基于白鲸优化算法BWO的VMD - KELM光伏发电功率短期预测
matlab:基于白鲸优化算法BWO的VMD-KELM光伏发电功率预测 短期功率预测 - 基于变分模态分解VMD对特征数据进行分解,将子序列输入后续模型 - 用白鲸优化算法BWO优化KELM模型的核参数和正则化系数 - 注释详细
在光伏发电领域,准确的短期功率预测对于电力系统的稳定运行和能源管理至关重要。今天咱们来聊聊基于Matlab实现的基于白鲸优化算法(BWO)的VMD - KELM光伏发电功率预测方法。
一、变分模态分解(VMD)
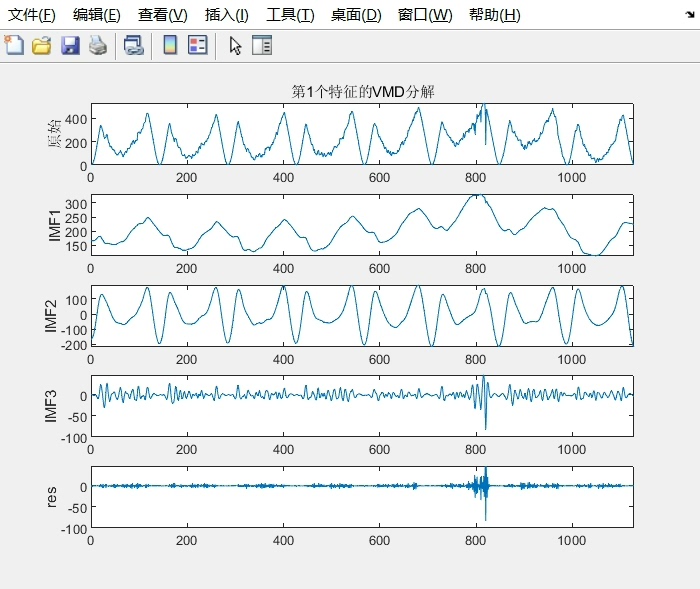
变分模态分解(VMD)是一种自适应的信号分解方法,它能够将复杂信号分解为一系列具有不同中心频率的本征模态函数(IMF)。在光伏发电功率预测中,我们可以利用VMD对原始功率数据进行分解,将其转化为多个子序列,这些子序列更易于后续模型处理。
matlab:基于白鲸优化算法BWO的VMD-KELM光伏发电功率预测 短期功率预测 - 基于变分模态分解VMD对特征数据进行分解,将子序列输入后续模型 - 用白鲸优化算法BWO优化KELM模型的核参数和正则化系数 - 注释详细
下面是一段简单的Matlab代码实现VMD对功率数据的分解:
% 假设原始功率数据为P,长度为N
N = length(P);
% 设置VMD的参数
alpha = 2000; % 惩罚参数,控制带宽约束的强度
tau = 0; % 噪声容限,设为0表示无噪声
K = 5; % 分解的模态数
DC = 0; % 是否包含直流分量,0表示不包含
init = 1; % 初始化模式,1表示随机初始化
tol = 1e-7; % 收敛阈值
% 进行VMD分解
[U, u_hat, omega] = VMD(P, alpha, tau, K, DC, init, tol);代码分析:
- 首先定义了原始功率数据
P的长度N。 - 设置
VMD的各项参数:
-alpha:惩罚参数,值越大,每个模态的带宽越窄,分解后的模态更加集中在各自的中心频率附近。
-tau:噪声容限,这里设为0,即不考虑噪声的影响。
-K:指定要分解出的模态数,这个值需要根据数据特点和经验来选择,比如这里设为5。
-DC:控制是否包含直流分量,0表示不包含。
-init:初始化模式,1表示随机初始化每个模态的中心频率。
-tol:收敛阈值,当迭代过程中目标函数的变化小于这个阈值时,认为分解收敛。 - 最后通过
VMD函数进行实际的分解,得到分解后的模态U、频域表示u_hat以及每个模态的中心频率omega。
二、白鲸优化算法(BWO)优化KELM模型
极限学习机(KELM)是一种单隐层前馈神经网络,具有学习速度快的优点,但它的核参数和正则化系数对预测性能影响较大。这时候就可以使用白鲸优化算法(BWO)来对其进行优化。
1. KELM模型基础
% 假设X为输入特征矩阵,Y为对应的输出功率向量
inputnum = size(X, 2); % 输入特征维度
hiddennum = 100; % 隐层节点数
outputnum = 1; % 输出维度
