CVPR 2025 | ROD-MLLM:迈向更可靠的多模态大型语言模型中的目标检测
论文信息
- 论文题目:ROD-MLLM: Towards More Reliable Object Detection in Multimodal Large Language Models
- 论文作者:Heng Yin,Yuqiang Ren,Ke Yan,Shouhong Ding,Yongtao Hao
- 发表单位:Tongji University,YouTu Lab,Tencent
- 发表会议:CVPR2025
论文主要贡献
现有 MLLM(多模态大语言模型) 仅能定位图像中已存在的单个目标,无法处理多目标与不存在目标场景,易产生错误匹配。我们提出ROD-MLLM模型,用于自由语言下的可靠目标检测:
1.提出基于查询的定位机制提取低层目标特征,将全局与区域视觉信息对齐到文本空间,由大型语言模型完成高层理解与最终定位决策;
2.设计自动化数据标注流程,构建ROD 数据集,解决训练数据稀缺问题;
3.实验表明,模型在指代、定位、语言目标检测等任务上达 SOTA,在 D³ 基准上较现有 MLLMs 提升13.7 AP,超越多数专用检测模型。
论文创新点
(1)提出了ROD-MLLM,这是一种能够执行基于语言的目标检测的多模态大型语言模型。它能基于自由形式的语言描述实现统一的目标定位,并能拒绝不存在的目标。
(2)设计了一个用于基于语言的检测的自动化标注流水线,并构建了包含超过50万个对象描述-图像对的ROD数据集。该数据集能够有效提升对自由对象描述的检测能力,缓解了通用多语言大模型只能执行REC任务的不足。
(3)我们在与目标定位和生成相关的各种基准上进行了实验,包括基于语言的目标检测、REC和区域描述生成。我们的结果表明,与其他多模态大语言模型(MLLMs)相比,我们在这些任务上的性能更优。
方法
