八大黄金数据分析模型与实战场景,助你告别“浆糊”数据
在数据分析和数据仓库(Data Warehouse)的建设过程中,你是否也遇到过这样的窘境:
-
明明有数据,但要搞个简单的销售报表,关联查询(Join)写到手软,性能还差得要命?
-
面对复杂的业务(比如从采购到库存的全链路),不知道该用一张大表兜底,还是该把表拆得“七零八落”?
-
ERP 系统里的项目编码、CRM 里自定义的项目号,一物多码,整合数据时简直想抓狂?
-
业务系统里的物料标准成本变来变去,但 BI 端就是没法还原历史某时刻的真实成本?
别慌,你遇到的这些问题,其实前人都遇到过。数据仓库建模并不是凭空想象,它有一套成熟的“配方”——分析模型。
今天,我们就把数仓工程师和架构师手里最常用的8 大黄金分析模型拿出来,进行一次深度的、全方位的解剖。我们会从基础维度建模讲起,一直聊到复杂的架构级敏捷建模。
最关键的是,我们不只讲抽象的概念,更会结合真实的实用场景(如销售分析、物料分类、高管驾驶舱、财务凭证等),让你彻底弄清楚:什么是这些模型、它们解决什么逻辑、以及最适合用在哪里。
话不多说,全是干货,建议收藏备用。
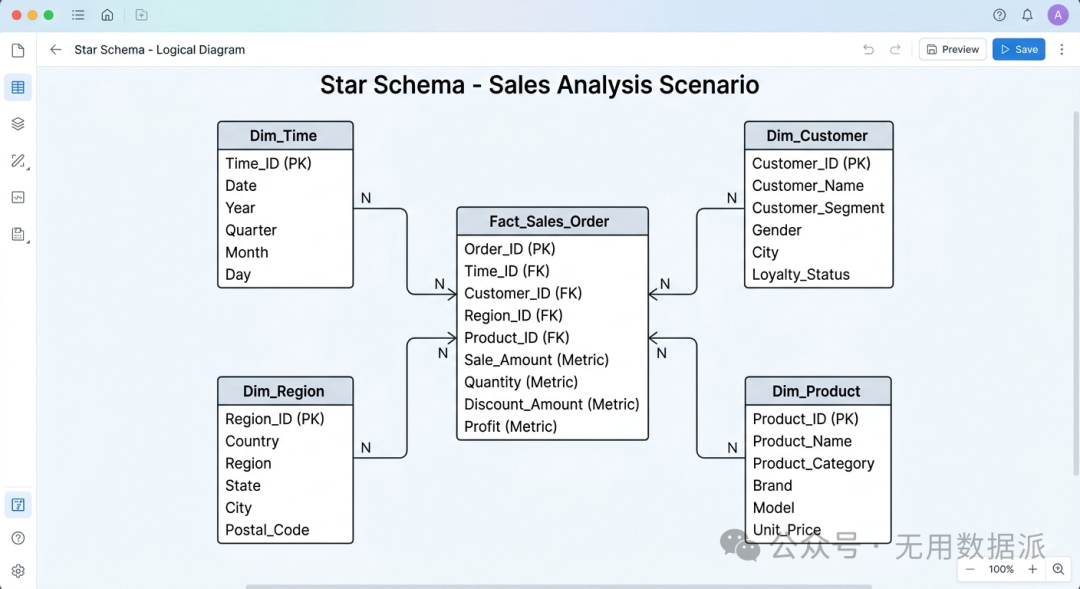
1. 基础维度建模:星型模型 (Star Schema)
|
字段名称 |
内容详情 |
|
模型名称 |
星型模型 (Star Schema) |
|
所属类型 |
维度建模 / 经典分析模型 |
|
模型涵义 |
以一个事实表为中心,直接关联多个维度表,结构简单且直观,是 BI 分析的最标准形态。 |
|
SQL逻辑与构建策略 |
