OpenViking实战:字节跳动开源AI代理上下文数据库部署与应用全指南
·
一、项目概述
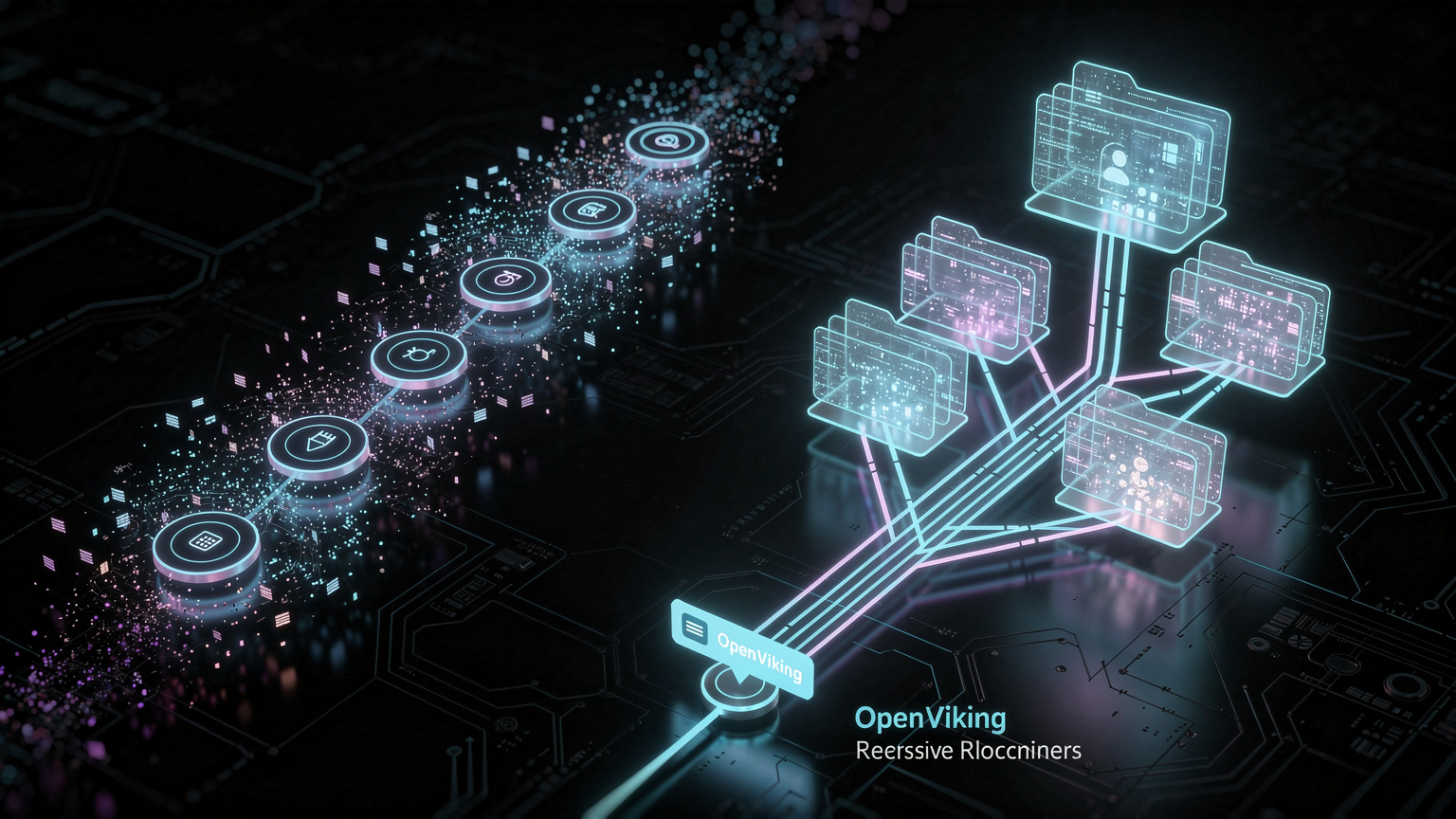
OpenViking是字节跳动开源的AI代理上下文数据库,专门解决复杂AI代理系统中的上下文管理难题。传统RAG方案在长期、多步骤任务中面临成本高、效率低的问题,OpenViking通过文件系统范式和三层加载策略,显著提升性能并降低成本。本文将详细讲解OpenViking的部署、配置和实战应用。
二、环境准备
2.1 系统要求
- 操作系统:Linux/Windows/macOS(推荐Ubuntu 22.04+)
- 内存:至少8GB RAM(生产环境建议16GB+)
- 存储:50GB可用空间
- 网络:可访问Docker Hub和GitHub
2.2 依赖安装
# 安装Python 3.9+
sudo apt update
sudo apt install python3.9 python3.9-venv python3.9-dev
# 安装Docker
curl -fsSL https://get.docker.com | sh
sudo systemctl start docker
sudo systemctl enable docker
# 安装Docker Compose
sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
2.3 虚拟环境配置
# 创建虚拟环境
python3.9 -m venv openviking-env
source openviking-env/bin/activate
# 升级pip
pip install --upgrade pip
三、快速部署
3.1 克隆项目
git clone https://github.com/bytedance/openviking.git
cd openviking
3.2 配置文件准备
# 复制配置文件模板
cp configs/config.example.yaml configs/config.yaml
cp configs/storage.example.yaml configs/storage.yaml
# 编辑主配置文件
nano configs/config.yaml
3.3 配置详解
3.3.1 基础配置
# configs/config.yaml
app:
name: "openviking-agent"
version: "1.0.0"
environment: "development" # development/production
storage:
type: "local" # local/s3/postgresql
base_path: "./data/viking-storage"
logging:
level: "INFO"
file: "./logs/openviking.log"
max_size: "100MB"
backup_count: 5
3.3.2 三层加载配置
layers:
l0:
enabled: true
compression_ratio: 0.05 # L0层压缩率5%
compression_algorithm: "gzip"
l1:
enabled: true
compression_ratio: 0.25 # L1层压缩率25%
summary_length: 500 # 摘要最大长度
l2:
enabled: true
full_content: true # 保留完整内容
compression: "none" # 不压缩
3.3.3 检索配置
retrieval:
algorithm: "directory_recursive"
max_depth: 5 # 目录递归最大深度
batch_size: 50 # 批量处理大小
similarity_threshold: 0.65 # 相似度阈值
cache:
enabled: true
type: "redis"
ttl: 3600 # 缓存过期时间(秒)
max_size: "1GB"
3.4 Docker部署
# docker-compose.yaml
version: '3.8'
