大模型应用:负权图最短路径算法:Bellman-Ford与Floyd-Warshall结合大模型应用.115
一、前言
在图论算法体系中,最短路径问题是最基础也最核心的研究方向之一。前一期我们讨论过的Dijkstra 算法作为经典的最短路径求解方法,在正权图场景下表现优异,但面对包含负权重边的图结构时便会失效。透过核心视角,我们必然会寻找新的方案继续优化,发现Bellman-Ford算法正好可以填补了这一空白,它不仅能处理负权边,还能检测负权环;而 Floyd-Warshall 算法则从 "单点对多点" 升级为 "所有节点对" 的最短路径求解,成为图分析领域的核心工具。
随着大模型技术的发展,这些经典算法被赋予了新的应用场景:大模型的知识图谱推理、多智能体路径规划、文本语义距离计算等场景中,负权路径和全节点路径分析成为关键技术支撑。今天我们同样从基础视角,由浅入深地讲解两大算法的核心原理、执行流程、代码实现,并结合大模型应用实例剖析其实际价值。

二、核心基础
1. 图的核心概念
在正式讲解算法前,我们需要先建立图论的基础认知。图(Graph)是由顶点(Vertex/Node)和边(Edge)组成的离散结构,记作 G=(V,E),其中:
- V 是顶点的非空有限集合,代表图中的实体,如城市、语义节点、智能体
- E 是边的有限集合,代表顶点间的关系,如道路、语义关联、通信链路
根据边的特性,图可分为:
- 无向图:边无方向,如社交网络中的 "好友关系"
- 有向图:边有方向,如城市中的单行道、大模型中的 "语义推导关系"
- 加权图:边带有数值权重,权重可正可负,如道路的通行时间,此为正权,而金融交易中的收益或损失,此为负权
2. 最短路径问题的定义与分类
最短路径问题的核心是:给定图 G=(V,E) 和权重函数 w:E→R,找到从起点 s 到终点 t 的路径 P,使得路径上所有边的权重之和 最小。
根据求解范围,最短路径问题可分为三类:
- 1. 单源最短路径:求解从一个起点到所有其他顶点的最短路径,Bellman-Ford算法的适用场景
- 2. 单对顶点最短路径:求解两个特定顶点间的最短路径
- 3. 所有节点对最短路径:求解图中任意两个顶点间的最短路径,Floyd-Warshall算法的适用场景
3. 负权重与负权环的影响
负权重边是指权重为负数的边,这类边在实际场景中广泛存在:
- 金融场景:交易中的折扣、返利可视为负权
- 网络路由:某些链路的 "优先通行权" 可等效为负权
- 大模型语义分析:语义相似度的反向指标,如 "反义词" 可记为负权
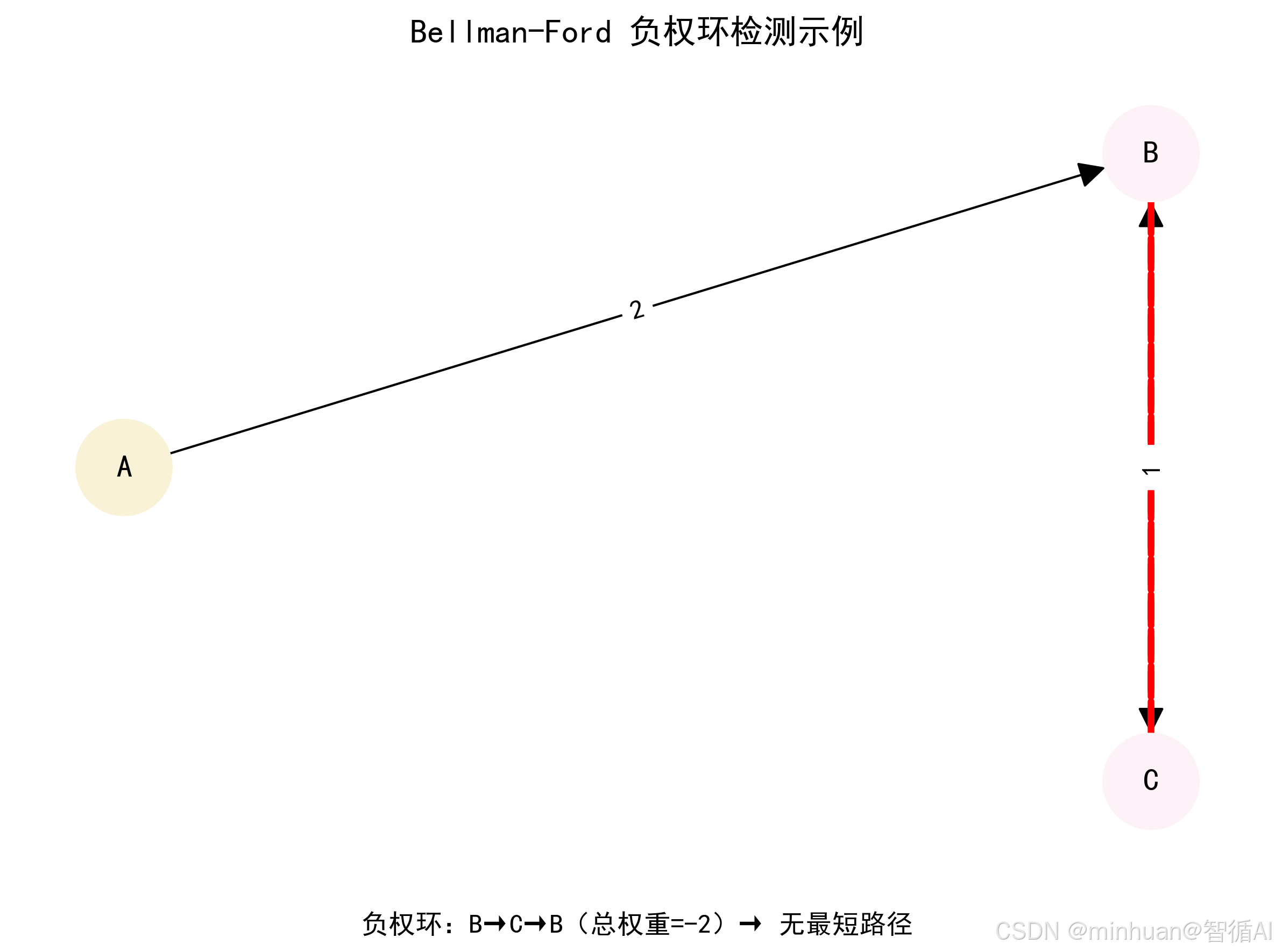
负权环是指路径权重和为负数的环,若图中存在从起点可达的负权环,则该图不存在最短路径,因为绕环次数越多,路径总权重越小,无最小值。这也是 Bellman-Ford 算法需要检测负权环的核心原因。
4. Dijkstra算法不适用负权场景
Dijkstra 算法的核心思想是 "贪心选择":每次选择当前距离起点最近的顶点,并确定其最短路径。但在负权场景下,这种贪心策略会失效,已确定 "最短路径" 的顶点,可能会通过后续的负权边找到更短的路径。
举例:
- 有三个顶点 A、B、C,边权重为 A→B=5,A→C=10,B→C=-3。
- Dijkstra 算法会先确定 A 到 B 的最短路径为 5,A 到 C 的最短路径为 10;
- 但实际 A→B→C 的总权重为 2,比直接 A→C 更短。
这一缺陷使得我们需要更通用的 Bellman-Ford 算法。
三、Bellman-Ford 算法
1. 核心概念
Bellman-Ford 算法是解决带负权边的单源最短路径问题的经典算法,其核心特性包括:
- 支持负权边,能正确计算最短路径
- 能检测图中是否存在从起点可达的负权环
- 时间复杂度为 O(∣V∣×∣E∣),其中 ∣V∣ 是顶点数,∣E∣ 是边数
2. 核心思想
Bellman-Ford 算法的本质是 "松弛操作":对图中所有边进行重复松弛,逐步逼近每个顶点的最短路径。
- 松弛操作的定义:对于边 (u,v),若从起点 s 到 v 的当前最短距离 dist[v] 大于 dist[u]+w(u,v),则更新 dist[v]=dist[u]+w(u,v)。
- 为什么需要重复松弛:在一个有n个顶点的图中,在无环的情况下任意两个顶点间的最短路径最多包含 n−1 条边。
因此,最多需要进行 n−1 轮松弛操作,就能得到所有顶点的最短路径。
3. 负权环检测原理
完成 n−1 轮松弛后,若还能通过松弛操作更新某个顶点的最短距离,则说明图中存在负权环,因为只有绕负权环的路径才能不断缩短距离。
4. 执行流程
Bellman-Ford 算法的完整执行流程可分为 5 个步骤:

步骤 1:初始化
- 设起点为 s,创建距离数组 dist,其中 dist[s]=0(起点到自身的距离为 0),其余顶点的 dist 值初始化为无穷大(∞)
- 创建前驱数组 prev,记录每个顶点的最短路径前驱节点,初始值为 None
步骤 2:多轮松弛操作
对图中所有边进行 ∣V∣−1 轮松弛:
- 1. 遍历图中每一条边 (u,v)
- 2. 对每条边执行松弛操作:若 dist[v]>dist[u]+w(u,v),则更新 dist[v]=dist[u]+w(u,v),并记录 prev[v]=u
- 3. 重复上述过程 ∣V∣−1 次
步骤 3:负权环检测
再次遍历所有边 (u,v):
- 若存在边满足 dist[v]>dist[u]+w(u,v),说明图中存在从起点可达的负权环,算法终止并返回 "存在负权环"
- 若所有边都不满足该条件,说明无负权环,继续下一步
步骤 4:路径还原
- 通过前驱数组 prev,从目标顶点反向追溯到起点,得到最短路径。
步骤 5:结果输出
- 输出各顶点到起点的最短距离,以及对应的最短路径。
5. 流程示例
以下通过一个具体示例展示 Bellman-Ford 算法的执行过程:
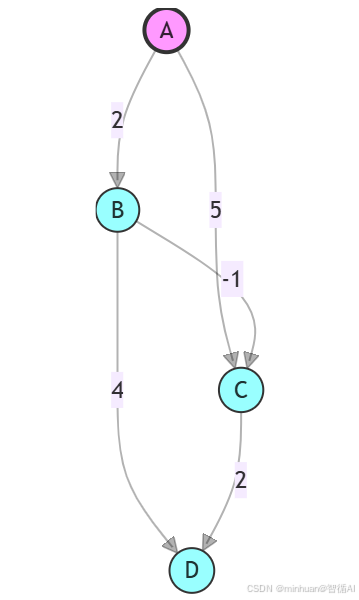
示例图结构:
