【MLLM】Agent-GUI之MobileAgent模型
note
- 提出了GUI-Owl-1.5,一个多平台的本地GUI代理模型,支持桌面、移动设备、浏览器等多种设备的自动化操作。通过Hybrid Data Flywheel、统一的代理能力增强和跨设备环境强化学习扩展,GUI-Owl-1.5在20多个GUI基准测试中取得了最先进的性能。开源发布GUI-Owl-1.5将推动GUI代理在多平台设备自动化中的应用。
- 在 browser 这类更长程、更需要规划的任务上,thinking 往往明显优于 instruct,但在有些 GUI/multi-platform benchmark 上,32B instruct 反而不差,甚至在某些工具调用任务上更强
- MRPO = 用一个带设备条件的统一 policy,在 mobile/desktop/web 上做 GUI agent RL;为了解决 GRPO 组塌缩,就先多采样再选组;为了解决训练/推理动作不一致,就把推理 token id 原样带回训练;为了解决多平台梯度冲突,就按平台交替训练。
文章目录
- note
- 一、研究背景
- 二、GUI-Owl-1.5
- 三、模型训练
- 四、实验设计
- 五、结果与分析
- 六、论文评价
- 七、相关问题
- Reference
一、研究背景
- 研究问题:这篇文章要解决的问题是如何开发一个多平台的本地GUI代理模型,以支持桌面、移动设备、浏览器等多种设备的自动化操作。
- 研究难点:该问题的研究难点包括:现实世界数据收集的效率低、多平台适应性强以及综合代理能力的全面性。
- 相关工作:该问题的研究相关工作包括基于端到端学习的本地代理模型的发展,如Ye等人(2025)和Qin等人(2025)的工作。然而,这些模型在处理复杂任务和高规模数据集时仍面临挑战。
二、GUI-Owl-1.5
这篇论文提出了GUI-Owl-1.5,用于解决多平台GUI自动化的问题。GUI-Owl-1.5模型的交互流程,参考如下的system prompt,system message 定义可用 action space,user message 放任务指令 + 压缩历史 + 当前观察,response message 放 reasoning、action summaries 和 final action output。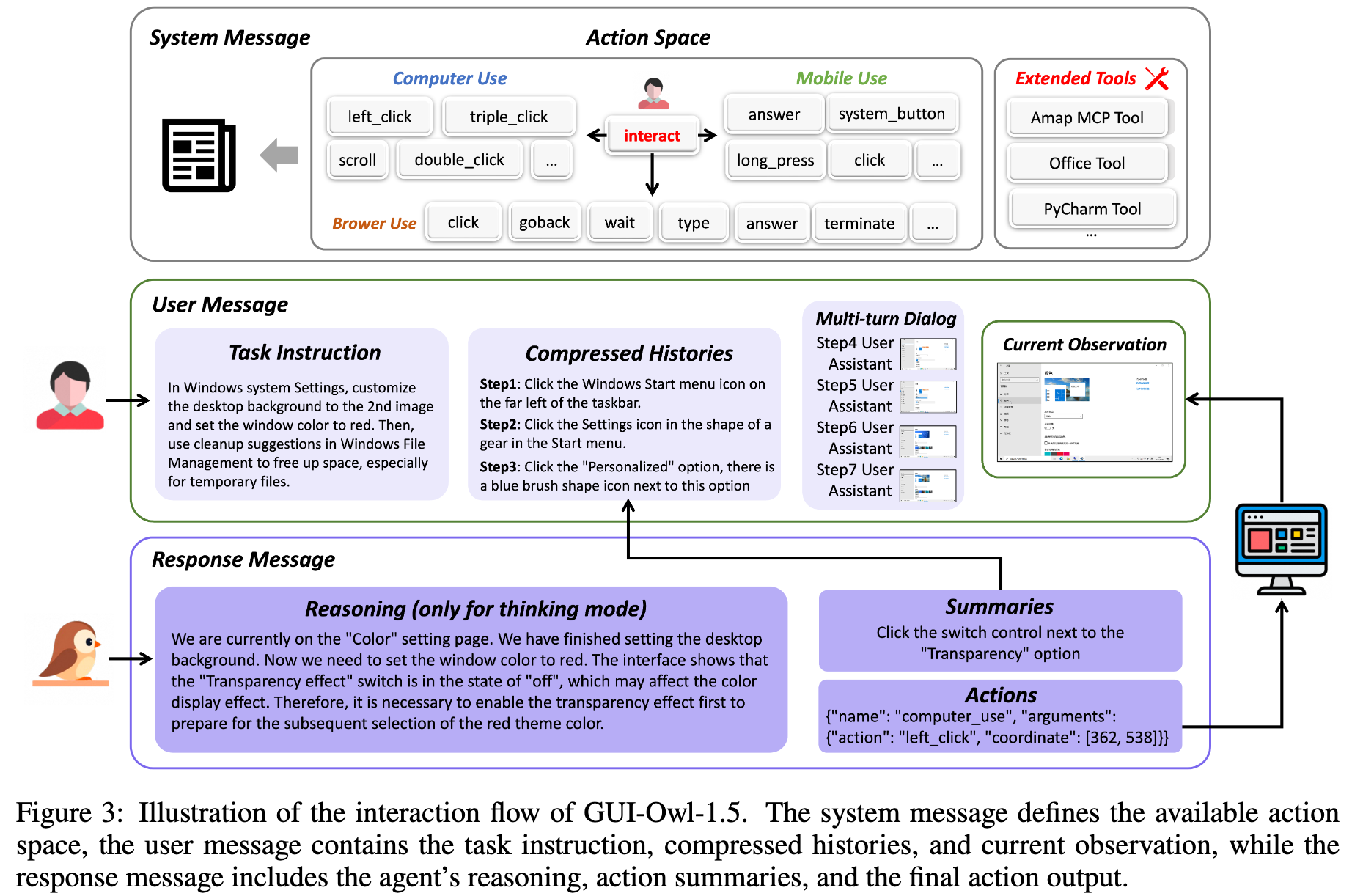
1、Hybrid Data Flywheel
