LLMENAS:大语言模型引导的进化神经架构搜索
LLMENAS:大语言模型引导的进化神经架构搜索
前言
神经架构搜索(NAS)是AutoML的核心方向,但传统方法始终绕不开早熟收敛到局部最优的痛点:可微NAS(DARTS)易因跳连操作堆积导致性能坍缩,进化式NAS搜索成本极高,现有LLM-based NAS又存在输出多样性低、易生成无效架构的问题。
会议:IEEE Transactions on Evolutionary Computation(TEVC)
年份:2026
源码已开源:https://github.com/LLMENAS/LLMENAS
一、研究背景:传统NAS的三大核心问题
- 可微NAS(DARTS):架构参数与超网权重强耦合,易选择无参数的跳连操作,陷入局部最优并引发性能坍缩;
- 进化式NAS:全局搜索能力强,但依赖随机探索,搜索成本动辄上千GPU天(如AmoebaNet-A需3150 GPU天);
- 现有LLM-based NAS:将LLM直接作为架构生成器,存在输出多样性低(易局部收敛)、幻觉问题(复杂空间生成无效架构)的缺陷。
LLMENAS的核心思路:不改变LLM和进化算法的底层逻辑,而是重新定义二者的协作方式——让LLM做「搜索策略指导者」,而非「架构生成者」。
二、LLMENAS核心框架与核心图解读
2.1 整体框架(Fig.1):分层优化+闭环协作
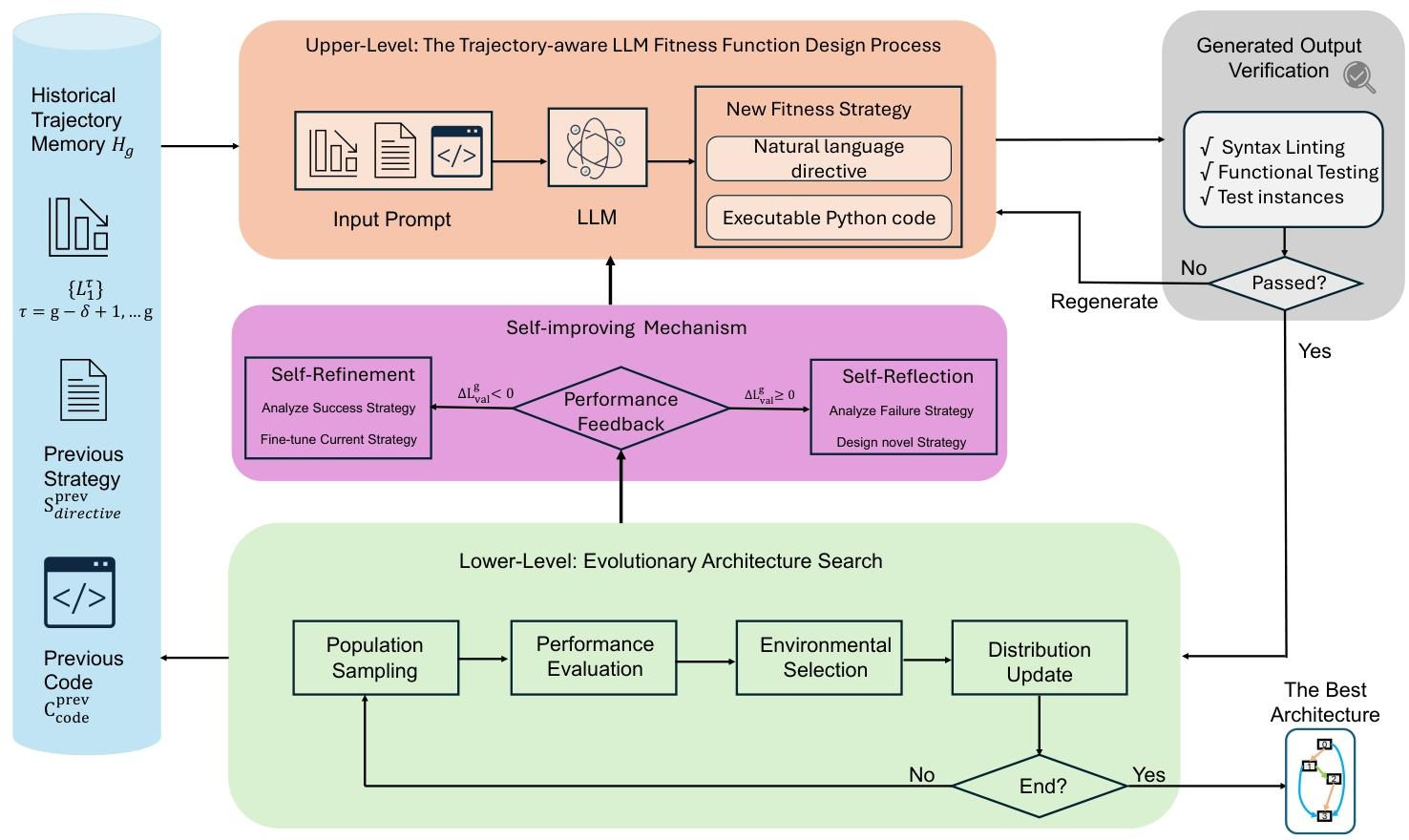
这是论文的核心框架图,清晰展示了LLMENAS的上层LLM轨迹感知适应度设计和下层进化架构搜索的闭环协作逻辑,分为6个核心步骤:
- 历史轨迹记忆:LLM获取前δ\deltaδ代的进化轨迹HgH_gHg(含性能、架构多样性指标、上一轮策略代码);
- LLM生成策略:LLM基于轨迹生成自然语言策略和可执行的适应度函数Python代码;
- 输出验证:对生成代码做语法检查、功能测试,失败则重生成,多次失败则启用兜底策略;
- 下层进化搜索:CMA-ES基于LLM设计的适应度函数,完成种群采样、评估、选择与更新;
- 性能反馈:将进化搜索的验证损失变化量ΔLval\Delta \mathcal{L}_{val}ΔLval反馈给LLM;
- LLM自改进:根据反馈触发自反思/自精修,优化下一轮的适应度设计策略。
核心亮点:框架实现了**数值进化(下层CMA-ES)和语义推理(上层LLM)**的深度协同,且通过反馈形成闭环,让整个搜索过程具备「自学习、自优化」能力。
2.2 核心组件:4大关键设计(含创新点)
(1)轨迹感知的LLM适应度设计器(核心定位创新)
首次将LLM从架构生成器改为适应度函数设计器,从根源解决LLM的幻觉和低多样性问题:
- LLM通过滑动窗口构建历史上下文HgH_gHg(固定δ=5\delta=5δ=5代,保证足够的趋势判断依据);
- 基于轨迹动态生成适应度函数fg+1=πLLM(Hg)f_{g+1}=\pi_{LLM}(H_g)fg+1=πLLM(Hg),目标是最小化未来验证损失,引导进化搜索向有潜力的区域探索,而非在局部最优中停滞。
(2)双指标驱动的适应度设计(解决局部最优的核心)
LLM设计适应度函数时,基于**开发(Exploitation)和探索(Exploration)**双指标动态平衡,二者缺一不可:
- L1L_1L1(开发):交叉熵损失,衡量候选架构的验证性能,最小化L1L_1L1引导种群向高性能区域收敛;
- L2L_2L2(探索):架构相似度指标,L2≈1L_2≈1L2≈1表示种群结构停滞(所有架构高度相似),此时LLM会自动调整适应度函数权重,强制增强探索。
(3)闭环自改进机制(论文核心亮点,Fig.1核心分支)
根据**验证损失变化量ΔLvalg\Delta \mathcal{L}_{val}^gΔLvalg**触发两种模式,让LLM能根据进化反馈迭代优化自身策略:
- 自反思(ΔLvalg≥0\Delta \mathcal{L}_{val}^g \geq0ΔLvalg≥0):验证性能停滞/恶化,说明当前策略失效,LLM诊断原有代码问题,重新设计全新的适应度函数,强制逃离局部最优;
- 自精修(ΔLvalg<0\Delta \mathcal{L}_{val}^g <0ΔLvalg<0):验证性能显著提升,说明当前策略有效,LLM保留核心逻辑,微调数学系数,加速种群向最优区域收敛。
(4)生成输出验证机制(工程化保障,Fig.1验证环节)
针对LLM的幻觉问题(生成语法错误/功能无效的代码),设计多轮验证+兜底策略,确保搜索不中断:
- 验证流程:语法检查→功能测试→测试实例验证;
- 迭代重生成:验证失败则基于错误信息重生成,最多3次;
- 兜底策略:多次失败则使用仅关注性能的鲁棒函数f=L1f=L_1f=L1,保证进化搜索的连续性。
2.3 进化搜索底层:CMA-ES的应用
下层采用**协方差矩阵自适应进化策略(CMA-ES)**作为进化算子,相比传统进化算法和梯度方法,CMA-ES通过精细的采样策略和自适应协方差矩阵调整,能更高效地探索复杂搜索空间,避免早熟收敛:
- 对架构参数构建高斯分布,随机采样生成候选架构;
- 用LLM设计的适应度函数评估候选架构,选取最优的⌊λ/2⌋\lfloor\lambda/2\rfloor⌊λ/2⌋个个体;
- 基于最优个体更新高斯分布的均值、方差和协方差矩阵,引导种群向更优区域探索。
三、论文核心实验图解读+关键实验结果
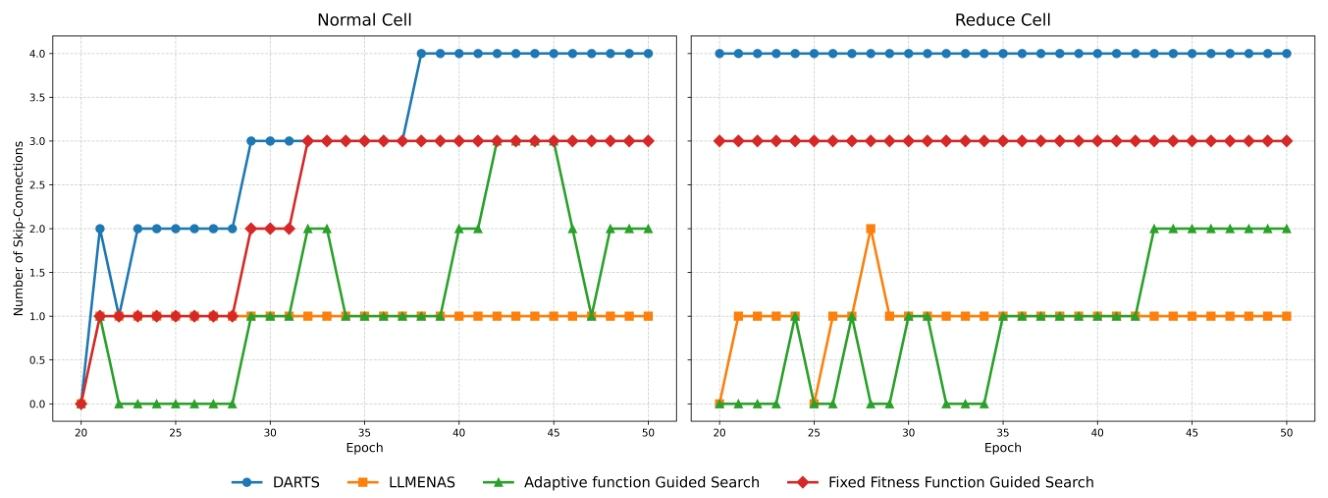
