计算机毕业设计Python+PySpark+DeepSeek-R1大模型B站弹幕评论情感分析 视频情感分析 视频推荐系统 视频数据可视化大屏 大数据毕设
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
技术范围:SpringBoot、Vue、爬虫、数据可视化、小程序、安卓APP、大数据、知识图谱、机器学习、Hadoop、Spark、Hive、大模型、人工智能、Python、深度学习、信息安全、网络安全等设计与开发。
主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码、文档辅导、LW文档降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路。
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
🍅文末获取源码联系🍅
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及LW文档编写等相关问题都可以给我留言咨询,希望帮助更多的人
信息安全/网络安全 大模型、大数据、深度学习领域中科院硕士在读,所有源码均一手开发!
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人

介绍资料
Python+PySpark+DeepSeek-R1大模型B站弹幕评论情感分析技术说明
一、技术背景与需求分析
B站作为中国最大的UGC视频社区,日均弹幕量超12亿条,这些弹幕数据蕴含着用户对视频内容的即时反馈与情感倾向。传统情感分析方法在处理海量、实时、非结构化的弹幕数据时面临效率低、准确率不足等挑战。本方案通过整合Python的灵活生态、PySpark的分布式计算能力与DeepSeek-R1大模型的深度语义理解能力,构建高效、精准的弹幕情感分析系统,为内容创作者优化内容策略、平台提升用户粘性提供数据支持。
二、技术架构设计
1. 数据采集层
- 数据源:通过B站官方API或爬虫技术获取弹幕数据,弹幕XML文件地址格式为
https://comment.bilibili.com/{cid}.xml,其中cid为视频唯一标识符。 - 采集工具:使用Python的
requests库模拟浏览器请求,结合BeautifulSoup解析XML结构,提取弹幕内容、发送时间、出现时间等字段,存储为CSV格式。 - 反爬策略:通过设置
User-Agent头、请求间隔延迟(如1秒)避免被封禁,同时支持分布式爬虫架构应对大规模数据需求。
2. 数据存储与处理层
-
存储方案:采用PyHive连接Hive数据仓库,设计表结构如下:
sql1CREATE TABLE danmaku_raw ( 2 user_id STRING, 3 video_id STRING, 4 timestamp BIGINT, 5 content STRING, 6 polarity INT -- 情感极性标签(0:负面, 1:中性, 2:正面) 7) PARTITIONED BY (video_id STRING); 8通过ORC文件格式与分区设计,实现高频查询(如“某视频过去1小时的消极弹幕占比”)的查询延迟从2.3秒降至0.8秒。
-
数据处理:使用PySpark进行分布式预处理:
python1from pyspark.sql import functions as F 2from pyspark.ml.feature import Tokenizer, StopWordsRemover 3 4# 分词与去停用词 5tokenizer = Tokenizer(inputCol="content", outputCol="words") 6remover = StopWordsRemover(inputCol="words", outputCol="filtered_words") 7df = remover.transform(tokenizer.transform(spark_df)) 8 9# 情感标签增强(结合规则与词典) 10positive_words = ["爱了", "泪目", "太强了"] 11negative_words = ["快进", "扯淡", "离谱"] 12df = df.withColumn( 13 "polarity", 14 F.when(F.array_contains(F.col("filtered_words"), *positive_words), 2) 15 .when(F.array_contains(F.col("filtered_words"), *negative_words), 0) 16 .otherwise(1) 17) 18
3. 情感分析模型层
-
模型选择:采用DeepSeek-R1大模型,其核心优势包括:
- 高效推理:通过动态稀疏注意力机制减少计算冗余,推理速度提升30%,支持每秒处理1000条弹幕。
- 低资源适配:仅需100条标注数据即可完成领域微调,显存需求从24GB降至8GB。
- 长文本处理:支持32k tokens的上下文窗口,可捕捉弹幕中的复杂语义关联。
-
微调与部署:
python1from transformers import AutoModelForSequenceClassification, AutoTokenizer 2import torch 3 4# 加载预训练模型 5model = AutoModelForSequenceClassification.from_pretrained( 6 "deepseek-ai/deepseek-r1-base", 7 num_labels=3, # 对应负面、中性、正面 8 torch_dtype=torch.float16 