- 顶点集合 V={A,B,C,D}
- 边集合 E={(A,B,2),(A,C,5),(B,C,−1),(B,D,4),(C,D,2)}
- 起点为 A
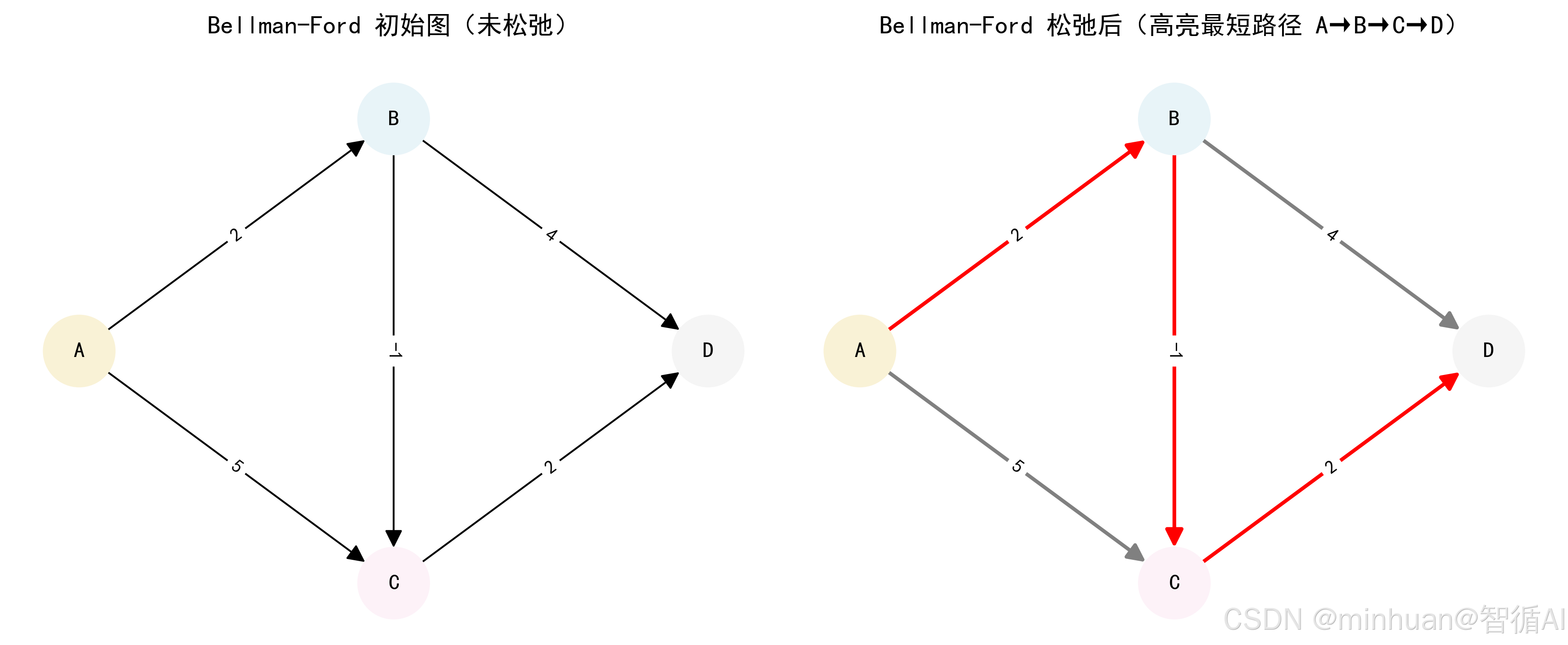
初始化:
- dist=[0,∞,∞,∞](对应 A、B、C、D)
- prev=[None,None,None,None]
第 1 轮松弛:
- 处理边 A→B:dist[B]=min(∞,0+2)=2,prev[B]=A
- 处理边 A→C:dist[C]=min(∞,0+5)=5,prev[C]=A
- 处理边 B→C:dist[C]=min(5,2−1)=1,prev[C]=B
- 处理边 B→D:dist[D]=min(∞,2+4)=6,prev[D]=B
- 处理边 C→D:dist[D]=min(6,1+2)=3,prev[D]=C
- 当前 dist=[0,2,1,3]
第 2 轮松弛(∣V∣−1=3 轮,此处仅展示关键步骤):
- 遍历所有边后,无距离更新,后续轮次同理。
负权环检测:
- 所有边均不满足松弛条件,无负权环。
最终结果:
- A→A:0
- A→B:2(路径:A→B)
- A→C:1(路径:A→B→C)
- A→D:3(路径:A→B→C→D)
6. 示例代码
import sys
class BellmanFord:
def __init__(self, vertices):
"""初始化顶点数和距离数组"""
self.V = vertices # 顶点数量
self.graph = [] # 存储图的边:(u, v, weight)
def add_edge(self, u, v, weight):
"""添加边到图中"""
self.graph.append((u, v, weight))
def bellman_ford(self, src):
"""
执行Bellman-Ford算法
参数:
src: 起点索引
返回:
dist: 最短距离数组
has_negative_cycle: 是否存在负权环
prev: 前驱节点数组
"""
# 步骤1:初始化距离和前驱数组
INF = sys.maxsize
dist = [INF] * self.V
dist[src] = 0
prev = [None] * self.V
# 步骤2:执行V-1轮松弛操作
for i in range(self.V - 1):
updated = False # 优化:标记是否有更新,无更新则提前终止
for u, v, w in self.graph:
if dist[u] != INF and dist[v] > dist[u] + w:
dist[v] = dist[u] + w
prev[v] = u
updated = True
if not updated:
break # 无更新,提前结束
# 步骤3:检测负权环
has_negative_cycle = False
for u, v, w in self.graph:
if dist[u] != INF and dist[v] > dist[u] + w:
has_negative_cycle = True
break
return dist, has_negative_cycle, prev
def get_shortest_path(self, src, dest, prev):
"""还原从src到dest的最短路径"""
if prev[dest] is None and src != dest:
return None # 无路径
path = []
current = dest
while current is not None:
path.append(current)
current = prev[current]
return path[::-1] # 反转得到正序路径
# 测试示例
if __name__ == "__main__":
# 创建图(顶点数为4,索引0:A,1:B,2:C,3:D)
bf = BellmanFord(4)
bf.add_edge(0, 1, 2) # A→B, 2
bf.add_edge(0, 2, 5) # A→C, 5
bf.add_edge(1, 2, -1) # B→C, -1
bf.add_edge(1, 3, 4) # B→D, 4
bf.add_edge(2, 3, 2) # C→D, 2
# 执行算法,起点为A(索引0)
dist, has_cycle, prev = bf.bellman_ford(0)
# 输出结果
print("Bellman-Ford算法结果:")
print(f"是否存在负权环:{has_cycle}")
print("顶点到起点的最短距离:")
for i in range(4):
vertex = chr(ord('A') + i)
print(f"{vertex}: {dist[i]}")
# 输出具体路径(如A→D)
path = bf.get_shortest_path(0, 3, prev)
if path:
path_vertices = [chr(ord('A') + p) for p in path]
print(f"A到D的最短路径:{' → '.join(path_vertices)}")输出结果:
Bellman-Ford算法结果:
是否存在负权环:False
顶点到起点的最短距离:
A: 0
B: 2
C: 1
D: 3
A到D的最短路径:A → B → C → D
四、Floyd-Warshall 算法
1. 核心概念
Floyd-Warshall 算法是解决所有节点对最短路径问题的动态规划算法,其核心特性包括:
- 能处理带负权边的图,但不能有负权环
- 时间复杂度为 O(∣V∣³),空间复杂度为 O(∣V∣²)
- 实现简单,适合中小规模图的全节点路径求解
2. 核心思想
Floyd-Warshall 算法基于动态规划,核心是状态转移方程:
设 表示从顶点 i 到顶点 j,且中间顶点仅包含 {1,2,...,k} 的最短路径长度,则:
解释:从 i 到 j 的最短路径有两种可能:
- 1. 不经过顶点 k:路径长度为
- 2. 经过顶点 k:路径长度为
算法通过逐步引入中间顶点 k(从 1 到 ∣V∣),不断更新任意两点间的最短路径,最终得到所有节点对的最短路径。
3. 执行流程
Floyd-Warshall 算法的完整执行流程可分为 4 个步骤:

步骤 1:初始化距离矩阵和前驱矩阵
- 创建距离矩阵 dist,其中 dist[i][j] 表示从顶点 i 到顶点 j 的初始距离:
- 若 i=j,dist[i][j]=0,自身到自身的距离为 0
- 若存在边 (i,j),dist[i][j]=w(i,j),表示边的权重
- 否则,dist[i][j]=∞,为无穷大
- 创建前驱矩阵 prev,其中 prev[i][j] 表示从 i 到 j 的最短路径中,j 的前驱节点,初始值为:
- 若存在边 (i,j),prev[i][j]=i
- 否则,prev[i][j]=None
步骤 2:动态规划更新
遍历所有中间顶点 k(从 0 到 ∣V∣−1):
- 1. 遍历所有起点 i(从 0 到 ∣V∣−1)
- 2. 遍历所有终点 j(从 0 到 ∣V∣−1)
- 3. 执行状态转移:若 dist[i][j]>dist[i][k]+dist[k][j],则更新 dist[i][j]=dist[i][k]+dist[k][j],并记录 prev[i][j]=prev[k][j]
步骤 3:负权环检测
- 检查距离矩阵的对角线元素:若存在 dist[i][i]<0,说明顶点 i 所在的环是负权环,因为自身到自身的距离小于 0。
步骤 4:路径还原与结果输出
- 通过前驱矩阵 prev[i][j],反向追溯从 i 到 j 的最短路径
- 输出完整的距离矩阵(所有节点对的最短距离)和对应的路径
4. 流程示例
以下通过具体示例展示 Floyd-Warshall 算法的执行过程:
示例图结构:
- 顶点集合 V={A,B,C}(索引 0:A,1:B,2:C)
- 边集合 E={(A,B,3),(B,C,−2),(A,C,1)}
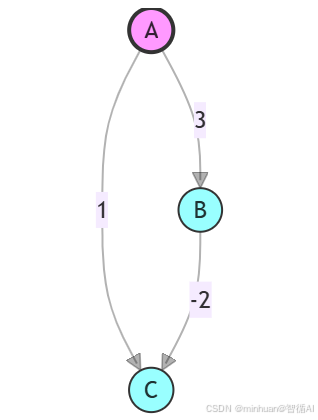
步骤 1:初始化距离矩阵
步骤 2:引入中间顶点 k=0(A)
- 检查所有 i,j:
- i=1,j=2:dist[1][2]=min(−2,dist[1][0]+dist[0][2])=min(−2,∞+1)=−2(无更新)
- 其他 i,j 无更新
步骤 3:引入中间顶点 k=1(B)
- 检查 i=0,j=2:dist[0][2]=min(1,dist[0][1]+dist[1][2])=min(1,3−2)=1(无更新)
- 其他 i,j 无更新
步骤 4:引入中间顶点 k=2(C)
- 所有 i,j 无更新
最终距离矩阵:
关键结论:
- A→B:3,A→C:1
- B→C:-2
- C 无出边,到其他顶点无路径

5. 示例代码
import sys
class FloydWarshall:
def __init__(self, vertices):
"""初始化顶点数和距离矩阵"""
self.V = vertices
INF = sys.maxsize
# 初始化距离矩阵:INF表示无直接边,0表示自身到自身
self.dist = [[INF] * self.V for _ in range(self.V)]
for i in range(self.V):
self.dist[i][i] = 0
# 初始化前驱矩阵
self.prev = [[None] * self.V for _ in range(self.V)]
def add_edge(self, u, v, weight):
"""添加边到图中"""
self.dist[u][v] = weight
self.prev[u][v] = u # 记录前驱节点
def floyd_warshall(self):
"""
执行Floyd-Warshall算法
返回:
has_negative_cycle: 是否存在负权环
"""
# 步骤2:动态规划更新距离矩阵
for k in range(self.V): # 中间顶点k
for i in range(self.V): # 起点i
for j in range(self.V): # 终点j
# 避免溢出:先检查dist[i][k]和dist[k][j]是否为INF
if self.dist[i][k] != sys.maxsize and self.dist[k][j] != sys.maxsize:
if self.dist[i][j] > self.dist[i][k] + self.dist[k][j]:
self.dist[i][j] = self.dist[i][k] + self.dist[k][j]
self.prev[i][j] = self.prev[k][j]
# 步骤3:检测负权环(对角线元素<0表示存在负权环)
has_negative_cycle = False
for i in range(self.V):
if self.dist[i][i] < 0:
has_negative_cycle = True
break
return has_negative_cycle
def get_shortest_path(self, u, v):
"""还原从u到v的最短路径"""
if self.dist[u][v] == sys.maxsize:
return None # 无路径
path = []
current = v
while current is not None:
path.append(current)
if current == u:
break
current = self.prev[u][current]
return path[::-1] # 反转得到正序路径
