OpenClaw实战 #06:让 AI 自动操作浏览器完成真实任务(生成每日AI早报)
最近我在连续写 OpenClaw 相关的实战文章。
写着写着,我越来越明确一件事:
OpenClaw 真正有价值的地方,不是它能聊,而是它能动。
很多工具都能回答问题。
但真正让我觉得“这东西能干活”的,是它可以直接接管浏览器,自己去打开网页、读取内容、整理结果。
所以这一篇,我不想再讲抽象概念。
我只做一件非常具体、也非常适合入门的事情:
用 OpenClaw 自动打开目标网站,抓取当天科技热点,然后直接整理出一份简短日报。
而且这次我刻意把方案压到最轻:
- 不单独建 Python 项目
- 不接数据库
- 不做复杂调度
- 整个流程都放在 OpenClaw 内完成
- 需要一点代码时,也只是封装成一个 skill 给 OpenClaw 调用
如果你正在找一个上手快、结果直观、看完就能试的 OpenClaw 案例,这个题目非常合适。
这篇文章,我到底想帮你解决什么问题
我先把目标说透。
这篇文章不是为了证明 OpenClaw 会打开浏览器。
那样的演示没有太大意义。
我真正想解决的是这个问题:
能不能只用 OpenClaw,快速做一个“抓热点 → 整理结果”的最小闭环。
我选 “36Kr”,是因为它特别适合做这个练手案例:
- 国内访问稳定
- 科技热点足够密集
- AI、融资、芯片、创业公司这些内容都比较集中
- 很适合整理成“日报”这种输出形式
也就是说,我这篇文章最终不是让你看到一堆网页源码。
而是让你拿到这样一份结果:
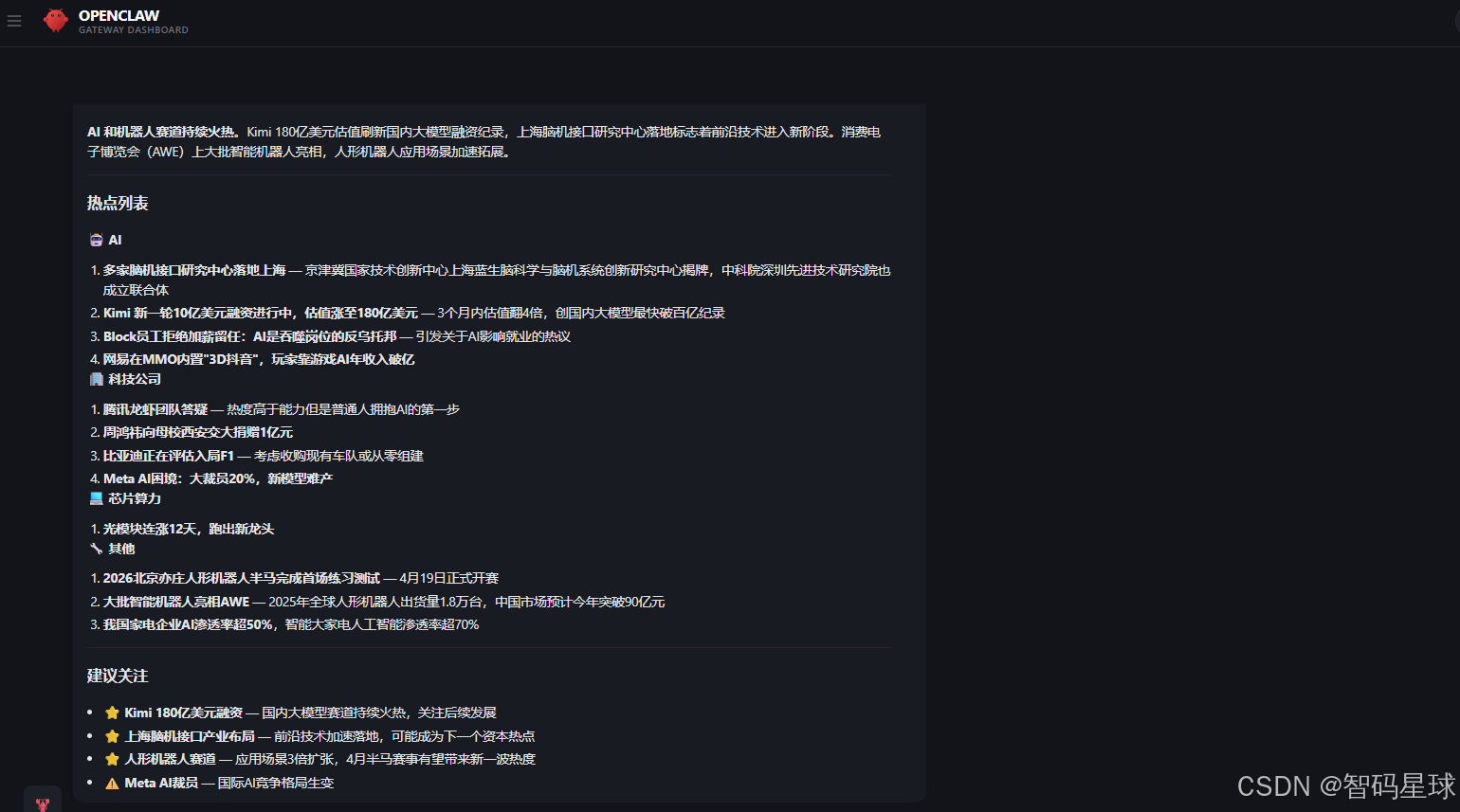
# 今日科技热点日报
## 今日判断
今天的热点主要集中在 AI、科技公司动态和芯片算力三个方向。
## 热点列表
1. AI Agent 相关产品热度继续提升
2. 大模型商业化落地讨论增多
3. 芯片与算力仍然是产业关注重点
4. 科技公司融资、并购和组织调整消息密集
## 建议关注
- 做 AI 应用的,优先看 AI 类热点
- 做基础设施的,重点看芯片和算力
- 做产品和运营的,重点看行业趋势与公司动作
我的目标很简单:
让你看完后知道,这件事不是概念,而是真的能做。
为什么我不用更复杂的工程方案
如果你看过一些 Agent 教程,应该会发现一个常见问题:
一上来就是项目结构、数据库、定时任务、消息推送、日志、服务编排……
这种内容当然有价值,但不适合这篇。
因为这篇在我的博客体系里,定位就是能快速复理,又确实有用的最小闭环。
这个案例的好处是很明显的:
任务真实,不是演示用假案例,上手轻,不需要先搭一整套系统,结果直观,做完马上就能看到价值,后面还能自然扩展成热点监控、内容选题、日报流水线。
我不会在这篇里铺开讲特别重的工程方案。
因为第一次跑 OpenClaw,更需要的是一个能快速复现、又确实有用的最小闭环。
所以我这次故意做了一个取舍:
我不写成“完整工程系统”,我只保留两层。
第一层是 OpenClaw 的 browser 能力。
负责打开 36Kr、读取页面、提取热点文本。
第二层是 一个很轻的自定义 skill。
负责把抓下来的文本做清洗、归类和排版,最后变成一份日报。
