PSO-LSSVM - Adaboost回归预测:多输入单输出模型的探索
PSO-LSSVM-adaboost基于粒子群优化最小二乘支持向量机LSSVM的Adaboost回归预测,PSO-LSSVM-Adaboost回归预测,多输入单输出模型。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,方便学习和替换数据。
在机器学习的世界里,预测任务一直是核心关注点。今天咱们来聊聊基于粒子群优化最小二乘支持向量机(PSO - LSSVM)的Adaboost回归预测,而且是多输入单输出模型哦,这个模型在很多领域都有不错的应用潜力,比如经济预测、环境数据预估等。
一、PSO - LSSVM - Adaboost模型概述
- LSSVM(最小二乘支持向量机):它是支持向量机在求解二次规划问题时的一种改进,将传统支持向量机中的不等式约束变为等式约束,从而简化了计算过程。用数学公式表达就是,给定训练样本集 $\{(xi, yi)\}{i = 1}^N$,$xi \in R^d$,$yi \in R$,LSSVM试图找到一个函数 $f(x) = w^T\varphi(x) + b$,使得 $\sum{i = 1}^N(yi - f(xi))^2$ 最小,同时满足正则化条件 $\frac{1}{2}w^Tw$ 最小。这里 $\varphi(x)$ 是将输入空间映射到高维特征空间的函数。
- PSO(粒子群优化):PSO模拟鸟群觅食行为,每个粒子在解空间中代表一个潜在解,通过跟踪自身历史最优位置 $pbest$ 和全局最优位置 $gbest$ 来更新自己的位置和速度。粒子 $i$ 的速度更新公式为:
# 速度更新公式的代码模拟(伪代码)
w = 0.729 # 惯性权重
c1 = 1.49445 # 学习因子1
c2 = 1.49445 # 学习因子2
v_i = w * v_i + c1 * random() * (pbest_i - x_i) + c2 * random() * (gbest - x_i)这里 $vi$ 是粒子 $i$ 的速度,$xi$ 是粒子 $i$ 的当前位置,$pbest_i$ 是粒子 $i$ 的历史最优位置,$gbest$ 是全局最优位置,$random()$ 是在 $[0, 1]$ 之间的随机数。通过不断更新速度和位置,粒子群逐渐靠近最优解,从而优化LSSVM的参数。
- Adaboost:它是一种迭代的集成学习算法,通过训练多个弱学习器,将它们加权组合成一个强学习器。每次迭代中,Adaboost会调整样本的权重,让下一个弱学习器更关注上一轮预测错误的样本。
二、多输入单输出模型构建
假设我们有多个输入特征 $X = [x1, x2, \cdots, x_n]$,输出为 $y$。在代码实现中,我们可以这样来构建数据集(以Python和pandas为例):
import pandas as pd
# 假设从文件中读取数据
data = pd.read_csv('data.csv')
X = data[['feature1', 'feature2', 'feature3']] # 多个输入特征
y = data['target'] # 单输出然后我们将数据集划分为训练集和测试集,这里使用 sklearn 库中的 traintestsplit 函数:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)三、模型训练与评价
- 模型训练:首先使用PSO优化LSSVM的参数,然后将优化后的LSSVM作为弱学习器集成到Adaboost中。下面是一个简化的代码框架(使用
sklearn中的相关库):
from sklearn.svm import SVR
from sklearn.ensemble import AdaBoostRegressor