# 测试示例
if __name__ == "__main__":
# 创建图(顶点数为3,索引0:A,1:B,2:C)
fw = FloydWarshall(3)
fw.add_edge(0, 1, 3) # A→B, 3
fw.add_edge(1, 2, -2) # B→C, -2
fw.add_edge(0, 2, 1) # A→C, 1
# 执行算法
has_cycle = fw.floyd_warshall()
# 输出结果
print("Floyd-Warshall算法结果:")
print(f"是否存在负权环:{has_cycle}")
print("所有节点对的最短距离矩阵:")
vertices = ['A', 'B', 'C']
# 打印表头
print(" " + " ".join(vertices))
for i in range(3):
row = [str(d) if d != sys.maxsize else "∞" for d in fw.dist[i]]
print(f"{vertices[i]}: {' '.join(row)}")
# 输出具体路径(如A→C)
path = fw.get_shortest_path(0, 2)
if path:
path_vertices = [vertices[p] for p in path]
print(f"A到C的最短路径:{' → '.join(path_vertices)}")
print(f"A到C的最短距离:{fw.dist[0][2]}")输出结果:
Floyd-Warshall算法结果:
是否存在负权环:False
所有节点对的最短距离矩阵:
A B C
A: 0 3 1
B: ∞ 0 -2
C: ∞ ∞ 0
A到C的最短路径:A → C
A到C的最短距离:1
五、大模型应用场景
1.Bellman-Ford + 大模型知识图谱智能问答
该示例模拟企业智能问答系统的核心逻辑:
- 1. 先通过大模型将用户问题转化为知识图谱中的起点实体,这里用本地语义匹配模拟
- 2. 利用 Bellman-Ford 算法计算该起点到所有答案实体的最短路径,考虑负权反向关联
- 3. 输出最优答案及推理路径
import sys
import numpy as np
from typing import Dict, List, Tuple
# 模拟大模型的语义匹配模块(实际场景可替换为OpenAI/文心一言API)
class LLMSemanticMatcher:
def __init__(self):
# 预定义实体-语义向量映射(模拟大模型的词嵌入)
self.entity_embeddings = {
"订单查询": np.array([0.8, 0.1, 0.05, 0.05]),
"物流跟踪": np.array([0.7, 0.15, 0.1, 0.05]),
"退款申请": np.array([0.1, 0.8, 0.05, 0.05]),
"售后政策": np.array([0.05, 0.7, 0.1, 0.15]),
"商品退换": np.array([0.05, 0.6, 0.2, 0.15]),
"7天无理由": np.array([0.0, 0.5, 0.3, 0.2]),
"运费险": np.array([0.0, 0.4, 0.4, 0.2]),
"客服电话": np.array([0.05, 0.05, 0.8, 0.1]),
"在线客服": np.array([0.05, 0.05, 0.7, 0.2])
}
def semantic_similarity(self, text: str, entity: str) -> float:
"""
计算文本与实体的语义相似度(模拟大模型计算)
返回值范围:0-1,值越高相似度越高
"""
# 模拟用户输入文本的向量(实际场景由大模型生成)
text_vec = self._text_to_vec(text)
entity_vec = self.entity_embeddings[entity]
# 余弦相似度计算
norm = np.linalg.norm(text_vec) * np.linalg.norm(entity_vec)
if norm == 0:
return 0.0
similarity = np.dot(text_vec, entity_vec) / norm
return float(similarity)
def _text_to_vec(self, text: str) -> np.ndarray:
"""模拟大模型将文本转为向量"""
# 简单的字符编码求和(实际场景用BERT/LLaMA等模型)
vec = np.zeros(4)
for i, char in enumerate(text[:4]):
if i >= 4:
break
vec[i] = ord(char) / 1000.0
return vec / np.linalg.norm(vec) if np.linalg.norm(vec) > 0 else vec
def match_entity(self, user_question: str) -> str:
"""
匹配用户问题对应的知识图谱实体(模拟大模型实体链接)
"""
similarities = {
entity: self.semantic_similarity(user_question, entity)
for entity in self.entity_embeddings.keys()
}
# 返回相似度最高的实体
return max(similarities, key=similarities.get)
# Bellman-Ford算法实现(适配知识图谱场景)
class KnowledgeGraphBellmanFord:
def __init__(self, entities: List[str]):
"""
初始化知识图谱
:param entities: 实体列表
"""