整个链路就是这样:
OpenClaw
↓
browser 打开 36Kr
↓
提取页面热点文本
↓
skill 清洗和整理
↓
输出日报
这个方案的好处非常明确。
第一,轻。
第二,直观。
第三,读者容易复现。
第四,后面你如果想扩成更复杂的系统,也有自然的升级路径。
第一步:先把 OpenClaw 的浏览器跑起来
我做这种任务时,第一件事从来不是写 skill。
而是先确认浏览器链路有没有问题。
因为如果浏览器本身都没打通,后面所有逻辑都是空的。
先执行:
openclaw browser status
我这里是提前已经启动好的。
如果看到浏览器没有启动,我就直接起一个受管浏览器:
openclaw browser start --browser-profile openclaw
我这里建议你也这么做。
不要一开始就用别的 profile,也不要先折腾复杂配置。
你就先把这件事做简单:
先让 OpenClaw 自己的浏览器能跑起来。
这样做的好处是,后面排障会轻很多。
第二步:我先验证 OpenClaw 能不能正常打开 36Kr
浏览器起来以后,我不会马上写提示词。
我会先手动验证一次页面能不能打开。
直接执行:
openclaw browser --browser-profile openclaw open https://m.36kr.com/newsflashes

我这里用的是快讯页,不是首页。
原因也很简单:
- 快讯页更适合做“日报入口”
- 信息密度更高
- 噪音更少
- 比首页更适合快速抓热点
页面打开后,我一般还会再等一下,让内容稳定下来:
然后再看快照:
openclaw browser --browser-profile openclaw snapshot --interactive
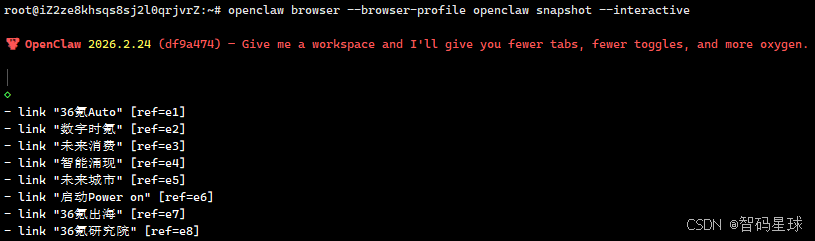
这一步很关键。
因为我真正想确认的不是“浏览器是不是打开了页面”,而是:
OpenClaw 现在到底能不能读到页面上的有效内容。
如果这一步看到的内容已经像样了,后面整个链路就好走很多。
接下来,我们就可以直接和Openclaw对话让他完成工们想要的任务了。
第三步:我不会直接让它“随便总结”,而是先把任务边界收紧(非常重要)
很多人写 Agent 提示词时,喜欢这样写:
帮我看看今天 36Kr 有什么热点。
这种写法听起来很自然,但实战里其实不稳定。
因为它太泛了。
一旦提示太泛,OpenClaw 很可能会:
- 抓到一堆噪音内容
- 输出很散
- 结果格式不稳定
- 每次表现都不一样
所以我这里的做法很简单:
不让它“自由发挥”,而是给它一个很明确的任务边界。
打开Openclaw Web UI, 我更推荐你像这样写:
使用 browser profile=openclaw 完成以下任务:
1. 打开 36Kr 快讯页
2. 提取当前页面里最值得关注的 8 到 12 条科技热点
3. 忽略登录、广告、下载 App、评论、分享等无关内容
4. 按 AI、科技公司、芯片算力、其他 四类整理
5. 输出一份简短日报,包含:
- 今日判断
- 热点列表
- 建议关注
我自己做下来最深的感受就是:
浏览器任务一旦想稳定,提示词一定要具体。
不要让它自己去猜“什么是热点”,
你要直接告诉它:
- 抓多少条
- 过滤什么
- 怎么归类
- 最后按什么格式输出
只要这一步做对了,后面结果会稳很多。
第四步 测试通过后,直接加一个每天早 8 点自动推送的定时任务
将这个任务添加 到计划任务,每天早8点为我推送AI早报
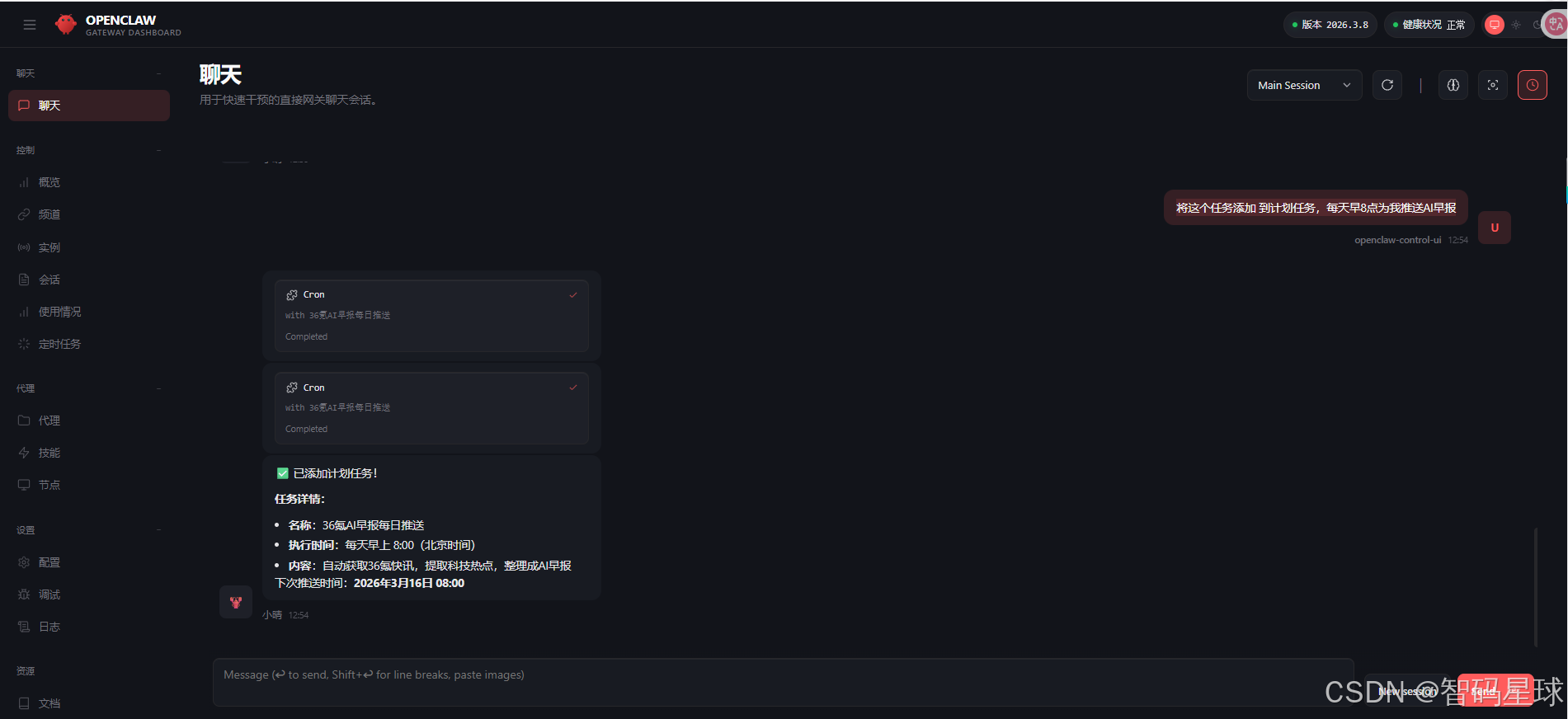
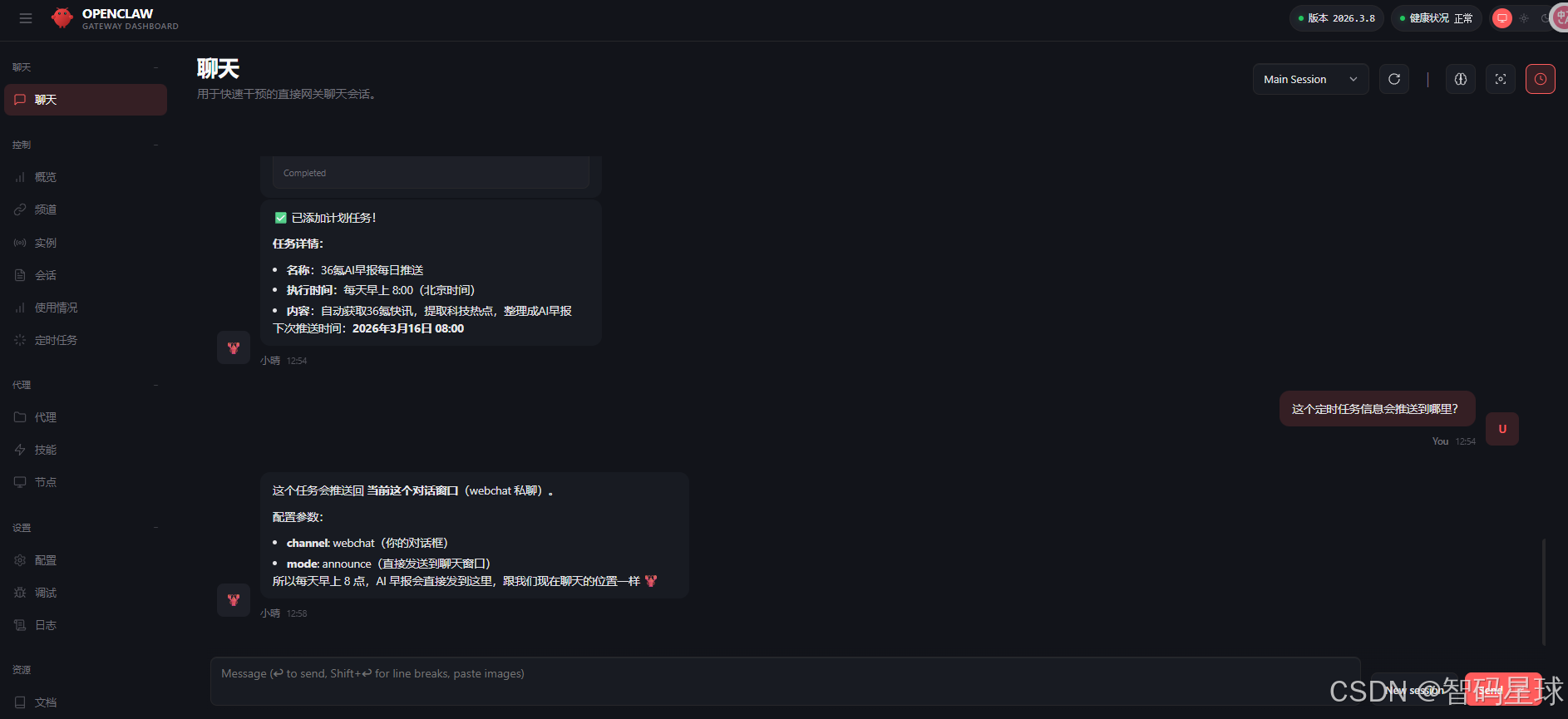
每天早8点就会有AI早报推送到你的Web UI对话框中。 如果想推送到其他即时通信工具,可以直接在已配置好的工具中完成这个任务创建的对话。 如飞书,飞书的对接建议看《OpenClaw 实战 #03-2: 接入飞书从 0 配到能用(新手不踩坑版)》
到了这一步,就已经闭环了。
结尾
如果你刚开始接触 OpenClaw,我真的建议你先别想着做太重的系统。
先跑通一个最小闭环就够了:
OpenClaw 打开 36Kr → 抓热点 → skill 整理 → 输出日报
这一步一旦跑通,你后面再往上接:
- 多平台热点监控
- AI 日报
- 自动选题整理
- 内容生产流水线
都会自然很多。
而对我来说,这篇文章真正想证明的也只有一句话:
OpenClaw 最有价值的,不是它能不能打开浏览器。
而是它能不能把“看网页”这件事,直接变成“交结果”。
下期我将介绍更多openclaw的实操方法,欢迎评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)