对一些主流模型的结构解析(pt/onnx/openvino/gguf)
pt&&onnx&&openvino&&gguf
经过前面的学习,我们大概都知道有这些不同的模型了,也知道一些他们的运用场景,然后我想再学习一下他们都是由什么组成的
pt
构成
首先,如图

从 PyTorch 1.6.0 开始,.pt 文件实际上是一个 ZIP64 压缩档案
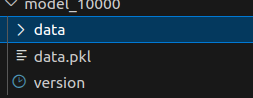
data.pkl
- 这是通过 Python 的 pickle 模块序列化的对象
- 包含:
-
- 是传递给
torch.save()对象的 pickle 序列化结果 - 包含模型的元数据和结构信息,但不包含实际的张量存储数据
- 具体包括:
- 是传递给
-
-
- 模型的类定义引用
- 张量的形状(shape)、数据类型(dtype)、步长(stride)等元数据
- 张量之间的视图关系(view relationships)
- state_dict 的字典结构(如果保存的是 state_dict)
- 对
data/中存储文件的引用指针
-
作用:
-
- 描述模型的架构和组织结构
- 记录如何重建模型对象的蓝图
- 指向实际数据在
data/文件夹中的位置
data 文件夹
- 包含所有的
torch.Storage对象(实际的张量数据) - 每个存储(storage)是一个单独的文件
- 文件通常以数字命名(0, 1, 2, 3...)
- 存储内容包括:
-
- 模型的权重(weights)
- 偏置(biases)
- 批量归一化的运行统计量(running_mean, running_var)
- 所有可学习参数和持久化缓冲区
作用:
- 存储模型的实际参数数据(张量的底层存储)
- 实现存储共享(storage sharing)
- 如果多个张量共享同一个底层存储(如视图关系),只保存一份数据
- 节省空间并保持张量间的关系
version
- 包含 PyTorch 的版本信息
- 用于兼容性检查
保存过程
- 序列化元数据 →
data.pkl
-
- 将 state_dict 的字典结构、键名等 pickle 化
- 记录每个张量的元信息
- 提取存储对象 →
data/
-
- 将每个独立的
torch.Storage提取出来 - 保存为单独的文件
- 将每个独立的
- 打包成 ZIP64 →
.pt文件
-
- 将所有文件压缩归档
加载过程
- 解压 ZIP64 归档
- 读取 data.pkl 重建字典结构和元数据
- 从 data/ 加载存储,填充实际数据
- 重建张量,恢复视图关系
拿我们HIMLoco训练的pt模型来举例
import torch
model_data = torch.load('/home/extra/zhy/桌面/IsaacGym_Preview_4_Package/HIMLoco-main/himloco_gym/logs/rough_go1/good/model_10000.pt',
map_location='cpu')
print("所有键名:", list(model_data.keys()))
# 常见的键名模式
possible_keys = ['model_state_dict', 'model', 'actor', 'critic', 'policy',
'state_dict', 'network', 'actor_critic']
for key in possible_keys:
if key in model_data:
print(f"\n找到模型权重键: '{key}'")
weights = model_data[key]
if isinstance(weights, dict):
total_params = sum(v.numel() for v in weights.values() if isinstance(v, torch.Tensor))
print(f" 参数量: {total_params:,} ({total_params/1e6:.2f}M)")
print(f" 键数量: {len(weights)}")
print(f" 键名: {list(weights.keys())[:]}")
# 如果上面没找到,遍历所有键
print("\n" + "="*60)
print("检查所有键是否包含张量:")
print("="*60)
for key, value in model_data.items():
if isinstance(value, dict):
tensor_count = sum(1 for v in value.values() if isinstance(v, torch.Tensor))
if tensor_count > 0:
total_params = sum(v.numel() for v in value.values() if isinstance(v, torch.Tensor))
print(f" '{key}': 包含 {tensor_count} 个张量,总参数 {total_params:,}")
那么什么是键呢?