services:
openviking-api:
image: openviking/openviking-api:latest
container_name: openviking-api
ports:
- "8080:8080"
volumes:
- ./configs:/app/configs
- ./data:/app/data
- ./logs:/app/logs
environment:
- ENVIRONMENT=development
- LOG_LEVEL=INFO
restart: unless-stopped
openviking-web:
image: openviking/openviking-web:latest
container_name: openviking-web
ports:
- "3000:3000"
depends_on:
- openviking-api
environment:
- API_URL=http://openviking-api:8080
restart: unless-stopped
redis:
image: redis:7-alpine
container_name: openviking-redis
ports:
- "6379:6379"
volumes:
- redis-data:/data
restart: unless-stopped
volumes:
redis-data:
启动命令:
docker-compose up -d
docker-compose logs -f openviking-api

四、核心概念与架构
4.1 文件系统范式
OpenViking采用虚拟文件系统管理上下文:
viking://agent-id/
├── memories/ # 记忆存储
│ ├── user-123/ # 用户记忆
│ ├── project-x/ # 项目记忆
│ └── skills/ # 技能记忆
├── resources/ # 资源文件
│ ├── docs/ # 文档库
│ ├── code/ # 代码片段
│ └── configs/ # 配置文件
└── workspace/ # 工作空间
├── current/ # 当前任务
└── history/ # 历史记录
4.2 API接口使用
4.2.1 Python SDK安装
pip install openviking-sdk
4.2.2 基础操作示例
from openviking import VikingClient
# 初始化客户端
client = VikingClient(
base_url="http://localhost:8080",
api_key="your-api-key"
)
# 创建上下文存储
context_store = client.create_context_store(
name="customer-service",
description="客服系统上下文存储"
)
# 写入记忆
memory_id = client.write_memory(
store_id=context_store.id,
path="memories/user-123/conversation-001",
content="用户咨询产品功能...",
metadata={
"user_id": "user-123",
"timestamp": "2024-03-15T10:00:00Z",
"category": "product_inquiry"
}
)
# 检索上下文
results = client.retrieve(
store_id=context_store.id,
query="用户询问产品功能",
max_results=10,
layer="l1" # 使用L1层内容
)
4.3 三层加载实战
4.3.1 L0层:元数据管理
# 创建L0层摘要
from openviking.compressors import L0Compressor
compressor = L0Compressor(ratio=0.05)
content = """OpenViking是一个专为AI代理设计的上下文数据库...