% 随机生成隐层权重和偏置
W = randn(hiddennum, inputnum);
b = randn(hiddennum, 1);
% 计算隐层输出
H = sigmoid(W * X' + repmat(b, 1, size(X, 1)));
% 计算输出权重
beta = pinv(H') * Y';代码分析:
- 确定输入特征维度
inputnum、隐层节点数hiddennum和输出维度outputnum。 - 随机生成隐层权重
W和偏置b。 - 使用
sigmoid函数作为激活函数计算隐层输出H。这里repmat函数用于将偏置b复制成与W * X'相同的维度,以便相加。 - 通过伪逆计算输出权重
beta。
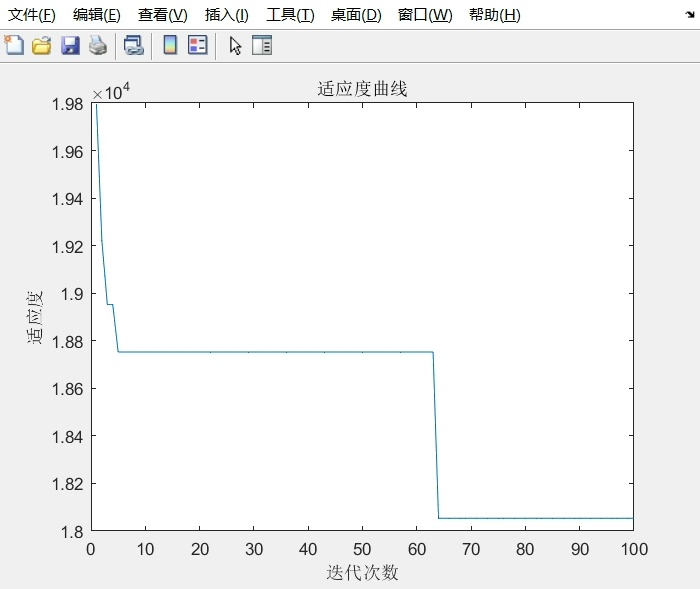
2. 白鲸优化算法(BWO)优化KELM
% 适应度函数定义
function fitness = fitness_func(x)
global X Y hiddennum outputnum
% 提取核参数和正则化系数
sigma = x(1);
C = x(2);
% 计算核矩阵
K = kernel_matrix(X, X, sigma);
% 计算输出权重
I = eye(size(K, 1));
beta = (K + I / C) \ Y';
% 计算预测输出
Y_pred = kernel_matrix(X, X, sigma) * beta;
% 计算均方误差作为适应度
fitness = mean((Y - Y_pred).^2);
end
% 核矩阵计算函数
function K = kernel_matrix(X1, X2, sigma)
n1 = size(X1, 1);
n2 = size(X2, 1);
K = zeros(n1, n2);
for i = 1:n1
for j = 1:n2
K(i, j) = exp(-norm(X1(i, :) - X2(j, :))^2 / (2 * sigma^2));
end
end
end
% BWO算法主程序
% 初始化参数
pop = 30; % 种群数量
dim = 2; % 优化参数维度(核参数和正则化系数)
MaxIter = 100; % 最大迭代次数
lb = [0.01, 0.01]; % 下限
ub = [100, 100]; % 上限
% 初始化种群
Whales = initializepop(pop, dim, lb, ub);
% 迭代优化
for t = 1:MaxIter
% 计算适应度
fitness = zeros(pop, 1);
for i = 1:pop
fitness(i) = fitness_func(Whales(i, :));
end
[best_fitness, best_index] = min(fitness);
best_whale = Whales(best_index, :);
% BWO算法更新策略
a = 2 - t * (2 / MaxIter); % 线性递减的控制参数
for i = 1:pop