一个键 = 一个可学习参数张量(一个可调节的数字参数),而这个参数就是我们最后需要得到的东西
就是我输入特定格式的东西,根据他神经网络的结构加上这些参数各种计算,最后得出特定格式输出
所以说 data.pkl 是整体结构(结构 + 键名 + 地址索引)
data文件夹里面就是具体的数值
TorchScript
这东西也是一个用来部署的一个pt,他本质上是PyTorch 的编译版本
他的推理是比正常的pytorch要快的,也可以支持cpp推理,但是比onnx还是差一些
主要还是和PyTorch 生态绑定的
这是解压缩后的
code文件夹
存储 TorchScript 编译后的计算图代码
包含了模型的静态计算图表示
计算图可以理解为提前把整个网络的结构写好,这样用的时候就不用一行行解析python代码了,所以也实现了跨语言,速度也更快,当然,快不过onnx
其他
|
serialization_id |
TorchScript 特有的序列化标识符 |
|
constants.pkl |
存储常量数据(如形状、配置) |
|
data.pkl |
主数据文件(元数据、结构信息) |
|
byteorder |
字节序信息(大端/小端) |
|
version |
格式版本号 |
特点就是
- 计算图编译优化
- 在 C++ 环境中加载
- 不包含优化器状态(无法继续训练)
- 结构固定(无法修改网络)
onnx
他是Protobuf 二进制
结构
ONNX 模型 = 计算图 (Computational Graph)
计算图包含 4 大部分:
┌─────────────────────────────────────────────────
│ 1️⃣ 输入 (Inputs)
│ 比如:270 维传感器数据
├─────────────────────────────────────────────────
│ 2️⃣ 输出 (Outputs)
│ 比如:12 维关节控制命令
├─────────────────────────────────────────────────
│ 3️⃣ 节点 (Nodes) - 计算步骤
│ 比如:矩阵乘法、激活函数、加法...
├─────────────────────────────────────────────────
│ 4️⃣ 初始化器 (Initializers) - 参数值
│ 比如:30 个键的具体数值 (weight/bias)
└─────────────────────────────────────────────────pt是框架和具体数值是分开的,onnx是混在一起的
还是以HIMLoco的为例子,代码
import onnx
# 加载模型
model = onnx.load('/home/extra/zhy/桌面/IsaacGym_Preview_4_Package/HIMLoco-main/himloco_gym/logs/rough_go1/good/model_10000.onnx')
# 查看基本信息
print("="*60)
print(f"模型版本:{model.opset_import[0].version}")
print(f"生产者:{model.producer_name}")
print("="*60)
# 查看输入
print("\n📥 输入:")
for inp in model.graph.input:
shape = [d.dim_value for d in inp.type.tensor_type.shape.dim]
print(f" 名称:{inp.name}")
print(f" 形状:{shape}")
# 查看输出
print("\n📤 输出:")
for out in model.graph.output:
shape = [d.dim_value for d in out.type.tensor_type.shape.dim]
print(f" 名称:{out.name}")
print(f" 形状:{shape}")
# 查看节点 (计算步骤)
print("\n🔧 计算节点:")
print(f" 总节点数:{len(model.graph.node)}")
for i, node in enumerate(model.graph.node[:10]): # 只显示前 10 个
print(f" [{i}] {node.op_type}: {node.input} → {node.output}")
# 查看参数 (初始化器)
print("\n🎛️ 参数 (初始化器):")
