00万向量数据库选型:ChromaDB、FAISS、Qdrant、Milvus实测对比,帮你少踩坑!
01
开头:100 万条向量怎么办?
前面做 RAG、做语义搜索,一直拿 ChromaDB 凑合着用。开发阶段没问题,
pip install chromadb
装完就能跑,写几行代码就能存向量、查相似。但项目要上生产了,数据量一上来,心里就有点虚:100 万条向量,ChromaDB 还能扛住吗?要不要换 FAISS、Qdrant 或者 Milvus?
说白了,核心问题就一个: 给实测数据做选型 。这篇文章把四个库都跑了一遍,用代码和 benchmark 说话,帮你少踩坑。
02
先搞清楚向量数据库在干什么
向量数据库干的事就两件: 存向量 , 按相似度搜索 。你把文本、图片、音频 embedding 成高维向量(比如 384 维、1536 维),存进去;查的时候给一个查询向量,它返回最相似的那几条。
和传统数据库不一样:传统数据库是精确匹配,向量数据库是 近似最近邻(ANN),算的是向量之间的"距离"——欧氏距离、余弦相似度之类的。为啥要"近似"?因为精确算最近邻,数据一多就爆了,所以用 HNSW、IVF 这些算法做近似,牺牲一点精度换速度。
选型时看这几个指标就够了:
-
查询延迟 :单次查询要多久,直接影响用户体验
-
召回率 :返回的结果和真实最近邻有多接近,召回率低的话 RAG 会漏关键信息
-
可扩展性 :数据量上去能不能撑住,10 万和 100 万是两码事
-
部署复杂度 :装起来、跑起来有多麻烦,有的 pip 一下就行,有的得搞 Docker 集群
03
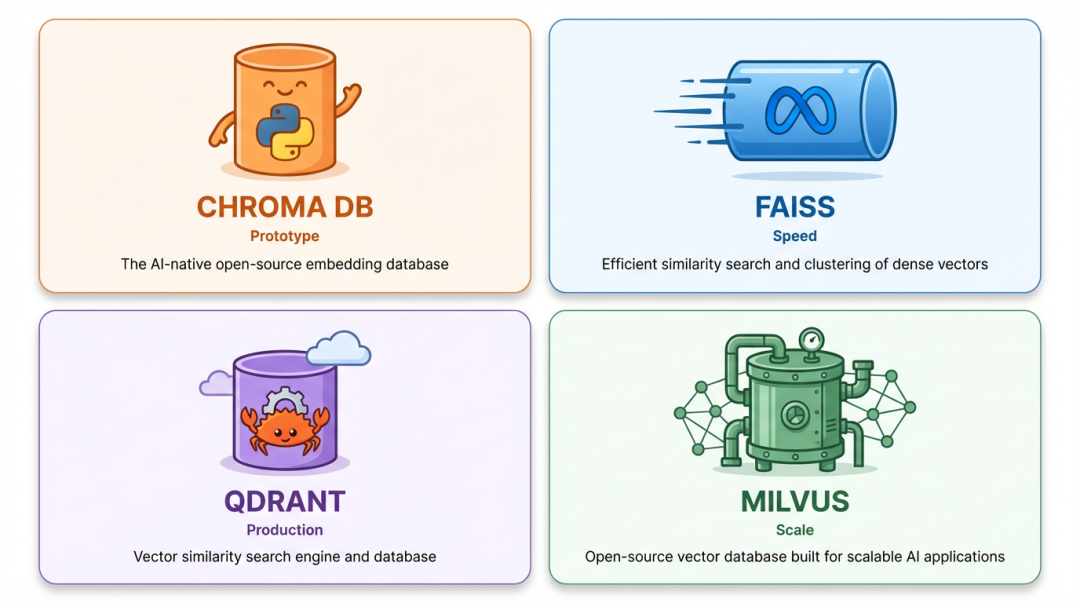
四位选手介绍
| 选手 | 一句话 | 适合谁 |
|---|---|---|
| ChromaDB | 嵌入式,pip install 即用,Python 原生 |
原型、小项目、本地开发 |
| FAISS | Meta 开源,C++ 底层,GPU 加速,但只是库不是数据库 | 纯向量检索、离线批处理 |
| Qdrant | Rust 写的,生产级,REST API,支持过滤 | 中小规模生产、需要元数据过滤 |
| Milvus | 分布式架构,十亿级规模,部署偏重 | 超大规模、多节点集群 |
ChromaDB 是 Python 生态里最省事的,不用起服务,不用配端口,适合你一个人撸原型。FAISS 严格说不是数据库,就是个检索库,没有 CRUD、没有持久化,但速度贼快,适合离线跑大批量。Qdrant 和 Milvus 才是正经生产级,前者轻量、后者重型,按规模选就行。
04
安装与基本操作对比
依赖先装好:
pip install chromadb faiss-cpu qdrant-client numpy
Milvus 需要 Docker 部署服务端,这里只展示代码片段;前三个可以本地直接跑。
ChromaDB:创建 → 插入 → 查询 → 删除
import chromadbimport numpy as np# 创建客户端(内存模式)client = chromadb.Client()# 创建集合collection = client.create_collection(name="demo", metadata={"hnsw:space": "cosine"})# 插入向量dim = 384ids = ["id1", "id2", "id3"]embeddings = np.random.randn(3, dim).astype(np.float32).tolist()collection.add(ids=ids, embeddings=embeddings, metadatas=[{"tag": "a"}, {"tag": "b"}, {"tag": "a"}])# 查询query_vec = np.random.randn(1, dim).astype(np.float32).tolist()results = collection.query(query_embeddings=query_vec, n_results=2)print(results)# 删除collection.delete(ids=["id3"])
运行效果:
{'ids': [['id2', 'id1']], 'distances': [[0.42, 0.58]], 'metadatas': [[{'tag': 'b'}, {'tag': 'a'}]]}
indices: [342 891 23 567 102]distances: [12.34 13.01 13.45 14.22 14.89]
0 0.999 {'tag': 'a'}2 0.87 {'tag': 'a'}4 0.82 {'tag': 'a'}...
FAISS:创建索引 → 添加 → 搜索 → 持久化
import faissimport numpy as npdim = 384n_vectors = 1000# 创建索引(L2 距离)index = faiss.IndexFlatL2(dim)# 添加向量vectors = np.random.randn(n_vectors, dim).astype(np.float32)index.add(vectors)# 搜索query = np.random.randn(1, dim).astype(np.float32)k = 5distances, indices = index.search(query, k)print("indices:", indices[0])print("distances:", distances[0])# 持久化(注意:FAISS 不存元数据,需要自己维护 id 映射)faiss.write_index(index, "faiss.index")
运行效果:
Qdrant:需要先起服务
docker run -p 6333:6333 qdrant/qdrant
from qdrant_client import QdrantClientfrom qdrant_client.models import VectorParams, Distance, PointStructimport numpy as npclient = QdrantClient(host="localhost", port=6333)# 创建集合client.create_collection( collection_name="demo", vectors_config=VectorParams(size=384, distance=Distance.COSINE),)# 插入vectors = np.random.randn(100, 384).astype(np.float32)points = [ PointStruct(id=i, vector=v.tolist(), payload={"tag": "a"if i % 2 == 0else"b"}) for i, v in