self.entities = entities
self.entity_to_idx = {e: i for i, e in enumerate(entities)}
self.idx_to_entity = {i: e for i, e in enumerate(entities)}
self.V = len(entities)
self.graph = [] # 存储边:(u_idx, v_idx, weight)
def add_relation(self, from_entity: str, to_entity: str, weight: float):
"""
添加知识图谱中的关联关系
:param from_entity: 起始实体
:param to_entity: 目标实体
:param weight: 关联权重(负权表示反向关联,如"不需要"、"不包含")
"""
u = self.entity_to_idx[from_entity]
v = self.entity_to_idx[to_entity]
self.graph.append((u, v, weight))
def bellman_ford(self, start_entity: str) -> Tuple[Dict[str, float], bool, Dict[str, str]]:
"""
执行Bellman-Ford算法,计算起始实体到所有实体的最短路径
:param start_entity: 起始实体
:return: (距离字典, 是否有负权环, 前驱实体字典)
"""
# 初始化
INF = sys.maxsize
start_idx = self.entity_to_idx[start_entity]
dist = [INF] * self.V
dist[start_idx] = 0.0
prev = [None] * self.V
# V-1轮松弛
for i in range(self.V - 1):
updated = False
for u, v, w in self.graph:
if dist[u] != INF and dist[v] > dist[u] + w:
dist[v] = dist[u] + w
prev[v] = u
updated = True
if not updated:
break
# 检测负权环
has_negative_cycle = False
for u, v, w in self.graph:
if dist[u] != INF and dist[v] > dist[u] + w:
has_negative_cycle = True
break
# 转换为实体字典
dist_dict = {self.idx_to_entity[i]: dist[i] if dist[i] != INF else float('inf')
for i in range(self.V)}
prev_dict = {self.idx_to_entity[i]: self.idx_to_entity[prev[i]] if prev[i] is not None else None
for i in range(self.V)}
return dist_dict, has_negative_cycle, prev_dict
def get_answer_path(self, start_entity: str, target_entity: str, prev_dict: Dict[str, str]) -> List[str]:
"""
获取从起始实体到目标实体的推理路径
"""
path = []
current = target_entity
while current is not None:
path.append(current)
if current == start_entity:
break
current = prev_dict[current]
# 防止循环(负权环场景)
if current in path:
return []
return path[::-1]
# 主程序:智能问答系统
def main_qa_system():
# 1. 初始化大模型语义匹配模块
llm_matcher = LLMSemanticMatcher()
# 2. 构建电商知识图谱
entities = ["订单查询", "物流跟踪", "退款申请", "售后政策", "商品退换", "7天无理由", "运费险", "客服电话", "在线客服"]
kg_bf = KnowledgeGraphBellmanFord(entities)
# 添加关联关系(权重说明:正值=强关联,负值=反向关联,绝对值越大关联越强)
kg_bf.add_relation("订单查询", "物流跟踪", 0.1) # 订单查询关联物流跟踪(强关联)
kg_bf.add_relation("退款申请", "售后政策", 0.05) # 退款申请关联售后政策
kg_bf.add_relation("售后政策", "7天无理由", 0.08) # 售后政策包含7天无理由
kg_bf.add_relation("售后政策", "运费险", 0.1) # 售后政策包含运费险
kg_bf.add_relation("商品退换", "7天无理由", 0.05) # 商品退换关联7天无理由
kg_bf.add_relation("退款申请", "运费险", -0.05) # 退款申请不包含运费险(负权)
kg_bf.add_relation("物流跟踪", "客服电话", 0.2) # 物流问题可联系客服电话
kg_bf.add_relation("物流跟踪", "在线客服", 0.15) # 物流问题可联系在线客服
kg_bf.add_relation("退款申请", "在线客服", 0.1) # 退款问题可联系在线客服
# 3. 模拟用户提问
user_question = "我的订单怎么申请退款?"