print(f" 总参数数量:{len(model.graph.initializer)}")
total_params = 0
for init in model.graph.initializer:
shape = list(init.dims)
params = 1
for s in shape:
params *= s
total_params += params
print(f" - {init.name}: {shape} ({params:,} 参数)")
print(f"\n💾 总参数量:{total_params:,} ({total_params/1e6:.2f}M)")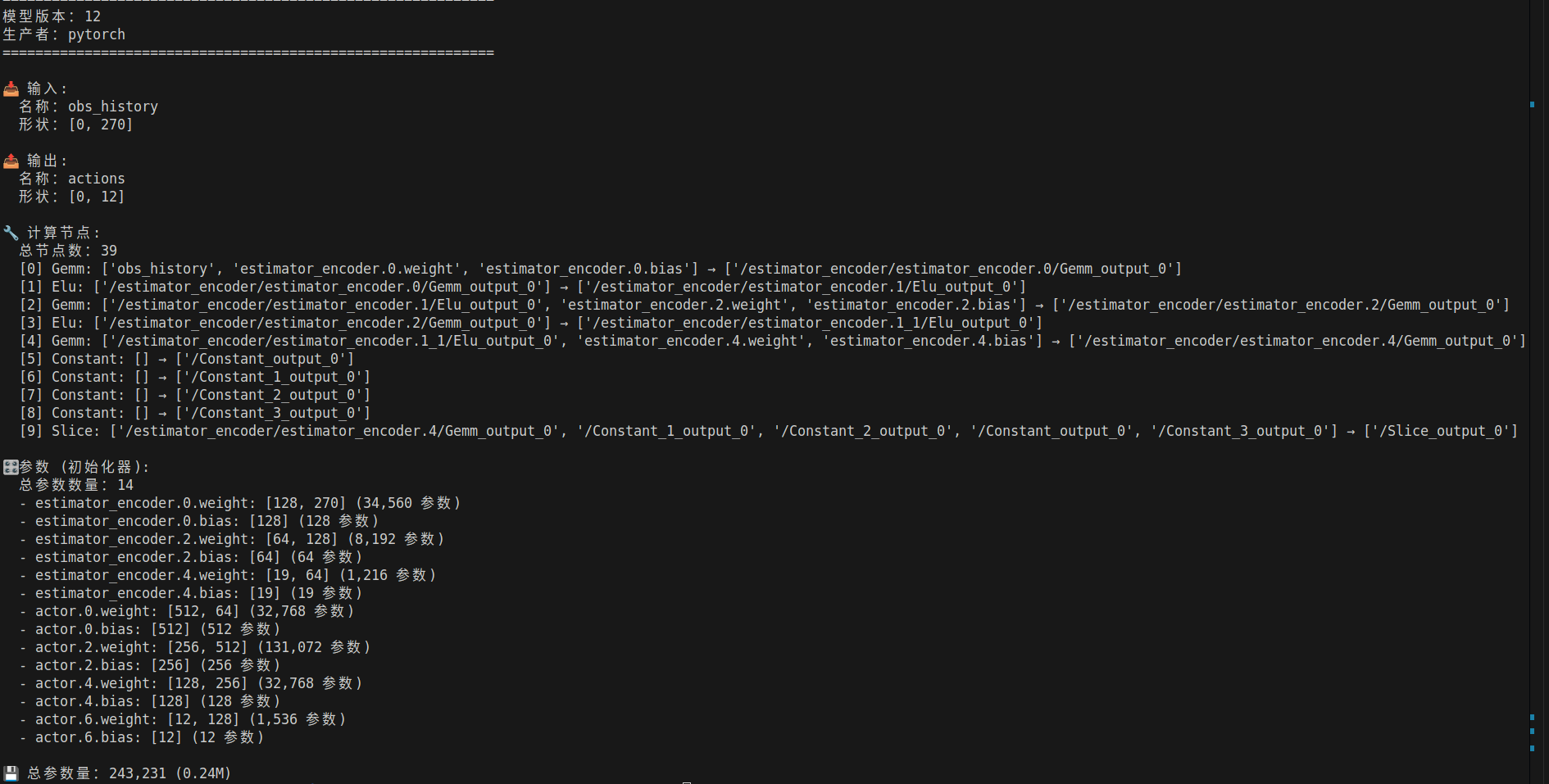
所以就很明确了
- 整个模型 = 一个计算图
- 每个节点 = 一个计算操作
- 初始化器 = pt的键值
- 输入,输出
关于键值
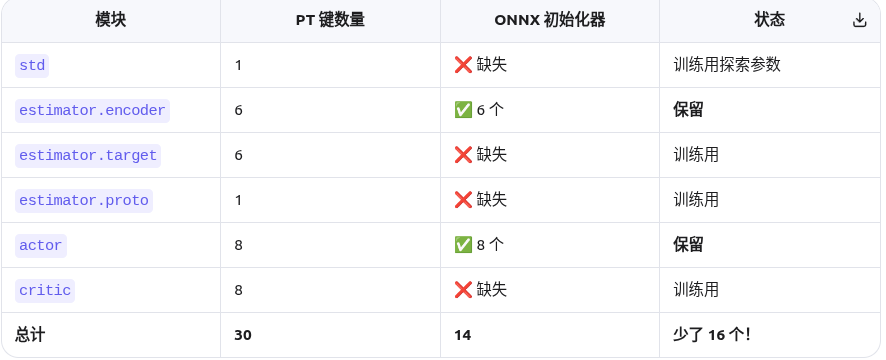
因为我这里onnx是纯推理,而且由于HIMLoco的框架设计,就导致实际的onnx中的初始化器个数比pt的键值少
所以这就是为啥 onnx 不能和 pt 一样继续训练的原因了
openvino
结构
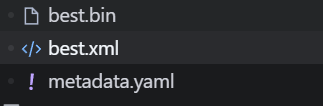
他的整个结构类似于onnx
这里我是用yolo的pt转成openvino的
- best.xm l就于是整个神经网络的计算图,也就是整个策略的结构
-
- 这里要注意的是,虽然这里叫计算图,但是他只负责静态拓扑和操作语义,权重被刻意剥离到独立的 best.bin 中
- best.bin 就是 权重的具体信息 也就是 data 文件夹里面的东西
- metadata.yaml 就是用来描述模型的辅助文件
-
- 记录导出时间、框架来源、量化方式、输入输出名称等,便于后续加载或调试
gguf
gguf就是很多本地大模型用的,比如ollama,LMstudio啥的
这里我以 gemma-3n-E4B-it-Q4_K_M.gguf 为例子分析//
from llama_cpp import Llama
# 你的 GGUF 文件路径
model_path = r"E:\ai\models\lmstudio-community\gemma-3n-E4B-it-text-GGUF\gemma-3n-E4B-it-Q4_K_M.gguf"
try:
# n_gpu_layers=0 表示纯 CPU 加载,只用来读信息,不推理
llm = Llama(
model_path=model_path,
n_gpu_layers=0, # 只读元数据,不加载权重到 GPU
verbose=False, # Ture的话会打印加载时的 GGUF 元数据
n_ctx=512, # 随便设小一点
load_format="gguf" # 强制 GGUF
)
# 加载成功后,llm.metadata 就是字典形式的元数据
print("\n" + "="*60)
print("GGUF 元数据(llama-cpp-python 解析):")
for key, value in sorted(llm.metadata.items()):
if isinstance(value, (list, tuple)) and len(value) > 10:
print(f" {key}: <list/tuple with {len(value)} items>")
else:
print(f" {key}: {value}")
print("\n模型基本信息:")
print(f" 架构: {llm.metadata.get('general.architecture', '未知')}")
print(f" 名字: {llm.metadata.get('general.name', '未知')}")
print(f" 量化类型: {llm.metadata.get('general.file_type', '未知')} (或从文件名推断 Q4_K_M)")
print(f" 上下文长度: {llm.metadata.get('llama.context_length', '未知')}")
except Exception as e:
print(f"加载失败: {e}")从名字开始,gemma-3n-E4B-it-Q4_K_M.gguf
gemma
- 模型家族:Google 的 Gemma 系列(开源轻量模型)。
- Gemma 是 Google DeepMind 推出的高效开源模型家族,继 Gemma 1、Gemma 2 之后,这是第 3 代变体。
