【大模型实战篇】在多GPU服务器上部署Qwen3.5本地模型服务并接入Claude Code
1. 前言
Claude Code 是 Anthropic 推出的 AI 编程助手,默认需要使用 Anthropic 官方 API。但它支持通过 ANTHROPIC_BASE_URL 环境变量切换后端服务,所以我们可以用本地部署的开源大模型替代官方 API,实现零成本、数据不出内网的编程助手方案。
这里我记录一下在一台 8卡 RTX 4090 服务器上,利用空闲 GPU 部署 Qwen3.5-35B-A3B 模型,并让本机和内网其他服务器的 Claude Code 都接入该模型服务的完整过程。
2. 环境信息
| 项目 | 配置 |
|---|---|
| GPU | 8x NVIDIA GeForce RTX 4090 (24GB) |
| 空闲卡 | GPU 4、GPU 5 |
| CUDA | 12.4 |
| 系统 | Ubuntu 22.04, Linux 5.15 |
| 内存 | 505 GB |
| Node.js | v22.22.1 |
| Python | 3.13.5 |
3. 架构设计
核心思路:用 llama.cpp 在本地起一个兼容 OpenAI API 的模型服务,Claude Code 所有请求都走这个本地服务,完全不依赖 Anthropic 官方 API。
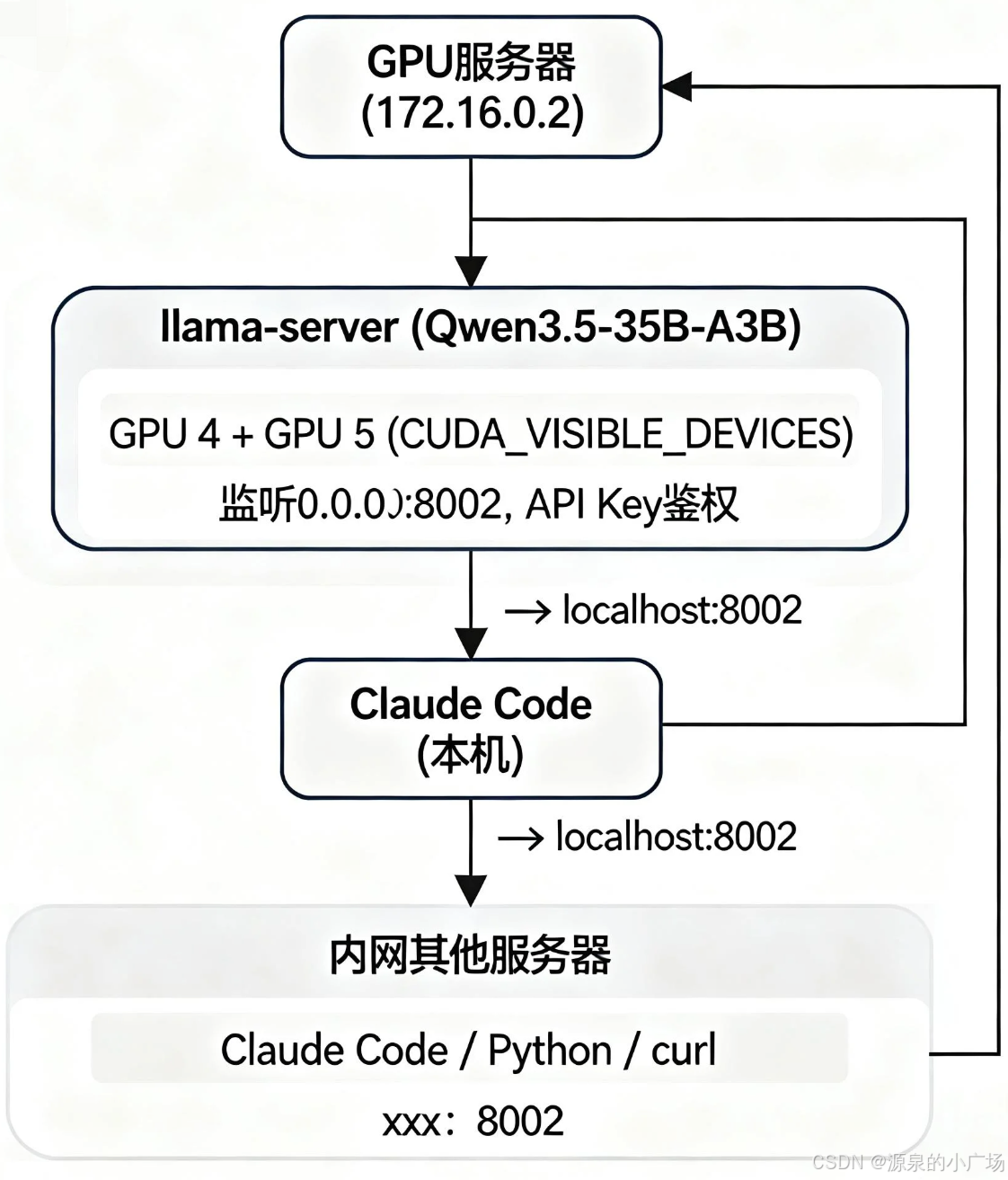
4. 问题评估与规划
拿到服务器后先做环境检查,我们遇到了三个实际问题:
问题1:根盘磁盘满了
$ df -h /
Filesystem Size Used Avail Use% Mounted on
/dev/sdc2 445G 441G 4.2G 100% /
根盘只剩 4.2GB,而模型文件就有 21GB。好在服务器挂了块 3.5TB 数据盘:
/dev/sxx1 3.5T 25G 3.5T 1% /mnt/sxx1
解决方案:所有文件(llama.cpp 编译、模型存储)都放到 /mnt/sxx1。
