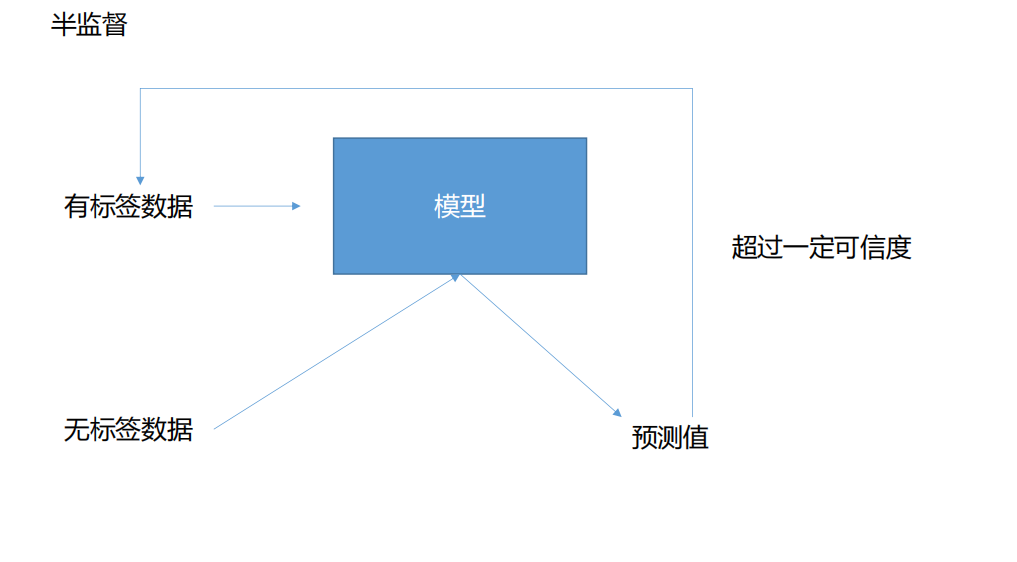
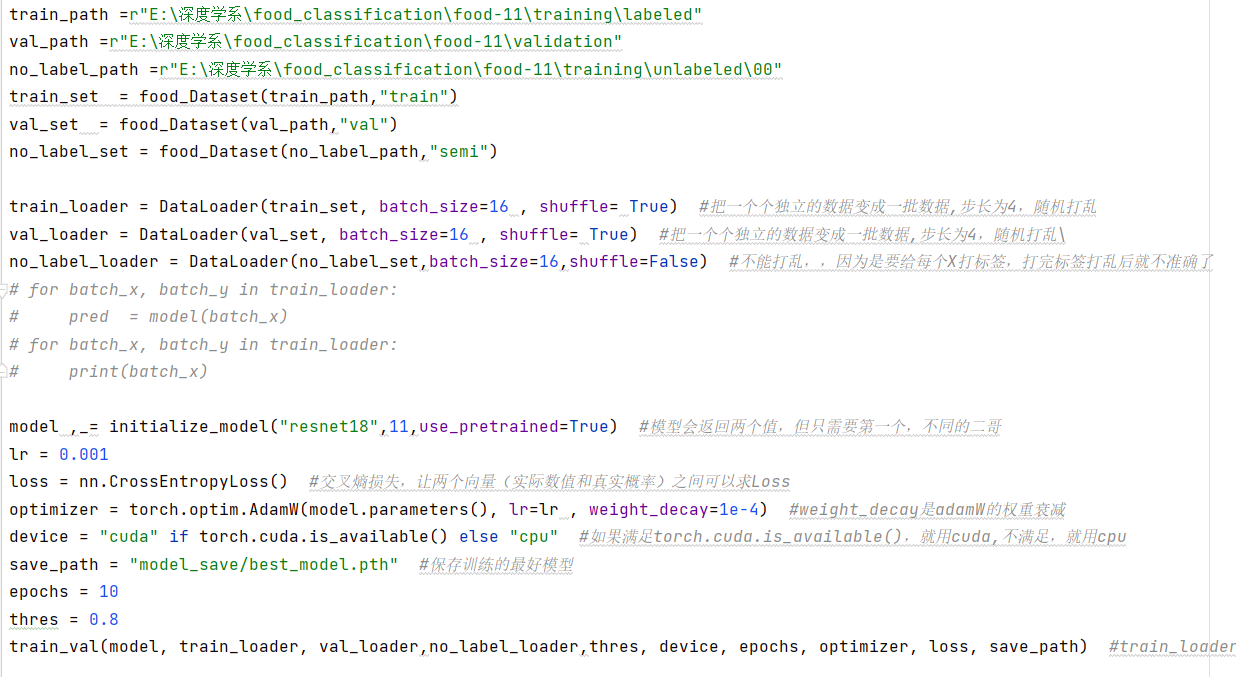
设置半监督下数据的处理方式

半监督模式下,先将有标签的数据拿去训练模型,让模型的准确率达到0.9以上后,再让无标签数据进入模型训练,只有那些经过模型后置信度达到0.9以上的数据才会让模型所做的预测值作为有标签数据的标签,这样就可以让无标签数据转化为有标签数据,增加模型的可训练数据量。
迁移学习
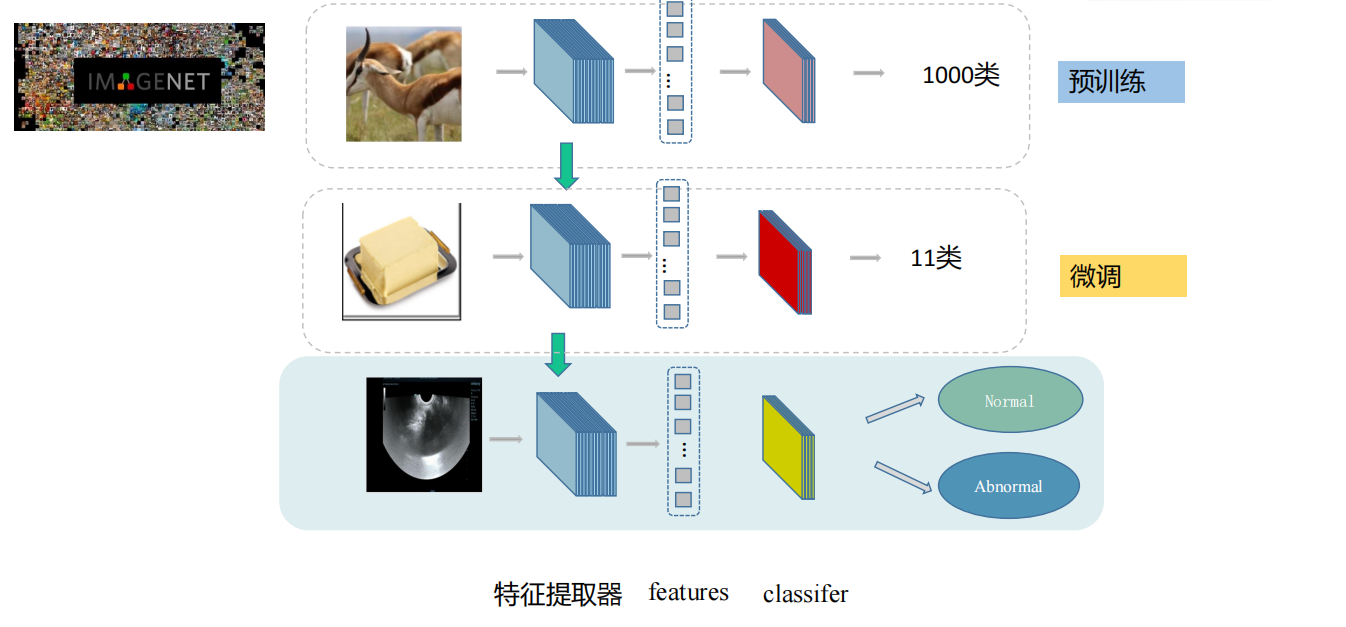