Hybrid Data Flywheel:首先,作者构建了一个基于模拟环境和云端沙盒环境的UI理解和轨迹生成数据管道,以提高数据收集的效率和准确性。对于定位任务,开发了一个全面的定位数据增强管道,包括高分辨率场景的多窗口合成和轨迹挖掘。
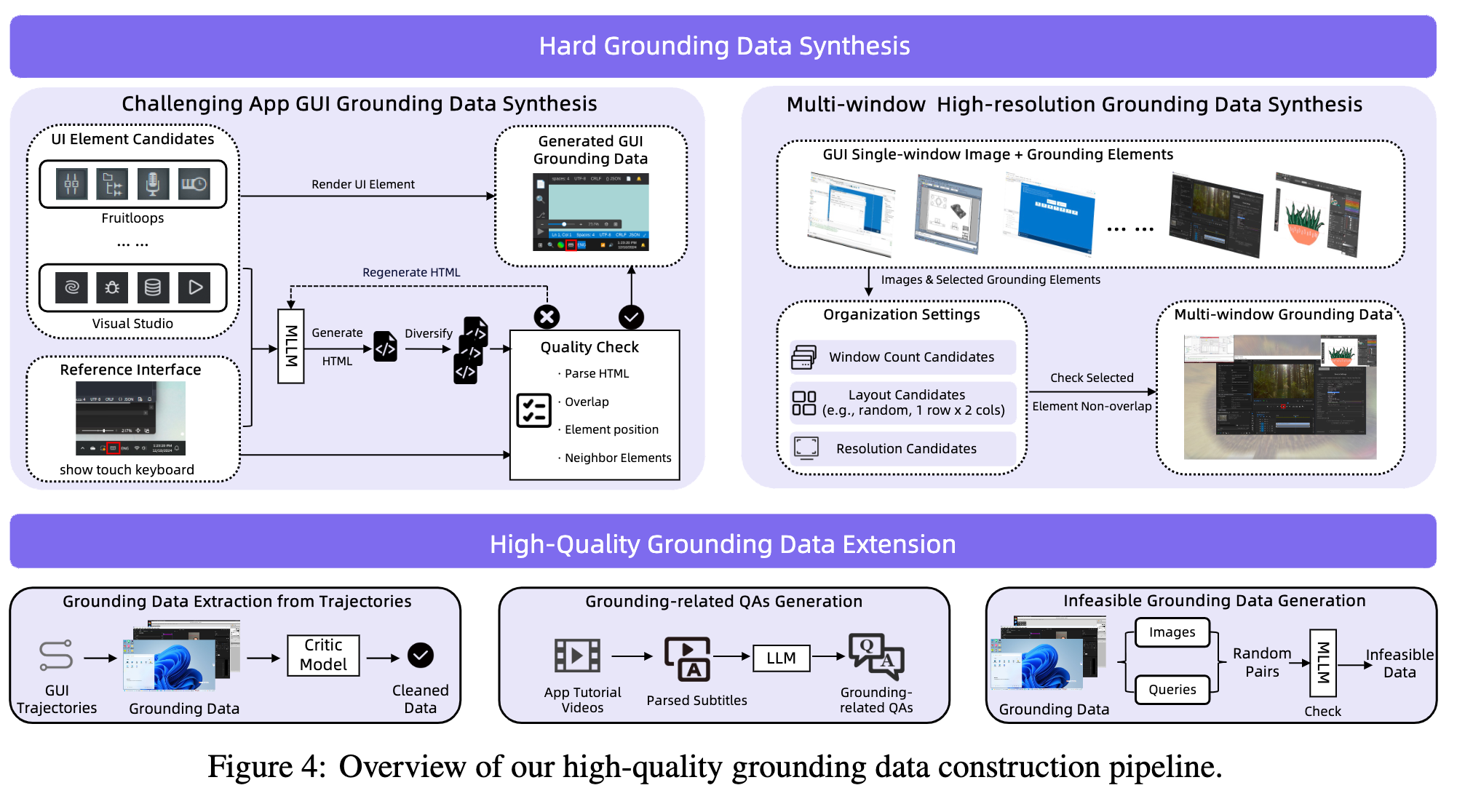
A. Grounding 数据
为了让模型会“在屏幕上定位元素”,他们构造了很多高质量 grounding 数据,包括:
- 挑战性专业软件 GUI 合成
- 多窗口高分辨率场景合成
- 从已有轨迹里挖 grounding 数据
- 从教程/字幕里抽 grounding QA
- 生成 infeasible grounding negative samples(不可行负例)
GUI grounding 最大问题就是:
高难样本太少、负例太弱、分辨率和布局复杂度不够。
B. Trajectory 数据
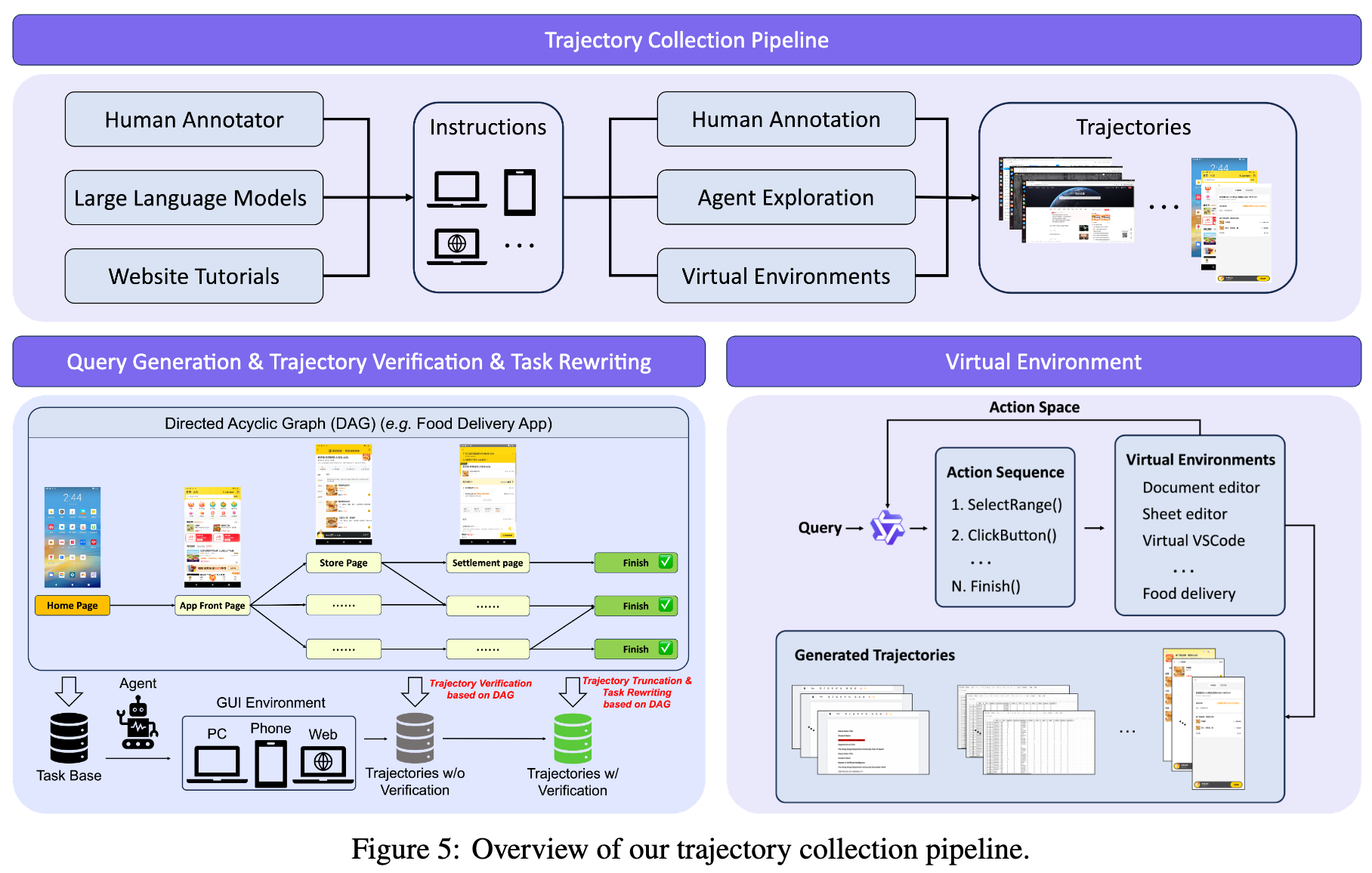
轨迹数据这块,他们用了一个 DAG-based task synthesis:
- 人先写应用域 DAG
- 从起点到终点采样路径
- 拼成 realistic multi-step task
- agent 在真实环境或虚拟环境里 rollout
- 用 checkpoint predicate 验证子任务完成情况
- 只保留正确 prefix,避免脏监督
2、Unified Enhancement of Agent Capabilities
Unified Enhancement of Agent Capabilities:其次,作者引入了几种策略来全面提升代理能力,包括通过大规模问答数据爬取和模型监督进行GUI知识注入、设计统一的思维链(CoT)合成管道以增强轨迹数据的推理能力,以及通过Mobile-Agent-v3.5框架收集的多代理协作数据。
- GUI Knowledge Injection:从官方文档、教程、论坛、网页导航数据里爬 GUI 知识,改写成 QA/VQA 数据。
- world modeling:给定当前截图 + 动作,训练模型预测下一状态变化描述,让模型学会“动作会导致什么界面变化”。
- Unified CoT Synthesis:把观察、反思、记忆、工具选择写进每一步对每个轨迹 step 合成结构化思维信息:
- 先用 VLM 做屏幕描述与关键信息抽取
- 再判定动作结果是否符合预期,生成反思与纠错信号
- 同步生成记忆条目(比如价格、天气、账号信息)