详细的技术架构包括文件系统范式、三层加载策略..."""
l0_content = compressor.compress(content)
# 输出:OpenViking是AI代理上下文数据库...文件系统范式...三层加载...
print(f"原始大小:{len(content)} 字符")
print(f"L0压缩后:{len(l0_content)} 字符")
print(f"压缩率:{len(l0_content)/len(content)*100:.1f}%")
4.3.2 L1层:核心要点提取
from openviking.compressors import L1Compressor
compressor = L1Compressor(ratio=0.25)
l1_content = compressor.compress(content)
# L1层保留关键信息:
# - OpenViking:AI代理上下文数据库
# - 核心技术:文件系统范式、三层加载策略
# - 优势:降低成本、提高检索效率
4.3.3 L2层:完整内容存储
# L2层存储完整内容
from openviking.storage import FileStorage
storage = FileStorage(base_path="./data")
storage.write(
path="viking://agent-001/resources/docs/openviking-intro.md",
content=content, # 完整内容
layer="l2"
)

五、集成主流AI框架
5.1 LangChain集成
5.1.1 内存管理集成
from langchain.memory import OpenVikingMemory
from langchain.agents import initialize_agent
# 创建OpenViking内存
memory = OpenVikingMemory(
base_path="viking://customer-agent/",
client_config={
"base_url": "http://localhost:8080",
"api_key": "your-key"
}
)
# 初始化代理
agent = initialize_agent(
tools=[web_search, calculator, database_query],
llm=llm,
memory=memory,
agent_type="chat-conversational-react-description",
verbose=True
)
# 运行代理
response = agent.run("用户上次咨询的问题是什么?")
5.1.2 检索增强集成
from langchain.retrievers import OpenVikingRetriever
# 创建检索器
retriever = OpenVikingRetriever(
store_id="customer-docs",
layer="l1", # 使用L1层内容
similarity_threshold=0.7
)
# 创建检索链
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=retriever
)
# 执行检索增强问答
answer = qa_chain.run("OpenViking的三层加载策略是什么?")
5.2 AutoGen集成
5.2.1 多代理上下文共享
from autogen import AssistantAgent, UserProxyAgent
from openviking.autogen_integration import OpenVikingContextManager
# 创建上下文管理器
context_manager = OpenVikingContextManager(
namespace="project-team",
base_path="viking://project-alpha/"
)
# 配置不同角色的代理
engineer_agent = AssistantAgent(
name="engineer",
system_message="你是软件工程师...",
context_manager=context_manager.get_context("engineer")
)
designer_agent = AssistantAgent(
name="designer",
system_message="你是UI设计师...",
context_manager=context_manager.get_context("designer")
)
# 代理间通过共享上下文协作
user_proxy = UserProxyAgent(
name="user_proxy",
human_input_mode="TERMINATE",
context_manager=context_manager.get_context("coordinator")
)
六、实战案例
6.1 案例一:智能客服系统
6.1.1 架构设计
viking://customer-service/
├── memories/
│ ├── users/ # 用户历史对话
│ ├── products/ # 产品知识库
│ └── solutions/ # 解决方案库
├── resources/
│ ├── faq/ # 常见问题文档
│ ├── manuals/ # 产品手册
│ └── policies/ # 政策文档
└── workspace/
├── active-sessions/ # 活跃会话
└── analytics/ # 分析数据
6.1.2 配置示例
customer_service:
layers:
l0:
compression_ratio: 0.03 # 客服场景需要更精确
l1:
compression_ratio: 0.2
summary_algorithm: "key_points"
retrieval:
directories:
- "memories/users/{user_id}"
- "resources/faq"
- "resources/manuals/{product_id}"
caching:
user_profiles_ttl: 86400 # 用户画像缓存24小时
product_info_ttl: 3600 # 产品信息缓存1小时
6.1.3 性能优化
# 预加载常用上下文
async def preload_contexts(user_id, product_ids):
contexts = []
# 预加载用户历史(L1层)
contexts.append({
"path": f"memories/users/{user_id}",
"layer": "l1",
"priority": "high"
})
# 预加载产品信息(L0层)
for product_id in product_ids:
contexts.append({
"path": f"resources/manuals/{product_id}",
"layer": "l0",
"priority": "medium"
})
await client.preload_contexts(contexts)
6.2 案例二:代码生成平台
6.2.1 工作流设计
class CodeGenerationWorkflow:
def __init__(self, task_id):