迁移学习是将源任务训练好的模型权重或特征知识,迁移应用到目标任务中,利用通用特征提升小样本下的训练效率与泛化能力,是深度学习中解决数据不足、训练成本高的核心技术。
微调,是基于原始模型下对模型进行针对性的数据训练(就是将符合项目的数据投喂给模型,提高模型针对此项目的泛化与适应能力)
提取特征其器(设置分类头),将模型输出后的数据通过一个全连接数据成符合类别的张量。
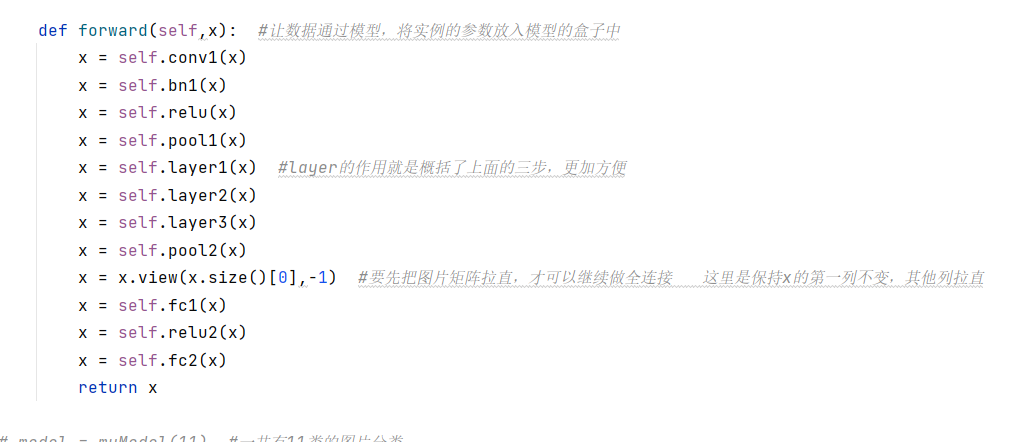
设置模型
超参数的设置

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)