- 若涉及工具调用,把工具定义纳入推理,合成“为何选这个工具”的 reasoning
3、Multi-platform Environment RL Scaling
Multi-platform Environment RL Scaling:此外,作者提出了一个新的环境强化学习算法MRPO(Multi-platform Reinforcement Policy Optimization),以应对多平台冲突和长期任务的训练效率低的问题。该算法通过统一学习、在线回滚缓冲、令牌ID传输和交替多平台优化来解决这些问题。
要解决的四个问题:
| 问题 | 通俗理解 |
|---|---|
| 1. 多平台统一 policy | 一个模型怎么同时学手机、电脑、网页 |
| 2. GRPO rollout collapse | 一组采样结果全一样,没法学 |
| 3. 训练和执行的 token 不一致 | 环境里执行的是一种 token 切法,训练时算 logprob 是另一种切法 |
| 4. 多平台梯度打架 | 手机任务想把模型往 A 方向拉,网页任务又往 B 方向拉 |
相关做法:
| 模块 | 它解决的问题 | 核心做法 |
|---|---|---|
| Unified policy | 一个模型怎么同时覆盖 mobile/desktop/web | 在 policy 里显式加入 device 条件 |
| Online rollout buffer | GRPO 一组 rollout 全成/全败,学不到 | 先多采样,再挑出有成败差异的一组 |
| Token-id transport | 环境执行动作与训练算 logprob 的 token 不一致 | 把推理时真实 token id 一起传回训练端 |
| Alternating optimization | 多平台混训梯度互相打架(训练时,模型参数更新方向来自 batch 里的样本梯度和。如果两类数据希望参数朝相近方向更新,那混训很好,互相增强。但如果两类数据希望参数朝相反方向更新,就会冲突。) | 按 device family 分阶段交替训练 |
(1)Multi-device RL with a unified policy
论文想做的是:不要手机一个模型、桌面一个模型、浏览器一个模型,而是尽量训练一个统一 policy。
形式上就是:
- device family
d ∈ {mobile, desktop, web} - policy 变成:
πθ(a | o, d)
意思是:
o是当前观察,比如截图、任务描述、历史动作d是设备类型a是当前动作
