霸榜的竟然是它!深度解析OpenClaw大模型基准测试结果

引言
大家的OpenClaw都是用的什么模型呢?选模型简直选到头秃。用开源小参数模型吧,经常胡言乱语跟不上逻辑;用顶配闭源大模型吧,跑几轮下来API账单又让人心痛。到底哪个大模型才是搞智能体开发的最佳外脑?刚好最近又发布了最新版的PinchBench评测榜单,今天咱们就接地气地扒一扒这个硬核榜单,帮你彻底终结大模型选择困难症!
一、PINCHBENCH 评测核心认知
在搞懂榜单之前,咱们得先知道PinchBench是啥。简单来说,它就是一个专门针对OpenClaw智能体框架的大模型“照妖镜”。很多模型平时聊天写诗看着挺机灵,一旦接入智能体框架,面对复杂的工具调用和多步任务,瞬间就原形毕露了。
这次官方的评测非常良心,不是单一维度的瞎比拼,而是从四个最核心的痛点切入。我给大家画个图,一看就懂:
网址直达:https://pinchbench.com/
二、成功率霸榜:神仙打架的绝对领域
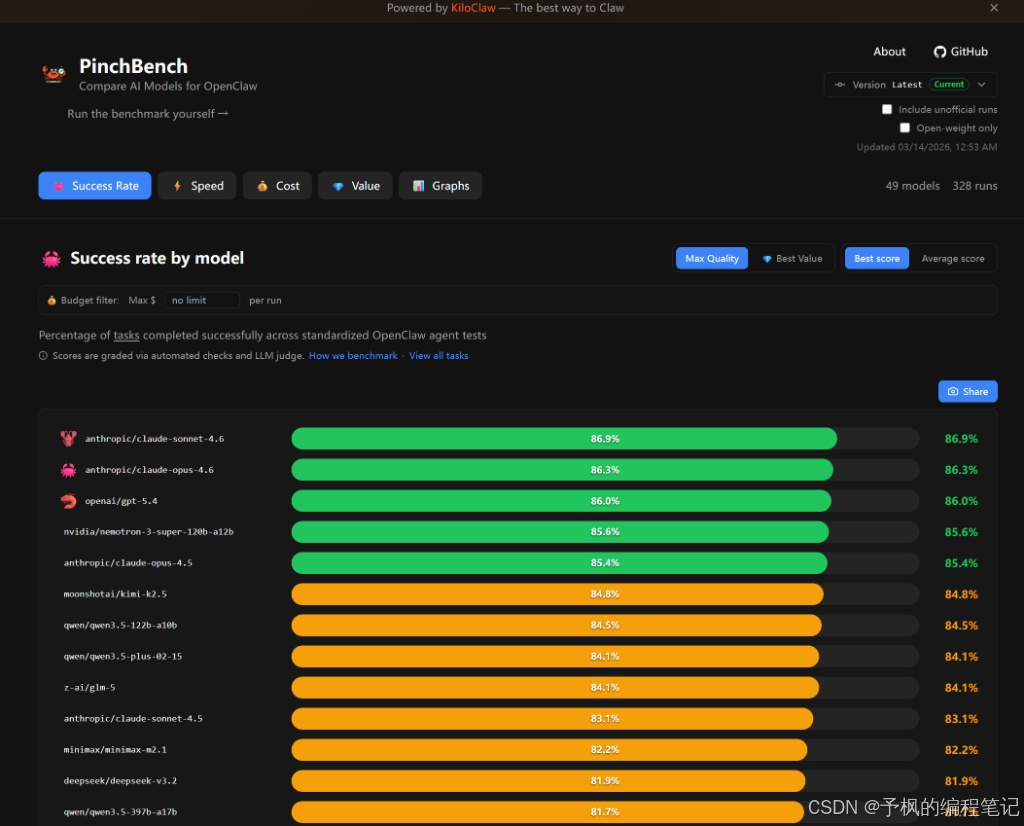
搞智能体开发,成功率绝对是第一生产力。你总不想写了一堆完美的代码,结果因为大模型抽风导致整个流程崩溃吧?