3.1 核心实验图解读
(1)Fig.2:CIFAR-10搜索过程中跳连操作数量变化
这张图直接验证了LLMENAS解决性能坍缩的效果,对比了DARTS、固定适应度函数、自适应函数引导、LLMENAS四种方法的跳连数变化:
- DARTS(蓝线):快速饱和到最大跳连数4,典型的性能坍缩表现(依赖无参数跳连,放弃有效卷积操作);
- 固定适应度(红线):也迅速陷入局部最优,稳定在3个跳连数;
- 自适应函数(绿线):虽有改善,但后期仍堆积跳连操作;
- LLMENAS(橙线):始终保持低且稳定的跳连数,证明其能有效识别并惩罚「路径最省力」的跳连操作,强制探索更有价值的卷积操作,从根源避免性能坍缩。
(2)Fig.3+Fig.4:超参T/δ对性能和搜索成本的影响
这两张图验证了LLMENAS核心超参的合理性,也是工程复现的关键:
- Fig.3(更新间隔T):T表示LLM更新适应度函数的epoch间隔,T=1时验证准确率最高(86.15%),虽搜索成本略有上升,但提升幅度远大于成本增加,因此论文设置T=1(每代更新,实时指导);
- Fig.4(观察窗口δ):δ表示LLM分析的历史轨迹代际数,δ=5时实现准确率最高(86.15%)+搜索成本最优(0.15 GPU天),δ过小则轨迹信息不足,δ过大则冗余且成本上升,因此论文设置δ=5。
(3)Fig.5:CIFAR-10损失景观可视化
这张图解释了LLMENAS泛化能力强的根本原因,对比了基线方法、自适应函数引导、LLMENAS的损失景观:
- 基线方法(左):收敛到尖锐最小值,损失等高线密集,参数轻微扰动就会导致损失骤升,泛化能力差;
- 自适应函数(中):收敛到较宽盆地,但边缘梯度仍陡峭,抗扰动能力一般;
- LLMENAS(右):收敛到平坦最小值,损失等高线稀疏,即使参数大幅扰动,损失仍保持稳定,泛化能力和鲁棒性显著提升。
3.2 关键实验结果(性能+效率双SOTA)
LLMENAS在CIFAR-10/100、ImageNet-1k、NAS-Bench-201四大基准上测试,平民级硬件即可复现(CIFAR用单RTX3090,ImageNet用单RTX4090),核心结果如下:
| 数据集 | Top-1准确率 | 搜索成本(GPU天) | 测试误差 | 核心优势 |
|---|---|---|---|---|
| CIFAR-10 | 97.58% | 0.15 | 2.42% | 低于ADARTS/GENAS等SOTA方法 |
| CIFAR-100 | 83.52% | 0.15 | 16.48% | 仅3.5M参数,兼顾轻量与性能 |
| ImageNet-1k | 75.6% | 2.0 | 24.4% | 远低于传统进化NAS的3150 GPU天 |