3n
- 版本标识:Gemma 3n(Gemma 3 的 “n” 变体)。
- “n” 代表 nested / nested MatFormer 架构(Matryoshka-like Transformer),这是 Gemma 3n 的核心创新:支持动态提取子模型(比如从 8B 里切出 4B 或 2B 有效参数的子网络)。
- 它让模型在边缘设备上更灵活:可以根据硬件资源选择不同“深度/宽度”。
E4B
- Effective 4 Billion(有效参数量约 4B)。
- 虽然底层总参数可能接近 6.9B–8B,但通过 MatFormer + 共享 KV + 交替投影(AltUp)等技术,实际计算和内存开销相当于传统 4B 模型。
- 这是 Gemma 3n 系列最关键的卖点:把大模型能力塞进小内存。
it
- Instruct-Tuned(指令微调版)。
- 说明这个模型经过了指令跟随(instruction tuning)和对话优化,不是原始的 base 模型。
- 适合聊天、问答、工具调用、角色扮演等任务,输出更听话、更符合人类偏好。
Q4_K_M
- 量化类型:Q4_K_M(4-bit 量化 + K-means clustering + Medium 变体)。
- 这是 llama.cpp / GGUF 生态中最受欢迎的量化方案之一:
-
- Q4:4-bit 每权重
- K:使用 K-means 聚类优化量化误差
- M:中等质量/速度平衡(比 Q4_K_S 稍大但质量更好,比 Q5_K_M 小但更快)
- 实际效果:在 4-bit 下,性能损失很小(通常 perplexity 只涨 5–10%),但文件大小和内存占用减少 60–70%。
============================================================
GGUF 元数据(llama-cpp-python 解析):
# gemma3n.* 系列字段(Gemma 3n 专有架构参数)
gemma3n.altup.active_idx: 0 # AltUp机制的激活索引,用于模型中的自适应层上采样
gemma3n.altup.num_inputs: 4 # AltUp机制的输入数量
gemma3n.attention.head_count: 8 # 注意力头的数量,这里是8个头
gemma3n.attention.head_count_kv: 2 # Key-Value头的数量,使用GQA(Grouped Query Attention)
# 2个KV头对应8个查询头
gemma3n.attention.key_length: 256 # 注意力机制中Key向量的长度
gemma3n.attention.layer_norm_rms_epsilon: 0.000001
# RMSNorm(Root Mean Square Normalization)的 epsilon 值 = 1e-6。用于稳定 LayerNorm 计算,避免除零
gemma3n.attention.shared_kv_layers: 15.000000 # 共享KV的层数,跨层共享Key-Value缓存以节省内存
gemma3n.attention.sliding_window: 512 # 滑动窗口注意力的大小,限制每个token只能关注最近的512个token
gemma3n.attention.value_length: 256 # 注意力机制中Value向量的长度
gemma3n.block_count: 35 # Transformer块的总数,即模型有35层
gemma3n.context_length: 32768 # 最大上下文长度,可以处理32768个token
gemma3n.embedding_length: 2048 # 主嵌入向量的维度
gemma3n.embedding_length_per_layer_input: 256 # 每层输入的嵌入维度
gemma3n.feed_forward_length: 16384 # 前馈网络(FFN)的隐藏层维度
gemma3n.rope.freq_base: 1000000.000000 # RoPE(旋转位置编码)的频率基数
# general.* 系列字段(通用信息)
general.architecture: gemma3n # 模型架构类型,基于Google的Gemma 3n架构
general.basename: gg-hf-gm_gemma # 模型基础名称
general.file_type: 15 # GGUF文件类型编码,对应Q4_K_M量化