从榜单来看,第一梯队完全是神仙打架。Anthropic家的Claude系列表现极其亮眼,claude-sonnet-4.6直接以86.9%的成功率登顶,紧随其后的是claude-opus-4.6和OpenAI的gpt-5.4。
发现没有?在复杂的智能体任务面前,顶级闭源模型的逻辑推理能力依然是天花板级别的存在。如果你开发的是面向企业级、对容错率要求极低的金融或医疗类Agent应用,别犹豫,直接上榜单前三的大哥,能帮你省去80%写异常处理代码的时间。
三、速度与激情:天下武功唯快不破
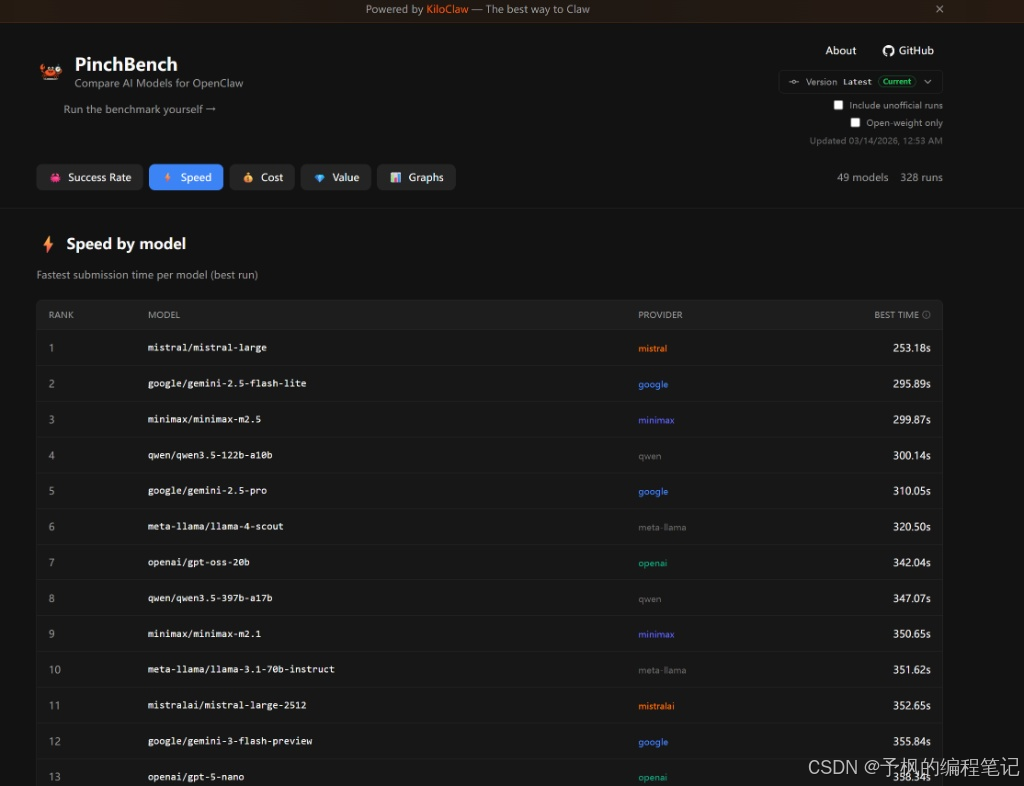
有些场景下,用户根本等不及模型慢慢吞吞地思考。比如在知光平台做实时知识检索和交互的时候,响应速度直接决定了用户体验。
在速度榜单上,局面发生了有意思的变化。mistral-large以惊人的253秒最佳提交时间拔得头筹。紧跟其后的是谷歌的gemini-2.5-flash-lite。
这说明啥?说明在需要高频交互、轻量级任务拆解的场景中,大厂的“敏捷版”或“Lite版”模型反而更吃香。它们参数规模适中,推理极快,绝对是实时处理场景的王者。
四、性价比之王:开发者和白嫖党的福音
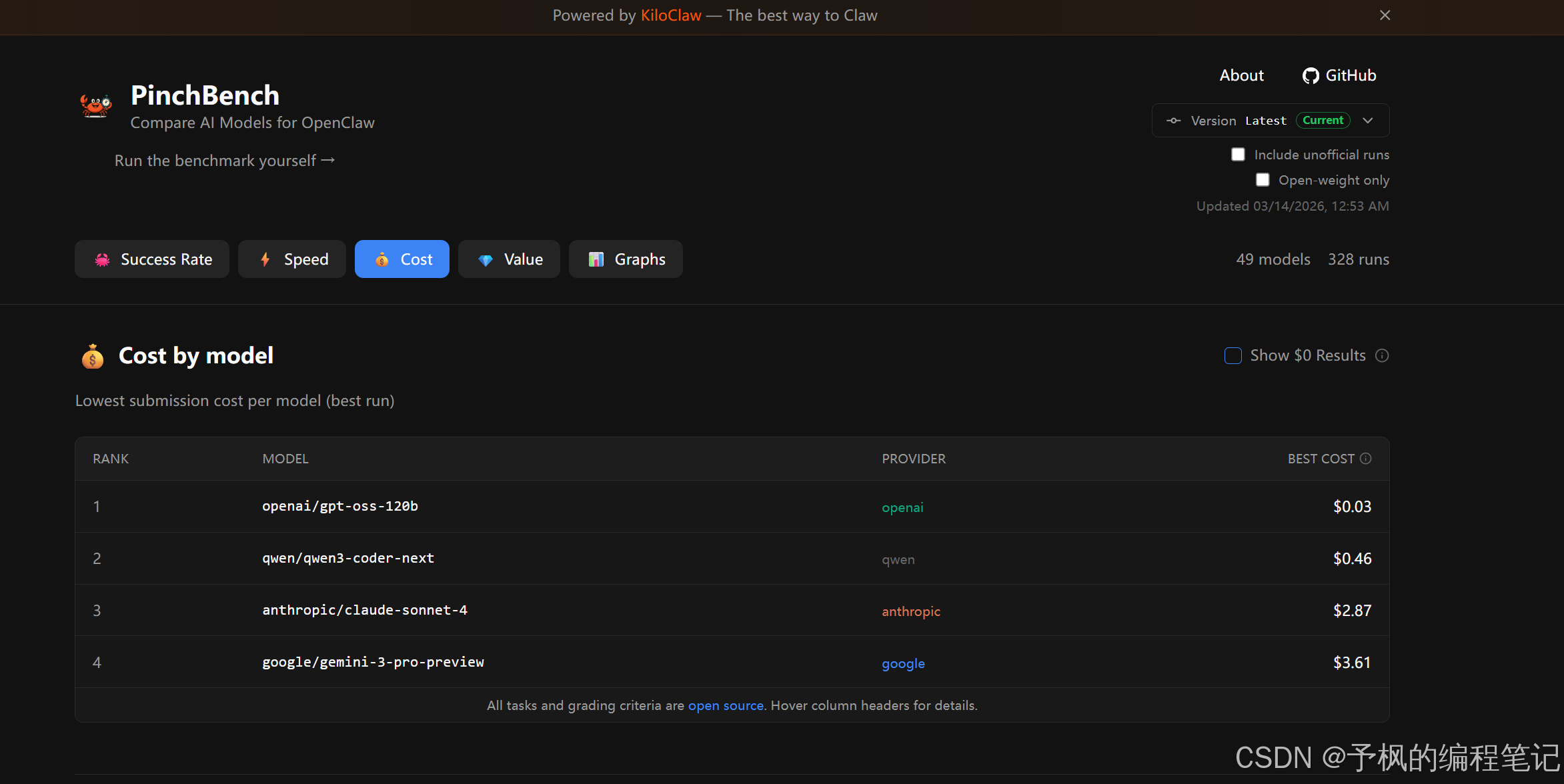
高配模型好用是好用,但那个费用真不是盖的。我平时手里那台32G内存的酷睿Ultra 7轻薄本写写代码、跑跑本地轻量化微调还算游刃有余,但要真扛起千亿参数的大模型推理,那也是分分钟发热狂飙。所以很多时候还是得依赖云端API。
这就不得不提这次榜单里最让我惊艳的价值得分与成本效率板块了!