【轻度冗余】 采用JOIN逻辑。事实表存外键 ID,维度表存属性。查询时通过Fact.ID = Dim.ID关联。维度表保持扁平。 |
|
推荐数仓处理 |
推荐 |
|
场景示例 |
销售分析:以销售订单事实表为中心,关联时间、客户、地区、产品四个维度表。 |
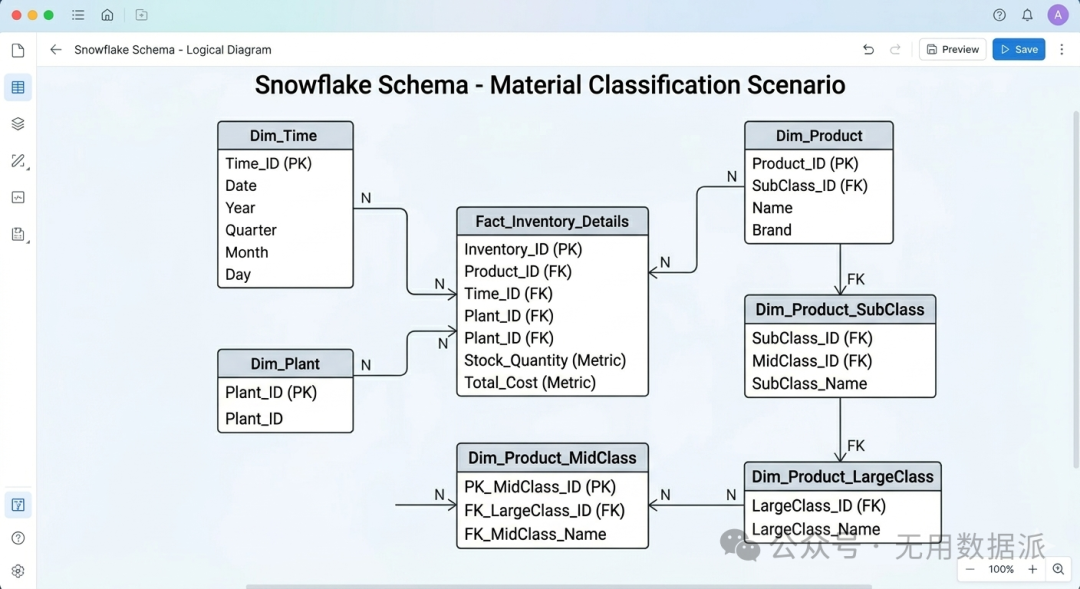
2. 规范化建模:雪花模型 (Snowflake Schema)
|
字段名称 |
内容详情 |
|
模型名称 |
雪花模型 (Snowflake Schema) |
|
所属类型 |
维度建模 / 规范化模型 |
|
模型涵义 |
对星型模型的维度表进一步规范化拆分。维度表可外接子维度表,层级较深,减少了数据冗余。 |
|
SQL逻辑与构建策略 |
【完全拆散】 严格遵循范式。需要多层嵌套JOIN。结构严谨但查询链路长。建议在展示层将其打平成星型。 |
|
推荐数仓处理 |
不推荐 (建议在数仓层打平以提升性能) |
|
场景示例 |
物料分类:产品表 -> 子类表 -> 中类表 -> 大类表,层层嵌套。 |
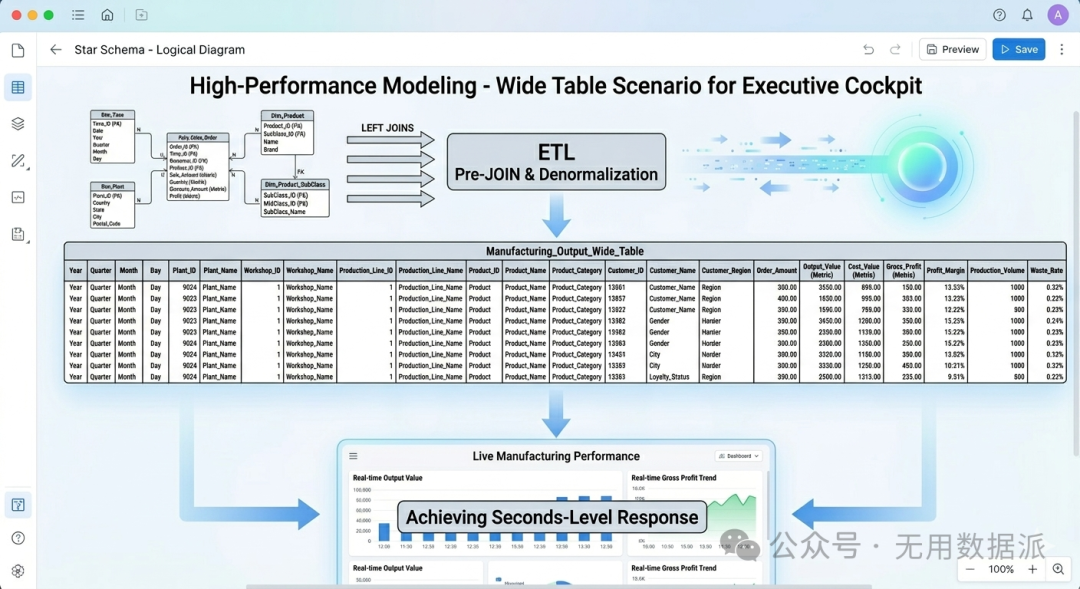
3. 高性能建模:大宽表模型 (Wide Table)
|
字段名称 |
内容详情 |
|
模型名称 |
大宽表模型 (Wide Table / Denormalized Model) |
|
所属类型 |
物理分析模型 / 扁平化模型 |
|
模型涵义 |
将事实表与相关维度表的所有字段预先通过 ETL 整合进一张单表,彻底取消 Join 操作。 |
|
SQL逻辑与构建策略 |