general.finetune: 3n-E4B-it # 微调版本信息,3n架构,4B参数,instruction-tuned
general.name: Gg Hf Gm_Gemma 3n E4B It # 模型完整名称
general.quantization_version: 2 # 量化版本号
general.size_label: 6.9B # 模型大小标签,约6.9B参数
general.type: model # 文件类型,这是一个模型文件
# 分词器信息
tokenizer.chat_template: {{ bos_token }}
# 对话模板,定义了如何格式化对话历史,支持:
# 系统消息处理
# 用户/助手角色交替检查
# 多模态内容(音频、图像、文本)
# BOS/EOS token插入
{%- if messages[0]['role'] == 'system' -%}
{%- if messages[0]['content'] is string -%}
{%- set first_user_prefix = messages[0]['content'] + '
' -%}
{%- else -%}
{%- set first_user_prefix = messages[0]['content'][0]['text'] + '
' -%}
{%- endif -%}
{%- set loop_messages = messages[1:] -%}
{%- else -%}
{%- set first_user_prefix = "" -%}
{%- set loop_messages = messages -%}
{%- endif -%}
{%- for message in loop_messages -%}
{%- if (message['role'] == 'user') != (loop.index0 % 2 == 0) -%}
{{ raise_exception("Conversation roles must alternate user/assistant/user/assistant/...") }}
{%- endif -%}
{%- if (message['role'] == 'assistant') -%}
{%- set role = "model" -%}
{%- else -%}
{%- set role = message['role'] -%}
{%- endif -%}
{{ '<start_of_turn>' + role + '
' + (first_user_prefix if loop.first else "") }}
{%- if message['content'] is string -%}
{{ message['content'] | trim }}
{%- elif message['content'] is iterable -%}
{%- for item in message['content'] -%}
{%- if item['type'] == 'audio' -%}
{{ '<audio_soft_token>' }}
{%- elif item['type'] == 'image' -%}
{{ '<image_soft_token>' }}
{%- elif item['type'] == 'text' -%}
{{ item['text'] | trim }}
{%- endif -%}
{%- endfor -%}
{%- else -%}
{{ raise_exception("Invalid content type") }}
{%- endif -%}
{{ '<end_of_turn>
' }}
{%- endfor -%}
{%- if add_generation_prompt -%}
{{'<start_of_turn>model
'}}
{%- endif -%}
tokenizer.ggml.add_bos_token: true # 是否在序列开始添加BOS token
tokenizer.ggml.add_eos_token: false # 是否在序列结束添加EOS token
tokenizer.ggml.add_sep_token: false # 是否添加分隔符token
tokenizer.ggml.add_space_prefix: false # 是否添加空格前缀
tokenizer.ggml.bos_token_id: 2 # Beginning of Sequence token的ID