直观理解
同样一个任务“打开设置”,在不同平台上完全不一样:
- 手机:点 App,再点设置页
- 桌面:菜单栏、窗口、弹窗
- 网页:页面按钮、标签页
如果不告诉模型“我现在在哪个平台”,模型会很混乱。所以他们加了一个 device-conditioned policy:同一个模型参数共享,但显式告诉模型当前设备类型。
为什么不用 3 个完全独立模型
因为还是有很多共性能力可以共享:
- 看懂 GUI
- 理解用户任务
- 多步规划
- 知道什么时候调用工具
- 知道什么时候该输入文本
所以这一步其实是在做:共享通用 agent 能力 + 保留设备条件差异。
(2)Online rollout buffer for GRPO under outcome collapse
先说什么叫 rollout collapse
GRPO 一般会对同一个任务采样一组 rollout,比如 4 条、8 条:
- 第 1 条轨迹:失败
- 第 2 条轨迹:失败
- 第 3 条轨迹:失败
- 第 4 条轨迹:失败
或者全成功。
这种情况下,这一组样本就没什么“相对比较信息”了。
因为组内没有差异,优势函数/相对排序几乎学不到东西。这就叫 group collapse。
在 GUI agent 里为什么更容易 collapse
因为 GUI 任务经常出现两种极端:
- 模型太弱:这类任务一组 rollout 全挂
- 模型太强:简单任务一组 rollout 全成
结果就是:**同一个任务采出来的一组轨迹,经常全 0 或全 1。**这对 GRPO 很不友好。
他们怎么解决
不是像传统 replay buffer 那样混很多旧样本,因为那样会带来 off-policy 偏差。他们的方法是:
第一步:先多采样
原本每个任务你想采 n 条轨迹。
他们改成先采 k*n 条,比如:
- 原本要 4 条
- 现在先采 12 条
这些都还是 当前 policy 现采的,所以仍然是 on-policy。
第二步:再从这 k*n 条里挑 n 条做训练组
如果随机挑出来的这 n 条还是全成功或全失败,就做一点小修正:
- 从大池子里找一条结果相反的轨迹
- 替换进来一条
- 让这一组里至少有成功也有失败
这样就能构造出“有区分度”的 group。
为什么这比 replay buffer 更好
因为 replay buffer 里常混入旧 policy 生成的轨迹,会有 off-policy 问题。
而这里所有候选轨迹都来自 当前 policy,只是:**先多采,再从里面挑一个不塌缩的小组。**所以本质上还是尽量保持 on-policy,只是提高了组内多样性。