【高度冗余】 在 ETL 阶段使用LEFT JOIN将所有属性拍平。单表结构,无须关联,牺牲存储换取扫描速度。 |
|
推荐数仓处理 |
强制推荐 (特别是配合 Doris/ClickHouse 等时) |
|
场景示例 |
高管驾驶舱:制造业产值、毛利实时看板,追求秒级响应。 |
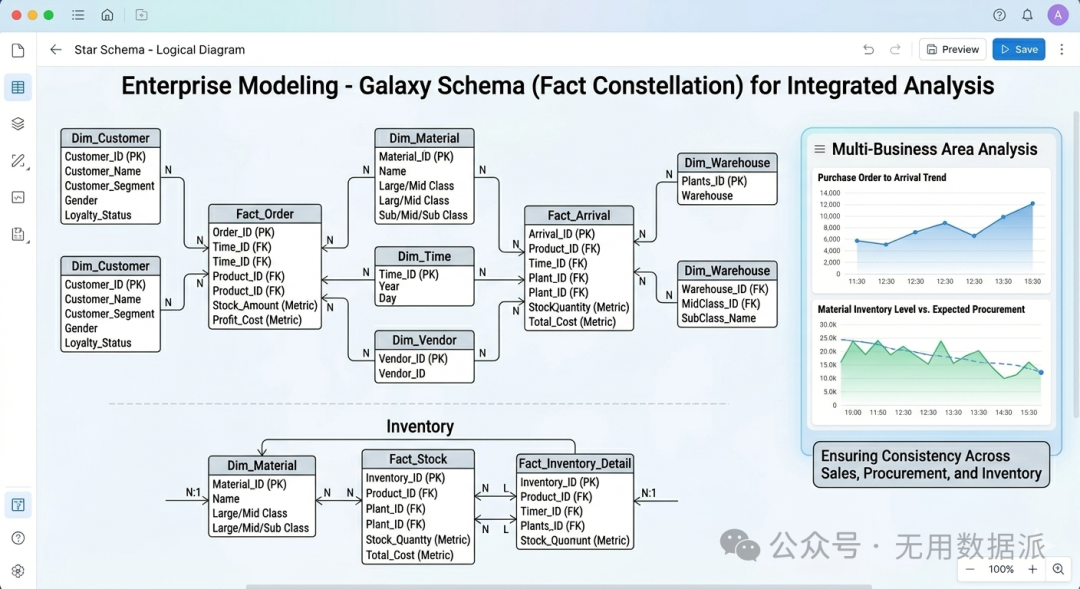
4. 企业级建模:星座模型 (Galaxy Schema)
|
字段名称 |
内容详情 |
|
模型名称 |
星座模型 (Galaxy Schema / Fact Constellation) |
|
所属类型 |
维度建模 / 综合应用模型 |
|
模型涵义 |
多个事实表共享同一组维度表。是企业中多个业务域联动分析的基础。 |
|
SQL逻辑与构建策略 |
【高度冗余】 核心是“一致性维度”。 SQL 上由多个事实表指向同一物理维表。需确保多业务域对同一属性定义一致。 一般面向不同主表是需要构建不同的SQL脚本, |
|
推荐数仓处理 |
部分推荐 (重点在于维度的一致性治理)、需要考虑关联模型构建该星座模型, |
|
场景示例 |
进销存联动:采购场景多事实表(订单、到货、开票、付款)以及库存事实表共用同一个“物料”维度。 |
5. 时间追溯建模:拉链表 (SCD Type 2)
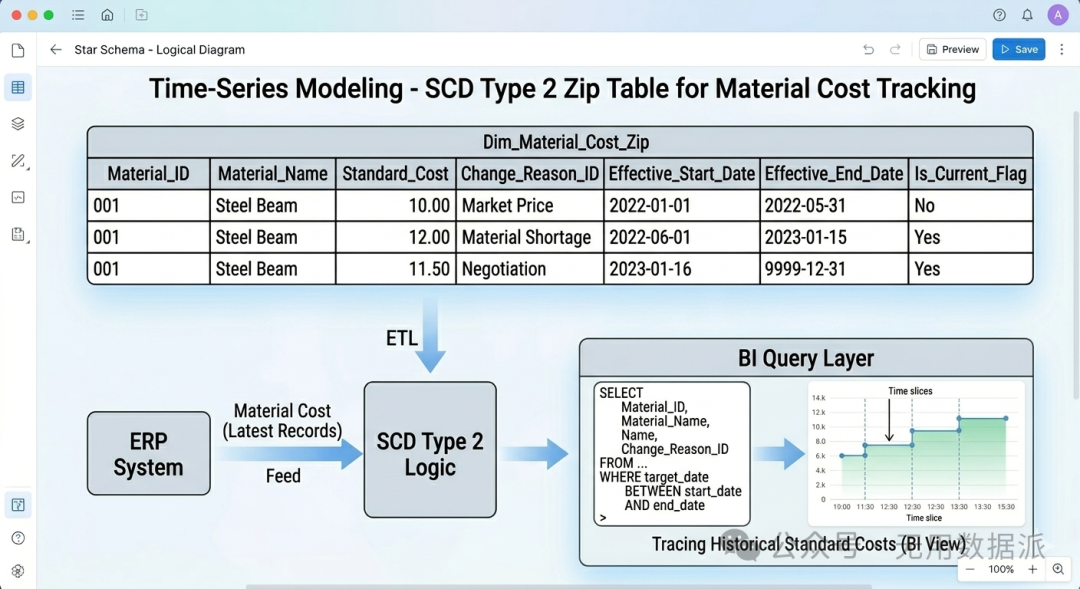
|
字段名称 |
内容详情 |
|
模型名称 |
拉链表 (Slowly Changing Dimensions Type 2) |
|
所属类型 |
时间相关模型 / 历史追溯模型 |