r1 = rand();
r2 = rand();
A = 2 * a * r1 - a;
C = 2 * r2;
l = (MaxIter - t) / MaxIter * (-1);
p = rand();
if p < 0.5
if abs(A) < 1
D = abs(C * best_whale - Whales(i, :));
Whales(i, :) = best_whale - A * D;
else
rand_whale_index = randi(pop);
D = abs(C * Whales(rand_whale_index, :) - Whales(i, :));
Whales(i, :) = Whales(rand_whale_index, :) - A * D;
end
else
D = abs(best_whale - Whales(i, :));
Whales(i, :) = best_whale + exp(l) * cos(2 * pi * r1) * D;
end
end
% 边界处理
Whales = bound(Whales, lb, ub);
end
% 得到优化后的核参数和正则化系数
sigma_opt = best_whale(1);
C_opt = best_whale(2);代码分析:
- 适应度函数
fitnessfunc:
- 从输入向量x中提取核参数sigma和正则化系数C。
- 使用kernelmatrix函数计算核矩阵K。
- 根据核矩阵和正则化系数计算输出权重beta。
- 计算预测输出Y_pred,并以均方误差作为适应度值返回。 - 核矩阵计算函数
kernel_matrix:
- 通过循环计算输入矩阵X1和X2中每对样本之间的高斯核函数值,填充核矩阵K。 - BWO算法主程序:
- 初始化种群数量pop、优化参数维度dim、最大迭代次数MaxIter以及参数的上下限lb和ub。
- 初始化种群Whales。
- 在每次迭代中:
- 计算每个个体的适应度,找到最优个体及其适应度。
- 根据BWO算法的更新策略更新种群中每个个体的位置,这里涉及到根据不同条件计算A、C、l、p等参数,以决定个体是向最优个体靠近还是随机移动等。
- 对更新后的种群进行边界处理,确保参数在设定的上下限范围内。
- 最后得到优化后的核参数sigmaopt和正则化系数Copt。
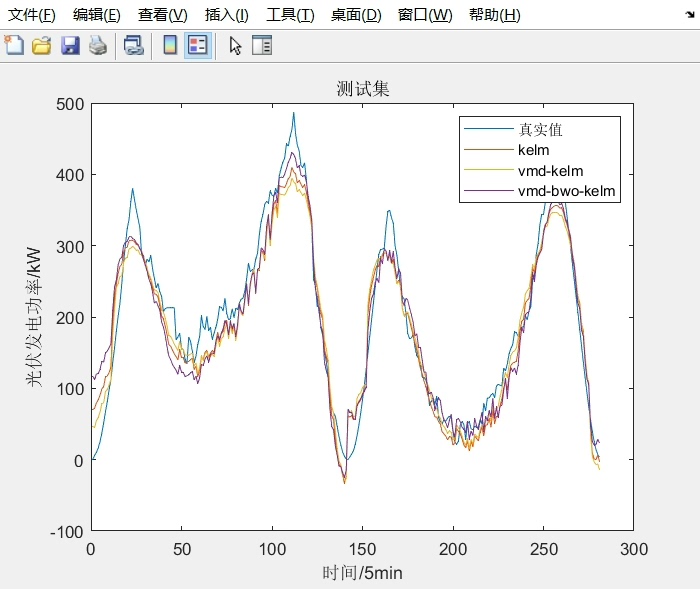
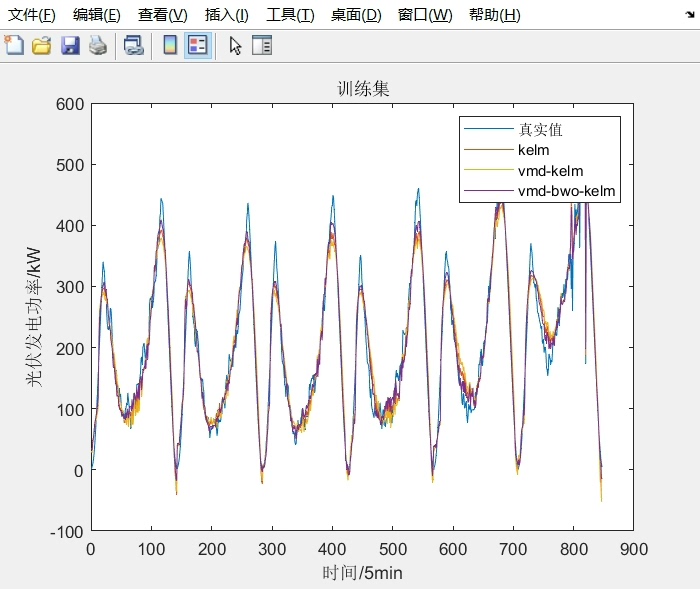
通过上述VMD对特征数据的分解,以及BWO对KELM模型的优化,能够显著提升光伏发电功率短期预测的精度。大家可以根据实际情况进一步调整参数和优化代码,以适应不同的数据集和应用场景。希望这篇博文能对研究光伏发电功率预测的小伙伴们有所帮助!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 18
18 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)