基于机器学习的钓鱼网站智能检测系统系统开发与实现
1 系统研究背景与开发目标
随着互联网应用的不断普及,网络攻击的形式逐渐从传统的漏洞利用转向更加隐蔽和具有欺骗性的社会工程攻击。其中,钓鱼攻击(Phishing Attack)因其实施成本低、传播范围广、成功率较高,已经成为当前网络安全领域最主要的威胁之一。攻击者通常通过构造伪造网站或恶意 URL,使用户误以为访问的是合法站点,从而诱导用户输入账号、密码、银行卡信息或其他敏感数据。
传统的钓鱼网站防护方法主要依赖以下方式:
- 黑名单机制
- 浏览器安全提示
- 用户安全意识
- 静态规则匹配
然而,这些方法存在明显不足。例如,黑名单更新存在滞后性,无法及时识别新生成的钓鱼网站;规则匹配方式缺乏灵活性,容易被攻击者绕过;用户自身安全意识差异较大,也难以形成有效防护。因此,如何构建一种能够自动学习钓鱼网站特征并实时检测未知风险 URL 的智能系统,成为当前网络安全研究的重要方向。
本系统在上述背景下设计与实现,旨在通过机器学习技术结合网页结构分析,实现对未知 URL 的自动化安全评估,从而提高钓鱼攻击的检测能力与响应效率。
2 系统总体设计思想
本系统的核心思想是:
将 URL 与网页内容视为一种“安全行为特征数据”,通过特征工程构建风险向量,再利用机器学习模型进行分类预测。
系统并非简单依赖单一维度信息,而是融合以下三类安全特征:
- URL 结构特征
- 网页 HTML 行为特征
- 安全语义关键词特征
通过多维特征融合,使系统能够更加准确地刻画钓鱼网站的典型模式,例如:
- URL 混淆
- 表单诱导
- 页面重定向
- 外部资源加载
- 登录仿冒行为
在系统架构设计上,采用典型的 Web 服务 + 机器学习推理架构,使检测功能能够以在线服务形式运行,实现用户实时检测需求。
3 系统整体架构设计
系统采用分层架构设计,主要包括以下四个逻辑层:
- 用户交互层
- Web 服务控制层
- 特征提取层
- 风险预测层
整体运行逻辑如下:
用户输入 URL 后,请求首先由 Flask Web 服务接收,随后系统调用特征提取模块对目标网页进行自动解析,提取结构化安全特征,并将其转换为数值向量输入机器学习模型。模型根据训练得到的决策规则输出风险概率,系统再根据风险阈值生成安全标签与风险解释信息,最终通过前端界面展示给用户。
这种架构具有良好的模块解耦特性,各模块之间通过清晰的数据接口进行通信,便于系统后期扩展与维护。
4 URL 特征提取模块设计原理
特征提取模块是系统的核心组成部分,其主要作用是将非结构化网页信息转换为机器学习模型可识别的数值特征。该模块主要通过 Python 编写,并利用 requests 与 BeautifulSoup 库实现网页抓取与解析。