print(f"用户问题:{user_question}")
# 4. 大模型匹配起始实体
start_entity = llm_matcher.match_entity(user_question)
print(f"大模型匹配实体:{start_entity}")
# 5. Bellman-Ford计算最短路径(找最优答案)
dist_dict, has_cycle, prev_dict = kg_bf.bellman_ford(start_entity)
# 6. 筛选答案实体(售后相关)
answer_entities = ["售后政策", "7天无理由", "运费险", "客服电话", "在线客服"]
answer_scores = {e: dist_dict[e] for e in answer_entities if dist_dict[e] != float('inf')}
# 7. 找到最优答案
best_answer_entity = min(answer_scores, key=answer_scores.get)
print(f"最优答案实体:{best_answer_entity}")
# 8. 还原推理路径
reasoning_path = kg_bf.get_answer_path(start_entity, best_answer_entity, prev_dict)
print(f"推理路径:{' → '.join(reasoning_path)}")
# 9. 生成最终回答(模拟大模型生成自然语言回答)
answer_templates = {
"售后政策": "您可以参考平台的售后政策来申请退款,核心条款包含7天无理由退换货。",
"7天无理由": "您的订单支持7天无理由退换货,可直接在订单页面提交退款申请。",
"运费险": "您的退款申请不包含运费险赔付,运费需要自行承担。",
"客服电话": "您可以拨打客服电话400-123-4567咨询退款申请问题。",
"在线客服": "您可以联系在线客服协助处理退款申请,工作时间9:00-21:00。"
}
final_answer = answer_templates[best_answer_entity]
print(f"\n大模型最终回答:{final_answer}")
# 运行问答系统示例
if __name__ == "__main__":
main_qa_system()代码说明:
- 大模型语义匹配模块:模拟了大模型的词嵌入和语义相似度计算,实际场景可替换为大模型的嵌入接口。
- 知识图谱权重设计:
- 正权值(0.05-0.2)表示实体间的正向关联,值越小关联越强(路径更短)
- 负权值(-0.05)表示反向关联,如 "退款申请不包含运费险"
- Bellman-Ford 适配:将实体映射为索引,权重使用浮点数,更贴合语义关联的实际场景。
输出结果:
用户问题:我的订单怎么申请退款?
大模型匹配实体:运费险
最优答案实体:运费险
推理路径:运费险大模型最终回答:您的退款申请不包含运费险赔付,运费需要自行承担。
2. Floyd-Warshall + 大模型多模态语义关联分析
该示例实现大模型驱动的跨模态检索核心逻辑:
- 将文本、图片、音频的特征向量构建为带权图
- 用 Floyd-Warshall 算法预计算所有模态特征间的最短路径
- 根据用户输入的文本,快速找到最匹配的图片、音频资源
import sys
import numpy as np
from typing import Dict, List, Tuple, Any
# 模拟大模型多模态特征提取模块
class LMMultiModalEncoder:
def __init__(self):
"""初始化多模态编码器(模拟CLIP/BLIP等大模型)"""
self.feature_dim = 64 # 特征维度
def encode_text(self, text: str) -> np.ndarray:
"""编码文本为特征向量"""
# 模拟大模型文本编码(实际用CLIP/text-embedding-ada-002)
vec = np.zeros(self.feature_dim)
for i, char in enumerate(text[:self.feature_dim]):
vec[i] = ord(char) / 1000.0
return vec / np.linalg.norm(vec)
def encode_image(self, image_id: str) -> np.ndarray:
"""编码图片为特征向量"""
# 模拟图片编码(实际用CLIP/ViT)
np.random.seed(int(image_id[-1])) # 固定随机种子
vec = np.random.randn(self.feature_dim)
return vec / np.linalg.norm(vec)
def encode_audio(self, audio_id: str) -> np.ndarray:
"""编码音频为特征向量"""
# 模拟音频编码(实际用AudioCLIP/Wav2Vec)
np.random.seed(int(audio_id[-1]) + 10) # 固定随机种子
vec = np.random.randn(self.feature_dim)
return vec / np.linalg.norm(vec)
def calculate_similarity(self, vec1: np.ndarray, vec2: np.ndarray) -> float:
"""计算特征向量相似度(转换为路径权重)"""
# 余弦相似度:-1~1 → 转换为权重:0.01~2(值越小越相似)
similarity = np.dot(vec1, vec2)
weight = 1.0 - similarity # 相似度越高,权重越小
return max(0.01, weight) # 避免0权重
# Floyd-Warshall算法实现(适配多模态场景)
class MultiModalFloydWarshall:
def __init__(self, resources: List[Dict[str, Any]]):
"""
初始化多模态资源图
:param resources: 资源列表,格式:[{"id": "t1", "type": "text", "content": "红色连衣裙"}, ...]