from pyswarm import pso # 用于PSO优化
# 定义LSSVM模型
def lssvm_model(C, gamma):
return SVR(kernel='rbf', C = C, gamma = gamma)
# 定义适应度函数,这里用均方误差(MSE)
def fitness_function(params):
C, gamma = params
model = lssvm_model(C, gamma)
model.fit(X_train, y_train)
y_pred = model.predict(X_train)
return mean_squared_error(y_train, y_pred)
# 使用PSO优化参数
lb = [0.01, 0.01] # 下限
ub = [100, 100] # 上限
best_params, _ = pso(fitness_function, lb, ub)
# 使用优化后的参数构建LSSVM
optimized_lssvm = lssvm_model(best_params[0], best_params[1])
# 构建Adaboost回归模型
adaboost_model = AdaBoostRegressor(optimized_lssvm, n_estimators = 50)
adaboost_model.fit(X_train, y_train)- 评价指标:我们使用R2、MAE、MSE、RMSE和MAPE等指标来评估模型性能。代码如下:
from sklearn.metrics import r2_score, mean_absolute_error, mean_squared_error
import numpy as np
y_pred = adaboost_model.predict(X_test)
r2 = r2_score(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
mse = mean_squared_error(y_test, y_pred)
rmse = np.sqrt(mse)
mape = np.mean(np.abs((y_test - y_pred) / y_test)) * 100
print(f'R2: {r2}')
print(f'MAE: {mae}')
print(f'MSE: {mse}')
print(f'RMSE: {rmse}')
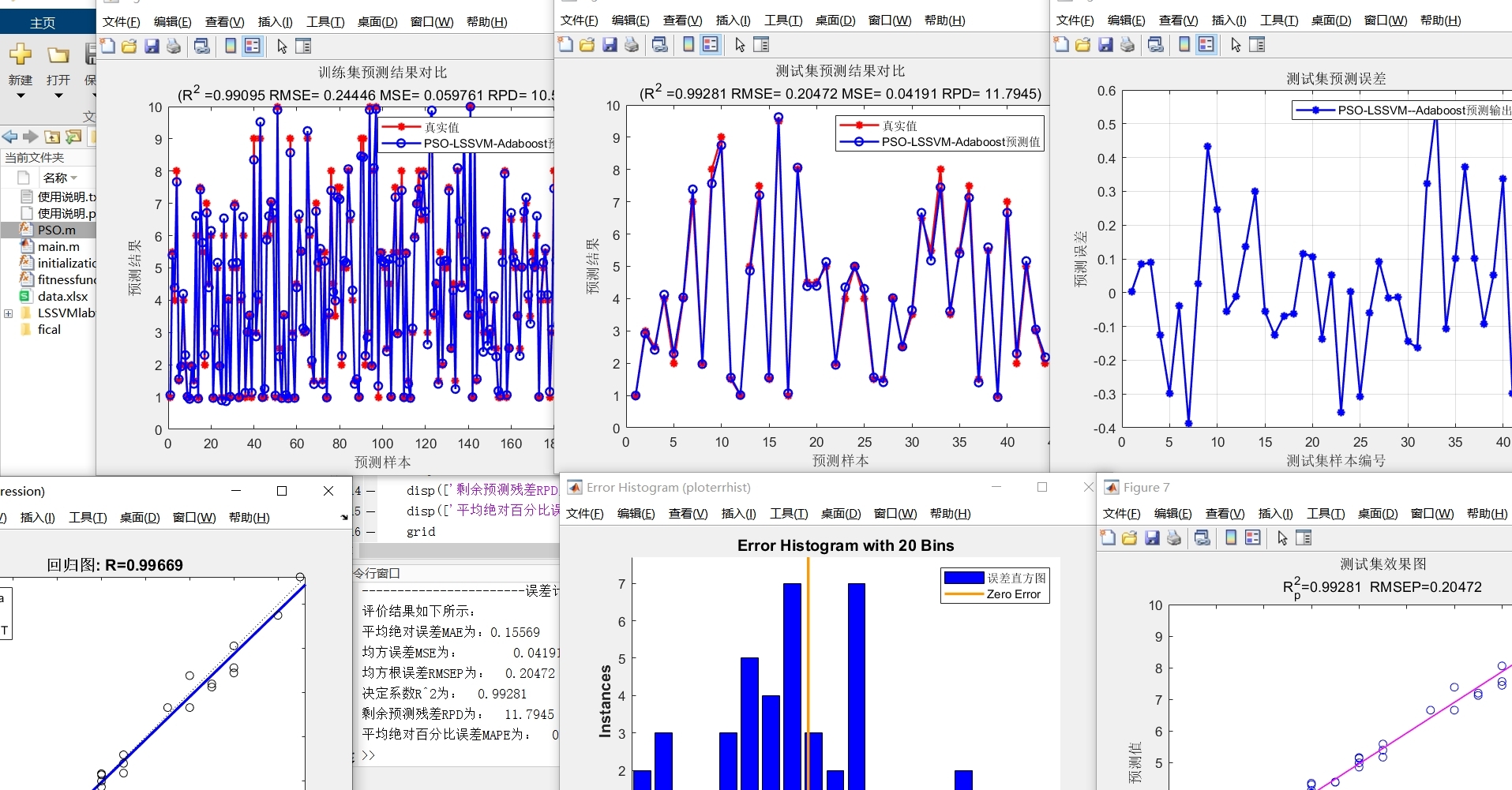
print(f'MAPE: {mape}')R2 衡量的是模型的拟合优度,越接近1表示模型拟合效果越好;MAE反映预测值与真实值误差的平均绝对值;MSE计算的是预测值与真实值误差的平方和的平均值;RMSE是MSE的平方根,与MAE相比,它对较大的误差给予更大的惩罚;MAPE以百分比的形式展示预测误差,便于理解相对误差大小。
PSO-LSSVM-adaboost基于粒子群优化最小二乘支持向量机LSSVM的Adaboost回归预测,PSO-LSSVM-Adaboost回归预测,多输入单输出模型。 评价指标包括:R2、MAE、MSE、RMSE和MAPE等,方便学习和替换数据。
通过上述过程,我们完成了PSO - LSSVM - Adaboost多输入单输出回归预测模型的构建、训练和评价。希望这篇文章能帮助大家快速上手这个模型,并根据自己的数据进行灵活替换和优化。
这样一个模型在实际应用中,可以帮助我们根据多个相关因素,准确预测出目标变量的值,为决策提供有力支持。大家不妨动手实践一下,感受它的魅力吧!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)