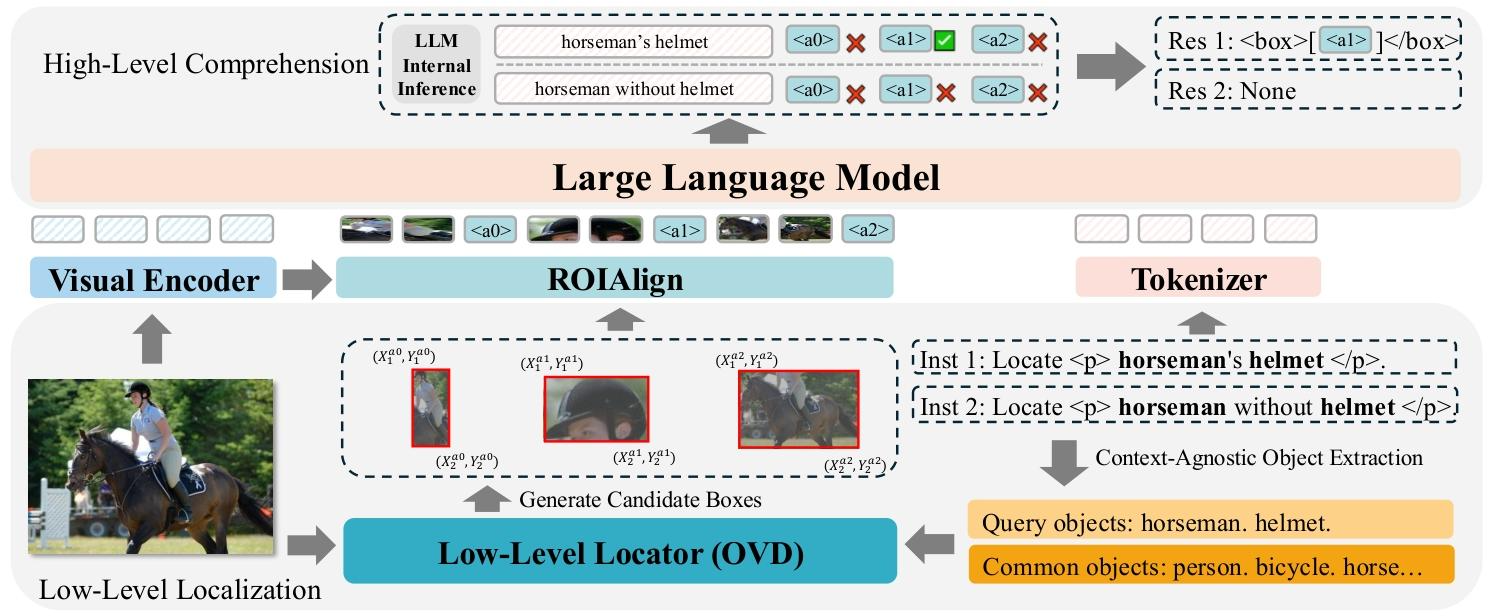
1.低级定位
基于查询的定位
B = L(I, O_query , O_common)
从用户查询中提取物体表达式,用N-gram(把句子按连续 N 个词切片,用来自动提取关键词的简单方法)提取所提及的物体,形成查询目标集O_query;补充 COCO 中的通用常见物体集O_common,增强通用场景感知;输入低级定位器(OVD),输出候选框集合B。
优点:只框出与查询相关的物体,大幅减少无效候选框;避开检测器不擅长复杂句子理解的缺点;不新增训练开销,兼容任意 OVD 检测器。
多粒度视觉输入
全局图像特征:用 CLIP 视觉编码器得到多层图像特征;取倒数第二层特征,通过两层 MLP(多层感知机) 投影器映射到文本空间;得到全局图像嵌入,用于让 LLM 理解整张图的整体内容。
区域视觉特征:从多层视觉特征中,选取第 12、18、L-1 层构建三层特征金字塔,并取平均;用ROI Align(8×8)根据候选框坐标,从特征图中抠出每个区域的视觉特征;把每个区域特征分成 2×2 个小块,每个块通过一层 MLP 变成一个文本令牌;用多个令牌表示一个区域,让 LLM 获得更细粒度的局部信息。
2.高级理解
以 Vicuna-7B 作为主干 LLM,完成复杂语义理解、目标筛选与不存在目标拒绝。
3.数据标注流程:全自动标注流水线
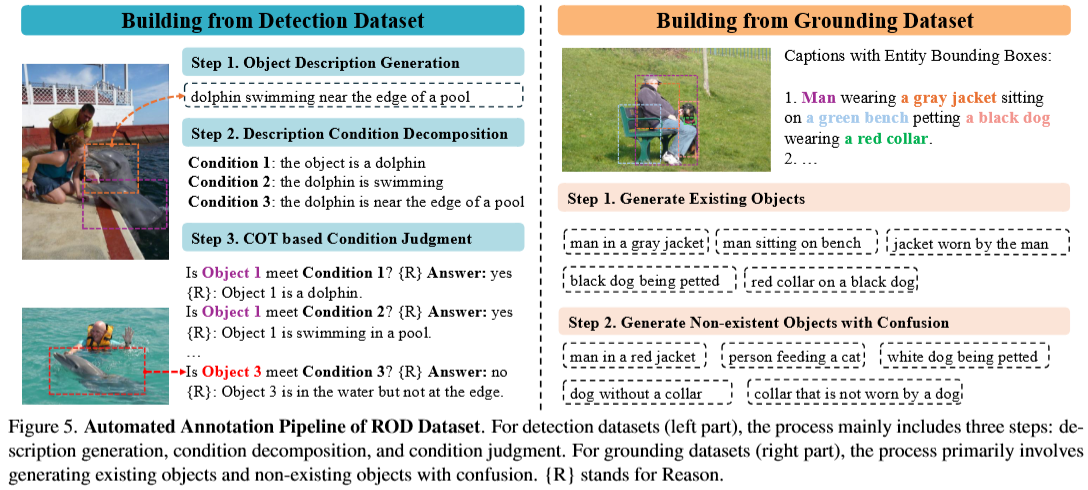
基于检测数据集(带框与类别)构建:生成对象的详细描述;将描述分解为几个必须满足的条件;给每个描述配正样本(原图)+ 负样本(随机同类别图),让 MLLM 逐条件判断目标是否满足每条规则,最终得到描述匹配 / 不匹配的目标框集合(基于COT的条件判断)。
基于定位数据集(带实体框的图像标题)构建:用 LLM 把标题中的实体扩展为丰富描述短语,生成语义相近但实际不存在的目标描述,让模型学会拒绝不存在 / 不匹配的查询。