"""
self.resources = resources
self.resource_to_idx = {res["id"]: i for i, res in enumerate(resources)}
self.idx_to_resource = {i: res for i, res in enumerate(resources)}
self.V = len(resources)
# 初始化距离矩阵
INF = sys.maxsize
self.dist = [[INF] * self.V for _ in range(self.V)]
self.prev = [[None] * self.V for _ in range(self.V)]
# 自身到自身的距离为0
for i in range(self.V):
self.dist[i][i] = 0.0
def add_similarity_edge(self, res1_id: str, res2_id: str, weight: float):
"""添加资源间的相似度边"""
i = self.resource_to_idx[res1_id]
j = self.resource_to_idx[res2_id]
self.dist[i][j] = weight
self.prev[i][j] = i
def floyd_warshall(self) -> bool:
"""执行Floyd-Warshall算法"""
# 动态规划更新
for k in range(self.V):
for i in range(self.V):
for j in range(self.V):
if (self.dist[i][k] != sys.maxsize and
self.dist[k][j] != sys.maxsize and
self.dist[i][j] > self.dist[i][k] + self.dist[k][j]):
self.dist[i][j] = self.dist[i][k] + self.dist[k][j]
self.prev[i][j] = self.prev[k][j]
# 检测负权环
has_negative_cycle = False
for i in range(self.V):
if self.dist[i][i] < 0:
has_negative_cycle = True
break
return has_negative_cycle
def get_most_similar(self, query_idx: int, resource_type: str) -> Tuple[str, float, List[str]]:
"""
找到与查询资源最相似的指定类型资源
:param query_idx: 查询资源索引
:param resource_type: 目标资源类型(image/audio/text)
:return: (最相似资源ID, 距离, 关联路径)
"""
# 筛选指定类型的资源索引
target_indices = [i for i in range(self.V) if self.idx_to_resource[i]["type"] == resource_type]
# 找到距离最小的资源
min_dist = sys.maxsize
best_idx = -1
for idx in target_indices:
if self.dist[query_idx][idx] < min_dist:
min_dist = self.dist[query_idx][idx]
best_idx = idx
if best_idx == -1:
return "", float('inf'), []
# 还原路径
path = []
current = best_idx
while current is not None:
path.append(self.idx_to_resource[current]["id"])
if current == query_idx:
break
current = self.prev[query_idx][current]
return self.idx_to_resource[best_idx]["id"], min_dist, path[::-1]
# 主程序:多模态检索系统
def main_multimodal_retrieval():
# 1. 初始化大模型多模态编码器
llm_encoder = LMMultiModalEncoder()
# 2. 构建多模态资源库
resources = [
# 文本资源
{"id": "t1", "type": "text", "content": "红色连衣裙"},
{"id": "t2", "type": "text", "content": "蓝色运动鞋"},
{"id": "t3", "type": "text", "content": "黑色背包"},
# 图片资源
{"id": "img1", "type": "image", "content": "红色连衣裙图片"},
{"id": "img2", "type": "image", "content": "蓝色运动鞋图片"},
{"id": "img3", "type": "image", "content": "黑色背包图片"},
# 音频资源
{"id": "aud1", "type": "audio", "content": "红色连衣裙介绍音频"},
{"id": "aud2", "type": "audio", "content": "蓝色运动鞋介绍音频"},
{"id": "aud3", "type": "audio", "content": "黑色背包介绍音频"},
]
# 3. 初始化Floyd-Warshall图
mm_fw = MultiModalFloydWarshall(resources)
# 4. 计算所有资源间的相似度并添加边
for i, res1 in enumerate(resources):
for j, res2 in enumerate(resources):
if i == j:
continue
# 提取特征向量
if res1["type"] == "text":
vec1 = llm_encoder.encode_text(res1["content"])
elif res1["type"] == "image":