self.base_path = f"viking://codegen/task-{task_id}/"
self.stages = ["analysis", "design", "implementation", "testing"]
async def execute(self, requirements):
# 阶段1:需求分析
analysis_result = await self.analyze_requirements(requirements)
await self.save_stage_result("analysis", analysis_result)
# 阶段2:架构设计
design_result = await self.design_architecture(analysis_result)
await self.save_stage_result("design", design_result)
# 阶段3:代码实现
code_result = await self.implement_code(design_result)
await self.save_stage_result("implementation", code_result)
# 阶段4:测试验证
test_result = await self.run_tests(code_result)
await self.save_stage_result("testing", test_result)
return self.compile_final_result()
6.2.2 上下文回溯
async def debug_code_issue(task_id, issue_description):
# 加载完整任务上下文
task_context = await client.load_full_context(
f"viking://codegen/task-{task_id}/"
)
# 分析各阶段决策
analysis_phase = task_context.get("analysis")
design_phase = task_context.get("design")
code_phase = task_context.get("implementation")
# 使用AI分析问题根源
analysis_prompt = f"""
代码问题:{issue_description}
需求分析阶段:{analysis_phase}
架构设计阶段:{design_phase}
代码实现阶段:{code_phase}
请分析问题可能出现在哪个阶段,并提供修复建议。
"""
return await llm.generate(analysis_prompt)
6.3 案例三:多智能体研究平台
6.3.1 协作架构
class ResearchCollaborationPlatform:
def __init__(self, project_id):
self.project_path = f"viking://research/project-{project_id}/"
self.agents = {
"literature_reviewer": LiteratureReviewAgent(),
"experiment_designer": ExperimentDesignAgent(),
"data_analyst": DataAnalysisAgent(),
"paper_writer": PaperWritingAgent()
}
async def conduct_research(self, research_topic):
# 文献调研智能体
literature_results = await self.agents["literature_reviewer"].review(
topic=research_topic,
context_path=f"{self.project_path}/literature/"
)
# 实验设计智能体
experiment_plan = await self.agents["experiment_designer"].design(
literature=literature_results,
context_path=f"{self.project_path}/experiments/"
)
# 数据分析智能体
analysis_results = await self.agents["data_analyst"].analyze(
experiment_data=experiment_plan.results,
context_path=f"{self.project_path}/analysis/"
)
# 论文写作智能体
paper = await self.agents["paper_writer"].write(
research_data={
"literature": literature_results,
"experiment": experiment_plan,
"analysis": analysis_results
},
context_path=f"{self.project_path}/paper/"
)
return paper
七、性能调优
7.1 存储优化
7.1.1 压缩策略调整
optimization:
compression:
text:
algorithm: "zstd"
level: 3
dictionary_training: true
code:
algorithm: "lz4"
level: 1 # 代码需要快速解压
images:
algorithm: "webp"
quality: 85
7.1.2 存储分层
# 根据访问频率分层存储
storage_strategy = {
"hot_data": {
"storage": "ssd",
"compression": "light",
"replication": 3
},
"warm_data": {
"storage": "hdd",
"compression": "medium",
"replication": 2
},
"cold_data": {
"storage": "object_storage",
"compression": "aggressive",
"replication": 1
}
}
7.2 检索优化
7.2.1 索引策略
# 创建复合索引
index_config = {
"primary": {
"type": "semantic",
"model": "all-MiniLM-L6-v2",
"dimension": 384
},
"secondary": {
"type": "keyword",
"fields": ["metadata.category", "metadata.timestamp"]
},
"tertiary": {
"type": "hierarchical",
"based_on": "directory_structure"
}
}
7.2.2 缓存优化
cache_config = {
"in_memory": {
"max_size": "2GB",
"eviction_policy": "lru",
"ttl": 300 # 5分钟
},
"redis": {
"host": "localhost",
"port": 6379,
"db": 0,
"max_connections": 100
},
"prefetch": {
"enabled": true,