问题2:目标端口被占用
$ ss -tlnp | grep 8001
LISTEN 0 4096 0.0.0.0:8001 0.0.0.0:* users:(("docker-proxy"...))
8001 端口被占用。改用 8002 端口。
问题3:其他 GPU 正在跑服务
8 张卡中 6 张都有任务在跑(显存占用 83%-93%),只有 GPU 4 和 5 完全空闲。
解决方案:使用 CUDA_VISIBLE_DEVICES=4,5 严格隔离,确保不影响其他服务。
5. 编译 llama.cpp
cd /mnt/sdb1
# 下载源码(GitHub 慢可以用浏览器下 zip 传上来)
# https://github.com/ggml-org/llama.cpp/archive/refs/heads/master.zip
unzip llama.cpp.zip && mv llama.cpp-master llama.cpp# cmake 配置(RTX 4090 = Ada Lovelace, Compute Capability 8.9)
cmake llama.cpp -B llama.cpp/build \
-DBUILD_SHARED_LIBS=OFF -DGGML_CUDA=ON \
-DCMAKE_CUDA_ARCHITECTURES="89"# 编译
cmake --build llama.cpp/build --config Release -j \
--clean-first \
--target llama-cli llama-mtmd-cli llama-server llama-gguf-split# 拷贝二进制
cp llama.cpp/build/bin/llama-* llama.cpp/
踩坑:cuBLAS 缺失
cmake 配置时报了一堆错:
Target "ggml-cuda" links to target "CUDA::cublas" but the target was not found.