4.1 URL 词法结构特征
URL 本身包含大量潜在安全信息,例如:
- URL 长度异常
- 域名层级复杂
- 特殊字符比例高
- 编码混淆行为
- 数字字符占比异常
钓鱼网站常通过增加子域名层级或插入混淆字符来伪装真实域名,例如:
paypal-login-secure.verify-user.xyz
系统通过统计 URL 中字母数量、数字数量、特殊符号数量及 Shannon 信息熵等指标,评估 URL 的复杂度与异常程度。信息熵越高,通常表示 URL 随机性越强,更可能属于恶意构造。
4.2 网页结构行为特征
系统在访问目标 URL 后,会自动获取 HTML 页面源码,并提取如下行为特征:
- 页面代码行数
- 最大单行代码长度
- JavaScript 脚本数量
- iframe 标签数量
- 图片与 CSS 资源数量
- 页面跳转次数
钓鱼网站往往具有以下特征:
- 页面结构简单但脚本加载较多
- 存在隐藏表单或密码输入框
- 使用 iframe 嵌入真实站点
- 使用大量外部资源伪装页面
通过统计这些结构行为指标,可以有效刻画网页攻击意图。
4.3 表单与交互诱导特征
钓鱼网站最常见目标是窃取用户登录信息,因此系统重点检测:
- 是否存在 password 输入框
- 表单提交地址是否指向外部域
- 是否存在隐藏字段
- 是否存在提交按钮
若页面存在跨域表单提交行为,则风险显著提高,因为这通常意味着用户输入的数据将被发送至攻击者服务器。
4.4 安全语义关键词特征
系统还会在 URL 与页面文本中搜索特定安全关键词,例如:
- 银行类词汇
- 支付类词汇
- 加密货币类词汇
这些词汇在钓鱼攻击中具有较高出现频率,例如:
- “account verify”
- “payment confirm”
- “crypto wallet connect”
关键词检测有助于提升系统对社会工程攻击的识别能力。
5 机器学习模型设计与训练原理
系统采用随机森林(Random Forest)作为主要分类模型。随机森林是一种基于集成学习思想的监督学习算法,通过构建多棵决策树并进行投票决策,从而提高模型的泛化能力。
选择随机森林的原因包括:
- 能处理非线性特征关系
- 对异常值不敏感
- 不需要复杂特征归一化
- 训练稳定性高
- 可输出特征重要性
在模型训练阶段,系统会:
- 自动读取数据集
- 清理缺失数据
- 筛选可在线复现的特征
- 划分训练集与测试集
- 训练模型并评估性能
模型性能通过以下指标评估:
- 准确率(Accuracy)