|
模型涵义 |
记录维度属性随时间的变化。通过“开始日期”和“结束日期”标记数据的有效期。 |
|
SQL逻辑与构建策略 |
【拆散+时间戳】 不覆盖旧数据,新增行记录。查询需用WHERE target_date BETWEEN start_date AND end_date。 |
|
推荐数仓处理 |
强制推荐 (逻辑复杂,严禁在 BI 端实时计算),拉链表是于时间序列上记录不同的变更状态,将变更状态进行时间切片的记录,数仓用于记录,而BI用于呈现和分析 |
|
场景示例 |
成本变动追踪:追踪物料在过去两年中每一次采购价格的调整历史。一个物料的不同时间的标准成本变动及原因溯源时候需要用到拉链表,一般标准成本在ERP系统中仅存最新记录。 |
6. 数据治理建模:Mapping 模型
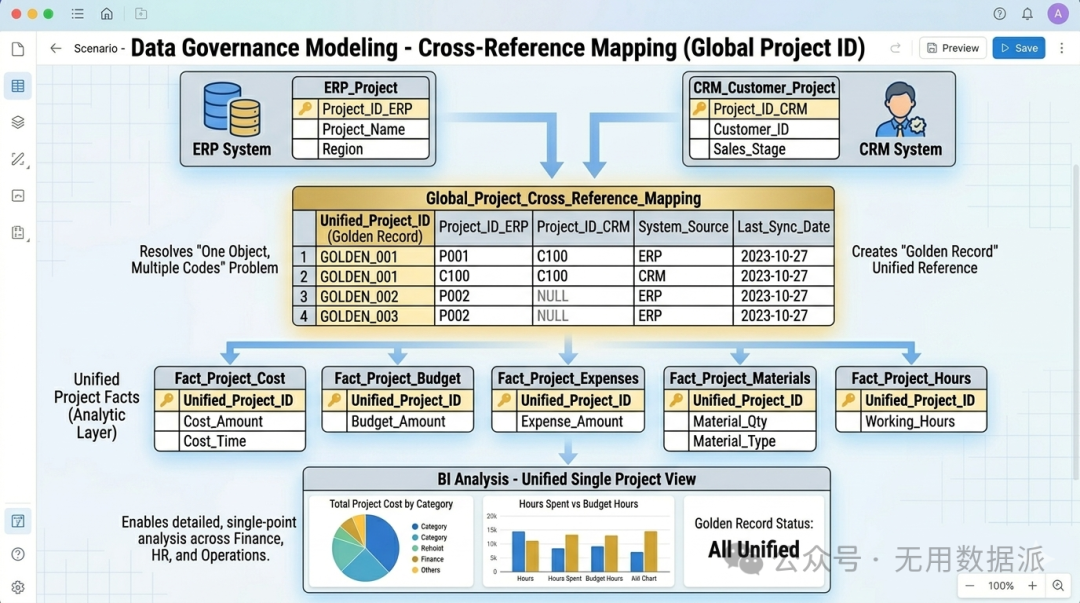
|
字段名称 |
内容详情 |
|
模型名称 |
Mapping 模型 (Cross-Reference Mapping) |
|
所属类型 |
数据治理 / ID 映射模型 |
|
模型涵义 |
用于解决多源系统中“一物多码”或“一客多号”问题,建立全局统一的对应关系。 |
|
SQL逻辑与构建策略 |
【高度冗余】 构建中间转换表。SQL 逻辑:事实 A JOIN Mapping JOIN 事实 B。通过黄金记录实现统一。 但是在分析层需要使用多个SQL脚本来分析基于项目的不同事实数据;仅是基于项目号的汇总则无须多个SQL. |
|
推荐数仓处理 |
强制推荐(按照项目主键内容将相关事实数据进行治理与规范)、由BI工具按需进行调取。 |