通俗类比
你要训练一个学生判断“哪种做法更好”,结果你给他的 4 个例子全都错,或者全都对,那他很难比较。更好的方式是:
- 先准备 12 个例子
- 从里面挑 4 个,有对有错
- 这样他才能学到“为什么这个好、那个差”
这就是 online rollout buffer 在干的事。
(3)token-id transport
这是最工程、但也最关键的一点。
1. 问题是什么
环境侧执行动作时,模型输出的是文本形式动作,比如:
click(“设置”)type("hello")call_tool({...})
但问题在于:训练端和推理端,对同一个文本的 token 切分不一定完全一样。
比如同一句字符串:
- 推理服务 tokenizer 切成 A B C
- 训练服务 tokenizer 切成 A BC
- 或者 special token、空格、标点切法有差异
这样就会导致一个严重问题:
环境真正执行的那个 action,和训练时拿来算 logprob 的 action,不再是同一个离散事件。
而 policy gradient / KL regularization 默认假设:
训练时算概率的那个动作,就是 rollout 时实际采样执行的动作
如果不一致,梯度就会歪。
2. 他们怎么修
环境在返回文本动作 y 的同时,不只返回文本,还返回:
t_infer = (t1, t2, ..., tL)
也就是:
推理时真正采样出来的原始 token id 序列
训练时不再自己对文本 y 重新 tokenize,而是直接用这组 token id 去算:
- 这些 token 在当前模型下的 logprob
这样就保证:
训练时计算的 logprob,和环境里实际执行的那串 token 完全一致。
3. 为什么这么重要
因为 GUI agent 里动作经常是结构化文本:
- 坐标
- 工具参数
- 序列化 action
- 输入字符串
这些东西一旦 tokenizer 切法不一致,就会出现:
- rollout 执行的是动作 A
- 训练优化的却像是在优化动作 B
这会直接破坏:
- policy gradient
- KL 惩罚
- advantage 对齐
所以 token-id transport 的本质是:
把“训练时优化的动作”和“环境里执行的动作”严格绑定成同一个东西。
(4)Alternating multi-device optimization
可以理解成:多平台混训时,梯度会打架。