核心效率亮点:LLM的推理延迟可忽略(CIFAR-10仅0.002 GPU天),整体搜索成本远低于高效梯度NAS(如DARTS 0.4 GPU天)和进化NAS(如NSGANetV1 27 GPU天)。
3.3 消融实验(验证组件必要性)
论文通过消融实验证明,移除任意核心组件均会导致性能显著下降,验证了设计的合理性:
- LLMENAS-V1(移除自改进机制):CIFAR-10测试误差从2.42%升至2.51%,无法自适应优化策略,搜索后期易停滞;
- LLMENAS-V2(移除LLM适应度设计):CIFAR-10测试误差骤升至3.19%,陷入局部最优,发现的架构仅2.6M参数(过度简单);
- 不同进化算法适配:LLMENAS可适配CMA-ES/DE/PSO,添加LLM指导后,所有算法的测试误差均显著下降,验证了框架的通用性。
四、结论与未来展望
4.1 研究结论
LLMENAS的核心贡献在于重新定义了LLM在NAS中的角色,通过四大关键设计实现了三大突破:
- 解决了传统NAS早熟收敛到局部最优的核心痛点,有效避免性能坍缩;
- 实现了SOTA性能+极致搜索效率的双重突破,平民级硬件可复现;
- 提出了LLM与进化算法的闭环协作范式,为后续融合研究提供了新思路。
用一句话概括LLMENAS:让LLM做NAS的「战略指导者」,通过动态适应度设计引导进化搜索,而非直接做「手工设计师」生成架构。
4.2 未来研究方向
- 高维轨迹表示:当前LLM仅基于标量轨迹推理,未来将融入架构拓扑等高维信息,实现更精细的机制化推理;
- 提升可解释性:解决LLM决策的「黑箱问题」,让适应度函数的设计过程更透明;
- 多目标优化扩展:将框架应用于「精度-参数量」「精度-推理速度」等多目标NAS场景;
- 实际任务落地:将LLMENAS应用于目标检测、语义分割、NLP等复杂任务,验证实际部署价值。
总结
LLMENAS是一款兼顾创新性、实用性、可复现性的NAS算法,其核心价值不仅在于实现了性能和效率的突破,更在于提出了一种全新的LLM与进化计算的协作方式。论文中的核心图表(Fig.1-Fig.5)层层递进,从框架设计、问题解决、超参优化到泛化能力,完整验证了算法的有效性,也是理解该论文的关键。
对于开发者和研究者而言,LLMENAS的开源代码和平民级复现成本,让其成为NAS领域值得深入学习和二次开发的优秀算法。
论文DOI:10.1109/TEVC.2026.3670336
源码地址:https://github.com/LLMENAS/LLMENAS
收藏+关注,后续持续拆解顶刊顶会核心论文+图表解读~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)