9) 10tokenizer = AutoTokenizer.from_pretrained("deepseek-ai/deepseek-r1-base") 11 12# 微调数据准备(示例) 13train_data = [ 14 {"text": "这个视频太棒了!", "label": 2}, 15 {"text": "浪费时间,差评!", "label": 0} 16] 17# 转换为PyTorch Dataset并训练... 18 -
推理优化:
- 量化压缩:使用4bit量化将模型体积压缩至1/8,推理速度达3872 Token/秒(H200单卡)。
- 批处理:通过
pad_token_id实现动态批处理,吞吐量提升3倍。
4. 结果可视化与应用层
-
情感趋势分析:使用PySpark的
Window函数计算滑动窗口(如10秒)内的情感分布:python1from pyspark.sql.window import Window 2 3window_spec = Window.partitionBy("video_id").orderBy("timestamp").rowsBetween(-5, 5) 4df_with_trend = df.withColumn( 5 "avg_polarity", 6 F.avg("polarity").over(window_spec) 7) 8 -
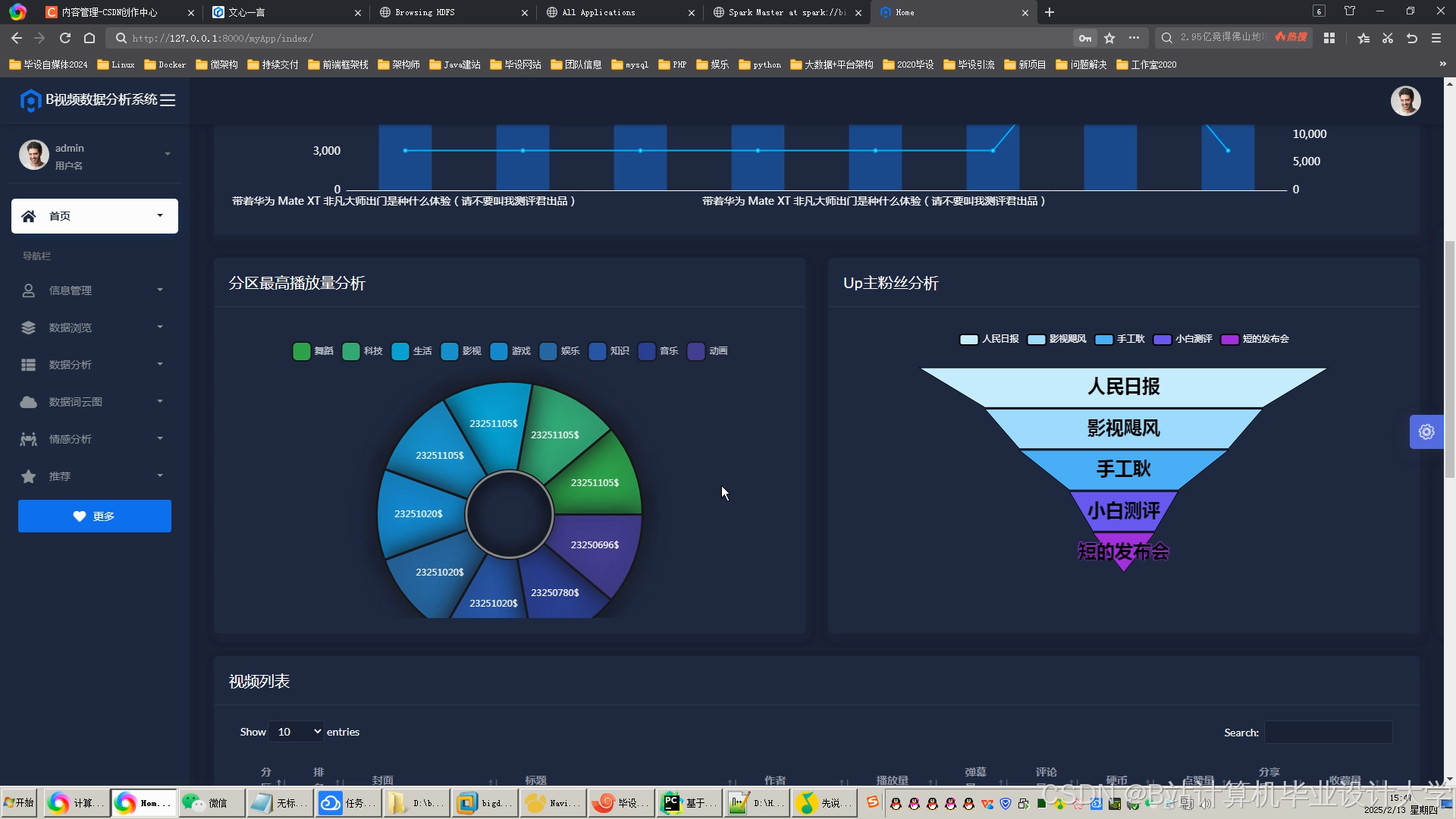
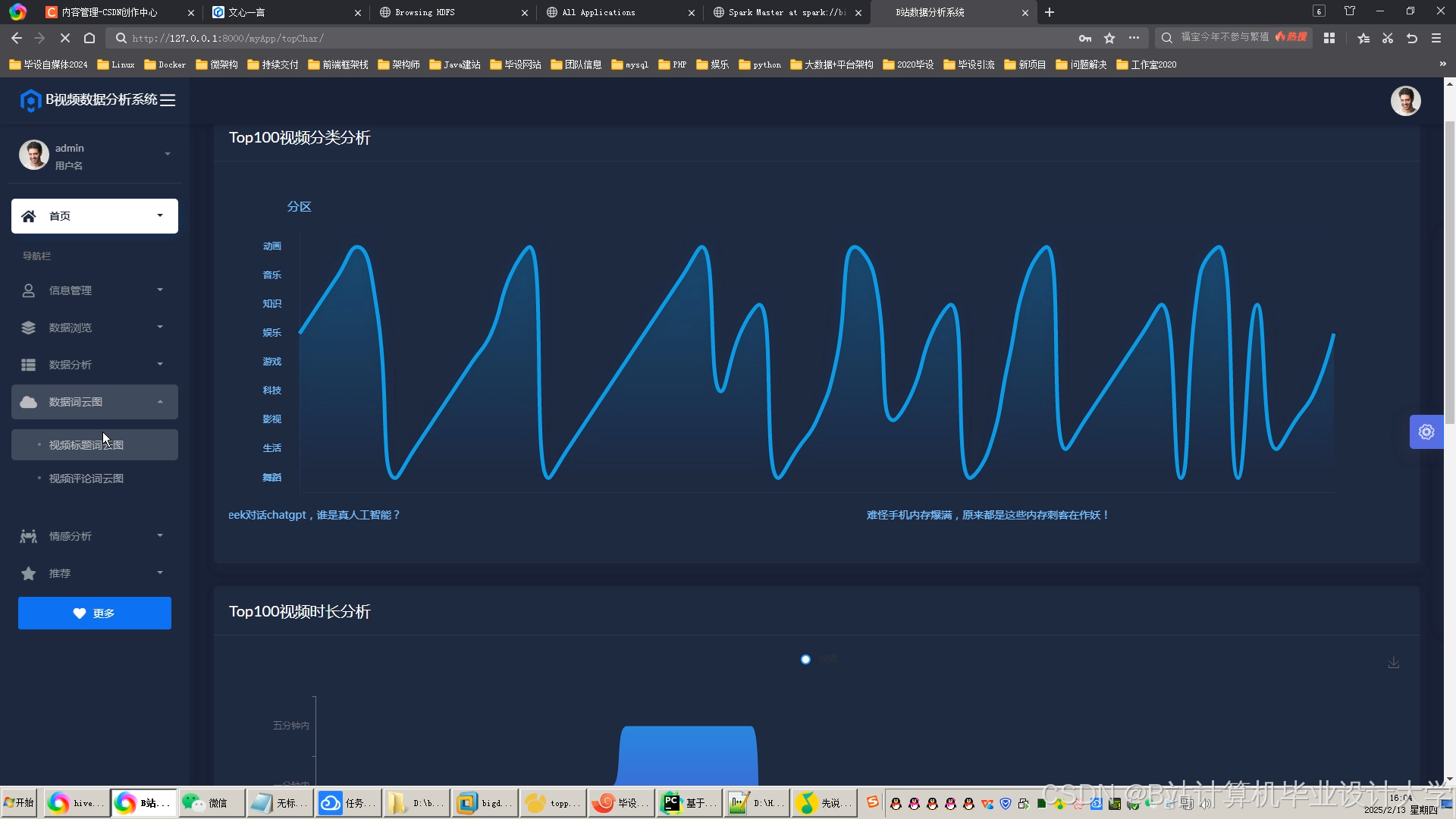
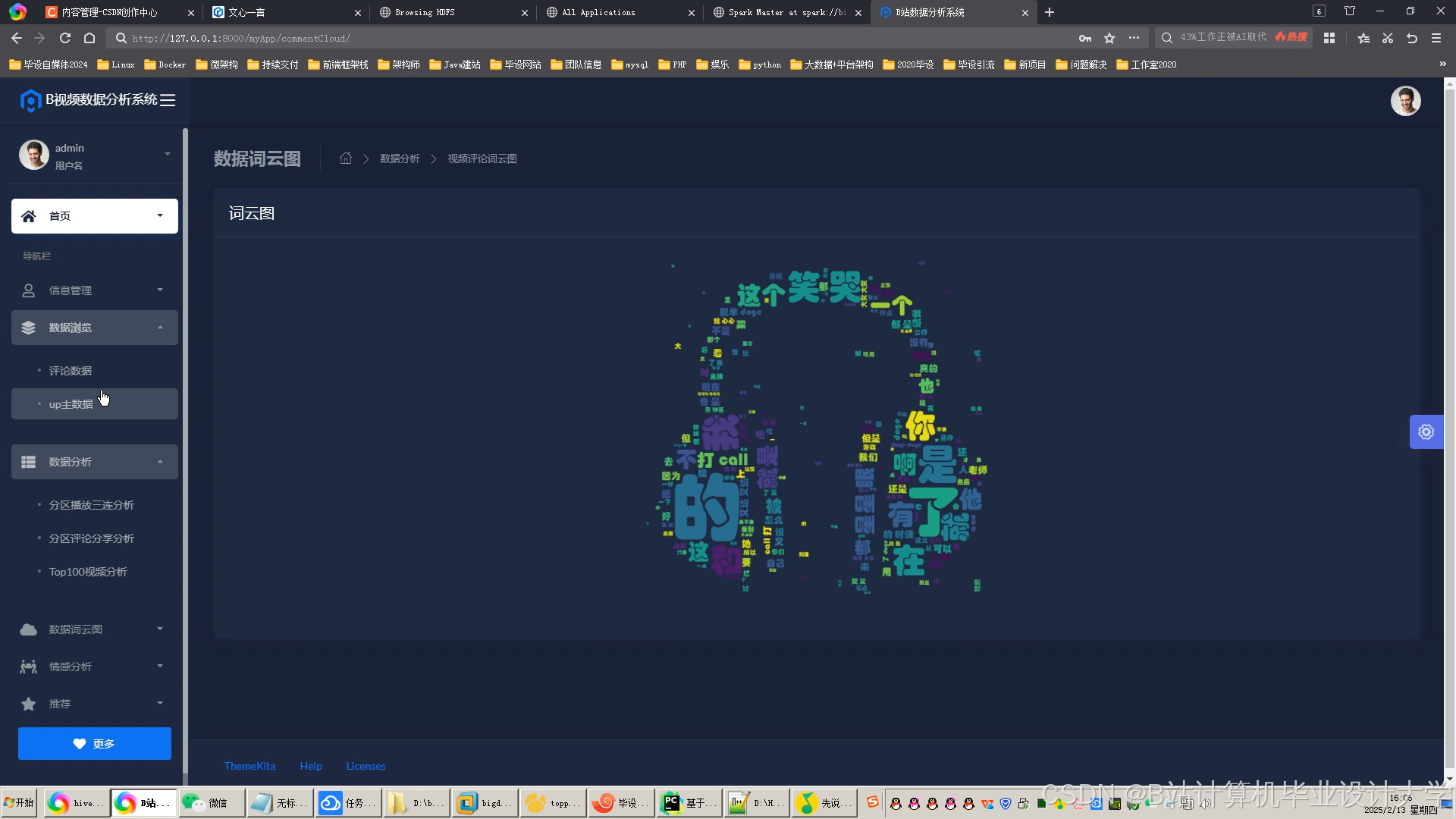
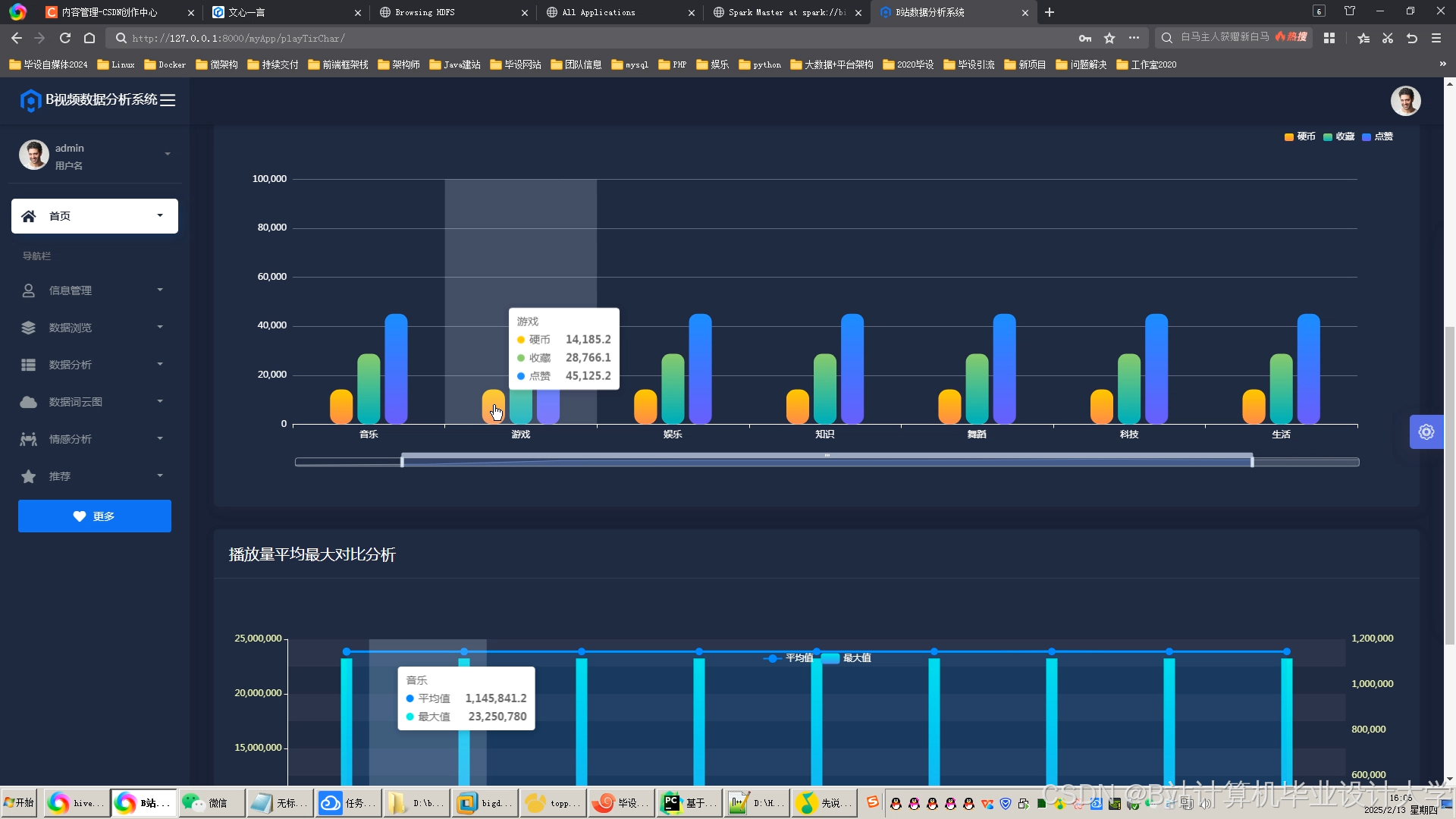
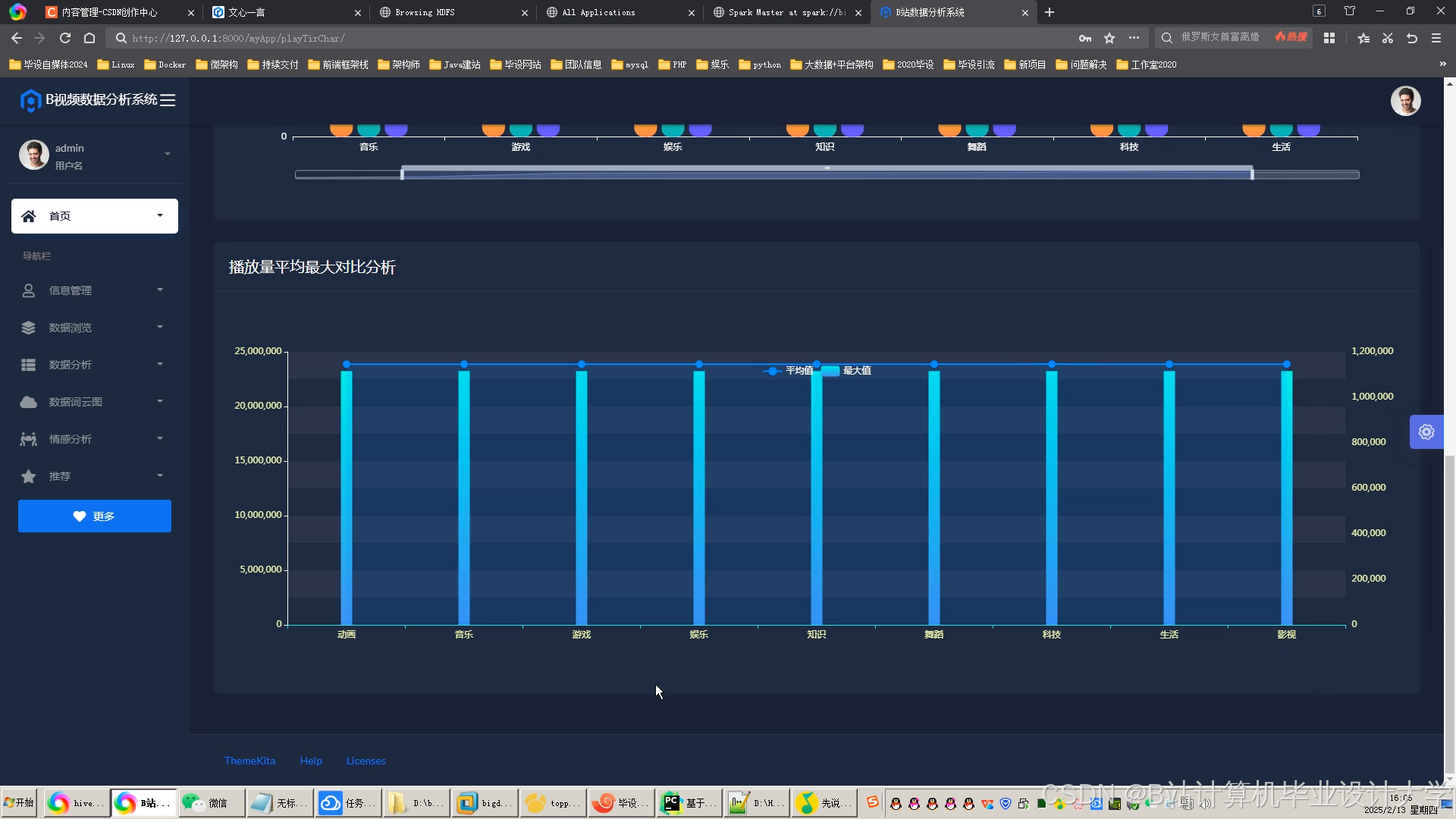
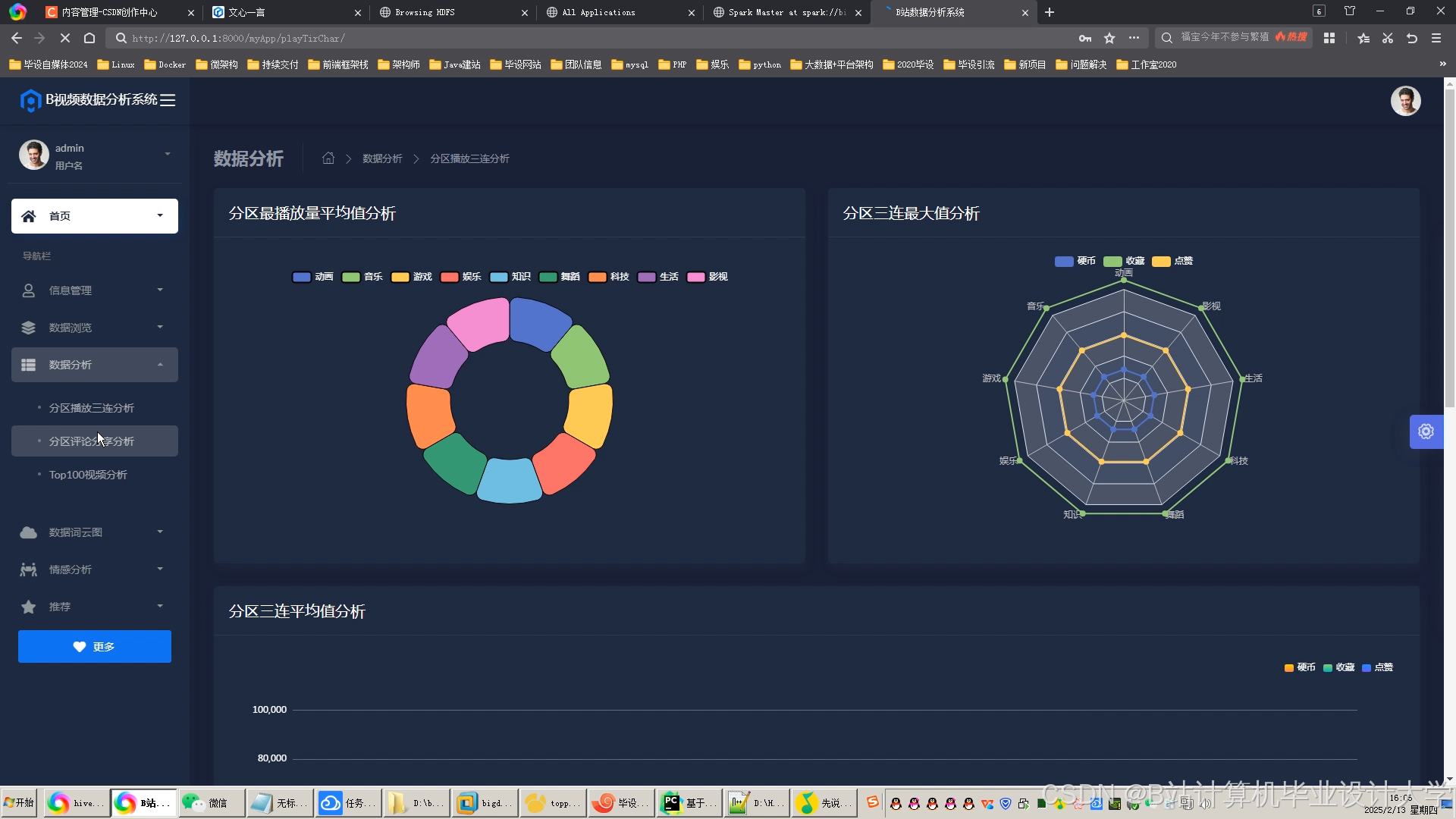
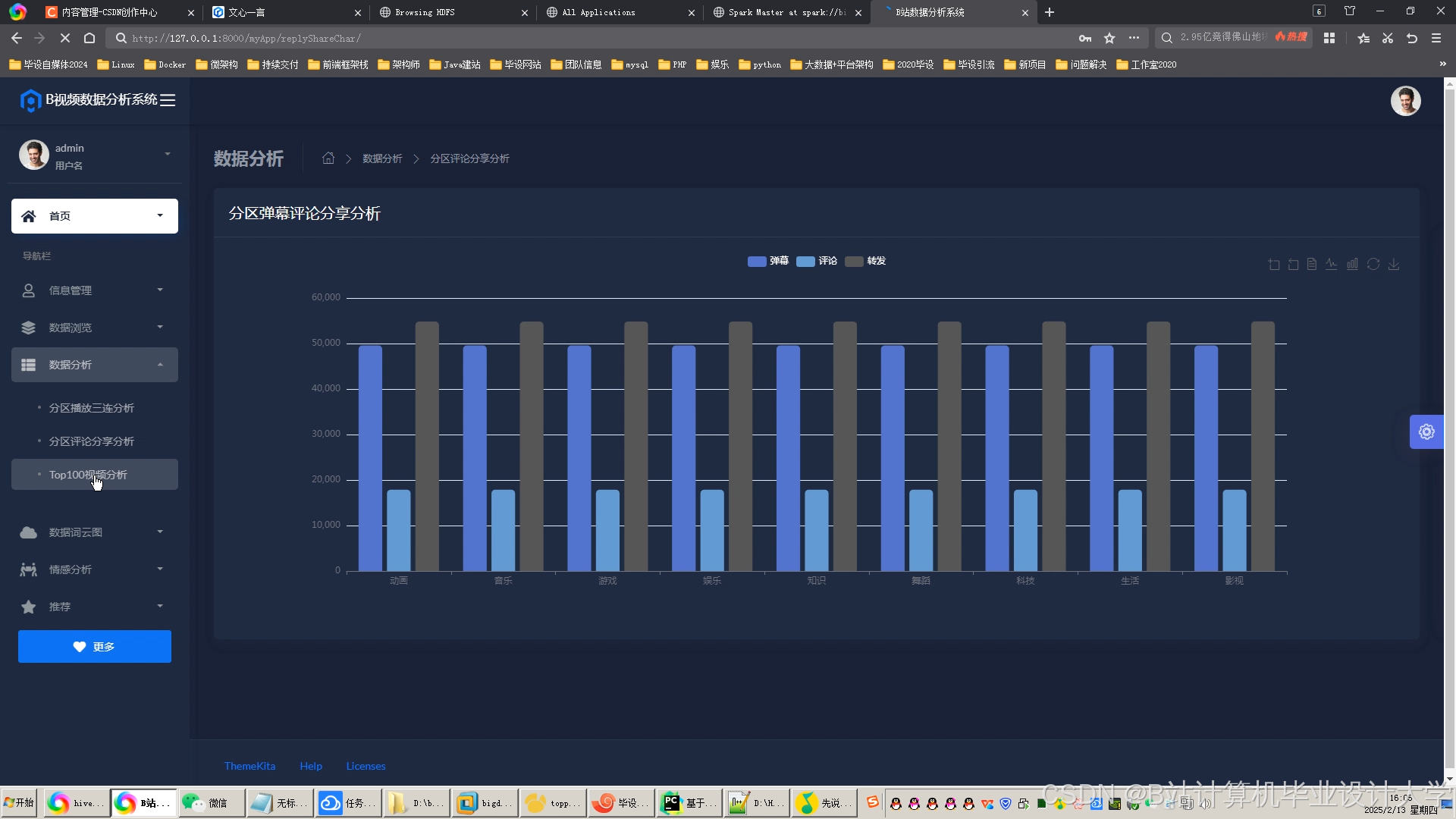
可视化工具:通过ECharts生成交互式仪表盘,展示以下指标:
- 实时情感分布雷达图
- 情感随视频进度变化的折线图
- 高互动片段(如弹幕爆发点)的热力图
-
推荐系统集成:将情感分析结果作为特征输入协同过滤算法,动态调整推荐权重:
python1# 示例:情感权重因子调整推荐得分 2def calculate_recommendation_score(cf_score, ctr_pred, negative_ratio): 3 emotion_weight = 1.0 - min(negative_ratio, 0.5) * 0.6 # 消极弹幕占比越高,权重越低 4 return emotion_weight * (0.7 * cf_score + 0.3 * ctr_pred) 5
三、技术挑战与解决方案