为什么会打架
手机、桌面、网页虽然都叫 GUI,但差异很大:
- action 空间不同
- UI 布局不同
- 交互习惯不同
- 任务先验不同
比如:
- 手机里“返回”是高频操作
- 网页里“切 tab / 滚动 / 表单提交”更常见
- 桌面里还有窗口、多任务、文件系统交互
如果你把这些数据全混在一个 batch 里一起训,常会出现:
- 来自 mobile 的梯度想让模型更偏向手机风格
- 来自 web 的梯度又把它往网页风格拉
于是就形成 tug-of-war。
他们的做法
不是完全混着训,而是:按 stage 交替训练不同 device family。比如:
- 这一阶段主要训 mobile
- 下一阶段训 desktop
- 再下一阶段训 web
- 再循环回来
这样做的好处是:
- 每个阶段梯度更一致
- 减少不同平台直接在同一 batch 里互相冲突
- 但 backbone 还是共享的,所以跨平台泛化还在
三、模型训练
训练分三阶段:
1)Pre-training:除了基础 UI recognition / trajectory,还加入:
QA / VQA GUI knowledge
world-modeling data
tool invocation data
2)SFT:用多平台轨迹 + CoT + grounding + tool/MCP + browser data 做对齐。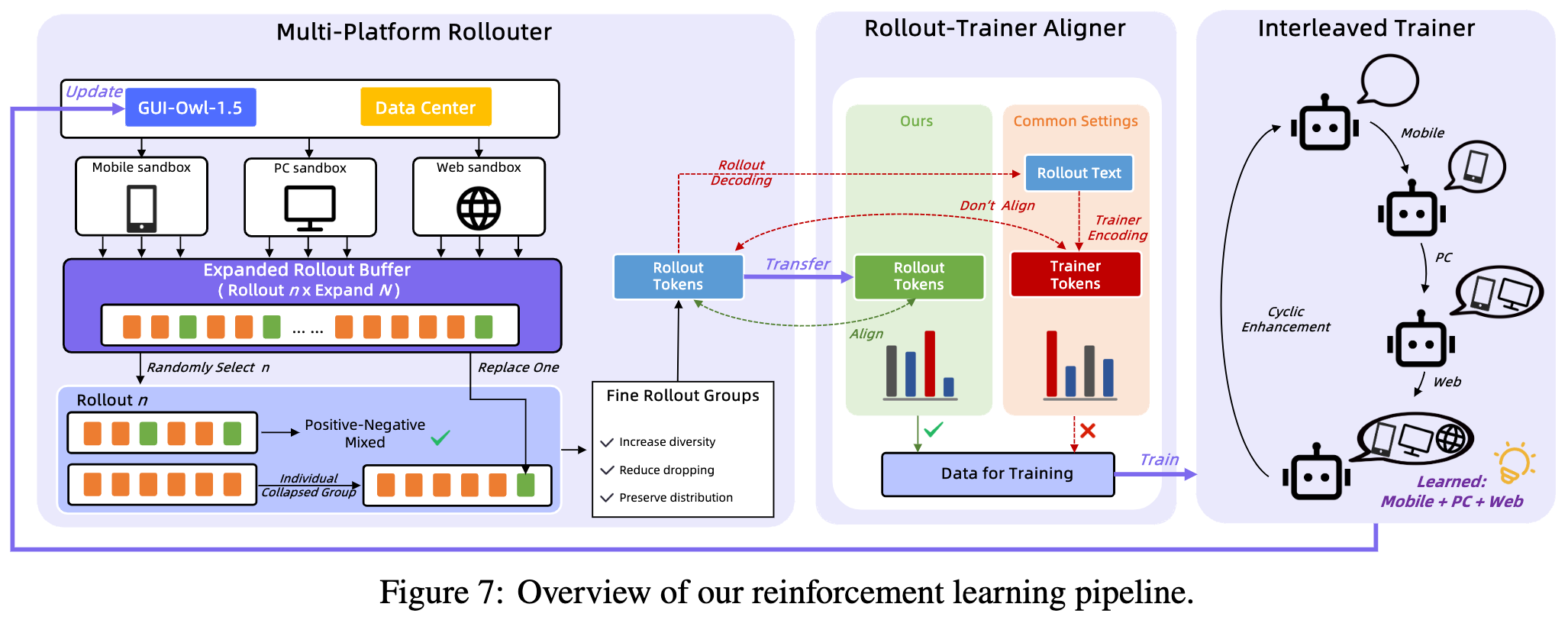
3)RL:最后用 MRPO 做大规模多平台长程 GUI control 的强化学习。
四、实验设计
数据收集:构建了一个混合轨迹语料库,涵盖多样化的应用和设备,同时保持高监督保真度。数据收集包括基于有向无环图(DAG)的任务合成、真实设备上的自动化回滚、人类演示和虚拟环境中的轨迹生成。
实验设置:评估GUI-Owl-1.5在多个基准测试中的性能,包括GUI任务自动化、定位、工具调用、记忆和知识任务。实验在移动使用、计算机使用和浏览器使用等领域进行。
样本选择:选择了多个代表性的版本进行评估,包括GUI-Owl-1.5-2B-Instruct、GUI-Owl-1.5-4B-Instruct、GUI-Owl-1.5-8B-Instruct、GUI-Owl-1.5-8B-Thinking、GUI-Owl-1.5-32B-Instruct和GUI-Owl-1.5-32B-Thinking。
参数配置:模型训练分为预训练、监督微调和强化学习三个阶段,每个阶段的数据多样性和任务覆盖范围都有所扩展。