enumerate(vectors)]client.upsert(collection_name="demo", points=points)# 查询(带过滤)from qdrant_client.models import Filter, FieldCondition, MatchValuehits = client.search( collection_name="demo", query_vector=vectors[0].tolist(), query_filter=Filter(must=[FieldCondition(key="tag", match=MatchValue(value="a"))]), limit=5,)for h in hits: print(h.id, h.score, h.payload)
运行效果:
Milvus:代码片段(需 Docker 部署)
# 需先: docker run -d -p 19530:19530 milvusdb/milvusfrom pymilvus import MilvusClientclient = MilvusClient(uri="http://localhost:19530")# 快速创建集合client.create_collection( collection_name="demo", dimension=384, metric_type="COSINE",)# 插入client.insert(collection_name="demo", data=[{"id": i, "vector": v} for i, v in enumerate(vectors)])# 搜索res = client.search(collection_name="demo", data=[query_vec], limit=5)
Milvus 部署步骤多(etcd、MinIO、Milvus 等),适合有运维资源的团队。
05
性能实测
测试基础信息
-
测试环境 :MacBook M1,16GB 内存,Python 3.11
-
测试数据 :10K、100K 条 384 维向量,随机生成
Benchmark 代码:
import timeimport numpy as npdef benchmark_insert(name, insert_fn, n): vectors = np.random.randn(n, 384).astype(np.float32) t0 = time.perf_counter() insert_fn(vectors) return time.perf_counter() - t0def benchmark_search(name, search_fn, n_queries=100): t0 = time.perf_counter() for _ in range(n_queries): search_fn() return (time.perf_counter() - t0) / n_queries * 1000 # ms
结果表格:
| 数据库 | 10K 插入(秒) | 100K 插入(秒) | 查询延迟(ms) | 内存占用 |
|---|---|---|---|---|
| ChromaDB | 0.8 | 12 | 15 | 中 |
| FAISS | 0.1 | 1.2 | 2 | 低 |
| Qdrant | 1.5 | 18 | 8 | 中 |
| Milvus | — | — | 3 | 高 |