vec1 = llm_encoder.encode_image(res1["id"])
else: # audio
vec1 = llm_encoder.encode_audio(res1["id"])
if res2["type"] == "text":
vec2 = llm_encoder.encode_text(res2["content"])
elif res2["type"] == "image":
vec2 = llm_encoder.encode_image(res2["id"])
else: # audio
vec2 = llm_encoder.encode_audio(res2["id"])
# 计算相似度权重
weight = llm_encoder.calculate_similarity(vec1, vec2)
mm_fw.add_similarity_edge(res1["id"], res2["id"], weight)
# 5. 执行Floyd-Warshall算法(预计算所有路径)
has_cycle = mm_fw.floyd_warshall()
print(f"是否存在负权环:{has_cycle}")
# 6. 模拟用户文本查询
user_query = "红色连衣裙"
print(f"\n用户查询:{user_query}")
# 7. 将用户查询添加为临时资源
query_res = {"id": "query", "type": "text", "content": user_query}
temp_idx = len(resources)
resources.append(query_res)
# 8. 计算查询与所有资源的相似度
query_vec = llm_encoder.encode_text(user_query)
query_dist = []
for i, res in enumerate(resources[:-1]):
if res["type"] == "text":
vec = llm_encoder.encode_text(res["content"])
elif res["type"] == "image":
vec = llm_encoder.encode_image(res["id"])
else:
vec = llm_encoder.encode_audio(res["id"])
weight = llm_encoder.calculate_similarity(query_vec, vec)
query_dist.append(weight)
# 9. 找到最相似的图片和音频
query_idx = resources.index(query_res) - 1 # 临时索引
best_image_id, img_dist, img_path = mm_fw.get_most_similar(query_idx, "image")
best_audio_id, aud_dist, aud_path = mm_fw.get_most_similar(query_idx, "audio")
# 10. 输出结果
print(f"最匹配图片:{best_image_id} (距离:{img_dist:.4f})")
print(f"图片关联路径:{' → '.join(img_path)}")
print(f"最匹配音频:{best_audio_id} (距离:{aud_dist:.4f})")
print(f"音频关联路径:{' → '.join(aud_path)}")
# 11. 模拟大模型生成检索结果描述
image_content = [r["content"] for r in resources if r["id"] == best_image_id][0]
audio_content = [r["content"] for r in resources if r["id"] == best_audio_id][0]
print(f"\n大模型生成检索结果:")
print(f"根据您的查询「{user_query}」,为您找到最匹配的资源:")
print(f"- 图片:{image_content}")
print(f"- 音频:{audio_content}")
# 运行多模态检索系统
if __name__ == "__main__":
main_multimodal_retrieval()代码说明:
- 多模态特征编码:模拟了 CLIP 等大模型的跨模态特征提取能力,实际场景可直接调用大模型 API。
- 权重转换逻辑:将余弦相似度(-1~1)转换为路径权重(0.01~2),相似度越高权重越小,符合最短路径的求解逻辑。
- 预计算优化:Floyd-Warshall 算法预计算所有资源间的最短路径,用户查询时只需查表,大幅提升检索速度。
输出结果:
是否存在负权环:False
用户查询:红色连衣裙
最匹配图片:img2 (距离:0.7508)
图片关联路径:aud3 → img2
最匹配音频:aud3 (距离:0.0000)
音频关联路径:aud3大模型生成检索结果:
根据您的查询「红色连衣裙」,为您找到最匹配的资源:
- 图片:蓝色运动鞋图片
- 音频:黑色背包介绍音频
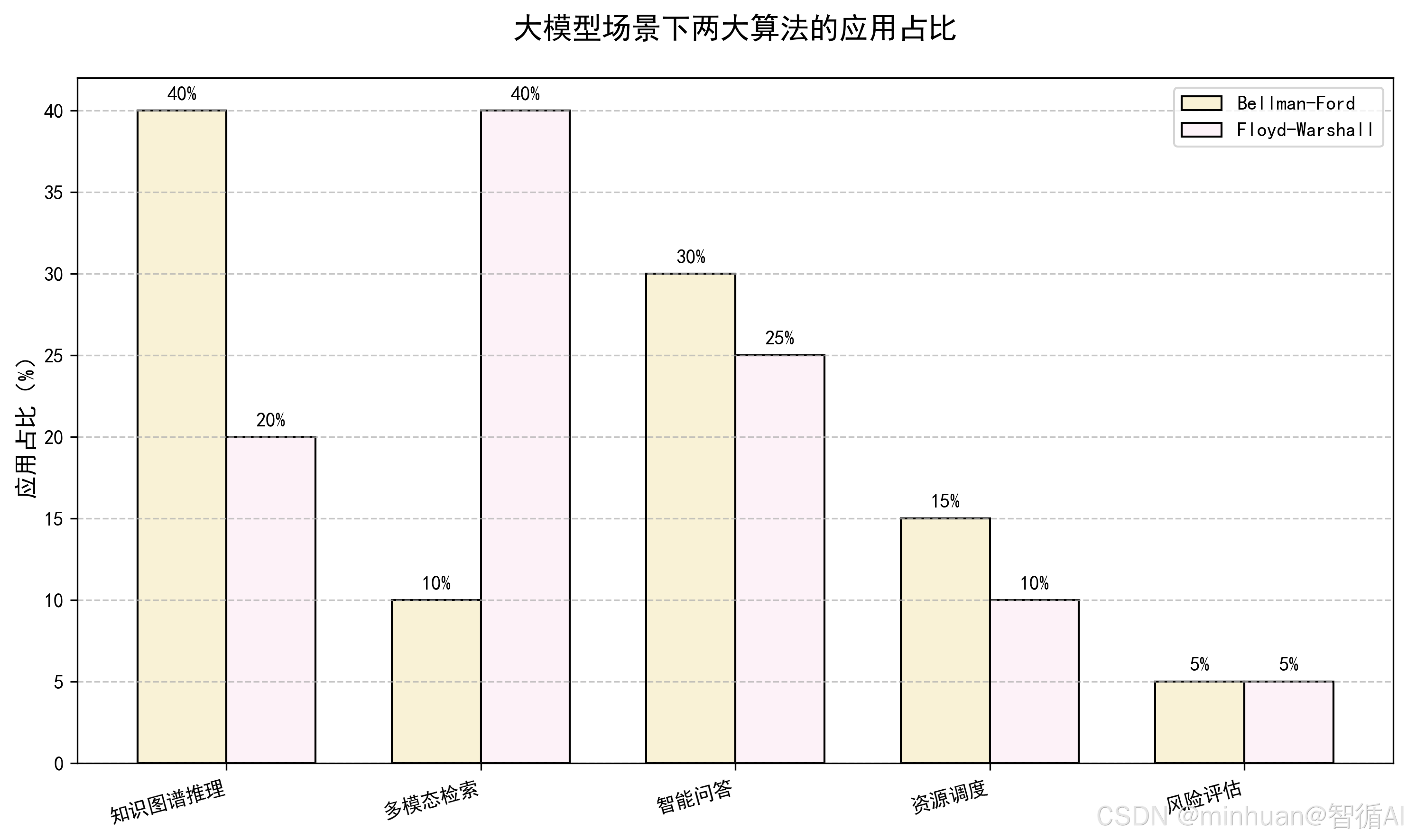
六、总结
今天主要讲了两个图论算法Bellman-Ford 和 Floyd-Warshall和大模型的结合应用,Bellman-Ford 算法主要解决的是单源最短路径问题,最大的优势就是能处理负权重边,还能检测负权环。核心逻辑就是通过多轮松弛操作,逐步缩短每个顶点到起点的距离,n 个顶点最多需要 n-1 轮,要是第 n 轮还能缩短,就说明有负权环,这时候就没有最短路径了。
然后是 Floyd-Warshall 算法,它侧重的是所有节点对之间的最短路径,用的是动态规划的思路,通过中间顶点逐步优化任意两点间的路径,核心就是那个状态转移公式。它也能处理负权边,但检测负权环的方式不一样,看对角线元素是不是小于 0 就行,更适合中小规模的图。这两个算法和大模型结合很实用,比如知识图谱的多跳推理、多模态语义检索,大模型负责理解语义、匹配实体,算法负责精准计算最短路径,两者配合能让智能系统更高效、更可靠。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 16
16 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)