【LangChain专栏】Retrieval 进阶:文本嵌入(Embedding)和向量存储实践
完成文本分块后,下一步就是文本嵌入(也叫向量化)。人类的自然语言无法直接被计算机计算相似度,而嵌入模型的作用,就是把文本块转换为固定维度的稠密向量,将文本的语义信息编码为数值表示,让计算机可以通过向量计算,判断两段文本的语义相似度。
嵌入模型的核心原理与价值
嵌入模型的核心逻辑是:语义相似的文本,在向量空间中的距离更近。
举个简单的例子:
- 句子1:"我家养了一只猫",嵌入向量为
[1.2, 3.4, 0.8, 2.1] - 句子2:"我家有一只宠物猫咪",嵌入向量为
[1.1, 3.5, 0.9, 2.0] - 句子3:"今天天气很好,适合出去旅游",嵌入向量为
[5.6, 0.2, 3.1, 1.2]
通过计算余弦相似度,句子1和句子2的向量夹角极小,相似度极高;而句子1和句子3的向量距离极远,相似度极低。这就是RAG语义检索的核心基础。
嵌入模型为RAG系统提供了核心能力支撑:
- 语义匹配:通过向量相似度计算,实现基于语义的匹配,而非传统的关键词匹配,解决同义词、近义词、句式变换的匹配问题;
- 语义检索:用户查询无需与知识库中的文本有完全一致的关键词,只需语义相关,就能检索到对应的内容;
- 信息聚类与挖掘:通过向量聚类,可对知识库内容进行分类、去重,优化知识库结构。
LangChain中嵌入模型的核心API
LangChain对嵌入模型做了统一的抽象封装,无论使用闭源API还是开源本地模型,都使用统一的接口,核心提供两个方法:
embed_query(text: str):针对用户查询语句的向量化,输入单个字符串,返回对应的向量;embed_documents(texts: List[str]):针对文档块的批量向量化,输入字符串列表,返回对应的向量列表。
示例:嵌入模型使用
import os
from openai import OpenAI
input_text = "衣服的质量杠杠的"
client = OpenAI(
api_key=os.getenv("DASHSCOPE_API_KEY"),
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1"
)
completion = client.embeddings.create(
model="text-embedding-v4",
input=input_text
)
# 向量信息
print(completion.model_dump_json())
# 向量维度
print(completion.data[0].embedding.__len__())

示例:开源嵌入模型使用(以BGE为例)
国内生产环境中,更推荐使用开源嵌入模型,可本地部署,无数据泄露风险,且中文效果远超通用模型。
# 前置依赖:pip install langchain-huggingface
from langchain_huggingface import HuggingFaceEmbeddings
# 初始化BGE开源嵌入模型(中文场景首选)
embeddings_model = HuggingFaceEmbeddings(
model_name="BAAI/bge-large-zh-v1.5", # 中文大模型,效果标杆
model_kwargs={"device": "cuda"}, # 有GPU用cuda,无GPU用cpu
encode_kwargs={"normalize_embeddings": True}, # 归一化,适配余弦相似度计算
)
# 向量化用法与OpenAI模型完全一致
query = "RAG的核心作用是什么?"
query_embedding = embeddings_model.embed_query(query)
print(f"开源模型向量维度:{len(query_embedding)}")2.3 开源vs闭源嵌入模型选型指南
|
模型类型 |
代表产品 |
优势 |
劣势 |
适用场景 |
|
闭源API嵌入模型 |
OpenAI text-embedding系列、Azure OpenAI嵌入服务、阿里云通义千问嵌入模型 |
开箱即用、无需算力、维护成本低、多语言效果均衡 |
数据需上传至第三方服务器,有隐私风险;按Token计费,大规模知识库成本高;无法微调适配业务场景 |
快速原型验证、非敏感数据场景、中小企业无GPU算力场景 |
|
开源本地嵌入模型 |
BGE系列、M3E系列、bge-m3、gte系列 |
可本地部署、数据隐私可控、可微调适配业务场景、中文效果更优、无长期使用成本 |
需要GPU算力支持、有一定的部署和维护成本 |