|
场景示例 |
全局项目号/客户号:串联 ERP 项目编码与 CRM 客户项目号。项目的成本分析,项目的预算、项目的费用、项目的材料、项目的工时通过项目号能够同时呈现明细信息的时候,则为多事实, |
7. 业务逻辑建模:主从模型 (Master-Detail)
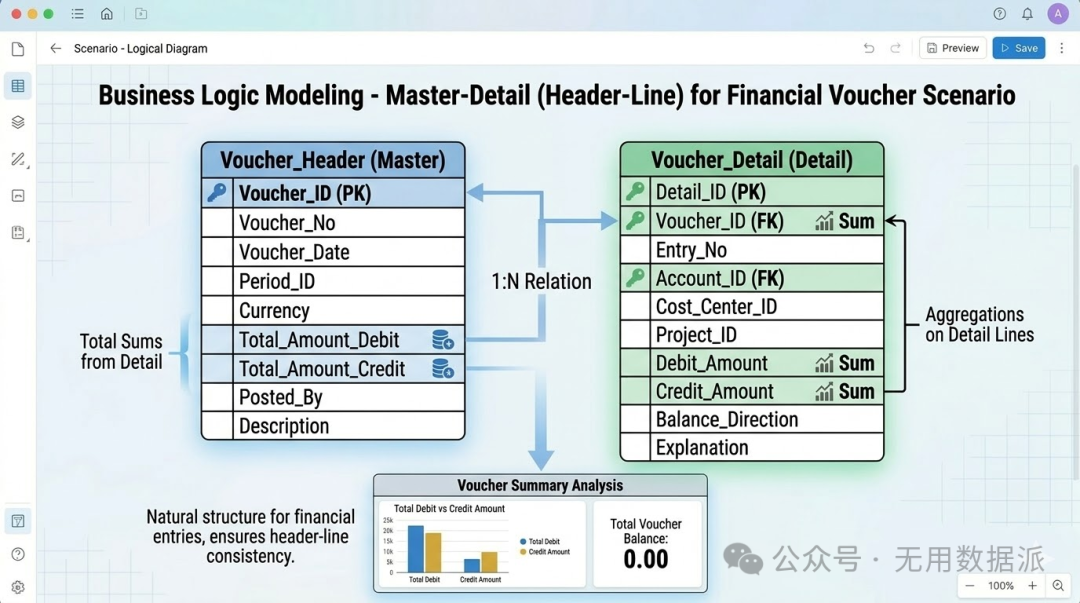
|
字段名称 |
内容详情 |
|
模型名称 |
主从模型 (Header-Line / Master-Detail) |
|
所属类型 |
业务单据模型 |
|
模型涵义 |
模拟真实的业务单据结构,如一张订单头(Master)对应多个商品明细行(Detail)。 |
|
SQL逻辑与构建策略 |
【自然拆散】 主外键 1:N 关联。需注意聚合陷阱,通常先处理明细行数据,再通过LEFT JOIN进行关联关联。 |
|
推荐数仓处理 |
视数据量而定 |
|
场景示例 |
财务凭证:一张凭证头信息关联多条借贷明细分录。 |
8. 敏捷架构建模:Data Vault 2.0
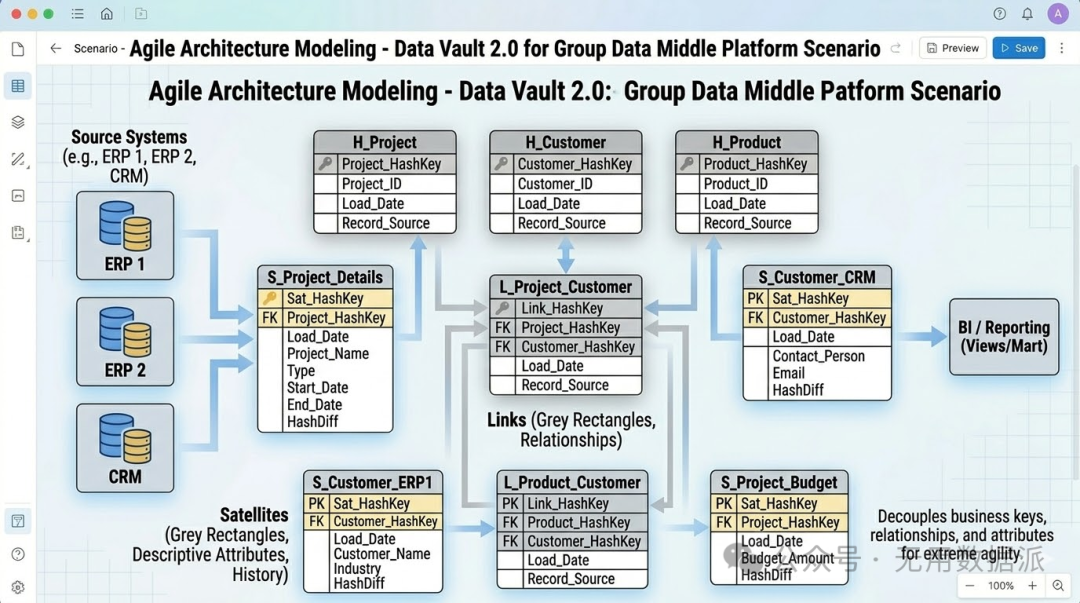
|
字段名称 |
内容详情 |
|
模型名称 |
Data Vault 2.0 (枢纽-链接-卫星) |
|
所属类型 |
架构级模型 / 解耦模型 |
|
模型涵义 |
将业务键、关联关系、描述属性完全分离。目的是实现底层系统的极端解耦和高度敏捷。 |
|
SQL逻辑与构建策略 |
【极端拆散】 通过大量的 Hub (核心键) 和 Link 表桥接。前端查询必须通过视图 (View) 将其重新冗余化。 |
|