tokenizer.ggml.eos_token_id: 1 # End of Sequence token的ID
tokenizer.ggml.model: llama # 使用的分词器模型类型
tokenizer.ggml.padding_token_id: 0 # Padding token的ID
tokenizer.ggml.pre: default # 预处理方式
tokenizer.ggml.unknown_token_id: 3 # Unknown token的ID
模型基本信息:
架构: gemma3n
名字: Gg Hf Gm_Gemma 3n E4B It
量化类型: 15 (或从文件名推断 Q4_K_M)
上下文长度: 未知生成流程
- 输入
- 阶段 1:前端 / 客户端预处理
-
- 分词(Tokenization) 使用模型自带的 tokenizer(SentencePiece 或类似 Llama 风格的分词器)把你的文字切成 token。 根据元数据:
-
-
- tokenizer.ggml.add_bos_token: true → 会在最前面自动加 BOS token(id=2)
- add_space_prefix: false → 不会在开头加空格
- chat_template 会把你的输入包装成对话格式(因为是 instruct 模型)
-
- 阶段 2:模型加载阶段(程序启动时一次性完成)
-
- GGUF 文件被 mmap(内存映射)加载到内存,几乎零拷贝,速度极快。
- 根据元数据:
-
-
- 35 层 Transformer block 被加载
- 所有权重(Q4_K_M 量化后的 6.9B 参数)被解码到内存
- KV Cache 预分配(根据上下文长度 32768,但实际只用你需要的部分)
- RoPE 基频设为 1,000,000,支持长序列
- 注意力机制使用 GQA(8 query heads 共享 2 kv heads)+ 滑动窗口 512 + 共享 KV 层 15 层
-
- 阶段 3:Prefill(预填充)阶段 —— 处理你的输入
-
- 模型一次性处理你全部的输入 token(包括 BOS、<start_of_turn>user ... <end_of_turn> <start_of_turn>model)
- 这是计算最密集的部分(所有层都要完整跑一遍)
- 输出:最后一个位置的隐藏状态(2048 维向量),以及所有历史 KV Cache(Key 和 Value 缓存)
关键优化点(Gemma 3n 专有):
-
- shared_kv_layers=15 → 中间 15 层的 KV 被复用,节省大量内存和计算
- sliding_window=512 → 超过 512 个 token 的历史注意力被截断,只保留最近 512 个,加速长对话
- altup / PLE → 每层输入嵌入使用低维缓存(256 维),进一步省内存
- 阶段 4:生成阶段(Autoregressive 自回归生成)
这是模型真正“写文章”的部分,一次生成一个 token,循环进行。
循环过程(重复 N 次,直到生成结束):
取上一步的输出 token(第一次是 prefill 最后的隐藏状态)
输入到下一层 Transformer
-
-
- 用 RoPE 编码当前位置(freq_base=1000000)
-
-
-
-
-
- 注意力计算:GQA + 滑动窗口 + KV 共享
- 前馈网络(16384 维中间层)
- RMSNorm(epsilon=1e-6)
-
-
-
得到 logits(词汇表大小的概率分布,通常 256000+ 个词汇)
采样下一个 token
-
-
- temperature(默认 0.7–1.0)
-
-
-
-
-
- top_p / top_k
- repetition_penalty
- mirostat / DRY 等高级采样
- 例如采样到 token id=1234(对应某个词)
-
-
-
把新 token 加到序列末尾,更新 KV Cache
重复 步骤 1–5,直到:
-
-
- 生成到 EOS token(id=1)
- 达到最大长度(max_tokens)
- 或手动停
-
- 阶段 5:后处理 & 输出
- 把生成的 token id 序列送回 tokenizer 解码成文字
- 去掉 <start_of_turn>model 等特殊标记
- 返回给用户:

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)