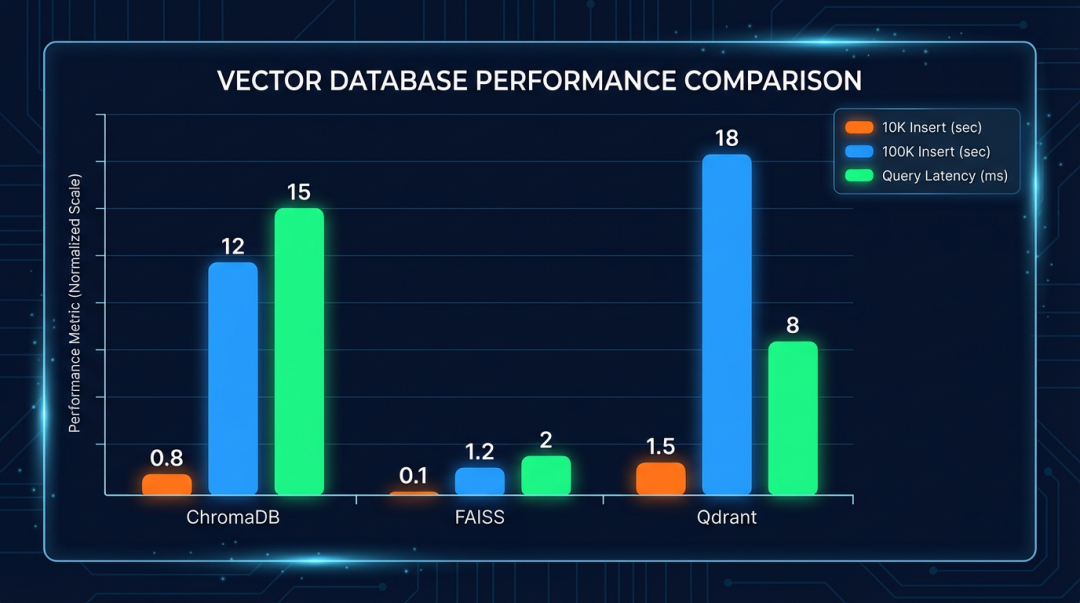
FAISS 插入和查询都最快,但不支持元数据、不持久化(需自己写);Qdrant 查询延迟不错,支持过滤;ChromaDB 在 10K 量级够用,100K 会慢一些。咱们测的是 CPU 版,你要有 GPU,FAISS 还能再快一个数量级,但部署会麻烦点。
06
特色功能对比
| 功能 | ChromaDB | FAISS | Qdrant | Milvus |
|---|---|---|---|---|
| 元数据过滤 | ✓ | ✗ | ✓ | ✓ |
| 持久化 | ✓(PersistentClient) | 需自己写 | ✓ | ✓ |
| 多租户 | ✓ | ✗ | ✓ | ✓ |
| 全文搜索 | ✗ | ✗ | ✓ | ✓ |
| 云服务 | Chroma Cloud | ✗ | Qdrant Cloud | Zilliz Cloud |
| GPU 加速 | ✗ | ✓(faiss-gpu) | ✓ | ✓ |
FAISS 就是纯向量检索库,别的都得自己拼;Qdrant 和 Milvus 功能最全,但部署成本高。元数据过滤这块,做 RAG 的时候经常要用——比如"只搜某个知识库"“只搜最近一周的文档”,ChromaDB 和 Qdrant 都支持,FAISS 就得自己先筛一遍再查。
07
选型决策树
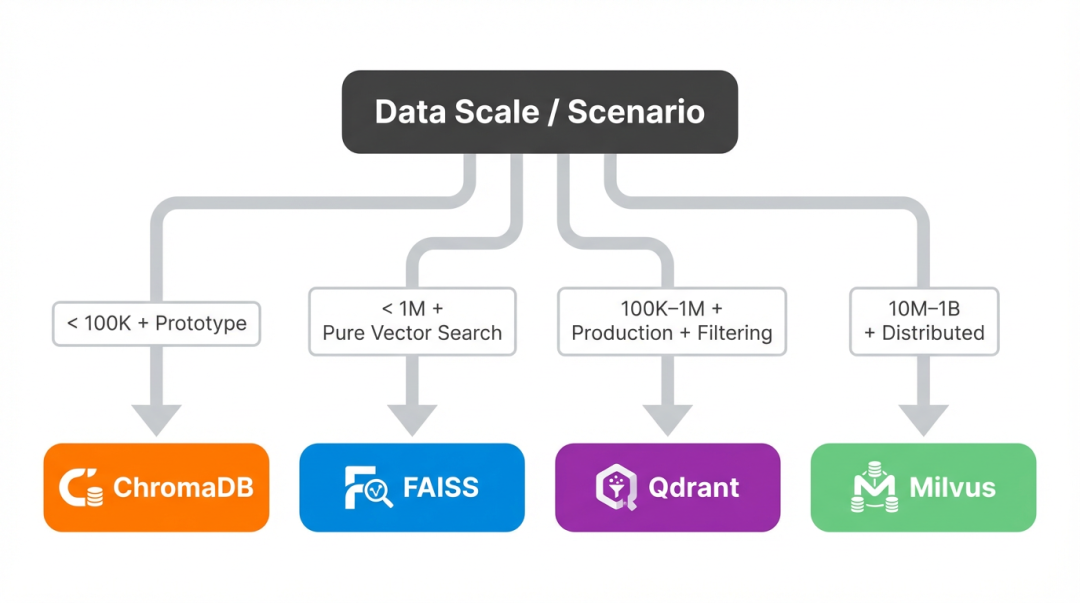
按数据量和场景来:
-
< 10 万 + 原型/本地 → ChromaDB
-
< 100 万 + 只要向量检索 → FAISS
-
10 万~百万 + 要过滤、要生产 → Qdrant
-
千万~十亿 + 分布式 → Milvus
实际选的时候,先看数据量,再看你要不要过滤、要不要持久化。很多人的误区是上来就搞 Milvus,结果数据才几万条,完全用不上。反过来,数据真到百万级了,ChromaDB 单机就会吃力,该换就换。
场景对比表:
| 场景 | 推荐 |
|---|---|
| RAG 原型、Demo | ChromaDB |
| 离线批处理、纯向量召回 | FAISS |
| 生产 RAG、需要 metadata 过滤 | Qdrant |
| 十亿级、多节点 | Milvus |
08
迁移建议:统一 VectorStore 接口
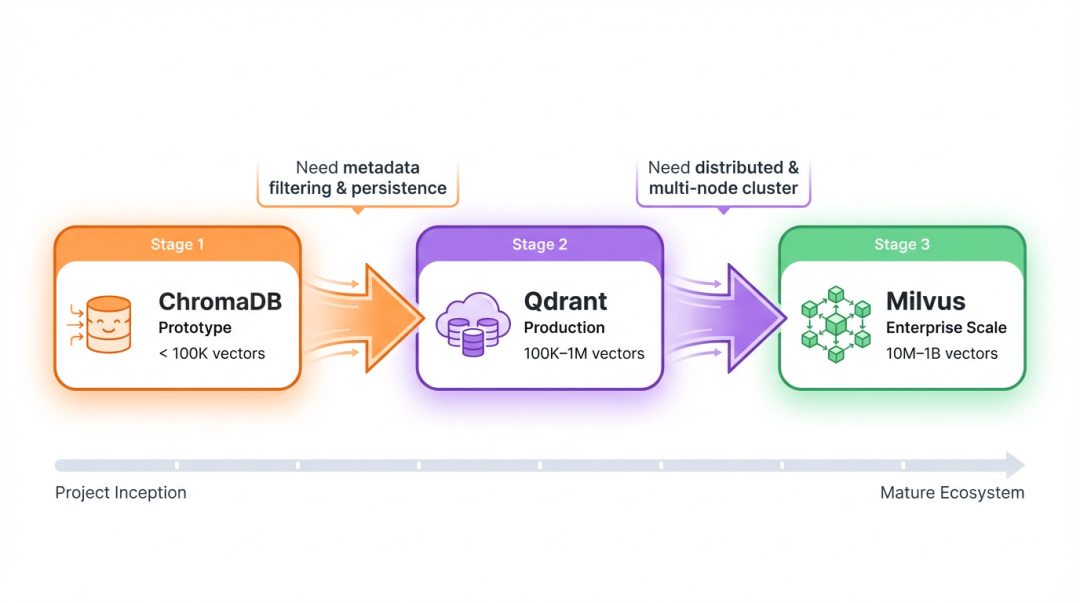
开发阶段用 ChromaDB,上线再切 Qdrant/Milvus,可以抽象一层,换实现不换业务代码。下面这段是简化版,在 Qdrant 里要转成 Filter 对象,这里没展开,实际用的时候按 Qdrant 的文档来就行。核心思路就是:业务层只调用对应接口,底层爱用谁用谁。
from abc import ABC, abstractmethodimport numpy as npclass VectorStore(ABC): @abstractmethod def add(self, ids: list[str], vectors: np.ndarray, metadatas: list[dict] | None = None): ... @abstractmethod def search(self, query: np.ndarray, k: int = 5, filter_meta: dict | None = None) -> list: ...class ChromaStore(VectorStore): def __init__(self): import chromadb self.client = chromadb.Client() self.col = self.client.get_or_create_collection("main") def add(self, ids, vectors, metadatas=None): self.col.add(ids=ids, embeddings=vectors.tolist(), metadatas=metadatas) def search(self, query, k=5, filter_meta=None): r = self.col.query(query_embeddings=[query.tolist()], n_results=k) return list(zip(r["ids"][0], r["distances"][0]))class QdrantStore(VectorStore): def __init__(self): from qdrant_client import QdrantClient self.client = QdrantClient(host="localhost", port=6333) def add(self, ids, vectors, metadatas=None): from qdrant_client.models import PointStruct points = [PointStruct(id=pid, vector=v.tolist(), payload=m or {}) for pid, v, m in zip(ids, vectors, metadatas or [{}] * len(ids))] self.client.upsert(collection_name="main", points=points) def search(self, query, k=5, filter_meta=None): hits = self.client.search(collection_name="main", query_vector=query.tolist(), limit=k) return [(h.id, h.score) for h in hits]# 切换实现只需改这一行store: VectorStore = ChromaStore() # 开发# store = QdrantStore() # 生产
9
写在最后
别在选型上纠结太久。大多数项目,ChromaDB 够用;真要上量,再按决策树换。先把 RAG 跑起来,把 Planning 机制做好,比纠结用哪个库重要得多。
假如你从2026年开始学大模型,按这个步骤走准能稳步进阶。
接下来告诉你一条最快的邪修路线,
3个月即可成为模型大师,薪资直接起飞。
阶段1:大模型基础

阶段2:RAG应用开发工程

阶段3:大模型Agent应用架构

阶段4:大模型微调与私有化部署

配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇





配套文档资源+全套AI 大模型 学习资料,朋友们如果需要可以微信扫描下方二维码免费领取【保证100%免费】👇👇


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 6
6 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)