| 排名 | 模型名称 | 提供商 | 核心优势 |
|---|---|---|---|
| 第一名 | gpt-oss-120b | openai | 极致性价比与超低单次任务成本 |
| 第二名 | qwen3-coder-next | qwen | 优秀的代码能力与亲民的价格 |
| 第三名 | claude-sonnet-4 | anthropic | 稳定均衡的综合表现 |
gpt-oss-120b以逆天的1598.9价值得分一骑绝尘,单次最好成本只要0.03美金!而国产之光阿里的qwen3-coder-next也表现极其抢眼,价值得分排在第二,对于需要处理大量代码逻辑的智能体来说,简直是真香警告。如果你是独立开发者或者在做个人项目,顺着价值榜单前两名去选,绝对能把每一分钱都花在刀刃上。
总结
看完整个OpenClaw的PinchBench排行榜,咱们可以抄个作业:
- 土豪求稳型:直接无脑接
claude-sonnet-4.6或gpt-5.4,成功率拉满。 - 天下武功唯快不破型:选用
mistral-large或gemini-2.5-flash-lite,告别转圈圈。 - 精打细算过日子型:强烈推荐
gpt-oss-120b或qwen3-coder-next,性价比高到离谱。
工具再好也只是辅助,怎么用好它们才是程序员的核心竞争力!大家在日常开发中都踩过哪些大模型的坑呢?欢迎在评论区一起吐槽交流~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 32
32 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)