"predictive_algorithm": "markov_chain",
"confidence_threshold": 0.7
}
}
7.3 成本控制
7.3.1 Token成本监控
class TokenCostMonitor:
def __init__(self, budget_daily=1000):
self.budget_daily = budget_daily
self.consumption_today = 0
async def check_and_limit(self, operation, estimated_cost):
if self.consumption_today + estimated_cost > self.budget_daily:
raise BudgetExceededError(
f"今日预算不足。已用:{self.consumption_today},"
f"需要:{estimated_cost},预算:{self.budget_daily}"
)
# 执行操作
result = await operation()
# 更新消耗
actual_cost = self.calculate_actual_cost(result)
self.consumption_today += actual_cost
return result
7.3.2 自动降级策略
async def retrieve_with_fallback(query, preferred_layer="l1"):
try:
# 首选L1层检索
results = await client.retrieve(
query=query,
layer=preferred_layer,
max_tokens=1000
)
return results
except TokenLimitExceededError:
# 降级到L0层
logging.warning(f"降级检索到L0层:{query}")
results = await client.retrieve(
query=query,
layer="l0",
max_tokens=500
)
return results
except Exception as e:
# 最终降级到关键词检索
logging.error(f"完全降级:{e}")
return await keyword_retrieval(query)
八、监控与维护
8.1 健康检查
# API健康检查
curl http://localhost:8080/health
# 存储健康检查
curl http://localhost:8080/health/storage
# 性能指标
curl http://localhost:8080/metrics
8.2 日志分析
# 配置结构化日志
import structlog
logger = structlog.get_logger()
# 关键操作日志
logger.info(
"context_retrieved",
path=context_path,
layer=layer,
token_cost=token_cost,
response_time=response_time_ms,
user_id=user_id
)
8.3 性能指标收集
from prometheus_client import Counter, Histogram
# 定义指标
RETRIEVAL_REQUESTS = Counter(
'openviking_retrieval_requests_total',
'Total retrieval requests',
['layer', 'status']
)
RETRIEVAL_DURATION = Histogram(
'openviking_retrieval_duration_seconds',
'Retrieval request duration',
['layer']
)
# 在检索函数中记录指标
@RETRIEVAL_DURATION.labels(layer=layer).time()
async def retrieve_context(query, layer):
RETRIEVAL_REQUESTS.labels(layer=layer, status='started').inc()
try:
result = await internal_retrieve(query, layer)
RETRIEVAL_REQUESTS.labels(layer=layer, status='success').inc()
return result
except Exception:
RETRIEVAL_REQUESTS.labels(layer=layer, status='error').inc()
raise
九、故障排除
9.1 常见问题
问题1:高延迟响应
症状:检索响应时间超过2秒
排查步骤:
1. 检查网络延迟:ping API端点
2. 检查存储性能:监控磁盘IO
3. 检查缓存命中率:查看Redis监控
4. 检查索引状态:重建可能损坏的索引
问题2:Token成本异常
症状:Token消耗远高于预期
排查步骤:
1. 检查压缩配置:确认L0/L1压缩率设置
2. 分析检索模式:检查是否频繁使用L2层
3. 审查上下文大小:清理过大的上下文文件
4. 验证降级策略:确保成本超限时正确降级
问题3:上下文不一致
症状:不同检索返回不一致结果
排查步骤:
1. 检查缓存一致性:清理缓存并重试
2. 验证索引同步:确保索引与存储同步
3. 检查并发控制:是否存在写冲突
4. 审计操作日志:查找异常操作记录
9.2 调试工具
# 启用调试模式
export OPENVIKING_DEBUG=true
export LOG_LEVEL=DEBUG
# 使用诊断工具
openviking diagnose --check-all
# 性能分析
openviking profile --duration 30 --output profile.json
十、最佳实践总结
10.1 部署实践
- 生产环境配置:使用独立的数据库实例,配置读写分离
- 高可用架构:部署多个API实例,使用负载均衡
- 备份策略:定期备份上下文数据,测试恢复流程
- 安全加固:启用TLS加密,配置访问控制,定期审计
10.2 开发实践
- 版本控制:所有配置文件纳入版本控制
- 测试覆盖:编写单元测试和集成测试
- 文档完善:为自定义集成编写详细文档
- 代码审查:建立代码审查流程,确保质量
10.3 运维实践
- 监控告警:设置关键指标告警阈值
- 容量规划:定期评估存储和性能需求
- 成本优化:持续监控和优化Token成本
- 灾难恢复:制定和演练灾难恢复计划
结语
OpenViking为AI代理系统提供了专业级的上下文管理能力。通过文件系统范式和三层加载策略,它在保持强大功能的同时,显著降低了Token成本和系统复杂度。
对于技术团队而言,掌握OpenViking不仅意味着解决当前的上下文管理难题,更是为构建下一代AI代理系统奠定基础。建议从测试环境开始,逐步掌握核心概念,然后在关键业务场景中应用,最终构建完整的AI代理基础设施。
OpenViking仍在快速发展中,关注官方GitHub仓库获取最新更新,参与社区讨论贡献想法,共同推动AI代理技术的发展。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 25
25 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)