原因是服务器只装了 CUDA toolkit 的最小集(nvcc + cudart),没装 cuBLAS 数学库。
# 确认缺失
ls /usr/local/cuda-12.4/include/cublas_v2.h # 文件不存在# 安装 cuBLAS(约 1.4GB,根盘剩余 4.2GB 刚好够)
apt-get install -y libcublas-dev-12-4 libcublas-12-4# 安装后清理 apt 缓存释放空间
apt-get clean
装好后重新 cmake 配置即可通过。
6. 下载模型
使用 ModelScope(国内源,速度快)下载 Unsloth 量化的 Qwen3.5-35B-A3B:
pip install modelscope
# 建议在 tmux 中运行,防止 SSH 断开
tmux new -s downloadmodelscope download --model unsloth/Qwen3.5-35B-A3B-GGUF \
--include '*UD-Q4_K_XL*' \
--local_dir /mnt/sxx1/models/Qwen3.5-35B-A3B-GGUF
Qwen3.5-35B-A3B 是 MoE 架构(Mixture of Experts),总参数 35B 但每次推理只激活 3B,推理速度非常快。UD-Q4_K_XL 是 Unsloth Dynamic 2.0 量化方案,重要层自动提升到 8-bit 或 16-bit,在体积和精度之间取得最佳平衡。
下载结果:
Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf 21GB
下载速度 ~6MB/s,耗时约 1 小时
7. 启动模型服务
tmux new -s llama
CUDA_VISIBLE_DEVICES=4,5 /mnt/sxx1/llama.cpp/llama-server \
--host 0.0.0.0 \
--port 8002 \
--api-key "sk-your-secret-key-here" \
--model /mnt/sxx1/models/Qwen3.5-35B-A3B-GGUF/Qwen3.5-35B-A3B-UD-Q4_K_XL.gguf \
--alias "unsloth/Qwen3.5-35B-A3B" \
--n-gpu-layers 99 \
--tensor-split 0.5,0.5 \
--temp 0.6 \
--top-p 0.95 \
--top-k 20 \
--min-p 0.00 \
--kv-unified \
--cache-type-k q8_0 --cache-type-v q8_0 \
--flash-attn on --fit on \
--ctx-size 32768 \
--chat-template-kwargs '{"enable_thinking": false}'
关键参数说明:
| 参数 | 作用 |
|---|---|
| CUDA_VISIBLE_DEVICES=4,5 | 只使用 GPU 4 和 5,不影响其他卡 |
| --host 0.0.0.0 | 允许内网其他机器连接 |
| --api-key | 接口鉴权,防止未授权访问 |
| --n-gpu-layers 99 | 所有层都放到 GPU 上 |
| --tensor-split 0.5,0.5 | 两张卡平均分配模型权重 |
| --ctx-size 32768 | 32K 上下文,编码场景够用 |
| --flash-attn on | 开启 Flash Attention 加速 |
| --cache-type-k q8_0 --cache-type-v q8_0 | KV Cache 用 8-bit 量化节省显存 |
| --chat-template-kwargs '{"enable_thinking": false}' | 关闭思考模式,提升编码速度 |
启动后的资源占用:
GPU 4: 11752 MiB / 24564 MiB (48%)
GPU 5: 11412 MiB / 24564 MiB (46%)
剩余约 12GB/卡,后续可尝试增大 ctx-size
推理性能:
Prompt 处理: ~115 tokens/s
Token 生成: ~157 tokens/s
8. 验证 API Key 鉴权
# 不带 Key → 401 拒绝
$ curl -s http://localhost:8002/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{"model":"unsloth/Qwen3.5-35B-A3B","messages":[{"role":"user","content":"hi"}]}'
{"error":{"message":"Invalid API Key","type":"authentication_error","code":401}}# 带正确 Key → 正常返回
$ curl -s http://localhost:8002/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-your-secret-key-here" \
-d '{"model":"unsloth/Qwen3.5-35B-A3B","messages":[{"role":"user","content":"hi"}]}'
{"choices":[{"message":{"role":"assistant","content":"Hello! How can I..."}}]}
9. 安装配置 Claude Code
9.1 安装
npm install -g @anthropic-ai/claude-code
9.2 环境变量(~/.bashrc)