合并成为ROD数据集。
实验分析
自由文本目标检测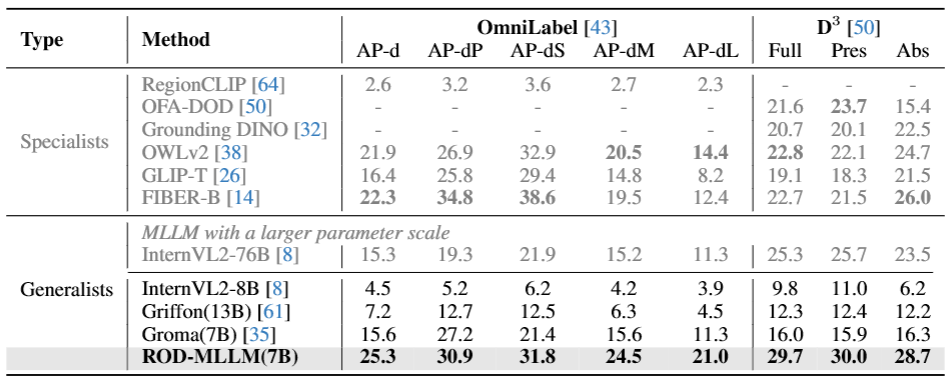 OmniLabel:AP-d 25.3,超同规模 MLLM +9.7 AP,长文本 / 否定描述优势明显;
OmniLabel:AP-d 25.3,超同规模 MLLM +9.7 AP,长文本 / 否定描述优势明显;
D³:Full AP 29.7,超现有 MLLM +13.7 AP,同时超越多数专用检测模型;
对存在目标与不存在目标描述均表现最优。
基础指代表达理解(REC)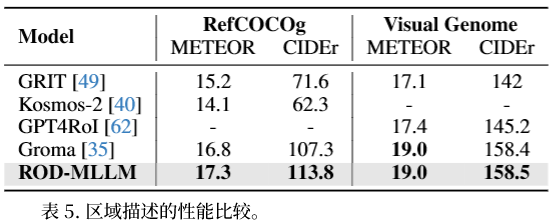
RefCOCOg 上 CIDEr 113.8,超 SOTA +6.5。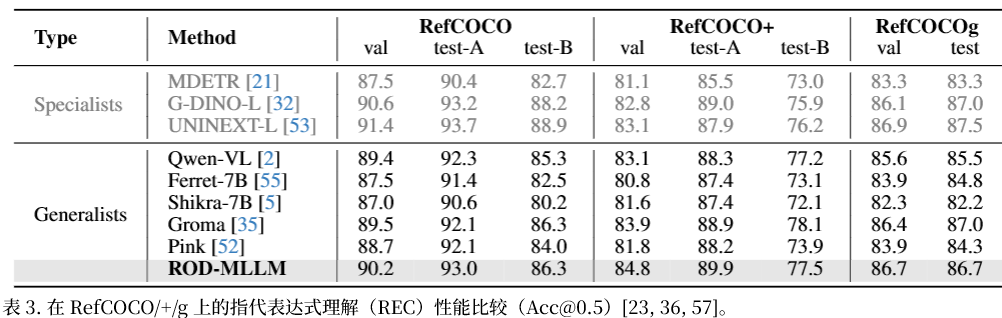
Acc@0.5 达90.2~93.0,超过 Shikra、Ferret、Groma 等主流 MLLM,保持顶尖水平。
广义指代表达理解(GREC)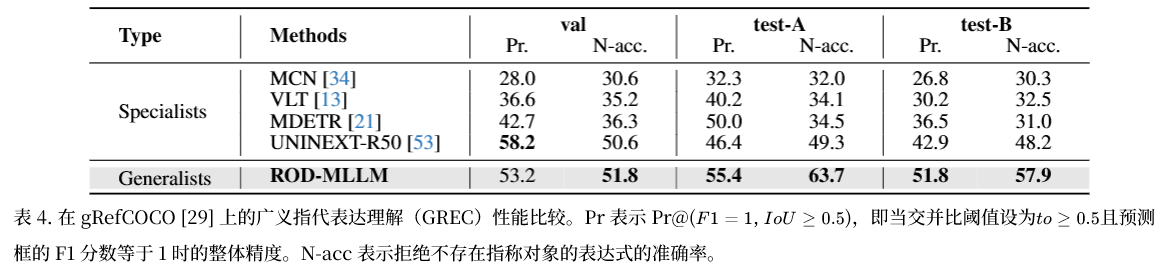
Pr 与 N-acc(无目标拒绝准确率)大幅领先专用模型,test-A/B 集分别提升 10.8% / 20.7%。
消融实验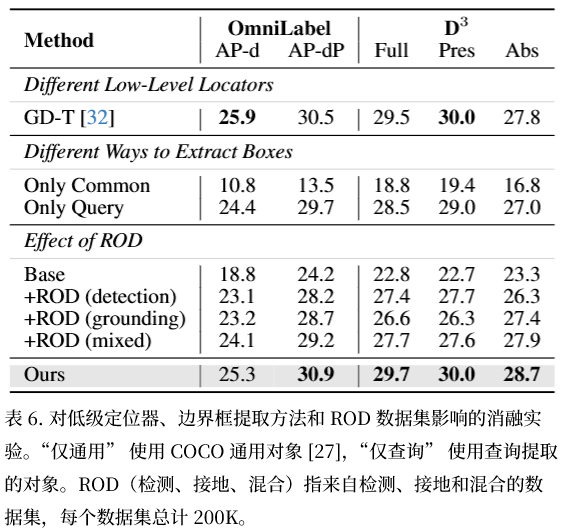
ROD 数据集:显著涨点,混合数据最优;
低层定位器:OWLv2 / Grounding DINO 通用,不依赖特定模型;
候选框提取:基于查询的物体框性能更好。
定性结果 能正确处理:否定语义、复杂描述、无目标场景;
能正确处理:否定语义、复杂描述、无目标场景;
不强行输出框,比 OWLv2、Griffon、Groma 更可靠。
个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)