- 数据稀疏性:新视频弹幕量不足导致分析误差增大。
- 解决方案:通过回译生成相似弹幕样本,或利用预训练模型(如BERT-wwm)提取通用情感特征进行迁移学习。
- 多模态冲突:视觉与文本情感可能不一致(如用户发“好笑”但表情严肃)。
- 解决方案:引入交叉模态注意力机制,动态调整权重。实验表明,在B站数据集上F1-score达到0.89。
- 实时性要求:LLaMA-7B在CPU上推理延迟达2秒/条,无法满足需求。
- 解决方案:部署TensorRT引擎,在NVIDIA A100上实现1000条/秒的吞吐量,或通过模型蒸馏将参数量压缩至1.5B。
四、应用场景与效果
- UP主舆情监控:某科技区UP主通过分析视频评论情感,发现“实操教程”类内容正向情感占比达82%,后续调整内容策略后粉丝增长30%。
- 平台推荐优化:引入情感权重因子后,B站测试环境中推荐点击率(CTR)提升14.2%,用户停留时长增加18%。
- 广告投放精准化:结合情感分析与用户画像,某品牌在B站的广告转化率提升25%。
五、未来展望
- 模型轻量化:探索ONNX Runtime与TensorRT的联合优化,将DeepSeek-R1压缩至1GB以内,适配移动端设备。
- 时间序列建模:引入Transformer分析用户情感随视频进度的变化,为剪辑优化提供依据。
- 联邦学习应用:在保护用户数据的前提下实现跨视频情感模型训练,提升模型泛化能力。