企业私有知识库、敏感数据场景、生产环境落地、需要定制化优化的场景 |
中文场景选型推荐:
- 轻量级场景:
bge-small-zh-v1.5,CPU即可运行,效果远超同体量模型; - 通用生产场景:
bge-large-zh-v1.5,中文效果标杆,平衡精度与性能; - 多语言/长文本场景:
bge-m3,支持多语言、超长文本,同时适配稠密检索、稀疏检索、多向量检索。
向量存储(Vector Stores):RAG的知识底座
介绍
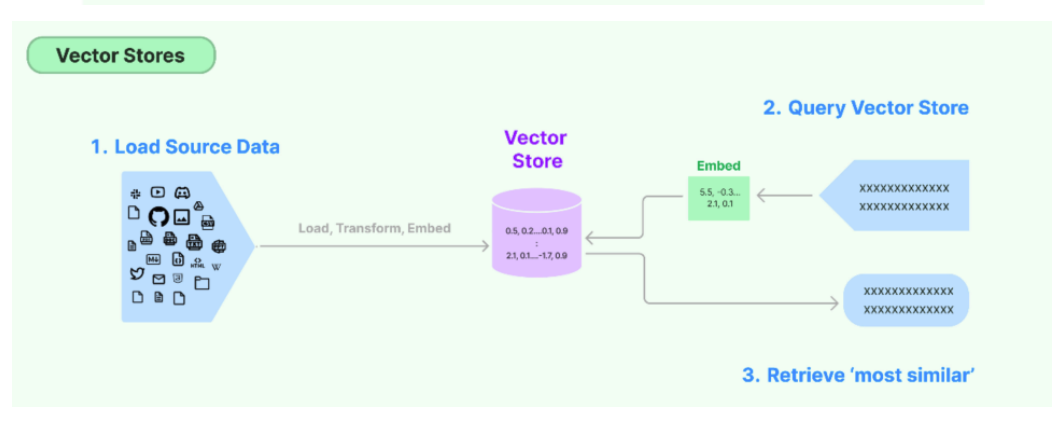
完成文本向量化后,我们需要一个专门的数据库来存储文本向量与对应的原始文档,同时提供高效的相似性检索能力,这就是向量数据库(Vector Stores)。
传统的关系型数据库无法高效处理高维向量的相似度计算,而向量数据库专为向量数据设计,通过向量索引算法,实现千万级、亿级向量的毫秒级相似性检索,是RAG系统的知识底座。
理解向量存储
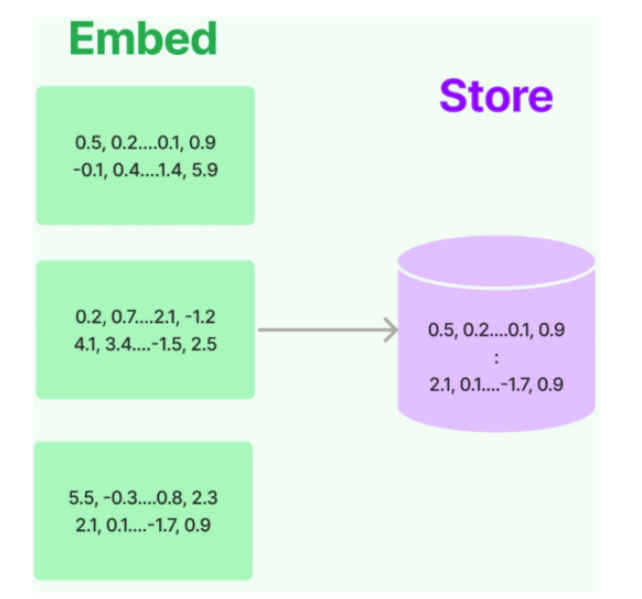
将文本向量化之后,下一步就是进行向量的存储。这部分包含两块:
向量的存储 :将非结构化数据向量化后,完成存储
向量的查询 :查询时,嵌入非结构化查询并检索与嵌入查询“最相似”的嵌入向量。即具有相似性 检索能力
向量数据库的核心能力
向量数据库的核心能力,围绕RAG的核心需求设计:
- 向量存储:存储高维向量数据,同时关联对应的原始文本、元数据,实现向量与原始内容的一一对应;
- 高效相似性检索:内置多种向量索引算法(如HNSW、IVF),支持海量向量的毫秒级相似度查询;
- 相似度计算:内置多种距离计算方式(余弦相似度、欧氏距离、内积),适配不同的嵌入模型与检索场景;
- 元数据过滤:支持检索时基于元数据进行条件过滤,缩小检索范围,提升精准度;
- 持久化存储:支持向量数据的磁盘持久化,避免程序重启后数据丢失,适配生产环境。
向量数据库的理解
向量数据库是一种专门用于存储和检索高维向量数据的数据库。以摄影师管理照片为例,传统的关系型数据库(如 MySQL、PostgreSQL)可以存储照片的元数据,如拍摄时间、地点、相机型号等,但当你希望根据照片的内容(颜色、纹理、物体等)进行搜索时,传统数据库就难以满足需求。
向量数据库的核心思路是:先将照片的内容通过特征提取算法映射到一个高维空间,每张照片对应空间中的一个点,再通过原点与这些点构成向量。向量化后,就可以利用向量之间的距离或相似度进行搜索。当用户查询时,数据库返回与查询向量最相似的照片,而不是精确匹配,实现模糊搜索。
这种方法不仅适用于照片,也可以用于视频、商品等其他素材,实现以图搜图、视频相关推荐、相似商品推荐等功能,大幅提升检索效率和用户体验。
主流向量数据库对比与选型
LangChain集成了超过50种向量数据库:
|
向量数据库 |
类型 |
核心优势 |
劣势 |
适用场景 |
|
Chroma |
本地嵌入式开源数据库 |
开箱即用、零配置、API极简、完美适配LangChain、支持持久化 |
分布式能力弱,不支持超大规模数据 |
原型验证、个人项目、中小规模知识库(百万级向量以内) |
|
FAISS |
Meta开源的向量检索库 |
性能极强、算法丰富、轻量化、CPU/GPU都适配 |
无内置持久化(需自行实现)、无服务端、分布式能力弱 |
高性能检索场景、本地部署、与其他数据库搭配使用 |
|
Milvus |
开源分布式向量数据库 |
专为生产环境设计、支持分布式部署、亿级向量毫秒级检索、完善的运维工具、云原生适配 |
部署复杂度高、需要集群资源、有一定的运维成本 |
企业级生产环境、大规模知识库(千万级以上向量)、高并发检索场景 |
|
PGVector |
PostgreSQL的向量扩展 |
基于关系型数据库,可同时存储结构化数据与向量数据、事务支持、无需额外维护一套数据库 |
极致性能弱于专用向量数据库、超大规模数据适配性一般 |
已有PostgreSQL业务、结构化+非结构化混合存储场景、中小规模企业应用 |
|
Pinecone |
云托管向量数据库服务 |
开箱即用、Serverless架构、无需运维、支持弹性扩缩容、超大规模数据适配 |
闭源收费、数据需上传至云端、国内访问有网络限制、隐私合规风险 |
海外业务、快速上线、无运维能力的团队、非敏感数据场景 |
选型法则:
- 学习/原型验证:首选Chroma,零配置,与LangChain无缝衔接,快速可跑通全流程;
- 本地部署/中小规模生产:首选FAISS+本地持久化,或Chroma持久化模式;
- 企业级大规模生产:首选Milvus,分布式架构,适配高并发、海量数据场景;
- 已有PostgreSQL业务:首选PGVector,减少技术栈复杂度,降低运维成本。