推荐数仓处理 |
强制推荐 (用于大型集团数仓底层),通过数据标签表与多系统事实及维度表进行关联,进行转换及隐射,无需业务系统的强一致性,降低业务系统及数据仓库的压力 |
|
场景示例 |
集团数据中台:底层 ERP 频繁更换,但核心业务号(如项目号)需跨系统保持稳定。 |
====================================================
读到这里,相信你对这 8 种数仓建模模型已经有了一个清晰的认识。
从最经典直观的星型模型,到规范化减少冗余的雪花模型,再到追求极致性能的大宽表和实现跨域联动的一致性星座模型;从专门处理时间属性的拉链表和解决一物多码的数据治理Mapping 模型,到贴近单据原生业务逻辑的主从模型,甚至是极端解耦、高度敏捷的架构级 Data Vault。
在数据仓库的世界里,模型没有绝对的好坏之分,只有适合与不适合。
一个优秀的数仓架构师,就像是一位经验丰富的名厨,他不是只会一道菜,而是能根据数据规模、查询性能要求、业务复杂度和底层数据库特性(如列存、行存),从工具箱里灵活地挑选最合适的“食材”和“烹饪方法”。
最后,留一个小思考:在你目前的业务场景中,最让你头疼的数据问题是什么?你认为哪一种模型可以有效地解决你的困惑?
欢迎在评论区留言,我们一起探讨!如果你觉得这篇文章对你有帮助,别忘了点赞、在看、转发,让更多的数据伙伴看到!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 14
14 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)