五、结果与分析
端到端和多代理能力:在移动使用和计算机使用基准测试中,GUI-Owl-1.5取得了最先进的性能。例如,在OSWorld-Verified基准上,8B-Thinking模型取得了52.9的准确率,超过了所有通用模型。
定位能力:在ScreenSpot Pro基准上,32B-Instruct模型取得了72.9的准确率,超过了所有现有GUI代理模型,包括单平台、多平台和定位专用模型。使用两阶段细化策略后,准确率提高到80.3。
综合GUI理解:在GUI知识基准上,32B-Instruct模型取得了75.45的整体准确率,在所有评估模型中表现最佳,特别是在小部件功能理解和动作参数预测方面表现突出。
内存能力:在MemGUI-Bench基准上,32B模型取得了27.1的准确率,显著优于所有现有基线模型,证明了训练配方有效植入了长期内存能力。
六、论文评价
1、优点与创新
Hybrid Data Flywheel: 通过结合模拟环境和云端沙箱环境,构建了UI理解和轨迹生成的数据管道,提高了数据收集的效率和质量。
Unified Enhancement of Agent Capabilities: 使用统一的思维综合管道来增强模型的推理能力,特别强调了工具/MCP使用、内存和多智能体适应等关键能力的提升。
Multi-platform Environment RL Scaling: 提出了MRPO(多平台强化策略优化)算法,解决了多平台冲突和长期任务训练效率低的问题。
开源模型: GUI-Owl-1.5模型开源,并提供了在线云沙盒演示。
多平台支持: 支持桌面、移动、浏览器等多种设备,能够进行复杂的代理实时交互,如边缘-云协作和多设备协调。
全面的代理能力: 不仅限于GUI操作,还支持工具/模型上下文协议(MCP)调用、短期和长期记忆、多智能体适应和人机交互。
创新的数据增强框架: 通过挑战性应用GUI合成和多窗口高分辨率场景生成高质量数据,并通过轨迹挖掘、教程知识提取和不可行查询生成扩展高质量数据。
2、不足与反思
数据收集的复杂性: 实际世界数据收集的效率低下,大规模轨迹的收集成本高,阻碍了GUI数据集的可扩展性。
多平台适应的挑战: 本地主模型需要在广泛的设备上可靠地执行自动化任务,并支持复杂的代理实时交互,如边缘-云协作和多设备协调。
综合代理能力的挑战: 通用GUI代理应能够高效地完成任务,不仅限于GUI操作,还应支持工具/模型上下文协议(MCP)调用、短期和长期记忆、多智能体适应和人机交互。
七、相关问题