向量数据库实战:存储、基础检索与持久化
这里我们以Chroma为例,详解向量数据库的完整操作,包括数据入库、持久化、多种检索方式。
Chroma实战
前置依赖:pip install langchain-chroma chromadb
1. 基础存储与检索(内存模式)
import os
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
# 初始化嵌入模型
embeddings = DashScopeEmbeddings(model="text-embedding-v4",
dashscope_api_key=os.getenv("DASHSCOPE_API_KEY")
)
# 加载并拆分文档
loader = TextLoader("./data/rag_intro.txt", encoding="utf-8")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=20)
split_docs = text_splitter.split_documents(docs)
# 文档向量化并存储到Chroma(内存模式)
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
)
# 基础相似性检索
query = "RAG的核心优势是什么?"
# 检索最相关的3个文档块
result_docs = db.similarity_search(query, k=3)
# 查看检索结果
print(f"检索到相关文档数量:{len(result_docs)}")
for i, doc in enumerate(result_docs):
print(f"\n结果{i+1}:{doc.page_content}")
print(f"元数据:{doc.metadata}")
2. 持久化存储与加载
内存模式下,程序重启后数据会丢失,生产环境必须使用持久化模式:
# 1. 数据持久化到磁盘
db = Chroma.from_documents(
documents=split_docs,
embedding=embeddings,
persist_directory="./chroma_db", # 指定持久化目录
collection_name="enterprise_knowledge_base", # 指定集合名称,区分不同知识库
)
# 2. 程序重启后,直接加载已持久化的向量库
db = Chroma(
persist_directory="./chroma_db",
embedding_function=embeddings,
collection_name="enterprise_knowledge_base",
)
# 3. 加载后即可直接检索
query = "RAG如何缓解大模型幻觉?"
result_docs = db.similarity_search(query, k=2)
for doc in result_docs:
print(doc.page_content)3. 进阶检索能力
Chroma提供了多种进阶检索方式,适配不同的业务场景:
# 带相似度分数的检索(L2距离,分数越小越相似)
docs_with_score = db.similarity_search_with_score(
query="RAG的核心优势是什么?",
k=3
)
for doc, score in docs_with_score:
print(f"相似度分数:{score:.4f},内容:{doc.page_content[:50]}")
# 基于向量的直接检索
query = "RAG的核心优势是什么?"
query_embedding = embeddings.embed_query(query)
docs = db.similarity_search_by_vector(query_embedding, k=3)
# 元数据过滤检索(仅检索指定来源的文档)
docs = db.similarity_search(
query="RAG的核心优势是什么?",
k=3,
filter={"source": "./data/rag_intro.txt"} # 元数据过滤条件
)
# MMR检索(最大边际相关性,平衡相关性与多样性,避免结果冗余)
docs = db.max_marginal_relevance_search(
query="RAG的核心优势是什么?",
k=3,
lambda_mult=0.7 # 0=最大多样性,1=最小多样性
)
AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)