- 精确率(Precision)
- 召回率(Recall)
- F1-score
这些指标能够综合反映模型对钓鱼网站识别能力。
6 风险评分融合机制
为了提升系统稳定性,本系统采用:
机器学习概率 + 安全规则评分 融合机制
即:
最终风险值 =
0.75 × 模型预测概率 + 0.25 × 启发式风险评分
其中,启发式评分基于安全专家经验规则,例如:
- 是否使用 IP 地址作为域名
- 是否存在外部表单提交
- 是否存在页面重定向
- 是否出现加密货币关键词
该融合策略能够有效减少模型误判,并提升系统在未知攻击场景下的鲁棒性。
7 风险分类策略设计
系统采用三档风险分类方式:
- Risk < 0.33 → 安全网站
- 0.33 ≤ Risk < 0.66 → 可疑网站
- Risk ≥ 0.66 → 钓鱼网站
这种设计相比传统二分类更符合真实安全应用场景,因为网络风险本身具有连续性和不确定性。
8 Web 服务实现原理
系统后端采用 Flask 框架构建,主要负责:
- 接收用户 URL 输入
- 调用特征提取模块
- 执行模型预测
- 返回 JSON 或 HTML 响应
系统同时提供 REST API 接口,使其能够被其他安全系统调用,实现服务化部署。
前端页面采用 HTML 与 CSS 构建,支持:
- 风险进度条可视化
- 批量检测表格展示
- 标签颜色区分风险等级
9 系统优势与创新点
本系统具有以下创新特点:
- URL + HTML + 语义 多维特征融合
- 机器学习与专家规则联合决策
- 实时在线检测能力
- 风险解释机制增强可理解性
- 支持批量安全分析
相比传统黑名单系统,本系统能够识别未知钓鱼攻击模式。
10 系统局限与改进方向
当前系统仍存在以下不足:
- 无法完全解析 JavaScript 动态渲染页面
- 对 CDN 跳转页面检测稳定性有限
- 深度语义分析能力不足
- 未集成 DNS 威胁情报
未来可改进方向包括:
- 引入深度学习 URL 表征模型
- 使用浏览器自动化技术提取动态特征
- 构建在线威胁情报更新机制
- 开发浏览器插件版本
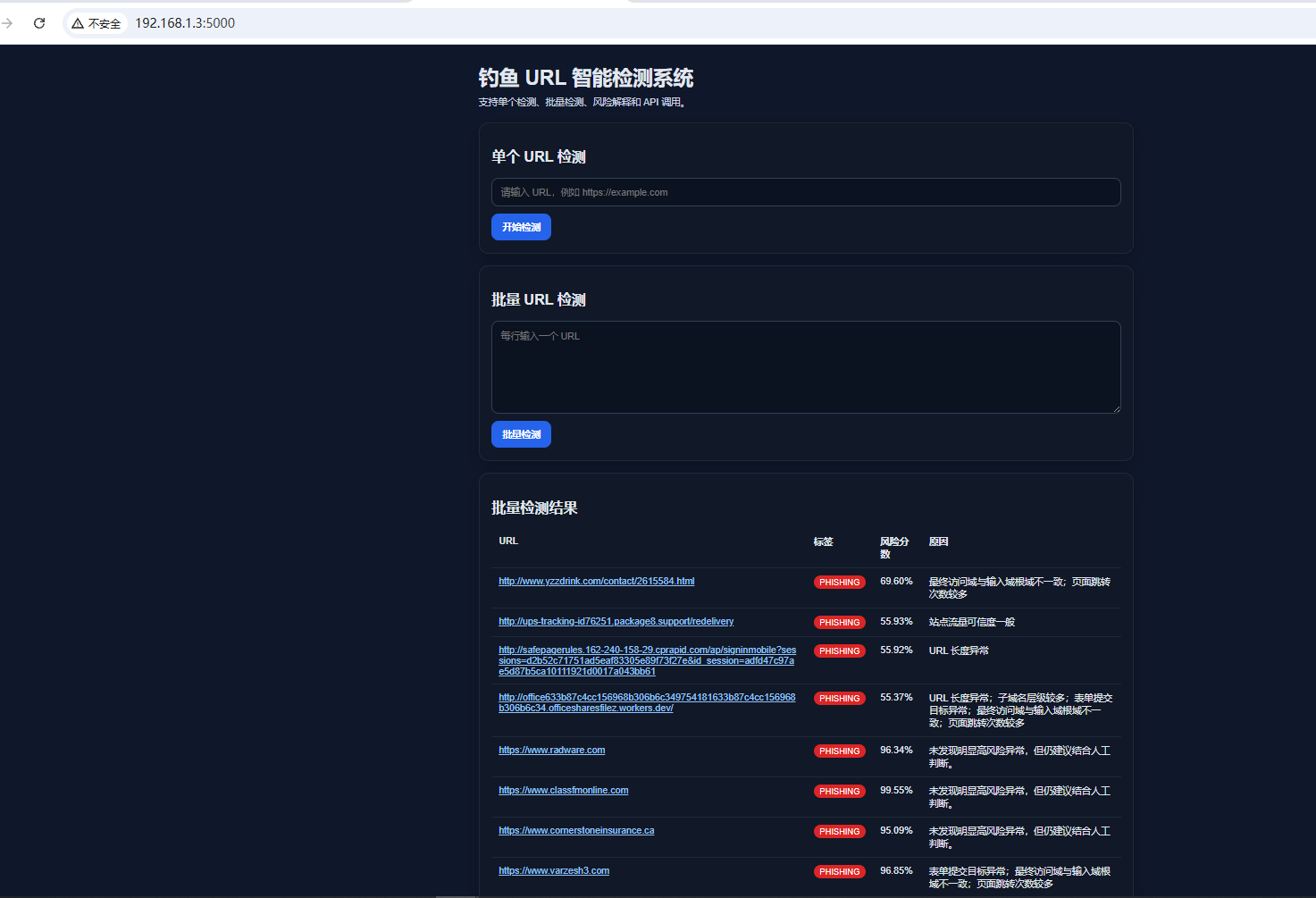
最终实现效果:
测试地址:
常用网站测试(安全):
不安全的网站:
http://www.yzzdrink.com/contact/2615584.html
http://ups-tracking-id76251.package8.support/redelivery

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)