# GPU 服务器(本机)
export ANTHROPIC_BASE_URL="http://localhost:8002"
export ANTHROPIC_API_KEY="sk-your-secret-key-here"# 内网其他服务器
export ANTHROPIC_BASE_URL="http://172.xx.xx.xx:8002"
export ANTHROPIC_API_KEY="sk-your-secret-key-here"
9.3 跳过登录(~/.claude.json)
{
"hasCompletedOnboarding": true,
"primaryApiKey": "sk-dummy-key"
}
9.4 性能优化(~/.claude/settings.json)
这个配置非常关键,不加的话 Claude Code 新版本默认的归属头会导致 KV 缓存失效,推理速度直接砍半:
{
"promptSuggestionEnabled": false,
"env": {
"CLAUDE_CODE_ENABLE_TELEMETRY": "0",
"CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC": "1",
"CLAUDE_CODE_ATTRIBUTION_HEADER": "0"
},
"plansDirectory": "./plans",
"effortLevel": "high"
}
9.5 启动使用
source ~/.bashrc
cd /your/project
claude --model "unsloth/Qwen3.5-35B-A3B"
10. 远程服务器通过 OpenAI 兼容 API 调用
llama-server 原生兼容 OpenAI API 格式,除了 Claude Code 之外,任何支持 OpenAI API 的工具都可以直接接入:
from openai import OpenAI
client = OpenAI(
base_url="http://172.xx.xx.xx:8002/v1",
api_key="sk-your-secret-key-here",
)# 普通调用
response = client.chat.completions.create(
model="unsloth/Qwen3.5-35B-A3B",
messages=[
{"role": "system", "content": "你是一个有用的助手。"},
{"role": "user", "content": "用Python写一个快速排序"},
],
temperature=0.6,
max_tokens=2048,
)
print(response.choices[0].message.content)# 流式输出
stream = client.chat.completions.create(
model="unsloth/Qwen3.5-35B-A3B",
messages=[{"role": "user", "content": "解释梯度下降"}],
stream=True,
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
11. 踩坑汇总
| 问题 | 原因 | 解决方案 |
|---|---|---|
| cmake 报 CUDA::cublas not found | CUDA toolkit 安装不完整,缺少 cuBLAS | apt-get install libcublas-dev-12-4 |
| 根盘空间不足 | 模型 21GB 放不下 | 使用独立数据盘 /mnt/sxx1 |
| 端口 8001 被占 | Docker 容器占用 | 改用 8002 端口 |
| GitHub 下载极慢 | 服务器到 GitHub 网络差 | 本地下 zip 上传,或用 gitee 镜像 |
| Claude Code 推理速度慢 | 归属头导致 KV 缓存失效 | settings.json 中设置 CLAUDE_CODE_ATTRIBUTION_HEADER: "0" |
| 推理出现乱码 | KV Cache 量化兼容问题 | 将 --cache-type-k q8_0 换为 bf16 |
12. 运维
# 查看/重连服务
tmux attach -t llama# 停止服务
tmux attach -t llama # 然后 Ctrl+C# 查看服务日志
tail -f /mnt/sdb1/llama-server.log# 查看 GPU 状态(确认只用了卡 4 和 5)
nvidia-smi -i 4,5# 健康检查
curl http://localhost:8002/health
13. 显存规划参考
| ctx-size | KV Cache 占用(估算) | 双卡总占用 | 是否可行 |
|---|---|---|---|
| 32768 | ~5 GB | ~28 GB | 轻松(推荐起步值) |
| 65536 | ~10 GB | ~33 GB | 可以 |
| 131072 | ~20 GB | ~43 GB | 偏紧,需要测试 |
14. 总结
整套方案的核心就一句话:llama.cpp 起服务,Claude Code 改地址。实际部署中大部分时间花在处理环境问题上(磁盘、端口、CUDA 库缺失)。
这套方案适合:
- 内网环境处理敏感代码,数据不出机房
- 节省 API 费用,模型跑在自己的 GPU 上
- 多人共享同一个模型服务(通过 API Key 控制访问)
局限性:
- Qwen3.5 的编码能力和 Claude 原版仍有差距
- Claude Code 的部分工具功能可能不完全兼容
- 需要维护 GPU 服务器和模型服务的稳定性
15. 参考资料

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)