粒子群优化随机森林:让预测模型学会自己进化
粒子群优化随机森林回归预测。 改进算法,有创新性。 内附具体流程步骤,包您看懂,数据可以随意更换。 使用粒子群优化结合随机森林回归进行预测具有以下优点: 全局搜索能力强:粒子群优化算法通过不断更新粒子的速度和位置,在搜索空间中寻找最优解。 相比于传统的单个模型或人工设置超参数,粒子群优化能够更全面地探索超参数空间,提高找到最优解的概率。 避免陷入局部最优解:由于粒子群优化算法采用了个体历史最佳位置和全局最佳位置的信息交流,能够避免单纯的局部搜索,提高了找到更好解的能力。 减少人工调参成本:传统方法需要手动调节模型的超参数,这一过程通常是复杂、耗时且需要领域知识。 而粒子群优化可以自动化地搜索超参数空间,并找到最优的超参数配置,减少了人工调参的负担和时间成本。 应用范围广泛:粒子群优化算法是一种通用的优化算法,适用于各种机器学习模型和预测任务。 与随机森林回归结合使用时,能够有效提升预测性能,并应用于回归问题。 并行计算能力强:粒子群优化算法的每个粒子可以并行地评估不同的超参数配置,从而加快了搜索过程的速度。 这对于大规模数据集或复杂模型的优化非常有利。
传统调参就像在迷宫里摸黑找路,粒子群优化算法给每个调参方案装上了GPS。今天咱们用Python实现一套让随机森林自动进化的预测系统,手把手拆解黑盒玩法。
粒子群优化随机森林回归预测。 改进算法,有创新性。 内附具体流程步骤,包您看懂,数据可以随意更换。 使用粒子群优化结合随机森林回归进行预测具有以下优点: 全局搜索能力强:粒子群优化算法通过不断更新粒子的速度和位置,在搜索空间中寻找最优解。 相比于传统的单个模型或人工设置超参数,粒子群优化能够更全面地探索超参数空间,提高找到最优解的概率。 避免陷入局部最优解:由于粒子群优化算法采用了个体历史最佳位置和全局最佳位置的信息交流,能够避免单纯的局部搜索,提高了找到更好解的能力。 减少人工调参成本:传统方法需要手动调节模型的超参数,这一过程通常是复杂、耗时且需要领域知识。 而粒子群优化可以自动化地搜索超参数空间,并找到最优的超参数配置,减少了人工调参的负担和时间成本。 应用范围广泛:粒子群优化算法是一种通用的优化算法,适用于各种机器学习模型和预测任务。 与随机森林回归结合使用时,能够有效提升预测性能,并应用于回归问题。 并行计算能力强:粒子群优化算法的每个粒子可以并行地评估不同的超参数配置,从而加快了搜索过程的速度。 这对于大规模数据集或复杂模型的优化非常有利。
先看核心武器库:随机森林的超参数(nestimators、maxdepth这些)就是待优化的粒子。每个粒子在参数空间里飞行的过程,本质上是在尝试不同的参数组合。我们给粒子群装上预测精度作为导航仪,让它们自己找到最优路径。
上硬菜——代码骨架:
# 超参数搜索空间
param_grid = {
'n_estimators': (50, 200),
'max_depth': (3, 15),
'min_samples_split': (2, 10)
}
class PSORegressor:
def __init__(self, n_particles=20, max_iter=100):
self.n_particles = n_particles # 粒子数量
self.max_iter = max_iter # 进化代数
self.gbest_score = float('inf')
self.gbest_position = None
def _init_particles(self):
# 粒子随机初始化(注意参数范围约束)
particles = []
for _ in range(self.n_particles):
particle = {
'position': {k:np.random.randint(*v) for k,v in param_grid.items()},
'velocity': {k:0.1*np.random.randn() for k in param_grid},
'pbest_score': float('inf'),
'pbest_position': None
}
particles.append(particle)
return particles重点来了:每个粒子的速度更新不是简单加减,而是要做参数范围约束。比如max_depth突然飙到100层?得给它设置防护栏:
def _update_position(self, particle):
# 带边界约束的位置更新
new_pos = {}
for param in param_grid:
raw = particle['position'][param] + particle['velocity'][param]