1、GUI-Owl-1.5在数据收集和增强方面有哪些创新?
- Hybrid Data Flywheel:构建了一个基于模拟环境和云端沙盒环境的UI理解和轨迹生成数据管道。通过结合这两种环境,提高了数据收集的效率和准确性。对于定位任务,开发了一个全面的定位数据增强管道,包括高分辨率场景的多窗口合成和轨迹挖掘。
- 多窗口高分辨率场景合成:利用现有的单窗口数据集和候选组织池,生成复杂的多窗口场景,同时确保目标UI元素不被遮挡。
- 轨迹挖掘和教程知识提取:从现有的PC和移动模拟环境轨迹中挖掘定位注释,通过批评模型过滤和验证数据质量,确保只保留高保真度的定位对。解析应用程序教程以提取与定位相关的问答知识,最终生成全面的定位导向问答对。
- 不可行查询生成:通过策略性随机配对查询和界面元素,生成大规模负样本,然后通过多模型共识过滤识别和验证真正不可行的定位实例。
2、GUI-Owl-1.5如何提升代理的多平台适应性和综合代理能力?
GUI知识注入:通过大规模问答数据爬取和模型监督进行GUI知识注入。爬取的数据包括软件文档和论坛中的问答数据,训练模型以预测界面状态转换。
统一的思维链(CoT)合成管道:设计了一个统一的思维链合成管道,将步骤观察、反思、记忆管理和工具调用推理增强到所有轨迹数据中,使模型能够在长距离规划和上下文信息保留方面表现出色。
多代理协作数据:通过Mobile-Agent-v3.5框架收集的多代理协作数据,使模型不仅能够作为独立的端到端代理运行,还能在结构化的多代理系统中担任专门角色(如规划器、执行器、验证器)。
3、MRPO算法如何解决多平台环境下的强化学习训练问题?
统一学习:在单一设备条件下优化单个策略,覆盖移动、桌面和Web环境。
在线回滚缓冲:引入在线回滚缓冲,通过过度采样轨迹和在保持策略一致性的情况下选择性采样多样化组来缓解分组回滚导致的不稳定性。
令牌ID传输:通过令牌ID传输确保环境端推理和训练端优化之间的日志概率一致性,防止由于分词不匹配导致的KL正则化和策略梯度估计问题。
交替多平台优化:采用交替多平台优化策略,在单个设备类型上循环训练,而不是混合轨迹,从而减少梯度干扰并提高训练的稳定性,同时保持跨设备泛化能力。
Reference
[1] https://github.com/X-PLUG/MobileAgent
[2] 阿里巴巴通义实验室开源 Mobile-Agent-v3.5:一套真正“多平台可用”的原生 GUI Agent 基座模型

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)