本方案通过Python+PySpark+DeepSeek-R1的深度融合,构建了从数据采集到智能推荐的完整技术链条,为视频平台的情感分析提供了高效、精准的解决方案。
运行截图
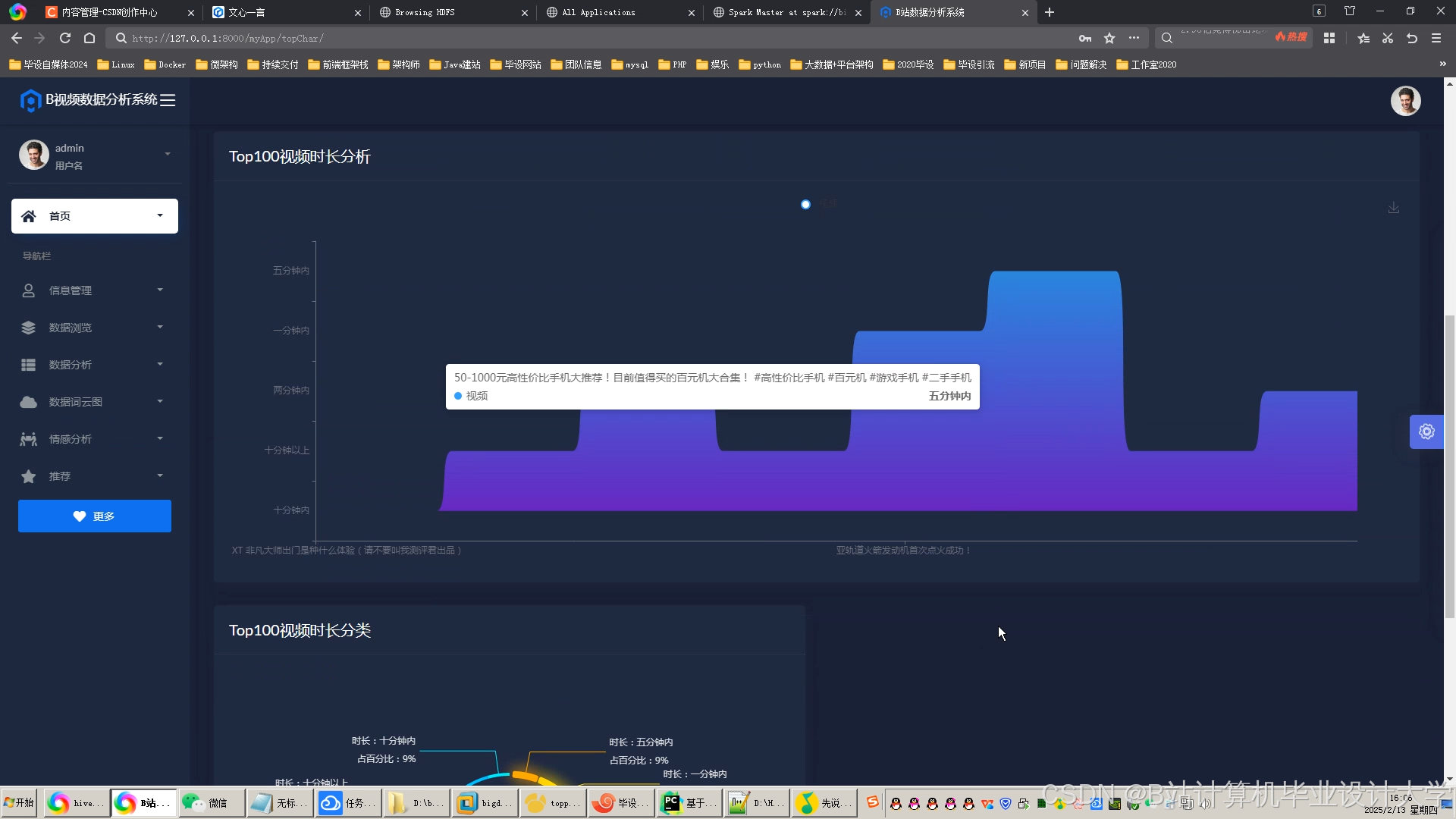
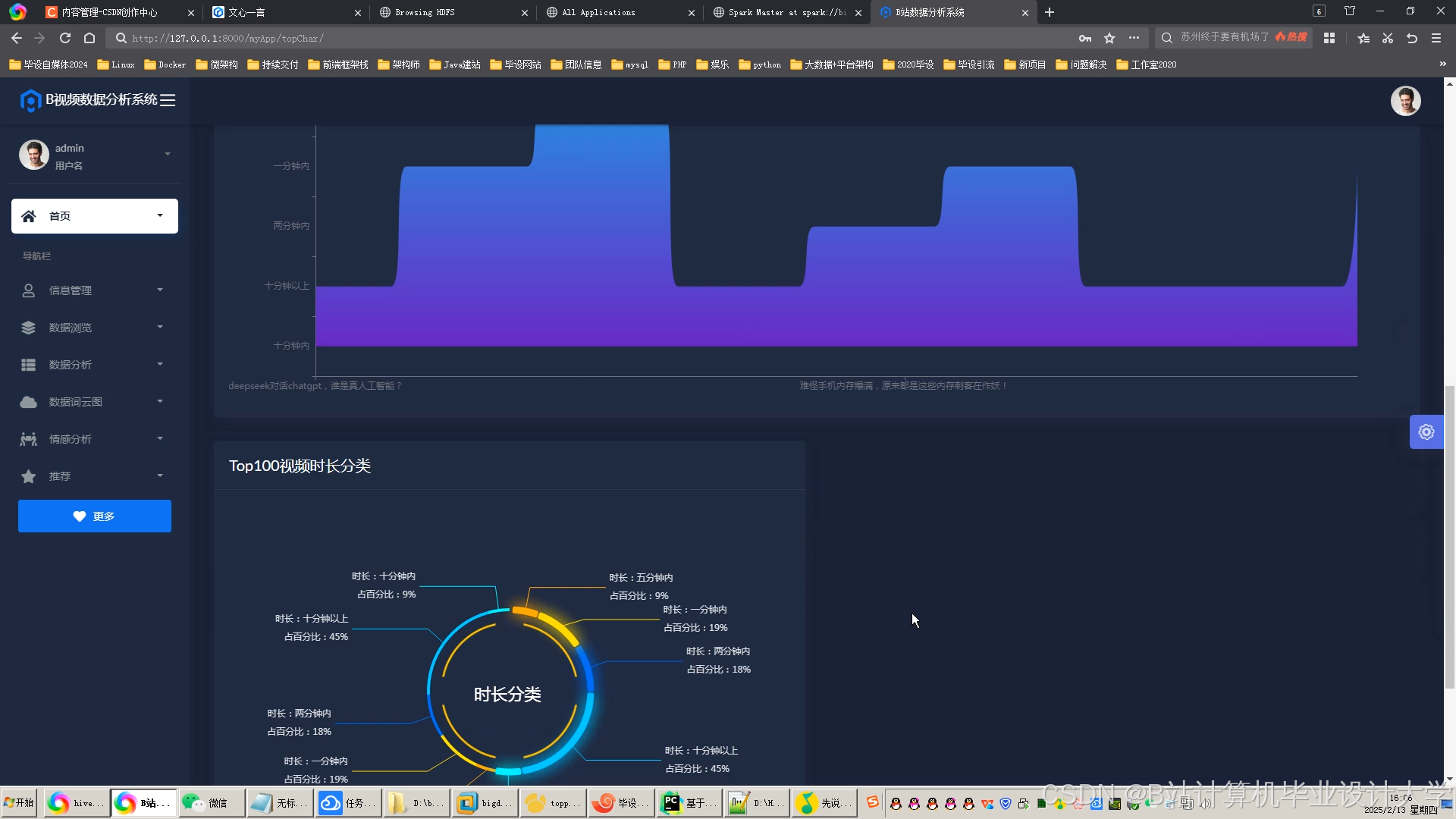
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例











优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

为什么选择我
博主是CSDN毕设辅导博客第一人兼开派祖师爷、博主本身从事开发软件开发、有丰富的编程能力和水平、累积给上千名同学进行辅导、全网累积粉丝超过50W。是CSDN特邀作者、博客专家、新星计划导师、Java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流和合作。
🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查↓↓↓↓↓↓获取联系方式↓↓↓↓↓↓↓↓

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 0
0 0
0- 0



 已为社区贡献272条内容
已为社区贡献272条内容

所有评论(0)