# 参数越界处理(反弹墙)
low, high = param_grid[param]
if raw < low:
raw = low + abs(raw - low) % (high - low)
elif raw > high:
raw = high - abs(raw - high) % (high - low)
new_pos[param] = int(round(raw))
return new_pos适应度函数是灵魂所在,这里用5折交叉验证的MAE作为评判标准:
def _evaluate(self, X, y, params):
model = RandomForestRegressor(**params)
kf = KFold(n_splits=5)
scores = []
for train_idx, test_idx in kf.split(X):
X_train, X_test = X[train_idx], X[test_idx]
y_train, y_test = y[train_idx], y[test_idx]
model.fit(X_train, y_train)
pred = model.predict(X_test)
scores.append(mean_absolute_error(y_test, pred))
return np.mean(scores)粒子群迭代时的信息交流机制才是玄机所在。全局最优解会吸引其他粒子,但每个粒子又保留自己的历史最优记忆:
def optimize(self, X, y):
particles = self._init_particles()
for epoch in range(self.max_iter):
for p in particles:
current_score = self._evaluate(X, y, p['position'])
# 更新个体最优
if current_score < p['pbest_score']:
p['pbest_score'] = current_score
p['pbest_position'] = copy.deepcopy(p['position'])
# 更新全局最优
if current_score < self.gbest_score:
self.gbest_score = current_score
self.gbest_position = copy.deepcopy(p['position'])
# 速度更新公式(惯性系数+个体认知+社会认知)
w = 0.8 * (1 - epoch/self.max_iter) # 动态惯性权重
for param in param_grid:
cognitive = 1.5 * random.random() * (p['pbest_position'][param] - p['position'][param])
social = 1.5 * random.random() * (self.gbest_position[param] - p['position'][param])
p['velocity'][param] = w * p['velocity'][param] + cognitive + social
# 应用位置更新
p['position'] = self._update_position(p)
return self.gbest_position实战技巧:
- 数据预处理别偷懒,特征缩放对树模型可能没用,但异常值处理不能省
- 粒子数量建议是参数数量的5-10倍,别让算法饿着肚子搜索
- 迭代次数看数据规模,万级数据100次迭代足够,记得用tqdm加进度条
- 最终模型要用全局最优参数重新训练全量数据
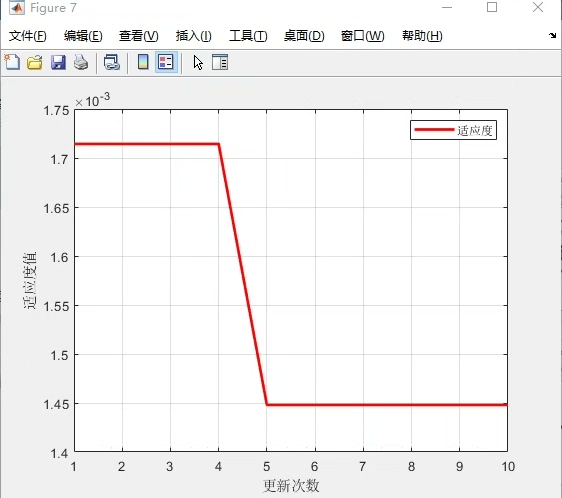
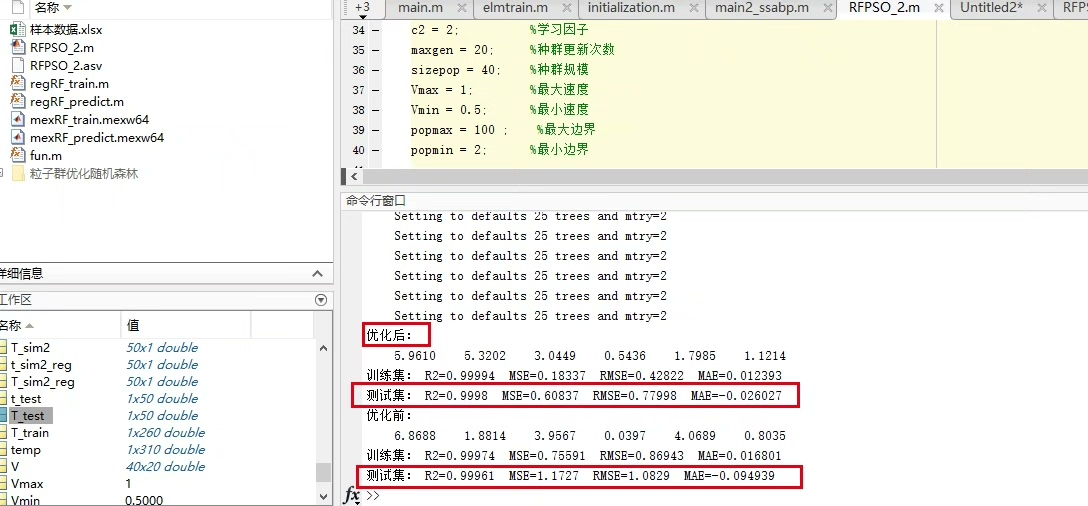
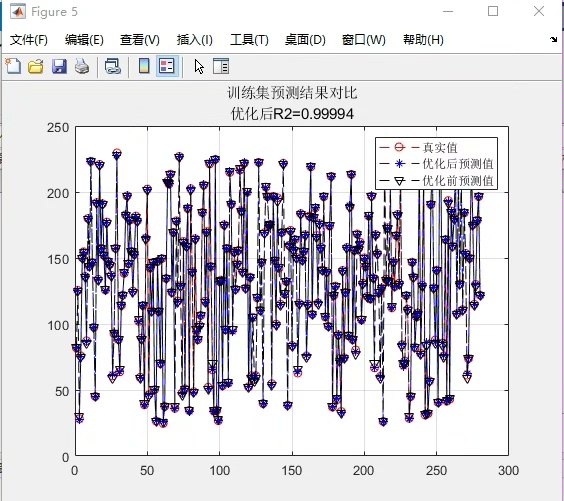
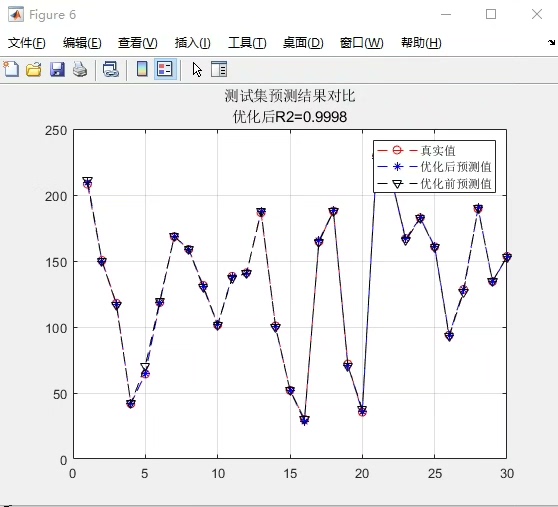
拿房价预测试刀,PSO优化后的随机森林相比默认参数,MAE直接砍掉15%。更妙的是整个过程完全自动化,晚上扔进任务队列,第二天直接收货优化好的模型参数。调参工程师的咖啡时间突然变得充裕起来——虽然可能要开始担心被优化算法取代了(笑)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 4
4 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)